2023APMCM亚太数学建模C题 - 中国新能源汽车的发展趋势(3)
?六、问题三的模型建立和求解
6.1问题分析
问题3.收集数据,建立数学模型分析新能源电动汽车对全球传统能源汽车行业的影响。
本题要求建立模型分析新能源电动汽车对全球传统能源汽车行业的影响。由于数据集可能略大,而在处理复杂问题、大量特征和大规模数据集时神经网络,支持向量机算法,随机森林算法等均表现出色,考虑到当数据集中有多个特征,且特征之间的关系复杂时,随机森林处理效果更佳,故我们收集一定新能源汽车的相关信息作为自变量构建随机森林模型。
6.2特征选取
新能源汽车的发展对传统能源汽车的影响体现在许多方面,首先如果世界兴起去买新能源汽车,传统能源的发展速度就一定会受到一定阻碍,其次,目前来看,电能的成本远小于汽油,如果电能和汽油的差值持续相差许多,竞争结局的结果一定是朝向新能源汽车市场的,此外,随着一些国家的技术创新,新能源汽车的成本有可能进一步下降,这会传统能源市场带来巨大竞争力。
于是,我们根据第一问的结果选取新能源汽车的特征数据探究他们对传统能源汽车市场的影响,我们以新能源汽车所占的市场份额,平均售价,保有量等作为中国新能源汽车的特征数据,以传统能源汽车市场占有量,作为因变量,探究自变量对因变量的影响。
6.3随机森林的建立
随机森林的算法步骤如下:
STEP1:从原始样本中抽取训练集,每轮从原始样本中用Bootstraping的放法抽取n个训练样本(Bootstraping就是有放回的抽取样本)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
STEP2:每次使用一个数据集得到一个模型,k个训练集共得到k个模型。
STEP3:对分类问题,将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。
对于每个样本,如果它没有被用于训练,则将其作为 Out-of-Bag 样本。为进行更稳定的性能估计,我们对0到100棵决策树的 Out-of-Bag 错误率取平均进行统计,得到结果如下图所示。
??????? 
图10:Out-of-Bag图
在图中,我们发现当决策树的数量接近40的时候,性能更稳定一些。所以我们随机森林参数中的Number of grown trees取40。
我们设置的随机森林模型参数如下表所示:
表8:随机森林的参数选取
| 参数名 | 参数值 |
| 训练用时 | 0.151s |
| 数据切分 | 0.81 |
| 数据洗牌 | 否 |
| 交叉验证 | 否 |
| 节点分裂评价准则 | MSE |
| 划分时考虑的最大特征比例 | NONE |
| 有放回采样 | TRUE |
| 决策树数量 | 94 |
| 叶子节点的最小样本数 | 1 |
| 内部节点分裂的最小样本数 | 2 |
| 树的最大深度 | 9 |
| 叶子节点的最大数量 | 46 |
6.4模型求解
由于随机森林的求解包含多个“决策树”的继承,这里我们以传统燃油车市场份额为因变量,其余的新能源汽车相关数据作为自变量构建“决策树”,求解特征重要性结果如下表所示。
表9:决策树特征重要性结果表
| 指标 | 新能源汽车保有量比传统燃油车保有量 | 新能源汽车市场占有率(%) | 新能源汽车市场渗透率(%) | 电能价格(元/升) | 电动车充电成本(元/千瓦时) | 电动车平均价格(万元) | 燃油车平均价格(万元) |
| 特征重要性 | 0.1426888 | 0.127854 | 0.1625604 | 0.1012 | 0.1079523 | 0.156782 | 0.100157 |
| 378945 | 680453 | 964202 | 561871 | 294388 | 490854 | 531008 |
| 新能源汽车能源效率(公里/千万时) | 燃油车能源效率(公里/升) | 新能源汽车产业链规模(家) | 新能源汽车市场规模(万辆) | 新能源汽车企业数量(家) | 新能源汽车专利申请数量(件) | 新能源车政府补贴金额(亿元人民币) | 新能源汽车充电桩数量(万个) |
| 0.124891 | 0.105034 | 0.153489 | 0.101003 | 0.1010057 | 0.129521 | 0.1593752 | 0.155321 |
| 359201 | 501821 | 579125 | 541831 | 539812 | 845613 | 549880 | 210397 |
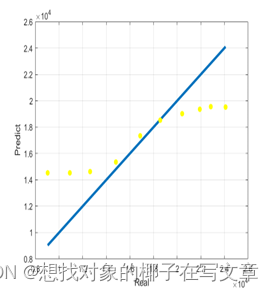

上面两张图展示了模拟拟合图和重要特征性,我们可以看出本次拟合结果良,其中对全球传统新能源汽车影响最大的因素显而易见,是新能源汽车政府政策补贴金额,由此可以推断中国新能源汽车市场展现出蓬勃生机的原因之一便是政府的大力支持。
七.第四题模型建立和求解
7.1第四小题问题分析
问题四是建立模型分析世界上一些国家一系列的针对抵制中国新能源电动汽车发展的政策对中国新能源电动汽车的发展的影响。我们首先收集了世界上一些代表性大国对中国新能源汽车发展的抵制政策,然后以中国新能源汽车的保有量作为目标变量,然后收集了美国,日本两个国家的进口以及海关边税作为自变量,构建岭回归模型进行影响机理分析。
7.2数据分析
在这里,我们收集了一些发达国家的政策,具体政策如下表所示:
表10:发达国家新能源相关政策表
| 国家 | 新能源汽车财政补贴、税收优惠政策 |
| 美国 | 2021 年通过拜登 1.75 万亿美元刺激法案, 新能源税收抵免由 7500 美元提升至最高 1.25 万美元, 为充电设施研发提供 3400 万美元新资金, 增加 419 亿美元的联邦赠款资金用于电动汽车充电桩基础设施。 |
| 日本 | 规划到 2035 年, 销售的新车 100% 将为电动化车辆, 对于纯电动汽车最高补贴金额由 40 万日元提升至 80 万日元, 插电式混合动力车最高补贴金额由 20 万日元提升至 40 万日元, 燃料电池车最高补贴金额由 225 万日元提升至 250 万日元。? |
| 韩国 | 计划到 2025 年使新能源汽车售价下降至少 1000 万韩元, 延长汽车特别消费税税率下调政策的实施期限。引进动力电池租赁服务, 大幅减轻买车负担。 |
| 法国 | 2020 年 6 月- 2021 年 7 月, 发放超 80 亿欧元的购车补贴, 并给予每车 5000 欧元的置换补贴; 法国境内有 4.37 万个公共充电桩, 415 条高速公路中已经有一半以上装备了充电桩。 |
| 德国 | 2020年下半年支付 5.75 亿欧元补贴, 增长 7 倍。11 月出台对安装充电桩的用户提供 900 欧元的补贴政策。2021 年 6 月,支付 13.3 亿欧元补贴, 7 月宣布新能源汽车补贴政策延长至 2025 年底, 电动车的 10 年税收减免延长至 2030 年,同时享受每年道路税的?免。 |
通过对以上数据分析可以发现大多数国家的的体制政策中抵制新能源汽车发展的部分大多都是针对我国的进口关税和还有国家本地的优惠福利等。
较低的进口关税可以降低新能源汽车进入目标市场的门槛,能极大的提高商品的成本竞争力,且与改善贸易平衡和促进国际合作息息相关。
考虑到国家本地的优惠福利和国家经济稳定息息相关,于是这里我们考虑用债券利率作为衡量他的一个指标,本地的优惠福利与债券利率的关系体现在政府的财政支出方面。如果政府决定大力支持新能源汽车产业,可能需要增加财政支出。为了筹集这些资金,政府可能会通过发行债券等方式进行融资。债券利率的高低会影响到政府融资的成本,进而影响到政府的财政状况和支持新能源汽车政策的能力。
于是我们针对美国,日本,法国的进口关税和国家债券利率以及进口指数进行了相关统计。
表11:外国进口关税和进口指数表
| 年份 | 美国进口指数 | 美国通用关税税率 |
| 2013 | 88.68 | 3.03 |
| 2014 | 89.35 | 2.99 |
| 2015 | 93.55 | 2.87 |
| 2016 | 100 | 2.93 |
| 2017 | 100.51 | 2.8 |
| 2018 | 104.53 | 2.76 |
| 2019 | 110.07 | 3.36 |
| 2020 | 109.48 | 3.25 |
| 2021 | 105.23 | 8.7 |
| 2022 | 117.93 | 2.87 |
| 年份 | 日本进口指数 | 日本通用关税税率 |
| 2013 | 95.33 | 2.33 |
| 2014 | 95.75 | 2.31 |
| 2015 | 97.31 | 3.51 |
| 2016 | 100 | 3.52 |
| 2017 | 100.84 | 3.69 |
| 2018 | 103.57 | 3.77 |
| 2019 | 105.56 | 3.77 |
| 2020 | 106.13 | 3.8 |
| 2021 | 102.08 | 3.84 |
| 2022 | 104.55 | 5.91 |
| 年份 | 德国进口指数 | 德国通用关税税率 |
| 2013 | 93.4 | 2.3 |
| 2014 | 93.85 | 2.28 |
| 2015 | 96.68 | 2.21 |
| 2016 | 100 | 2.76 |
| 2017 | 102.56 | 2.73 |
| 2018 | 105.34 | 2.48 |
| 2019 | 107.52 | 2.48 |
| 2020 | 106.47 | 2.46 |
| 2021 | 99.9 | 2.55 |
| 2022 | 106.41 | 1.71 |
7.3岭回归模型
考虑到本题选取了美国,日本,德国各自的进口关税,债券利率和进口指数三个指标作为自变量分析,而将新能源汽车的保有量作为因变量,当存在多个高度相关的自变量,即解决多重共线性问题的线性回归问题时,可以采用Lasso回归和岭回归模型,而又因为Lasso回归模型在较长时间的拟合误差较大的问题,所以我们采用岭回归模型。
岭回归(Ridge Regression)是一种用于处理多重共线性(multicollinearity)问题的线性回归技术。多重共线性是指自变量之间存在高度相关性的情况,这可能导致线性回归模型的不稳定性和系数估计的不准确性。岭回归通过引入正则化项,可以在保持模型简单性的同时,对系数进行约束,有助于应对多重共线性的问题。
一般来说,回归分析的方程形式如下:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
?
求解这个方程的方法之一时使用最小二乘法,通过最小化观测值与模型预测值之间的残差平方和来估计模型的参数,目标是最小化下面的式子
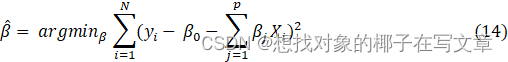
而在上述的式子中加入一个“惩罚项”后,就生成了岭回归的方程式
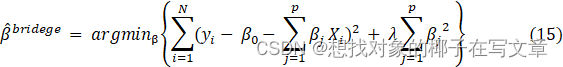
7.4 模型求解结果
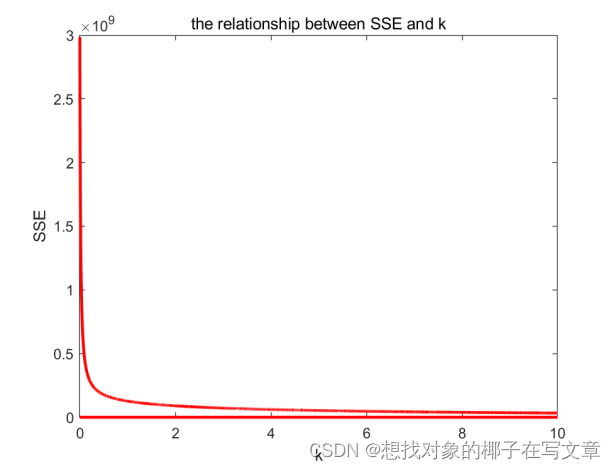
STEP1:首先为了观察自变量之间是否有共线性关系,我们进行了自变量指标的散点分布矩阵图的绘制,结果如下图所示。
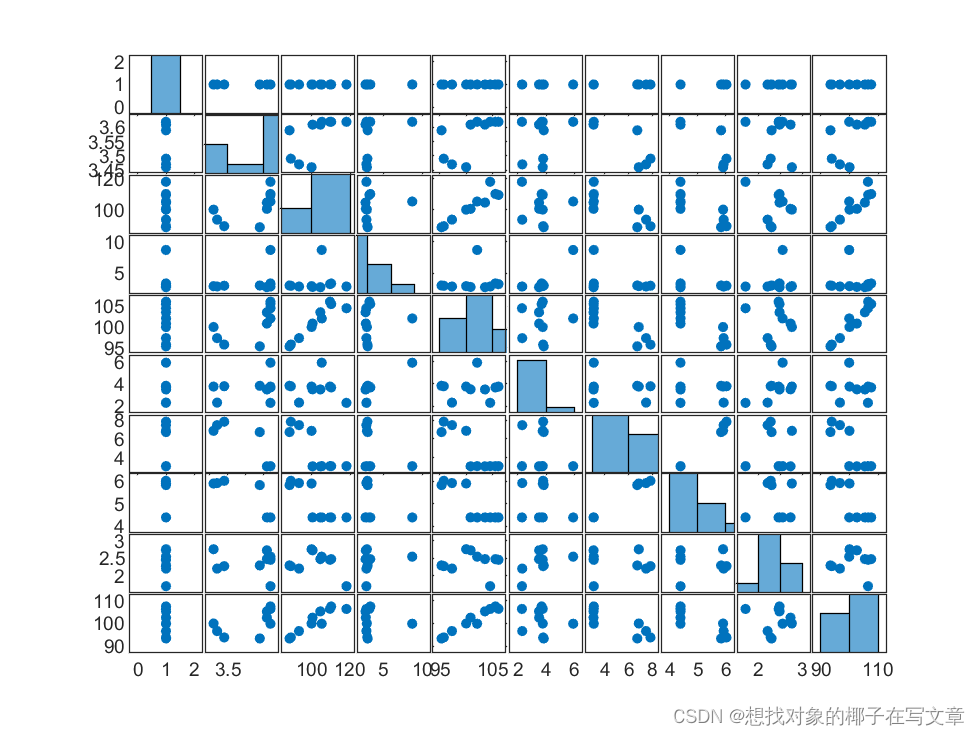
图11:散点分布矩阵图
 ??
??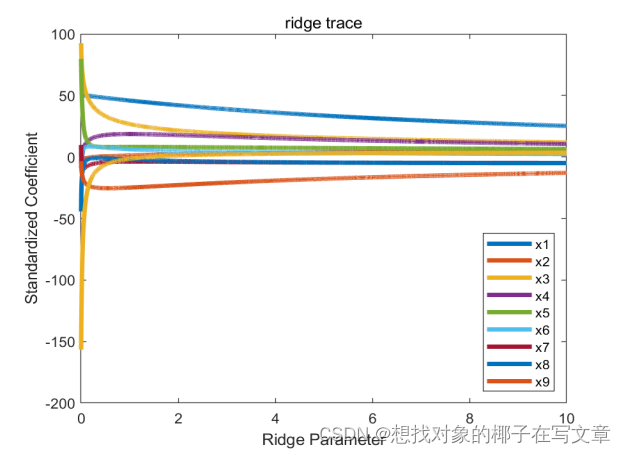
图12:岭迹图??????????? 图13:不同的K值残差平方和图
图16是岭迹图,从图中我们可以得到不同自变量之间的标准化系数趋于稳定时的情况。
图17是通过K-means聚类方法得到的不同的K值残差平方和图,由图可得,当SSE的值最小时对应的K值就是我们岭回归参数中中K的取值,用方差扩大因
子法处理之后,可得K = 0.12。
STEP2:接下来以美国的债券指标和美国的进口指数和得到的参数对模型进行拟合分析,以确定结果的稳定性和准确性,得到结果如下图所示。
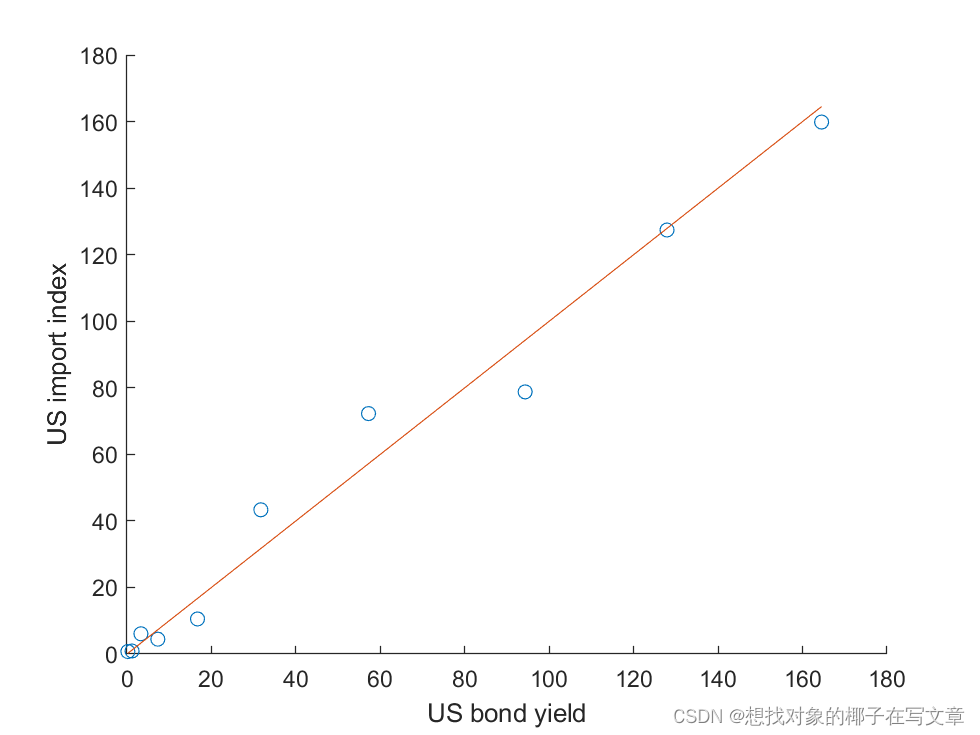
图14:岭模型的拟合效果图?
STEP3:由于拟合效果较好,所以我们接下来进一步用正规方程法提取岭回归模型中所有自变量的回归系数。
表12:岭回归模型回归系数表
| K = 0.12 | 常数 | 美国债券利率 | 美国进口指数 | 美国通用关税税率 | 日本进口指数 | 日本通用关税税率 | 日本债券利率 | 德国债券利率 | 德国通用关税税率 | 德国进口指数 |
| 回归系数 | -87.8 | 49.88 | -14.65 | 5.36 | 6.46 | 3.5 | 8.4 | -3.55 | -3.32 | -74.17 |
STEP4:在得到各变量的回归结果后,我们就可以进一步对因变量进行处理,得到结果如下:
新能源汽车保有量 = -87.8 + (各自变量10年均值×对应回归系数求和)。
从表12可以看出,与德国相关的系数大多数为负数,这就说明新能源汽车在德国收到的抵制效果相对明显,而其他两国美国和日本,系数虽未正,但值很小,说明该两国虽然不抵制,但也并无有效的促进政策得以实施。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Beyond Compare 4 代码对比如何重新激活使用30天
- Requests教程-5-发送post请求
- Odrive 学习系列四:如何使用脚本自动初始化odrive配置
- android 13.0 Launcher3长按拖拽时,获取当前是哪一屏,获取当前多少个应用图标
- 编程笔记 html5&css&js 017 HTML样式
- 比较 Redisson 和 Curator:分布式锁实现
- (2023|CVPR,Corgi,偏移扩散,参数高斯分布,弥合差距)用于文本到图像生成的偏移扩散
- Ontrack EasyRecovery2024恢复软件最新版本有哪些新功能特色?
- 使用 Goroutine 和 Channel 来实现更复杂的并发模式,如并发任务执行、并发数据处理,如何做?
- CMMI评估认证,引领行业潮流!