hw03-食物图像识别-simple
发布时间:2023年12月21日





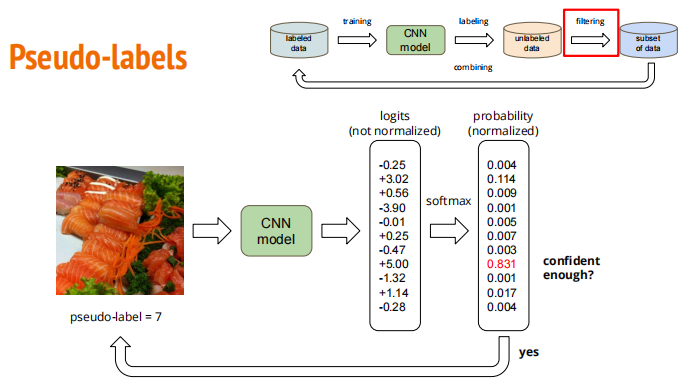
# Import necessary packages.
import numpy as np
import pandas as pd
import torch
import os
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
# "ConcatDataset" and "Subset" are possibly useful when doing semi-supervised learning.
from torch.utils.data import ConcatDataset, DataLoader, Subset, Dataset
from torchvision.datasets import DatasetFolder, VisionDataset
# This is for the progress bar.
from tqdm.auto import tqdm
import random
myseed = 6666 # set a random seed for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(myseed)
torch.manual_seed(myseed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(myseed)
_exp_name = "sample"
Transformer
Torchvision provides lots of useful utilities for image preprocessing, data wrapping as well as data augmentation.
Please refer to PyTorch official website for details about different transforms.
# Normally, We don't need augmentations in testing and validation.
# All we need here is to resize the PIL image and transform it into Tensor.
test_tfm = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor(),
])
# However, it is also possible to use augmentation in the testing phase.
# You may use train_tfm to produce a variety of images and then test using ensemble methods
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.Resize((128,128)),
# You may add some transforms he|re.
# ToTensor() should be the last one of the transforms.
transforms.ToTensor()
]
)
Datasets
The data is labelled by the name, so we load images and label while calling ‘getitem’
class FoodDataset(Dataset):
def _init__(self,path,tfm=test_tfm,files=None):
super(FoodDataset).__init__()
self.path = path
self.files = sorted([os.path.join(path,x) for x in os.listdir(path) if x.endwith(".jpg")])
if files != None:
self.files = files
print(f"One {path} sample",self.files[0])
self.tramsform = tfm
def __len__(self):
return len(self.files)
def __getitem__(self,idx):
fname = self.files[idx]
im = Image.open(fname)
im = self.transform(im)
try:
label = int(fname.split("/"))[-1].split('_')[0]
except:
label = -1 # test has no label
return im,label
class FoodDataset(Dataset):
def __init__(self,path,tfm=test_tfm,files = None):
super(FoodDataset).__init__()
self.path = path
self.files = sorted([os.path.join(path,x) for x in os.listdir(path) if x.endswith(".jpg")])
if files != None:
self.files = files
print(f"One {path} sample",self.files[0])
self.transform = tfm
def __len__(self):
return len(self.files)
def __getitem__(self,idx):
fname = self.files[idx]
im = Image.open(fname)
im = self.transform(im)
#im = self.data[idx]
try:
label = int(fname.split("/")[-1].split("_")[0])
except:
label = -1 # test has no label
return im,label
class Classfier(nn.Module):
def __init__(self):
super(Classfier,self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3,64,3,1,1), #[64,128,128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2,2,0), # [64,64,64]
nn.Conv2d(64,128,3,1,1), # [128,64,64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2,2,0), # [128,32,32]
nn.Conv2d(128,256,3,1,1), # [256,32,32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2,2,0), # [256,16,16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512*4*4,1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self,x):
out = self.cnn(x)
out = out.view(out.size()[0],-1) # ? can be replaced by flatten ?
return self.fc(out)
batch_size = 64
_dataset_dir = "./food11"
# construct datasets
# The argument "loader" tells how torchvision reads the data
train_set = FoodDataset(os.path.join(os.getcwd(),_dataset_dir,"training/"), tfm=train_tfm)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
valid_set = FoodDataset(os.path.join(_dataset_dir,"validation"), tfm=test_tfm)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
One /home/puniu/xuxiu/LIHYAI/2022_hw3/./food11/training/ sample /home/puniu/xuxiu/LIHYAI/2022_hw3/./food11/training/0_0.jpg
One ./food11/validation sample ./food11/validation/0_0.jpg
batch_size = 64
_dataset_dir = "./food11"
# construct datasets
# The argument "loader" tells how torchvision reads the data
train_set = FoodDataset(os.path.join(_dataset_dir,"training/"), tfm=train_tfm)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
valid_set = FoodDataset(os.path.join(_dataset_dir,"validation"), tfm=test_tfm)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
One ./food11/training/ sample ./food11/training/0_0.jpg
One ./food11/validation sample ./food11/validation/0_0.jpg
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
n_epochs = 4
patience = 300
model = Classfier().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.0003,weight_decay=1e-5)
stale = 0
best_acc = 0
for epoch in range(n_epochs):
model.train()
train_loss = []
train_accs = []
for batch in tqdm(train_loader):
imgs,labels = batch
# Forward data. Make sure data and model are on the same device
logits = model(imgs.to(device))
# calculate the cross-entrophy
loss = criterion(logits,labels.to(device))
optimizer.zero_grad()
loss.backward()
grad_norm = nn.utils.clip_grad_norm_(model.parameters(),max_norm=10)
optimizer.step()
acc = (logits.argmax(dim=-1) == labels.to(device)).float().mean()
train_loss.append(loss.item())
train_accs.append(acc)
train_loss = sum(train_loss)/len(train_loss)
train_acc = sum(train_accs)/len(train_accs)
print(f"[ Train | {epoch + 1:03d}/{n_epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")
# ---------- Validation ----------
# Make sure the model is in eval mode so that some modules like dropout are disabled and work normally.
model.eval()
valid_loss = []
valid_accs = []
for batch in tqdm(valid_loader):
imgs,labels = batch
with torch.no_grad():
logits = model(imgs.to(device))
loss = criterion(logits, labels.to(device))
# Compute the accuracy for current batch.
acc = (logits.argmax(dim=-1) == labels.to(device)).float().mean()
# Record the loss and accuracy.
valid_loss.append(loss.item())
valid_accs.append(acc)
#break
# The average loss and accuracy for entire validation set is the average of the recorded values.
valid_loss = sum(valid_loss) / len(valid_loss)
valid_acc = sum(valid_accs) / len(valid_accs)
# Print the information.
print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
# update logs
if valid_acc > best_acc:
with open(f"./{_exp_name}_log.txt","a"):
print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f} -> best")
else:
with open(f"./{_exp_name}_log.txt","a"):
print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
# save models
if valid_acc > best_acc:
print(f"Best model found at epoch {epoch}, saving model")
torch.save(model.state_dict(), f"{_exp_name}_best.ckpt") # only save best to prevent output memory exceed error
best_acc = valid_acc
stale = 0
else:
stale += 1
if stale > patience:
print(f"No improvment {patience} consecutive epochs, early stopping")
break
0%| | 0/155 [00:00<?, ?it/s]
[ Train | 001/004 ] loss = 1.88524, acc = 0.34442
0%| | 0/54 [00:00<?, ?it/s]
[ Valid | 001/004 ] loss = 1.66863, acc = 0.41609
[ Valid | 001/004 ] loss = 1.66863, acc = 0.41609 -> best
Best model found at epoch 0, saving model
0%| | 0/155 [00:00<?, ?it/s]
[ Train | 002/004 ] loss = 1.55749, acc = 0.46121
0%| | 0/54 [00:00<?, ?it/s]
[ Valid | 002/004 ] loss = 1.64495, acc = 0.44732
[ Valid | 002/004 ] loss = 1.64495, acc = 0.44732 -> best
Best model found at epoch 1, saving model
0%| | 0/155 [00:00<?, ?it/s]
[ Train | 003/004 ] loss = 1.35729, acc = 0.52966
0%| | 0/54 [00:00<?, ?it/s]
[ Valid | 003/004 ] loss = 1.65936, acc = 0.46634
[ Valid | 003/004 ] loss = 1.65936, acc = 0.46634 -> best
Best model found at epoch 2, saving model
0%| | 0/155 [00:00<?, ?it/s]
[ Train | 004/004 ] loss = 1.19824, acc = 0.58109
0%| | 0/54 [00:00<?, ?it/s]
[ Valid | 004/004 ] loss = 1.36239, acc = 0.54997
[ Valid | 004/004 ] loss = 1.36239, acc = 0.54997 -> best
Best model found at epoch 3, saving model
Test
test_set = FoodDataset(os.path.join(_dataset_dir,"test"), tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
One ./food11/test sample ./food11/test/0001.jpg
model_best = Classfier().to(device)
model_best.load_state_dict(torch.load(f"{_exp_name}_best.ckpt"))
model_best.eval()
prediction = []
with torch.no_grad():
for data,_ in test_loader:
test_pred = model_best(data.to(device))
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
prediction += test_label.squeeze().tolist()
#create test csv
def pad4(i):
return "0"*(4-len(str(i)))+str(i)
df = pd.DataFrame()
df["Id"] = [pad4(i) for i in range(1,len(test_set)+1)]
df["Category"] = prediction
df.to_csv("submission.csv",index = False)
文章来源:https://blog.csdn.net/weixin_39107270/article/details/135136266
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- fastadmin学习02-修改后台管理员账号密码
- 基于ssm的劳务外包管理系统论文
- 文献分享四:(基础)Pyroelectric drift of integrated-optical LiNbO3 modulators
- MATLAB - 为机械臂路径选择轨迹
- 关于网络模型的笔记
- 山西电力市场日前价格预测【2024-01-24】
- 【远程计算机,这可能是由于 Credssp 加客数据库修正】解决方案
- 什么是功能测试?原因、方式和类型
- Poe 和 ChatGPT 有何分別,可以平替吗?
- 直接通过像素读取图片内容返回结果