PyTorch Tutorial 2.0
这里是对于PyTorch Tutorial-CSDN博客的补充,但是与其相关的NLP内容无关,只是一些基础的PyTorch用法的记录,主要目的是能够自己生成一些模拟的数据集。先介绍随机数的目的是因为based on随机数方法。
当然在看随机数的方法的时候,觉得也有必要对统计学方法进行一个总结,也许在不久的将来吧:))
随机数
本节包含:normal、bernoulli、multinomial、poisson、rand、randn、randint、rand_like、randint_like、randn_like、randperm、seed、manual_seed、initial_seed
normal
正态分布。什么是正态分布?
一文搞懂“正态分布”所有需要的知识点 - 知乎 (zhihu.com)
如果我们各取一字变为“正常分布”,就很白话了,而这正是“正态分布”的本质含义,Normal Distribution。它太常见了,基本上能描述所有常见的事物和现象:正常人群的身高、体重、考试成绩、家庭收入等等。这里的描述是什么意思呢?就是说这些指标背后的数据都会呈现一种中间密集、两边稀疏的特征。以身高为例,服从正态分布意味着大部分人的身高都会在人群的平均身高上下波动,特别矮和特别高的都比较少见。
PyTorch文档:torch.normal — PyTorch 2.1 documentation
首先,先看例子:
import torch
randmat1 = torch.normal(mean=torch.arange(1., 11.), std=torch.arange(1, 0, -0.1))
print('random # from separate normal distribution, size = 10x1: \n{}'.format(randmat1))
randmat2 = torch.normal(mean=0.5, std=torch.arange(1., 6.))
print('random # from separate normal distribution, size = 5x1: \n{}'.format(randmat2))
randmat3 = torch.normal(mean=torch.rand((2, 3)), std=torch.randint(1,10, (2, 3)))
print('random # from separate normal distribution, size = 2x3: \n{}'.format(randmat3))
randmat4 = torch.normal(mean=torch.rand((2, 5, 3)), std=torch.randint(1,20, (2, 5, 3)))
print('random # from separate normal distribution, size = 5x3x2: \n{}'.format(randmat4))
print('\ntorch.arange(1, 0, -0.1): {}'.format(torch.arange(1, 0, -0.1)))
random # from separate normal distribution, size = 10x1:
tensor([ 1.6991, 0.1268, 1.4137, 3.6513, 4.8708, 6.3970, 7.2918, 7.9855,
8.6577, 10.1725])
random # from separate normal distribution, size = 5x1:
tensor([ 3.4052, -1.5300, -0.0505, 1.5723, -5.3387])
random # from separate normal distribution, size = 2x3:
tensor([[ 3.7323, 1.4971, 2.4993],
[ 1.8528, 13.7850, -7.3867]])
random # from separate normal distribution, size = 5x2x3:
tensor([[[ 2.9947, -11.1519, -1.9256],
[ 10.4225, 14.2182, -7.3297],
[ 8.6169, -0.3921, -4.4008],
[ 1.1487, 25.4888, -3.8014],
[ -0.3186, -27.3557, 10.4733]],
[[ 13.8811, -1.0995, 17.7056],
[ -1.5848, -4.5089, -2.9512],
[-12.1184, 13.2905, 7.7889],
[-11.9025, 6.5581, -0.3579],
[ 16.1341, 9.5634, -8.7593]]])
torch.arange(1, 0, -0.1): tensor([1.0000, 0.9000, 0.8000, 0.7000, 0.6000, 0.5000, 0.4000, 0.3000, 0.2000,
0.1000])
返回一个随机数字的张量,这些随机数是从单独的正态分布中抽取的,这些正态分布的平均值和标准差都是给定的。
均值(Tensor):每个输出元素正态分布的均值
标准差(Tensor):每个输出元素正态分布的标准差
bernoulli
伯努利分布:
R统计学(01): 伯努利分布、二项分布 - 知乎 (zhihu.com)
在现实生活中,许多事件的结果往往只有两个。例如:抛硬币,正面朝上的结果只有两个:国徽或面值;检查某个产品的质量,其结果只有两个:合格或不合格;购买彩票,开奖后,这张彩票的结果只有两个:中奖或没中奖;拨打女朋友电话:接通或没接通。。。以上这些事件都可被称为伯努利试验。
PyTorch文档:torch.bernoulli — PyTorch 2.1 documentation
先看例子:
import torch
randmat1 = torch.bernoulli(torch.ones(3, 3))
print('random (0, 1) from Bernoulli distribution, size = 3x3: \n{}'.format(randmat1))
randmat2 = torch.bernoulli(torch.ones(3, 2, 5))
print('random (0, 1) from Bernoulli distribution, size = 2x5x3: \n{}'.format(randmat2))
randmat3 = torch.bernoulli(torch.rand((5,)))
print('random (0, 1) from Bernoulli distribution, size = 5x1: \n{}'.format(randmat3))
randmat4 = torch.bernoulli(torch.rand((2, 5, 3)))
print('random (0, 1) from Bernoulli distribution, size = 5x3x2: \n{}'.format(randmat4))
random (0, 1) from Bernoulli distribution, size = 3x3:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
random (0, 1) from Bernoulli distribution, size = 2x5x3:
tensor([[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]]])
random (0, 1) from Bernoulli distribution, size = 5x1:
tensor([0., 1., 1., 1., 1.])
random (0, 1) from Bernoulli distribution, size = 5x3x2:
tensor([[[0., 1., 0.],
[0., 1., 1.],
[0., 1., 1.],
[0., 0., 1.],
[1., 1., 0.]],
[[1., 1., 1.],
[0., 1., 0.],
[1., 0., 1.],
[0., 1., 1.],
[0., 0., 0.]]])
返回0or1,伯努利分布。
要求输入是Tensor,Tensor中的每个位置代表了分布所使用的概率(说明这里不能>1or<0)
multinomial
Pytorch小抄:multinominal采样函数 - 知乎 (zhihu.com)
根据给定权重对数组进行多次采样,返回采样后的元素下标。
PyTorch文档:torch.multinomial — PyTorch 2.1 documentation
先看例子:
import torch
randmat1 = torch.multinomial(torch.Tensor([0.2, 0.3, 0.1, 0.4]), 2)
print('random # by weights from multinomial probability distribution, size = 2x1: \n{}'.format(randmat1))
randmat2 = torch.multinomial(torch.Tensor([12, 2, 8, 11, 13]), 2)
print('random # by frequency from multinomial probability distribution, size = 2x1: \n{}'.format(randmat2))
randmat3 = torch.multinomial(torch.Tensor([
[0, 0.3, 0.7],
[0.3, 0.7, 0]
]), 2, replacement = True)
print('random # with replacement from multinomial probability distribution, size = 2x2: \n{}'.format(randmat3))
randmat4 = torch.multinomial(torch.rand((3, 5)), 2)
print('random # from multinomial probability distribution, size = 2x3: \n{}'.format(randmat4))
random # by weights from multinomial probability distribution, size = 2x1:
tensor([3, 1])
random # by frequency from multinomial probability distribution, size = 2x1:
tensor([0, 3])
random # with replacement from multinomial probability distribution, size = 2x2:
tensor([[2, 2],
[0, 1]])
random # from multinomial probability distribution, size = 2x3:
tensor([[1, 4],
[0, 1],
[1, 2]])
根据给定权重对数组进行多次采样,返回采样后的元素下标。看起来不是很好理解,看一下randmat2,这里就是给了一排数字,然后要求采样,采样个数是2,(不规定的话都是不放回的采样,也就是不会重复抽中同一个),这里抽中的就是index=0,3。在randmat3中可以看到加了replacement,第一行抽样的时候就抽出来两个2。
另外也要注意,这里抽样的个数必须小于行内的元素个数。
poisson
泊松分布。什么是泊松分布?
泊松分布(Poisson distribution) - 知乎 (zhihu.com)
PyTorch文档:torch.poisson — PyTorch 2.1 documentation
泊松分布适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数,电话交换机接到呼叫的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数、DNA序列的变异数、放射性原子核的衰变数、激光的光子数分布等等。
先看例子:
import torch
randmat1 = torch.poisson(torch.rand((5,)))
print('random # from Poisson distribution, size = 5x1: \n{}'.format(randmat1))
randmat2 = torch.poisson(torch.rand((3, 5)))
print('random # from Poisson distribution, size = 3x5: \n{}'.format(randmat2))
randmat3 = torch.poisson(torch.rand((3, 5))*4)
print('random # from Poisson distribution, size = 3x5: \n{}'.format(randmat3))
randmat4 = torch.poisson(torch.rand((2, 5, 3)))
print('random # from Poisson distribution, size = 5x3x2: \n{}'.format(randmat4))
random # from Poisson distribution, size = 5x1:
tensor([2., 1., 0., 0., 0.])
random # from Poisson distribution, size = 3x5:
tensor([[3., 0., 0., 1., 1.],
[1., 0., 0., 1., 0.],
[0., 3., 0., 0., 0.]])
random # from Poisson distribution, size = 3x5:
tensor([[ 2., 0., 1., 0., 1.],
[ 2., 5., 1., 1., 0.],
[ 2., 5., 10., 4., 2.]])
random # from Poisson distribution, size = 5x3x2:
tensor([[[3., 0., 0.],
[1., 2., 0.],
[1., 0., 0.],
[0., 0., 1.],
[0., 1., 0.]],
[[1., 0., 0.],
[1., 0., 0.],
[0., 1., 3.],
[0., 0., 1.],
[0., 0., 0.]]])
返回与输入相同大小的张量,其中每个元素从泊松分布中采样。
rand
均匀分布。什么是均匀分布?
轻松搞懂均匀分布、高斯分布、瑞利分布、莱斯分布(含MATLAB代码)_莱斯分布参数-CSDN博客
在概率论和统计学中,均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的。 均匀分布由两个参数a和b定义,它们是数轴上的最小值和最大值,通常缩写为U(a,b)。
举个例子,掷骰子就是一个均匀分布,概率论中一个很常用分布。?
PyTorch文档:torch.rand — PyTorch 2.1 documentation
先看例子:
import torch
randmat1 = torch.rand((5,))
print('random # between 0~1, size = 5x1: \n{}'.format(randmat1))
randmat2 = torch.rand((5, 2))
print('random # between 0~1, size = 5x2: \n{}'.format(randmat2))
randmat3 = torch.rand((5, 2, 3))
print('random # between 0~1, size = 5x2x3: \n{}'.format(randmat3))
random # between 0~1, size = 5x1:
tensor([0.5519, 0.5765, 0.1931, 0.1176, 0.4503])
random # between 0~1, size = 5x2:
tensor([[0.5004, 0.0666],
[0.2678, 0.7157],
[0.4731, 0.6699],
[0.0438, 0.3714],
[0.1693, 0.7547]])
random # between 0~1, size = 5x2x3:
tensor([[[0.9698, 0.8137, 0.4986],
[0.5466, 0.1063, 0.6841]],
[[0.1904, 0.0203, 0.9359],
[0.9789, 0.4542, 0.9193]],
[[0.2009, 0.3308, 0.5143],
[0.7144, 0.4449, 0.8133]],
[[0.9602, 0.9726, 0.3021],
[0.9982, 0.5359, 0.5535]],
[[0.3467, 0.2626, 0.1181],
[0.1847, 0.7154, 0.9336]]])
输入:尺寸,在上述例子中尺寸采用的是tuple形式,这里也可以直接用数字或者list,得到的结果是一样的。比如:
randmat3 = torch.rand(5, 2, 3)
print('random # between 0~1, size = 5x2x3: \n{}'.format(randmat3))?可以得到尺寸相同的结果(当然由于是random,这里值肯定不一样了)。
返回一个在区间[0, 1)上均匀分布的随机数填充的Tensor。
randn
PyTorch文档:torch.randn — PyTorch 2.1 documentation
import torch
randmat1 = torch.randn((5,))
print('random # from standard normal distribution, size = 5x1: \n{}'.format(randmat1))
randmat2 = torch.randn((5, 2))
print('random # from standard normal distribution, size = 5x2: \n{}'.format(randmat2))
randmat3 = torch.randn((5, 2, 3))
print('random # from standard normal distribution, size = 5x2x3: \n{}'.format(randmat3))
random # from standard normal distribution, size = 5x1:
tensor([0.3987, 2.0789, 1.0601, 0.6458, 1.8633])
random # from standard normal distribution, size = 5x2:
tensor([[-1.3455, -0.0239],
[ 0.1014, -0.2797],
[-0.4648, -0.8710],
[ 2.3227, 0.0700],
[-0.1368, 1.1718]])
random # from standard normal distribution, size = 5x2x3:
tensor([[[-1.4921, -0.4009, 0.5712],
[-0.7376, 1.4972, 0.9918]],
[[ 0.6887, -0.3278, 0.3653],
[ 2.0750, 0.0713, 0.1487]],
[[-0.2964, 2.2312, -0.2235],
[-1.1455, 0.1765, 1.1348]],
[[-0.9339, -0.4845, 0.5840],
[-0.0384, -0.0624, 0.5701]],
[[ 1.9086, -0.3426, -1.3153],
[-1.0366, -0.0710, -0.1452]]])
randint?
PyTorch文档:torch.randint — PyTorch 2.1 documentation
先看例子:?
import torch
randmat1 = torch.randint(1, 255, (5,))
print('random int between 1~255, size = 5x1: \n{}'.format(randmat1))
randmat2 = torch.randint(1, 255, (5, 2))
print('random int between 1~255, size = 5x2: \n{}'.format(randmat2))
randmat3 = torch.randint(1, 255, (5, 2, 3))
print('random int between 1~255, size = 5x2x3: \n{}'.format(randmat3))
random int between 1~255, size = 5x1:
tensor([161, 40, 140, 212, 183])
random int between 1~255, size = 5x2:
tensor([[128, 37],
[ 45, 127],
[237, 7],
[ 77, 166],
[209, 22]])
random int between 1~255, size = 5x2x3:
tensor([[[ 73, 116, 79],
[100, 27, 2]],
[[174, 49, 11],
[116, 66, 4]],
[[ 49, 10, 52],
[167, 51, 154]],
[[170, 86, 107],
[208, 79, 181]],
[[ 50, 121, 29],
[ 30, 38, 192]]])
输入三个参数,最低的整数(可选,default为0),最高的整数(注意这里和Python其他的范围类似,是不包含的关系,也就是如果想要取到255,那么最高的整数就得设为256),Tensor的尺寸。
返回一个张量,其中充满在low(包含)和high(不包含)之间均匀生成的随机整数。
rand_like
返回一个与输入大小相同的张量,该张量由区间[0,1)上均匀分布的随机数填充。
均匀分布。什么是均匀分布?
均匀分布(定义、期望、方差) - 知乎 (zhihu.com)

PyTorch文档:torch.rand_like — PyTorch 2.1 documentation
先看例子:
import torch
randmat1 = torch.rand_like(torch.rand((5,)))
print('random # in [0, 1) from uniform distribution, size = 5x1: \n{}'.format(randmat1))
randmat2 = torch.rand_like(torch.rand((3, 5)))
print('random # in [0, 1) from uniform distribution, size = 3x5: \n{}'.format(randmat2))
randmat3 = torch.rand_like(torch.rand((3, 5))*4)
print('random # in [0, 1) from uniform distribution, size = 3x5: \n{}'.format(randmat3))
randmat4 = torch.rand_like(torch.randn((2, 5, 3)))
print('random # in [0, 1) from uniform distribution, size = 5x3x2: \n{}'.format(randmat4))
random # in [0, 1) from uniform distribution, size = 5x1:
tensor([0.3876, 0.9832, 0.9819, 0.0567, 0.4899])
random # in [0, 1) from uniform distribution, size = 3x5:
tensor([[0.5503, 0.2844, 0.0792, 0.4641, 0.1407],
[0.8325, 0.8805, 0.2052, 0.8001, 0.2356],
[0.8523, 0.2093, 0.0953, 0.2912, 0.9842]])
random # in [0, 1) from uniform distribution, size = 3x5:
tensor([[0.3326, 0.1793, 0.5883, 0.9048, 0.5251],
[0.4898, 0.5017, 0.0844, 0.7989, 0.4368],
[0.0731, 0.3907, 0.3953, 0.3256, 0.8585]])
random # in [0, 1) from uniform distribution, size = 5x3x2:
tensor([[[0.7219, 0.2934, 0.7838],
[0.3688, 0.2671, 0.3579],
[0.5251, 0.6458, 0.5450],
[0.2735, 0.5921, 0.1392],
[0.6090, 0.6160, 0.1935]],
[[0.3500, 0.9959, 0.7040],
[0.1859, 0.5252, 0.4252],
[0.3315, 0.3816, 0.2716],
[0.1890, 0.2120, 0.4218],
[0.7946, 0.8808, 0.8799]]])
randint_like
PyTorch文档:
先看例子:torch.randint_like — PyTorch 2.1 documentation
import torch
randmat1 = torch.randint_like(torch.rand((5,)), 1, 25)
print('random # in [1, 25) from uniform distribution, size = 5x1: \n{}'.format(randmat1))
randmat2 = torch.randint_like(torch.rand((3, 5)), 1, 25)
print('random # in [1, 25) from uniform distribution, size = 3x5: \n{}'.format(randmat2))
randmat3 = torch.randint_like(torch.rand((3, 5))*4, 1, 25)
print('random # in [1, 25) from uniform distribution, size = 3x5: \n{}'.format(randmat3))
randmat4 = torch.randint_like(torch.randn((2, 5, 3)), 1, 25)
print('random # in [1, 25) from uniform distribution, size = 5x3x2: \n{}'.format(randmat4))
random # in [0, 1) from uniform distribution, size = 5x1:
tensor([ 4., 21., 5., 1., 24.])
random # in [0, 1) from uniform distribution, size = 3x5:
tensor([[10., 19., 2., 22., 8.],
[13., 2., 18., 5., 16.],
[10., 20., 15., 24., 15.]])
random # in [0, 1) in [0, 1) from uniform distribution, size = 3x5:
tensor([[22., 17., 19., 6., 23.],
[11., 8., 23., 2., 21.],
[ 6., 17., 19., 3., 6.]])
random # in [0, 1) from uniform distribution, size = 5x3x2:
tensor([[[16., 6., 11.],
[19., 19., 4.],
[20., 9., 16.],
[ 9., 4., 18.],
[13., 7., 23.]],
[[ 9., 6., 21.],
[ 3., 13., 17.],
[ 2., 23., 22.],
[15., 6., 20.],
[ 2., 17., 23.]]])
randn_like
PyTorch文档:torch.randn_like — PyTorch 2.1 documentation
先看例子:
import torch
randmat1 = torch.randn_like(torch.rand((5,)))
print('random # from normal distribution with mean 0 and variance 1, size = 5x1: \n{}'.format(randmat1))
randmat2 = torch.randn_like(torch.rand((3, 5)))
print('random # from normal distribution with mean 0 and variance 1, size = 3x5: \n{}'.format(randmat2))
randmat3 = torch.randn_like(torch.rand((3, 5))*4)
print('random # from normal distribution with mean 0 and variance 1, size = 3x5: \n{}'.format(randmat3))
randmat4 = torch.randn_like(torch.randn((2, 5, 3)))
print('random # from normal distribution with mean 0 and variance 1, size = 5x3x2: \n{}'.format(randmat4))
random # from normal distribution with mean 0 and variance 1, size = 5x1:
tensor([ 2.6534, 1.1162, 0.2601, -0.4965, 0.6950])
random # from normal distribution with mean 0 and variance 1, size = 3x5:
tensor([[ 0.0652, -2.5616, 0.0284, -1.2705, 0.6823],
[-0.6783, 0.2622, -2.2505, 2.0945, -0.1017],
[ 0.1652, -1.4292, 0.9019, -1.3582, -1.1806]])
random # from normal distribution with mean 0 and variance 1, size = 3x5:
tensor([[ 1.6769, 0.5854, -1.5175, 1.1947, 1.3363],
[ 1.2854, 1.6041, 0.4576, 0.1328, 0.3250],
[-1.4290, -0.9607, -0.1005, 0.6504, -0.2264]])
random # from normal distribution with mean 0 and variance 1, size = 5x3x2:
tensor([[[ 1.8667, -1.1027, -2.0161],
[ 0.6036, 0.2920, -1.1247],
[-0.6150, -1.1839, -0.7927],
[ 0.2736, 0.2209, 1.4035],
[-1.8238, -1.2559, -0.5278]],
[[ 0.3819, 1.4140, 0.0312],
[-1.0143, 0.1047, 0.9498],
[ 0.3460, -0.0644, 0.3481],
[ 0.4995, -2.0039, 0.8907],
[-0.5305, -0.9221, -0.9462]]])
返回一个与输入大小相同的张量,其中填充了来自均值为0、方差为1的正态分布的随机数。
randperm
PyTorch文档:torch.randperm — PyTorch 2.1 documentation
先看例子:
randList = torch.randperm(10)
print('a random permutation of integers from 0 to n - 1:\n {}'.format(randList))a random permutation of integers from 0 to n - 1: tensor([7, 3, 0, 5, 2, 8, 1, 9, 6, 4])
返回0到n-1的排列
seed
PyTorch文档:torch.seed — PyTorch 2.1 documentation
print('random seed, no specific parameters, used for other set seeds functions: \n {}'.format(torch.seed()))random seed, no specific parameters, used for other set seeds functions: 11787264891204884695
将生成随机数的种子设置为不确定随机数。返回用于RNG种子的64位数字。
manual_seed
PyTorch文档:torch.manual_seed — PyTorch 2.1 documentation
initial_seed
PyTorch文档:torch.initial_seed — PyTorch 2.1 documentation
先看例子:
print('random seed, no specific parameters, used for other set seeds functions: \n {}'.format(torch.initial_seed()))
random seed, no specific parameters, used for other set seeds functions: 11807800269025701155
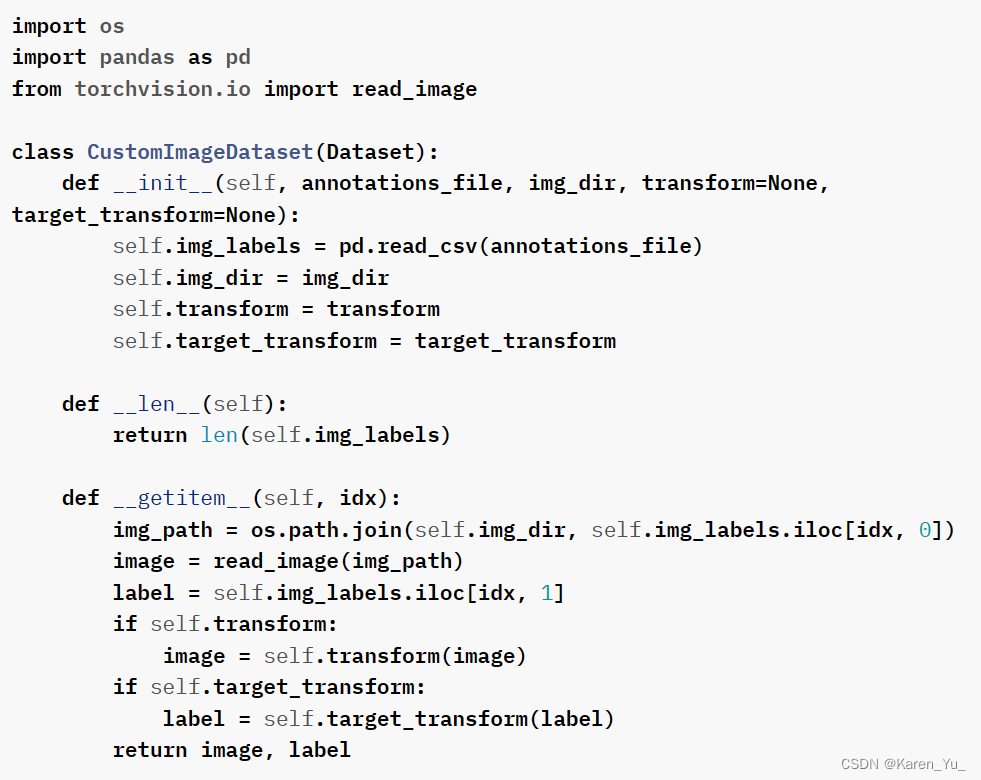
生成训练数据
本节内容旨在帮助理解训练数据的形状、尺寸、包括生成单个数据,生成一定数量的数据,生成分好batch的数据。主要分为CV和NLP两类数据。
CV数据生成
单张图像(灰度图像)
import torch
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage, Grayscale
def generate_image(channel, width, height):
img = torch.rand((channel, width, height))
img = ToPILImage()(img)
if channel == 1:
img = img.convert('RGB')
return img
img = generate_image(1, 225, 225)
plt.imshow(img)
plt.show()
参考:
PIL 图片转换为三通道RGB_pil image 保存为jpg3通道图片-CSDN博客
【PyTorch】生成一张随机噪声图片_torch.randn 生成随机图片-CSDN博客
单张图像(RGB图像)
import torch
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage
def generate_image(channel, width, height):
img = torch.rand((channel, width, height))
img = ToPILImage()(img)
if channel == 1:
img = img.convert('RGB')
return img
img = generate_image(3, 225, 225)
plt.imshow(img)
plt.show()
单张图像(带标签)
import torch
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage
import numpy as np
def generate_image(channel, width, height):
img = torch.rand((channel, width, height))
label = np.max(np.random.choice(np.arange(0, height, 8))) % 10
img = ToPILImage()(img)
if channel == 1:
img = img.convert('RGB')
return img, label
img, label = generate_image(3, 225, 225)
plt.imshow(img)
plt.show()
print(label)
指定数量的图像(带标签)
import torch
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage
from torch.utils.data import Dataset, DataLoader
import numpy as np
class SampleDataset(Dataset):
def __init__(self, size=1024, channel=3, width=225, height=225, n_classes=10):
self.img = torch.rand((size, channel, width, height))
self.channel = channel
self.height = height
self.n_classes = n_classes
def __len__(self):
return len(self.img)
def __getitem__(self, idx):
indices = np.random.choice(np.arange(0, len(self.img)), 1)
return self.img[indices][0], torch.tensor(indices % self.n_classes)
def to_PIL_image(img):
img = ToPILImage()(img)
img = img.convert('RGB')
return img
batch_size = 4
size = 1024
width = 255
height = 255
n_classes = 10
channel = 3
dataset = SampleDataset(channel=channel, width=width,
height=height, n_classes=n_classes)
img, label = dataset.__getitem__(7)
img = to_PIL_image(img)
plt.imshow(img)
plt.show()
print(label)
图像batch(带标签)
import torch
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage
import torchvision
from torch.utils.data import Dataset, DataLoader
import numpy as np
class SampleDataset(Dataset):
def __init__(self, size=1024, channel=3, width=225, height=225, n_classes=10):
self.img = torch.rand((size, channel, width, height))
self.channel = channel
self.height = height
self.n_classes = n_classes
def __len__(self):
return len(self.img)
def __getitem__(self, idx):
indices = np.random.choice(np.arange(0, len(self.img)), 1)
return self.img[indices][0], torch.tensor(indices % self.n_classes)
def imshow(img):
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
batch_size = 4
size = 1024
width = 255
height = 255
n_classes = 10
channel = 3
trainset = SampleDataset(channel=channel, width=width,
height=height, n_classes=n_classes)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
labels = labels.numpy().tolist()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print([labels[j][0] for j in range(batch_size)])
NLP数据生成
Tensor和tensor的区别
首先先看一下Tensor和tensor的区别:
import torch
print('tensor: {}'.format(torch.tensor(5)))
print('Tensor: {}'.format(torch.Tensor(5)))tensor: 5 Tensor: tensor([-2.5796e-23, 4.3125e-41, 1.1204e+18, 3.0705e-41, 4.4842e-44])
在前面关于随机数的章节中我们用到了torch.Tensor,这里如果换成tensor会怎么样呢?
import torch
randmat1 = torch.multinomial(torch.tensor([0.2, 0.3, 0.1, 0.4]), 2)
print('random # by weights from multinomial probability distribution, size = 2x1: \n{}'.format(randmat1))
randmat3 = torch.multinomial(torch.tensor([
[0, 0.3, 0.7],
[0.3, 0.7, 0]
]), 2, replacement = True)
print('random # with replacement from multinomial probability distribution, size = 2x2: \n{}'.format(randmat3))
randmat2 = torch.multinomial(torch.tensor([12, 2, 8, 11, 13]), 2)
print('random # by frequency from multinomial probability distribution, size = 2x1: \n{}'.format(randmat2))
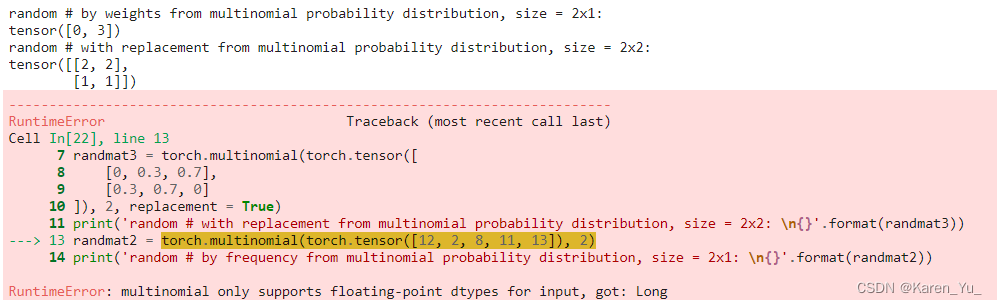
关于Tensor类型,在文档中也给出了具体的说明:torch.Tensor — PyTorch 2.1 documentation
import torch
t1 = torch.tensor(5)
t2 = torch.Tensor(5)
print('tensor: {}, type: {}'.format(t1, t1.type()))
print('Tensor: {}, type: {}'.format(t2, t2.type()))
t3 = torch.rand((3, 5))
print('torch.rand: {}, type: {}'.format(t3, t3.type()))
t4 = torch.randint(1, 8, (3, 5))
print('torch.randint: {}, type: {}'.format(t4, t4.type()))
t5 = torch.tensor([1, 2, 6])
print('tensor: {}, type: {}'.format(t5, t5.type()))
t6 = torch.tensor([.1, .2, .6])
print('tensor: {}, type: {}'.format(t6, t6.type()))
t7 = torch.tensor([2.1, 4.2, 3.6])
print('tensor: {}, type: {}'.format(t7, t7.type()))
tensor: 5, type: torch.LongTensor
Tensor: tensor([-2.5796e-23, 4.3125e-41, 1.0567e+18, 3.0705e-41, 4.4842e-44]), type: torch.FloatTensor
torch.rand: tensor([[0.4311, 0.3397, 0.5677, 0.0792, 0.1102],
[0.9115, 0.8358, 0.2522, 0.4829, 0.7098],
[0.2585, 0.5666, 0.9115, 0.6682, 0.0824]]), type: torch.FloatTensor
torch.randint: tensor([[1, 5, 6, 5, 3],
[2, 5, 5, 5, 3],
[7, 4, 4, 2, 1]]), type: torch.LongTensor
tensor: tensor([1, 2, 6]), type: torch.LongTensor
tensor: tensor([0.1000, 0.2000, 0.6000]), type: torch.FloatTensor
tensor: tensor([2.1000, 4.2000, 3.6000]), type: torch.FloatTensor
【PyTorch】Tensor和tensor的区别_pytorch tensor tensor-CSDN博客
【PyTorch】tensor和Tensor有什么区别?-CSDN博客
简要来说就是Tensor固定生成Float,而tensor可以有一定的自由度。
一些说明
一切尽在不言中×
如果下面有觉得看着很迷惑的,请来这里看看例子~
embedding得到的就是1024个token,每个token都用32个数字去描述,indices这里是从刚刚的1024个token中抽取8个作为句子。也就是说一个句子的长度为8。这里也给label定义。
import numpy as np
import torch
embeddings = torch.rand(1024, 32)
print('embeddings:\n {}\n embeddings size: \n {}\n embeddings type: \n {}\n'.format(embeddings, embeddings.size(), embeddings.type()))
print('------------------------------')
indices = np.random.choice(np.arange(0, len(embeddings)), 8)
print('np.arange(0, len(embeddings)): \n {}\n'.format(np.arange(0, len(embeddings))))
print('np.random.choice(np.arange(0, len(embeddings)), 8):\n{}\n'.format(indices))
seq = embeddings[indices]
label = torch.tensor(np.max(indices) % 3)
print('np.max(indices): {}, %3: {}'.format(np.max(indices), np.max(indices) % 3))
print('sequence: {}, label: {}'.format(seq, label))
embeddings:
tensor([[0.5950, 0.8211, 0.5239, ..., 0.6351, 0.2043, 0.3707],
[0.4606, 0.2120, 0.4629, ..., 0.5546, 0.3214, 0.0353],
[0.1479, 0.8472, 0.4502, ..., 0.3190, 0.1214, 0.8164],
...,
[0.5470, 0.2261, 0.0055, ..., 0.3998, 0.4072, 0.8836],
[0.5240, 0.1334, 0.4030, ..., 0.5154, 0.2541, 0.4662],
[0.4748, 0.7097, 0.0870, ..., 0.5444, 0.0609, 0.1201]])
embeddings size:
torch.Size([1024, 32])
embeddings type:
torch.FloatTensor
------------------------------
np.arange(0, len(embeddings)):
[ 0 1 2 ... 1021 1022 1023]
np.random.choice(np.arange(0, len(embeddings)), 8):
[ 102 941 706 29 1020 44 420 525]
np.max(indices): 1020, %3: 0
sequence: tensor([[9.3969e-01, 9.7674e-01, 4.3202e-02, 9.1800e-01, 5.8985e-01, 1.2796e-02,
3.6486e-01, 5.4620e-01, 9.7397e-01, 9.6150e-01, 1.0920e-01, 8.8843e-01,
4.1399e-01, 5.6093e-01, 6.5011e-01, 7.8331e-01, 1.6752e-01, 4.5388e-01,
7.6690e-01, 9.6550e-01, 7.9818e-01, 1.4861e-01, 5.5701e-01, 8.0982e-01,
2.0266e-01, 1.3363e-01, 6.7499e-01, 6.9142e-01, 7.8924e-01, 5.4258e-01,
8.5754e-01, 3.9922e-01],
[3.5086e-01, 8.0730e-01, 2.7350e-01, 2.1650e-01, 3.8455e-01, 8.0626e-01,
9.7108e-01, 9.7459e-01, 6.1122e-01, 3.1264e-01, 5.6719e-01, 8.4728e-01,
7.3474e-01, 4.0242e-01, 6.4138e-01, 4.5030e-01, 5.1827e-01, 9.7699e-01,
4.1467e-01, 9.6212e-01, 8.4609e-01, 7.4549e-01, 2.6910e-03, 3.5232e-01,
9.8072e-01, 4.6758e-01, 8.5339e-01, 7.3056e-01, 8.4993e-01, 2.1359e-01,
6.2138e-01, 5.2202e-01],
[1.1818e-01, 4.7182e-01, 6.0396e-01, 9.4202e-01, 1.0025e-01, 3.5185e-01,
9.6465e-01, 3.0395e-01, 3.0913e-01, 5.8751e-01, 3.5960e-01, 5.3077e-01,
5.9469e-01, 4.1033e-01, 2.5605e-01, 5.3595e-01, 9.8169e-01, 4.9731e-01,
1.7659e-01, 6.9279e-01, 3.5794e-01, 6.7661e-01, 2.6034e-01, 5.2406e-02,
6.1333e-01, 2.2913e-02, 2.6842e-01, 9.7140e-01, 2.4521e-01, 5.8844e-01,
1.4405e-01, 3.5522e-01],
[1.6004e-01, 5.8004e-01, 2.9356e-01, 1.3992e-01, 4.7796e-01, 5.0674e-01,
3.6266e-01, 3.7189e-02, 7.9477e-01, 2.3659e-01, 7.5312e-01, 6.7590e-01,
9.0985e-02, 5.8764e-01, 1.0979e-01, 9.1712e-01, 7.7690e-01, 5.3795e-01,
2.6610e-01, 4.8186e-01, 5.0209e-01, 9.6645e-01, 6.2966e-01, 9.1539e-01,
9.1318e-01, 1.9397e-01, 2.9087e-02, 9.1457e-01, 9.2000e-01, 3.1310e-03,
4.5268e-01, 2.6268e-01],
[3.9238e-01, 2.7272e-01, 5.3895e-02, 4.6496e-01, 2.1729e-01, 3.1993e-01,
2.4330e-01, 5.2198e-01, 9.5925e-01, 3.2153e-01, 3.7217e-01, 3.7506e-01,
8.4822e-01, 8.6122e-01, 9.4756e-01, 6.5892e-01, 4.5551e-01, 1.3852e-01,
6.0787e-01, 9.8025e-01, 4.0925e-01, 9.5617e-01, 7.7522e-01, 4.9262e-01,
4.5342e-02, 8.2521e-01, 6.0294e-01, 6.6940e-01, 1.8891e-01, 8.2866e-01,
3.9630e-01, 5.9513e-01],
[1.1300e-01, 8.4010e-01, 3.7156e-01, 6.7291e-01, 4.7949e-01, 7.2294e-01,
5.0097e-01, 3.6849e-01, 2.7238e-01, 1.0143e-01, 8.5916e-01, 6.9111e-03,
2.7380e-02, 9.8451e-01, 2.4735e-01, 8.3816e-03, 3.7466e-01, 4.8278e-01,
6.6746e-02, 3.9626e-01, 3.8502e-01, 1.5853e-01, 6.2635e-01, 5.5668e-01,
4.5723e-01, 6.9070e-02, 9.8803e-01, 7.5164e-01, 9.6380e-02, 8.7469e-02,
5.2552e-01, 1.8842e-01],
[8.2018e-01, 5.1812e-01, 7.5742e-02, 8.7664e-01, 8.8095e-01, 9.5179e-01,
7.4036e-01, 9.5574e-01, 1.4106e-01, 4.9915e-01, 3.1341e-01, 7.8643e-01,
5.5806e-01, 7.3059e-01, 9.1721e-01, 9.7636e-01, 3.7074e-02, 9.7177e-01,
5.6018e-01, 4.4830e-01, 2.9606e-01, 5.7863e-02, 5.2747e-01, 7.9749e-01,
8.8895e-01, 1.8094e-01, 8.1038e-01, 3.2423e-01, 2.5211e-02, 4.1670e-01,
8.2494e-01, 2.8963e-01],
[8.4206e-01, 9.8369e-01, 3.8594e-01, 4.1664e-01, 8.4951e-01, 8.9908e-01,
1.6372e-01, 8.7082e-01, 3.6789e-01, 1.9403e-01, 5.5556e-01, 9.6168e-01,
5.5864e-01, 1.2936e-01, 2.9550e-01, 7.4263e-01, 4.3219e-04, 4.7454e-01,
5.1302e-01, 4.5214e-01, 5.2430e-01, 1.7938e-01, 8.8911e-01, 7.4648e-02,
6.5389e-02, 5.0446e-01, 9.0789e-02, 4.3035e-01, 9.8959e-01, 7.5943e-01,
6.2928e-01, 7.3990e-01]]), label: 0
单个句子
import torch
import numpy as np
def generate_sentence(token_len, token_number, seq_len, n_classes):
embeddings = torch.rand(token_number, token_len)
indices = np.random.choice(np.arange(0, len(embeddings)), seq_len)
seq = embeddings[indices]
return seq
seq = generate_sentence(token_len=32, token_number=1024, seq_len=8, n_classes=3)
print(seq)
tensor([[0.1055, 0.4417, 0.7026, 0.1617, 0.2982, 0.9604, 0.6201, 0.2974, 0.3708,
0.0406, 0.1156, 0.2565, 0.8255, 0.9861, 0.8613, 0.6052, 0.0941, 0.1006,
0.8360, 0.6786, 0.7128, 0.6680, 0.5682, 0.5155, 0.3452, 0.7330, 0.2129,
0.9405, 0.3904, 0.5202, 0.4163, 0.9121],
[0.4663, 0.3193, 0.6405, 0.9163, 0.3617, 0.4974, 0.6576, 0.0646, 0.5581,
0.7022, 0.2043, 0.1116, 0.0324, 0.4996, 0.5281, 0.4375, 0.8709, 0.7649,
0.1874, 0.7807, 0.9542, 0.8089, 0.2426, 0.9035, 0.1789, 0.8814, 0.0270,
0.8803, 0.0670, 0.5327, 0.4766, 0.5667],
[0.4097, 0.0854, 0.3301, 0.6764, 0.0812, 0.3937, 0.9174, 0.6711, 0.3044,
0.2932, 0.9467, 0.4988, 0.0474, 0.9517, 0.6987, 0.3441, 0.0773, 0.6338,
0.3327, 0.9019, 0.4738, 0.1837, 0.4787, 0.7724, 0.7200, 0.5644, 0.4859,
0.1180, 0.5955, 0.3040, 0.7327, 0.4150],
[0.5593, 0.9066, 0.5239, 0.2913, 0.4066, 0.0745, 0.5051, 0.7576, 0.1782,
0.9158, 0.8912, 0.8034, 0.2604, 0.4673, 0.2207, 0.3956, 0.6093, 0.7031,
0.2342, 0.1301, 0.0122, 0.1927, 0.9124, 0.5560, 0.2776, 0.9081, 0.5031,
0.1151, 0.7837, 0.5810, 0.5846, 0.5667],
[0.4359, 0.1676, 0.8172, 0.8280, 0.8748, 0.9026, 0.4925, 0.1150, 0.4588,
0.8161, 0.9793, 0.1296, 0.3500, 0.7751, 0.9856, 0.9782, 0.5598, 0.7937,
0.8984, 0.0638, 0.0463, 0.9358, 0.5368, 0.7980, 0.8393, 0.4096, 0.1220,
0.2645, 0.7243, 0.6852, 0.3279, 0.0105],
[0.3553, 0.1199, 0.5489, 0.1569, 0.3334, 0.3668, 0.5197, 0.2979, 0.3643,
0.9057, 0.9469, 0.8624, 0.3043, 0.4426, 0.7682, 0.9898, 0.6836, 0.3537,
0.9617, 0.6856, 0.3951, 0.1785, 0.6641, 0.9414, 0.7967, 0.9393, 0.9158,
0.1999, 0.7434, 0.2855, 0.6924, 0.4813],
[0.4685, 0.1095, 0.7986, 0.0252, 0.1160, 0.8867, 0.8301, 0.9273, 0.7654,
0.1244, 0.0160, 0.1824, 0.1096, 0.8009, 0.6391, 0.9233, 0.7622, 0.7455,
0.9768, 0.6279, 0.3692, 0.7567, 0.6241, 0.3768, 0.2914, 0.6346, 0.1970,
0.9242, 0.2833, 0.4225, 0.0556, 0.7449],
[0.9240, 0.4110, 0.6585, 0.1600, 0.1152, 0.8804, 0.9960, 0.0584, 0.7691,
0.6840, 0.8209, 0.5205, 0.9119, 0.8644, 0.5021, 0.3016, 0.0274, 0.3670,
0.7700, 0.0987, 0.1258, 0.1823, 0.1844, 0.5233, 0.7304, 0.1150, 0.9800,
0.7905, 0.4896, 0.0966, 0.0567, 0.0070]])
单个句子(带标签)
import torch
import numpy as np
def generate_sentence(token_len, token_number, seq_len, n_classes):
embeddings = torch.rand(token_number, token_len)
indices = np.random.choice(np.arange(0, len(embeddings)), seq_len)
seq = embeddings[indices]
label = torch.tensor(np.max(indices) % n_classes)
return seq, label
seq, label = generate_sentence(token_len=32, token_number=1024, seq_len=8, n_classes=3)
print(seq, label)
tensor([[0.4889, 0.4177, 0.4337, 0.4099, 0.6549, 0.2441, 0.2630, 0.0197, 0.9860,
0.5308, 0.7586, 0.0466, 0.1880, 0.1510, 0.3560, 0.7250, 0.6974, 0.4832,
0.3404, 0.2006, 0.2987, 0.1921, 0.3935, 0.2643, 0.7406, 0.1420, 0.0441,
0.4321, 0.9418, 0.6721, 0.1094, 0.8862],
[0.9453, 0.2066, 0.0726, 0.1304, 0.0469, 0.1491, 0.6861, 0.4568, 0.0360,
0.0481, 0.7499, 0.4141, 0.7290, 0.0542, 0.4941, 0.2201, 0.9943, 0.5494,
0.6984, 0.2823, 0.1337, 0.1772, 0.3116, 0.4968, 0.2572, 0.6313, 0.2000,
0.5022, 0.1842, 0.3630, 0.4601, 0.6121],
[0.1742, 0.8773, 0.5313, 0.1989, 0.7188, 0.4755, 0.2788, 0.5632, 0.8161,
0.8405, 0.5981, 0.0563, 0.4605, 0.5000, 0.1258, 0.3628, 0.4593, 0.1674,
0.8968, 0.9505, 0.0144, 0.8586, 0.8176, 0.4292, 0.9691, 0.0196, 0.9934,
0.6321, 0.2527, 0.4716, 0.6691, 0.3175],
[0.5191, 0.2432, 0.8799, 0.7704, 0.9788, 0.5917, 0.4663, 0.6421, 0.9225,
0.5842, 0.1761, 0.0858, 0.3097, 0.6868, 0.4688, 0.1012, 0.9078, 0.7326,
0.7476, 0.4481, 0.9825, 0.2528, 0.6700, 0.9715, 0.4395, 0.5667, 0.0323,
0.3454, 0.3646, 0.3293, 0.1259, 0.8677],
[0.7679, 0.4662, 0.3475, 0.8881, 0.0493, 0.3277, 0.7581, 0.8458, 0.4405,
0.2129, 0.0902, 0.2773, 0.7536, 0.5859, 0.7785, 0.6997, 0.1411, 0.3248,
0.2326, 0.5126, 0.7637, 0.6824, 0.3790, 0.3733, 0.3878, 0.3818, 0.2395,
0.0693, 0.5121, 0.1702, 0.0659, 0.3272],
[0.5026, 0.9611, 0.5067, 0.6645, 0.4892, 0.9065, 0.6089, 0.6368, 0.5205,
0.6452, 0.3356, 0.7100, 0.1463, 0.6814, 0.5926, 0.3886, 0.6949, 0.0817,
0.6264, 0.1295, 0.1659, 0.6596, 0.4529, 0.1045, 0.7688, 0.4339, 0.6176,
0.5953, 0.0920, 0.1155, 0.2195, 0.8974],
[0.3639, 0.6652, 0.1732, 0.9802, 0.5916, 0.0104, 0.3043, 0.3904, 0.0573,
0.0402, 0.9867, 0.7842, 0.6881, 0.2942, 0.3224, 0.6236, 0.1038, 0.4554,
0.5720, 0.3483, 0.3865, 0.8806, 0.4875, 0.7692, 0.1616, 0.8584, 0.5004,
0.5855, 0.1460, 0.4121, 0.6782, 0.0437],
[0.0802, 0.1696, 0.5097, 0.6684, 0.0934, 0.1534, 0.3463, 0.1505, 0.1981,
0.3822, 0.7575, 0.8124, 0.8430, 0.0873, 0.7725, 0.3932, 0.8395, 0.3442,
0.5081, 0.5182, 0.1594, 0.8820, 0.7755, 0.6773, 0.9283, 0.7906, 0.3377,
0.8842, 0.2443, 0.6519, 0.9925, 0.9551]]) tensor(0)
多个句子(带标签)
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
class SampleDataset(Dataset):
def __init__(
self,
size: int = 1024,
emb_dim: int = 32,
sequence_length: int = 8,
n_classes: int = 3,
):
self.embeddings = torch.randn(size, emb_dim)
self.sequence_length = sequence_length
self.n_classes = n_classes
def __len__(self):
return len(self.embeddings) - self.sequence_length + 1
def __getitem__(self, idx):
indices = np.random.choice(
np.arange(0, len(self.embeddings)), self.sequence_length
)
return (
self.embeddings[indices], # sequence_length x emb_dim
torch.tensor(np.max(indices) % self.n_classes),
)
size = 1024
emb_dim = 32
sequence_length = 8
n_classes = 3
trainset = SampleDataset(size=size, emb_dim=emb_dim, sequence_length=sequence_length, n_classes=n_classes)
seq, label = trainset.__getitem__(7)
print(seq, label)
tensor([[ 2.7567e-01, 1.8115e+00, 2.5822e-01, -4.7080e-01, 3.7290e-01,
-4.4162e-01, -1.2756e+00, 1.1127e+00, 7.0213e-01, -1.5775e-01,
-9.4483e-02, -1.7822e-01, 9.7160e-02, 9.8652e-02, 7.2581e-01,
-2.1706e+00, 1.2200e+00, 9.2007e-01, -2.5690e+00, 3.7861e-01,
-1.8212e-04, -9.6909e-01, -4.1302e-01, 6.8342e-01, 8.0448e-03,
-3.8304e-01, -8.9294e-01, 2.0070e-01, -1.6254e+00, -6.3853e-01,
5.4009e-02, -3.0313e-01],
[-1.0637e+00, 3.8875e-01, 6.6931e-01, 9.6796e-01, -1.9486e+00,
1.3687e+00, -1.1058e+00, -4.1554e-02, 1.5667e+00, -6.7008e-01,
-7.3514e-01, 9.3274e-01, 4.8057e-01, 1.5185e-01, -7.6053e-01,
-5.6608e-02, -5.7766e-02, -6.4288e-01, 9.8750e-02, 1.0223e+00,
7.7759e-01, 6.4274e-01, 5.4502e-01, -3.5921e-01, -9.4965e-01,
-5.8405e-01, 1.2020e+00, -2.3932e-01, 1.1706e+00, -1.5020e+00,
1.3020e+00, 1.2625e+00],
[-3.6313e-01, 7.3447e-02, 4.6395e-01, -7.8496e-01, 1.1169e+00,
-1.2897e-01, 8.0826e-01, -5.6813e-01, 2.9373e-01, 5.4832e-01,
-4.3653e-01, 4.8938e-01, 4.4685e-01, -1.2104e+00, 2.2498e-02,
-1.2567e+00, -1.3671e+00, -1.8864e+00, 3.3536e-01, -4.4277e-02,
1.4514e+00, -4.1136e-01, 3.5647e-01, -9.9254e-01, 5.9698e-01,
-1.3116e+00, -1.2169e-01, 4.8391e-01, -2.1127e+00, -1.5413e+00,
2.4266e-01, 6.5636e-02],
[-1.4378e+00, 1.0472e+00, -7.9972e-01, 1.5971e+00, -2.2762e-01,
4.2076e-01, -7.6180e-01, 1.7015e+00, 1.1904e+00, -5.1038e-01,
1.1748e+00, -2.1830e-01, 2.3443e+00, 1.2750e+00, 9.2058e-01,
7.0825e-01, 4.3038e-01, -1.8827e+00, 7.5303e-01, 3.0916e-01,
1.0007e+00, 5.4854e-02, -1.5419e+00, 7.4721e-01, -1.1671e+00,
1.5878e+00, 1.5468e-01, 1.9930e-01, -2.0341e-01, -1.5807e+00,
1.1020e+00, 1.1212e-01],
[-1.8586e-01, -6.3636e-01, 1.6055e+00, 1.8611e+00, 1.4813e+00,
-2.9734e-01, -4.0349e-01, 7.2211e-01, -1.5849e+00, -4.0749e-01,
9.5344e-01, -1.2364e+00, -1.5549e+00, 7.6416e-01, 1.2216e+00,
-4.2242e-01, 1.0933e+00, 4.7638e-01, 1.6813e-01, -3.9375e-01,
4.7872e-01, 8.6785e-01, 1.2454e-01, -2.0458e+00, 2.4382e+00,
-1.5022e-01, -2.2507e+00, 4.7150e-01, -6.7617e-01, -2.6852e+00,
-9.5083e-01, 1.7825e-01],
[ 1.5406e+00, 5.6118e-01, 5.6671e-01, -1.0631e+00, -6.3804e-01,
-4.6236e-01, -5.0994e-02, -1.5228e+00, -1.4586e+00, -3.8091e-01,
-3.8060e-02, 6.3429e-01, -1.6340e+00, 1.0809e+00, 1.1526e+00,
-1.7139e-01, 1.3772e-02, -2.0869e+00, 1.6291e+00, -7.0059e-01,
-7.9747e-01, 1.5902e-01, -1.1186e+00, -3.6230e-01, -1.8297e+00,
1.2019e+00, -1.9672e-01, -9.5106e-01, 9.2412e-02, 7.9688e-01,
1.2752e+00, -6.2857e-01],
[-7.2704e-01, 7.3595e-01, 1.8353e+00, -5.0271e-01, 1.4489e+00,
-7.5944e-01, 1.8489e-01, -9.3314e-02, -6.4899e-01, 2.9504e-01,
4.1762e-01, -4.9189e-01, 1.2940e-01, 1.6158e-01, -1.6994e-01,
-1.4896e-01, -7.7437e-02, 7.3287e-01, 3.8545e-01, 1.7603e+00,
1.7547e+00, 6.7519e-01, -7.3843e-01, -7.2541e-01, -1.0181e+00,
2.1402e+00, -1.3686e+00, -3.9245e-01, -3.9555e-01, 1.0335e+00,
5.2201e-01, -3.4141e-01],
[ 5.1360e-01, 1.3339e+00, 1.4972e+00, -7.8894e-01, 1.2359e+00,
1.3918e-01, 5.8419e-01, 1.9019e+00, -1.1569e+00, 3.4441e-01,
-4.2662e-01, -9.3540e-01, 1.2694e+00, 6.4401e-01, 6.7648e-01,
-4.8101e-01, 8.1791e-02, -4.8887e-01, 1.1595e-01, -1.2787e+00,
1.9470e+00, -1.1013e+00, -7.5908e-01, 6.1225e-01, 1.8400e+00,
-8.5006e-02, -4.8657e-01, 7.2233e-01, 7.8222e-01, 7.1141e-01,
1.6821e+00, -1.7286e+00]]) tensor(0)
句子batch(带标签)
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
class SampleDataset(Dataset):
def __init__(
self,
size: int = 1024,
emb_dim: int = 32,
sequence_length: int = 8,
n_classes: int = 3,
):
self.embeddings = torch.randn(size, emb_dim)
self.sequence_length = sequence_length
self.n_classes = n_classes
def __len__(self):
return len(self.embeddings) - self.sequence_length + 1
def __getitem__(self, idx):
indices = np.random.choice(
np.arange(0, len(self.embeddings)), self.sequence_length
)
return (
self.embeddings[indices], # sequence_length x emb_dim
torch.tensor(np.max(indices) % self.n_classes),
)
size = 1024
emb_dim = 32
sequence_length = 8
n_classes = 3
batch_size=4
trainset = SampleDataset(size=size, emb_dim=emb_dim, sequence_length=sequence_length, n_classes=n_classes)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
# get some random training samples
dataiter = iter(trainloader)
sequences, labels = next(dataiter)
print('# of sequences in one batch: {}\n # of labels in one batch: {}\n'.format(len(sequences), len(labels)))
print('length of one sequence: {}'.format(len(sequences[0])))
print('labels in one batch: {}'.format(labels))# of sequences in one batch: 4 # of labels in one batch: 4 length of one sequence: 8 labels in one batch: tensor([0, 0, 1, 1])
Datasets & DataLoaders — PyTorch Tutorials 2.2.0+cu121 documentation?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【MySQL】CRUD,常见函数及union&union
- 章鱼网络 Community Call #17|打造全新 Omnity 跨链协议
- spring springfox-swagger2 2.7.0配置
- JavaFX入门
- Docker瞬间搭建本地开发环境
- element-ui的选择实现上拉刷新和回显
- E中国造船行业运营规划与发展前景趋势分析报告2024-2030年
- 【ceph】ceph关于清洗数据scrub的参数分析
- 【系统架构】集群、分布式概念及系统架构演进过程
- gcc介绍