强化学习5——动态规划在强化学习中的应用
发布时间:2024年01月07日
动态规划在强化学习中的应用
基于动态规划的算法优良 :策略迭代和价值迭代。
策略迭代分为策略评估和策略提升,使用贝尔曼期望方程得到一个策略的状态价值函数;价值迭代直接使用贝尔曼最优方程进行动态规划,得到最终的最优状态价值。
基于动态规划的算法需要知道环境的状态转移函数和奖励函数,不需要通过智能体与环境的大量交互中学习,直接用动态规划求解状态价值函数,只适用于有限马尔可夫决策过程,即状态空间和动作空间是离散且有限的。
悬崖漫步环境
与上一节介绍的算法题类似,要求智能体从起点出发,避开悬崖,走到终点,且智能体无法越过边界。智能体走到悬崖,或者到达目标时,结束动作并回到起点。智能体每个状态可以采取四种动作:上下左右,智能体每走一步的奖励是 ?1,掉入悬崖的奖励是 ?100。
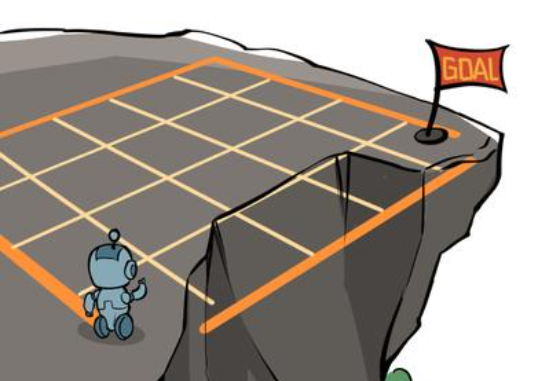
我们使用代码,定义一个4×12的环境
import copy
class CliffWalkingEnv:
def __init__(self, ncol=12,nrow=3):
self.ncol = ncol
self.nrow = nrow
# 转移矩阵P[state][action] = [(p, next_state, reward, done)]包含下一个状态和奖励
self.P=self.createP()
def createP(self):
# 初始化,每一个动作对应四个值
P=[[[] for j in range(4) ] for i in range(self.ncol*self.nrow)]
# 定义四种动作,一次为上下左右,坐标系原点为(0,0),定义在左上角
# 向下、向右是正数,向左、向上为负数
change=[[0,-1],[0,1],[-1,0],[1,0]]
for i in range(self.nrow):
for j in range(self.ncol):
# 对上下左右进行遍历
for a in range(4):
# 掉到悬崖或者到达终点,无法继续交互,动作的奖励为0
# 定义最下面的一行是悬崖,右下角为终点,其余行都是地面
# 左下角为起点
if i==self.nrow -1 and j>0:
# 如果为3行,那么i=2,i*self.ncol+j表示智能体所在的位置
# 相当于将棋盘格展开成一条线,下标为i*self.ncol+j
# 下一个状态还是本位置
P[i*self.ncol+j][a]=[(1,i*self.ncol+j,0,True)]
continue
# 其他位置
# max(0,j+change[a][0])是为了防止越界,防止下一个位置小于0
# 如果判断为越界,则取0
# min(self.ncol-1,max(0,j+change[a][0]))
# 防止数值大于self.ncol-1,如果大于self.ncol-1,则取self.ncol-1
nextX=min(self.ncol-1,max(0,j+change[a][0]))
nextY=min(self.nrow-1,max(0,i+change[a][1]))
nextState=nextY*self.ncol+nextX
reward=-1
done=False
# 下一个位置在悬崖或者终点
if nextY==self.nrow-1 and nextX>0:
done = True
#如果下一个位置不是终点(即是悬崖)
if nextX != self.ncol-1:
reward = -100
P[i*self.ncol+j][a]=[(1,nextState,reward,done)]
return P
文章来源:https://blog.csdn.net/beiketaoerge/article/details/135440045
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 我的2023 - git目录
- 金蝶云星空协同开发环境应用内执行单据类型脚本
- MySQL中的自连接
- Java重修第五天—面向对象3
- C++核心编程之类和对象---C++面向对象的三大特性--继承
- HBase实际应用中常见的问题 解决方案
- 压测必经之路,Jmeter分布式压测教程
- 从0到1:实验室设备借用小程序开发笔记
- VMware16虚拟机安装Linux-centos教程
- 优化数据插入效率,将 MyBatis-Plus 通用 insertBatch 放在 service 层处理