[SS]语义分割——基础知识
一、定义
1、概念?
????????语义分割(Semantic Segmentation)是计算机视觉中的一项任务,目标是将图像中的每个像素按其语义类别进行分类。与传统的目标检测不同,语义分割对图像中的每个像素都进行分类,而不是只关注物体的边界框。
????????语义分割的目标是给图像中的每个像素分配一个类别标签,通常使用颜色编码来可视化不同的类别。例如,将图像中的道路像素标记为蓝色,建筑物像素标记为红色等。
????????语义分割在许多计算机视觉任务中起到重要作用,如自动驾驶、智能监控、图像编辑等。它可以提供详细的场景理解,使计算机能够准确地理解图像中的不同物体和区域,并在各种应用中进行更精确的分析和决策。
????????近年来,随着深度学习的快速发展,基于深度学习的语义分割方法取得了显著的进展。常用的深度学习模型包括全卷积网络(FCN)、U-Net、DeepLab等,它们能够准确地分割图像,并在各种实际场景中取得了优秀的性能。
2、 常见分割任务
语义分割(Semantic Segmentation)
????????语义分割是将图像分割为不同的语义区域,即将图像中的每个像素都标记为属于哪个语义类别。换句话说,它的目标是为图像中的每个像素分配一个语义标签,例如人、车、树、建筑等。语义分割关注的是图像中的每个像素的语义信息,不关心具体的实例。
实例分割(Instance Segmentation)
????????实例分割是将图像中的目标物体分割为独立的实例,即为每个目标分配唯一的标识符,并进行像素级的分割。与语义分割不同,实例分割不仅关注目标的语义类别,还关注目标的个体性。因此,在实例分割中,同一类别的不同目标物体会被分配不同的标识符,以区分它们。
全景分割(Panoramic Segmentation)
????????全景分割是语义分割和实例分割的融合,旨在将图像中的每个像素分配一个语义标签,并为每个目标物体分配唯一的标识符,同时区分不同的实例。全景分割可以视为将图像中的每个像素标记为语义类别和实例标识符的任务。实质上,全景分割是一种综合性的图像分割任务,旨在提供对图像中所有物体的语义信息和个体信息。
3、建筑物提取(Building Footprint Extraction)
????????建筑物提取任务BFE(Building Footprint Extraction)是指从高分辨率遥感图像中准确地提取出建筑物的轮廓或边界信息。这是一项具有重要应用价值的任务,可以用于城市规划、地理信息系统(GIS)、自动驾驶、灾害评估等领域。
????????BFE任务的挑战在于建筑物在图像中呈现出各种形状、大小和复杂性。为了解决这个问题,研究者们提出了各种方法和算法。以下是一些常用的BFE方法:
-
基于图像特征的方法:这些方法利用图像的颜色、纹理、形状等特征来区分建筑物和非建筑物。例如,可以使用边缘检测、纹理分析、形状匹配等技术来提取建筑物的边界。
-
基于机器学习的方法:这些方法使用机器学习算法来学习建筑物和非建筑物的分类器。常用的算法包括支持向量机(SVM)、随机森林(Random Forest)和深度学习模型等。这些方法需要大量的标注数据和特征工程。
-
基于分割的方法:这些方法将建筑物提取任务看作是像素级的语义分割任务,利用分割模型将每个像素分类为建筑物或非建筑物。深度学习模型如U-Net、Mask R-CNN等常被用于此类方法。
-
基于无监督学习的方法:这些方法通过对图像进行聚类和分割来提取建筑物。常用的技术包括基于颜色、纹理和形状的聚类分析、超像素分割等。
-
结合多源数据的方法:这些方法将多源数据(如高分辨率遥感图像、激光雷达数据等)结合起来,通过融合不同数据源的信息来提高建筑物提取的准确性。
????????BFE是一个复杂的任务,目前仍然存在一些挑战和问题,如建筑物遮挡、复杂背景、低对比度等。未来的研究将继续致力于提高建筑物提取的准确性和鲁棒性,以满足实际应用的需求。
二、任务数据
1、数据集格式

????????PASCAL VOC数据集提供一个PNG图片(P模式),在图片中记录每个像素所属的类别信息。需要注意的是,提供的PNG图片是用调色板的模式进行存储,为1通道图片,图象呈彩色是因为针对像素0到255提供了一个调色板,针对每个像素值都对应一个颜色,所以可以将1通道的图片映射到彩色的图片上。?
notes:
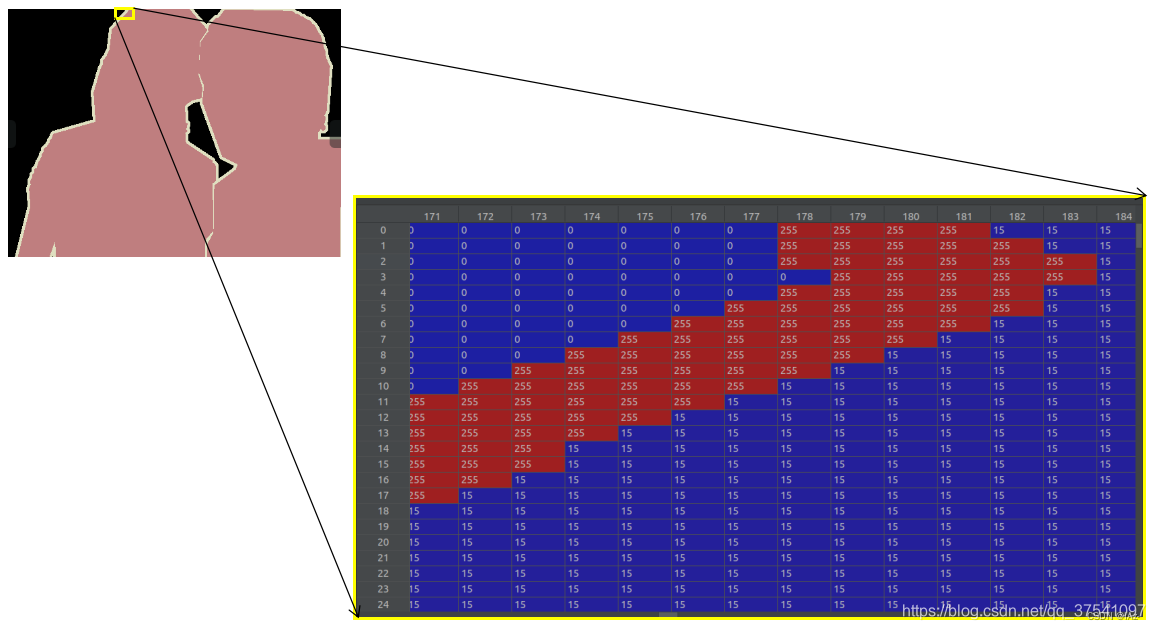
? ? ? ? 针对目标的边缘,会有特殊的颜色进行分割,或者图片特殊区域也会用特殊颜色进行填充。该特殊颜色对应的像素值是255,在训练过程中计算损失时会忽略数值为255的地方,针对目标边缘的类别划分并不容易,包括有些不容易分割的目标也可以进行填充,这样就可以忽略,在训练模型时候就不会计算这部分损失。

? ? ? ? MS COCO数据集中提供的是针对图片中每一个目标都给出了多边形的坐标形式,将坐标点连起来就对应了目标所在的区域。在使用中需要将多边形坐标信息解码成PNG图片。计算损失时将预测的每个像素对应的类别与真实标签的每一个类别进行对比计算,所以在计算损失时希望得到PNG图象的。
2、结果具体形式

? ? ? ? 单通道图片,加上调色板显示彩色。如图,背景的像素值为0,对应飞机的位置像素值为1,对应人的位置像素值等于15。灰度图片显示效果远不如调色板显彩效果。每个像素的数值对应了每个类别的索引。
三、评价指标与标注
1、评价指标
Pixel Accuracy(Global Acc)
?
- 在预测标签图像中所有预测正确的像素个数的总和除以这幅图片的总像素个数。?
mean Accuracy
?
- ?每个类别的Accuracy计算出来,再进行求和取平均操作。
mean IoU
?
- 计算每个类别的IoU,然后每个类别求平均操作。目标IoU交并比计算是将两个目标的交集面积比上两个目标的并集面积,公式的含义则是该类别的正确预测像素个数比上真实标签与预测像素的并集面积,并集计算过程为真实标签面积加上错误预测面积减去正确预测面积。?
notes:?
:类别
被预测成类别
的像素个数,如
为类别
:目标类别个数(包含背景)
:目标类别
?构建混淆矩阵进行计算
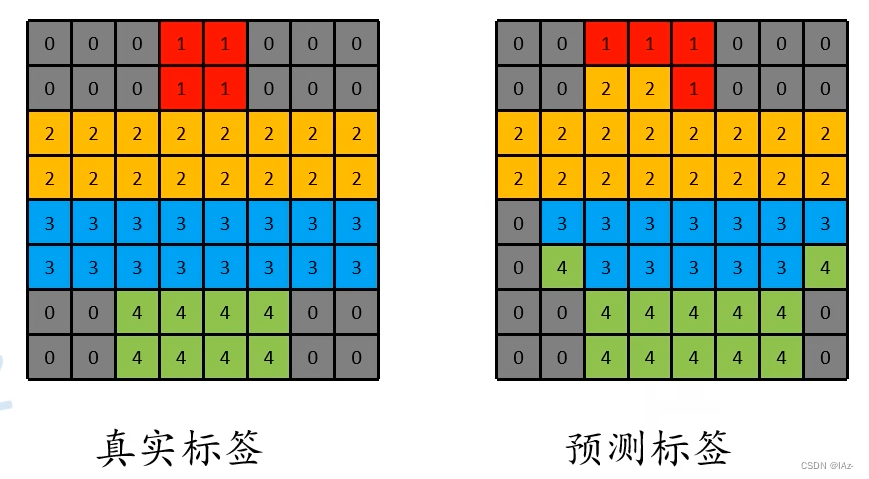

表示类别
表示类别
为类别0被预测为类别1的像素个数
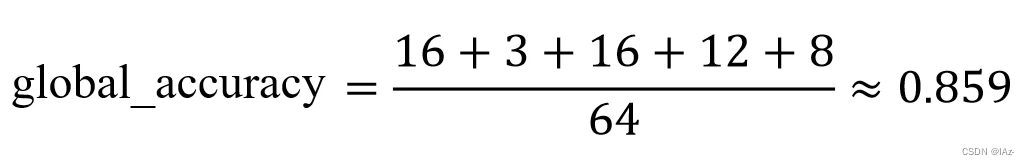

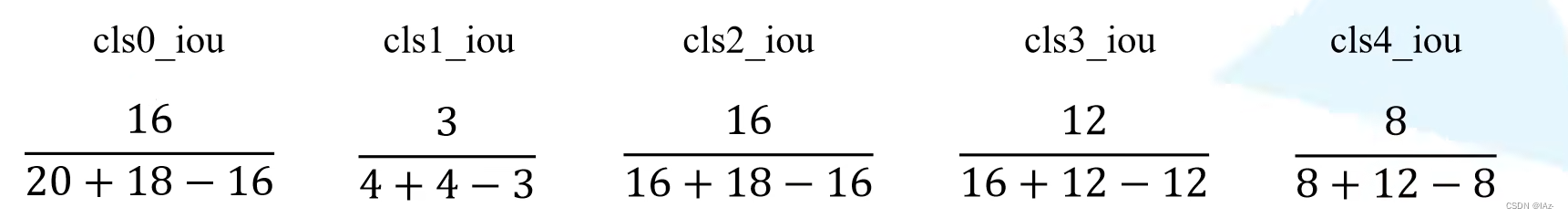
2、标注工具
Labelme?
EISeg?
ArcGis
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- elementui消息弹出框MessageBox英文内容不换行问题
- 京东年度数据报告-2023全年度打印机十大热门品牌销量(销额)榜单
- 【前后端的那些事】解放前端!10min快速上手人人代码生成器(前端篇)
- 力扣:300. 最长递增子序列(动态规划入门)
- 工业制造领域,折弯工艺如何进行优化?
- Function
- 基于Web的宠物医院信息管理系统论文
- 指针的学习
- 【INTEL(ALTERA)】Agilex7 FPGA Development Kit DK-DK-DEV-AGI027RBES 编程/烧录/烧写/下载步骤
- 如何积极管理日内伦敦银交易?