基于C++11的数据库连接池【C++/数据库/多线程/MySQL】
一、概述
概述:数据库连接池可提前把多个数据库连接建立起来,然后把它放到一个池子里边,就是放到一个容器里边进行维护。这样的话就能够避免数据库连接的频繁的创建和销毁,从而提高程序的效率。线程池其实也是同样的思路,也是为了避免线程的重复的创建和销毁。
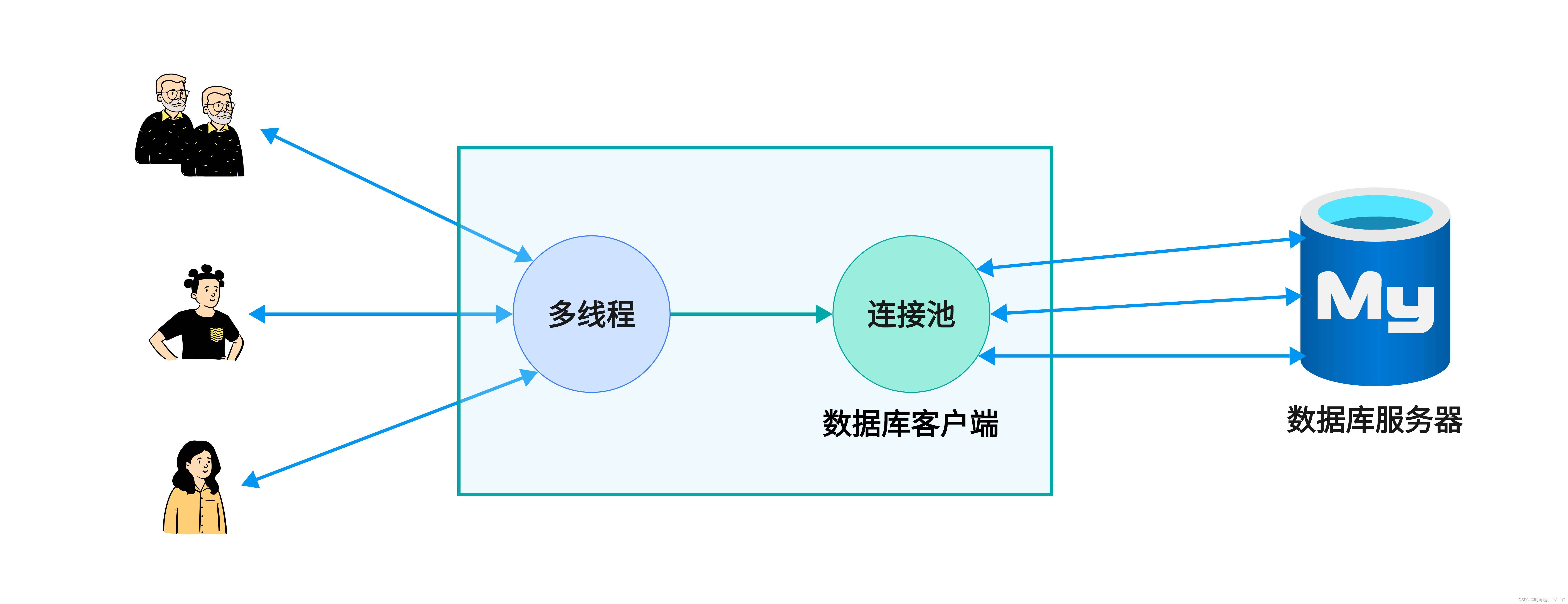
这个图模拟的是一个网络通信,在左侧有多个客户端,客户端给服务器发数据,发数据可以理解为就是发送一个请求,比如说请求登录,请求注册,请求下载或者上传某些文件。
我们还需要做身份的验证,或者说做数据的读和写操作,那这个数据在哪里呢??
- 数据在一个数据库里边,这个数据库它其实位于服务器端。
在服务器端,其实并不是只有一个应用程序。和服务器端程序一块部署的还可以有其他模块,比如关系型数据库的服务器,非关系型数据库的服务器,或者说部署一些分布式的文件系统。
当客户端向服务器发起了某个请求之后,比如说它要登录,那么此时服务器就会连接数据库。从数据库里面去查询一下这个用户的数据是否存在。如果存在,允许它登录;如果不存在,就不允许它登录。所以在这个网络通信的服务器端可以看成是数据库的客户端。如果是多个客户端同时向服务器发起请求,此时服务器就需要建立多个连接去进行数据库的查询。当查询完之后,它需要断开这个连接。
小细节:这个连接一直保持着可以吗?
- 如果一直保持着这个数据库连接,但是你又不进行数据库操作,就浪费了资源。所以在服务器端在进行数据库操作的时候,一般的处理思路就是用的时候去连接,用完了之后就把它销毁掉。
- 如果在网络通信的服务器端,频繁地进行数据库地连接和断开,这很显然是非常的浪费时间以及浪费资源的,所以就可以在网络通信的服务器端去维护一个连接池。当需要连接数据库的时候,就从这个连接池中拿出一个连接,用完之后再把这个连接还给连接池。
有了数据库连接池的好处是什么?
- 就是避免了这个数据库连接的频繁创建和销毁,使用这种方式在访问量比较高的情况下,就能够节省一部分时间。如果访问量很少,有无连接池其实我们是看不到任何的区别的。
- 如果在高并发情况下,这些需要频繁处理的操作就会消耗很多的资源和时间。
涉及的技术点:
C++11新特性
- 多线程编程
- 线程同步(互斥锁的使用)
- 处理时间和日期的chrono库
- 条件变量
- 智能指针(帮我们释放一块内存)
- lambda表达式
- 使用=delete删除函数(在实现数据库连接池的时候,需要创建一个单例模式的类,某些函数是不允许存在的,比如说拷贝构造函数,还有=赋值操作符重载函数,可以用=delete删除,它们也就不允许使用了。如果不使用=delete删除,访问权限设置为私有也可以)
其他知识点:
- MYSQL数据库查询,主要是官方API的封装和使用
- 单例模式
- STL容器
- 生产者和消费者模型
- Jsoncpp库的使用(解析配置文件中的数据库相关信息)
?二、Mysql API
MySQL API 使用详解 | 爱编程的大丙 (subingwen.cn)![]() https://subingwen.cn/mysql/mysql-api/VsCode + CMake构建项目 C/C++连接Mysql数据库 | 数据库增删改查C++封装 | 信息管理系统通用代码 ---- 课程笔记-CSDN博客
https://subingwen.cn/mysql/mysql-api/VsCode + CMake构建项目 C/C++连接Mysql数据库 | 数据库增删改查C++封装 | 信息管理系统通用代码 ---- 课程笔记-CSDN博客![]() https://blog.csdn.net/weixin_41987016/article/details/135668803?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_41987016/article/details/135668803?spm=1001.2014.3001.5501
- MysqlConn.h
#pragma once
#include <mysql.h>
#include <string>
#include <chrono>
using namespace std;
using namespace std::chrono;
class MysqlConn {
public:
// 初始化数据库连接
MysqlConn();
// 释放数据库连接
~MysqlConn();
// 连接数据库
bool connect(string user, string passwd, string dbName, string ip, unsigned short port = 3306);
// 更新数据库: select,update,delete
bool update(string sql);
// 查询数据库
bool query(string sql);
// 遍历查询得到的结果集
bool next();
// 得到结果集中的字段值
string value(int index);
// 事务操作
bool transaction();
// 提交事务
bool commit();
// 事务回滚
bool rollback();
// 刷新起始的空闲时间点
void refreshAliveTime();
// 计算连接存活的总时长
long long getAliveTime();
private:
void freeResult();
MYSQL* m_conn = nullptr; // 数据库连接
MYSQL_RES* m_result = nullptr;
MYSQL_ROW m_row = nullptr;
steady_clock::time_point m_aliveTime;
};- ?MysqlConn.cpp
#include "MysqlConn.h"
// 初始化数据库连接
MysqlConn::MysqlConn() {
m_conn = mysql_init(nullptr);
mysql_set_character_set(m_conn, "GBK"); // 设置字符集
}
// 释放数据库连接
MysqlConn::~MysqlConn() {
if (m_conn != nullptr) {
mysql_close(m_conn);
}
freeResult();
}
// 连接数据库
bool MysqlConn::connect(string user, string passwd, string dbName, string ip, unsigned short port) {
MYSQL* ptr = mysql_real_connect(m_conn, ip.c_str(), user.c_str(), passwd.c_str(), dbName.c_str(), port, nullptr, 0);
return ptr != nullptr;
}
// 更新数据库:insert,update,delete
bool MysqlConn::update(string sql) {
if (mysql_query(m_conn, sql.c_str())) {
return false;
}
return true;
}
// 查询数据库
bool MysqlConn::query(string sql) {
freeResult(); // 释放之前查询的结果集
if (mysql_query(m_conn, sql.c_str())) {
return false;
}
m_result = mysql_store_result(m_conn); // 获取查询结果
return true;
}
// 遍历查询得到的结果集
bool MysqlConn::next() {
if (m_result != nullptr) {
m_row = mysql_fetch_row(m_result);
if (m_row != nullptr) {
return true;
}
}
return false;
}
// 得到结果集中的字段值
string MysqlConn::value(int index) {
int rowCount = mysql_num_fields(m_result);
if (index >= rowCount || index < 0) {
return string();
}
char* val = m_row[index];
unsigned long length = mysql_fetch_lengths(m_result)[index];
return string(val, length);
}
// 事务操作
bool MysqlConn::transaction() {
return mysql_autocommit(m_conn, false);
}
// 提交事务
bool MysqlConn::commit() {
return mysql_commit(m_conn);
}
// 事务回滚
bool MysqlConn::rollback() {
return mysql_rollback(m_conn);
}
// 刷新起始的空闲时间点
void MysqlConn::refreshAliveTime() {
// 这个时间戳就是某个数据库连接,它起始存活的时间点
// 这个时间点通过时间类就可以得到了
m_aliveTime = steady_clock::now();
}
// 计算连接存活的总时长
long long MysqlConn::getAliveTime() {
nanoseconds duration = steady_clock::now() - m_aliveTime;
milliseconds millsec = duration_cast<milliseconds>(duration);
return millsec.count();
}
void MysqlConn::freeResult() {
if (m_result != nullptr) {
mysql_free_result(m_result);
m_result = nullptr;
}
}
数据库操作类封装好了之后,看一下如何编写一个数据库连接池。
三、数据库连接池
关于数据库连接池,它主要是用在网络通信的服务器端,在网络通信的服务器端有可能同时接收多个客户端请求,并且客户端请求的数据它并不在服务器上,而是在服务器对应的那个数据库服务器上。
一定要注意:网络通信的服务器端,它有可能部署了多个组件,数据库服务器是这多个组件里边的其中一个。又因为这个请求是多个客户端发送过来的,所以服务器端为了提高读取数据的效率,它需要通过多线程去访问数据库服务器。
在服务器端如果想要连接数据库服务器,需要做四步操作:
- 第一步:通过tcp进行三次握手。因为网络通信的服务器端其实就是数据库的客户端。数据库的客户端连接数据库的服务器端,其实是一个tcp通信,tcp通信的第一步就是需要进行三次握手。
- 第二步:数据库服务器的连接认证。当连接建立之后,数据库的服务器需要验证客户端的身份,就是验证用户名和密码。验证成功之后,数据库的客户端就可以通过sql语句去服务器端读取或者更新一些数据,
- 第三步:数据库服务器关闭连接时的资源回收。当操作完成之后,客户端和服务器需要断开连接,在断开连接的时候需要进行资源的释放。
- 第四步:断开通信连接的TCP四次挥手。数据库资源释放完了之后,这个tcp通信还需要进行四次挥手。
把这四步操作做完了之后,数据库的客户端和数据库的服务器端,它们之间的通信也就结束了。如果说这个客户端和服务器端需要频繁地进行这四步操作,很显然是非常的浪费时间的,因此就提供了一个解决方案:使用数据库连接池。
在这个数据库连接池里边,我们需要事先和数据库的服务器建立若干个连接,当需要将进行数据库操作的时候,套接字通信的服务器端通过线程去连接池里取出一个可用的连接。取出这个连接之后,就可以和数据库的服务器直接通信了。通信结束之后,这个连接是不需要进行断开的,网络通信的服务器端对应的这个线程,把这个数据库连接就还给数据库连接池。因此我们就可以实现数据库连接的复用。通过这样的操作,大大的降低了数据库连接的创建和销毁的次数,对应的时间也就被节省出来了。
如果要实现一个数据库连接池,它都需要有哪些组成部分?
这个数据库连接池,它在程序中对应的肯定是一个对象。那么这个数据库连接池的对象有一个还是多个呢?很显然,一个就够了,因为在数据库连接池里边,它可以给我们提供若干个连接,只需要一个数据库连接池对象就可以把多个连接取出来,故这个对象一个就够。
因此,在编写数据库连接池对应的类的时候,这个类应该是一个单例模式的类。提供一个单例模式的类,可以避免出创建多个数据库连接池对象。
分析在这个单例模式的类里边,我们需要给数据库连接池提供哪些属性呢?
// 连接服务器所需信息
string m_ip; // 数据库服务器ip地址
string m_user; // 数据库服务器用户名
string m_dbName; // 数据库服务器的数据库名
string m_passwd; // 数据库服务器密码
unsigned short m_port; // 数据库服务器绑定的端口数据库连接池里边,它存储的是数据库连接,如果我们要成功地建立一个数据库连接,那么就需要提供一系列的属性,这个属性包括数据库服务器对应的IP和它的端口Port。另外在连接数据库服务器的时候,需要提供数据库服务器对应的用户名和密码。因为在一个mysql数据库的服务器上,可以创建多个数据库,每个数据库都有对应的自己的名字,故还需要指定dbName。有了这些属性,就可以成功的去建立一个数据库连接,如果要建立多个数据库连接,那么这个连接是需要存储起来的。
// 连接池信息
queue<MysqlConn*> m_connQ;
unsigned int m_maxSize; // 连接数上限值
unsigned int m_minSize; // 连接数下限值
int m_timeout; // 连接超时时长
int m_maxIdleTime; // 最大的空闲时长
mutex m_mutexQ; // 独占互斥锁
condition_variable m_cond; // 条件变量在STL中我们可以选择队列,存储数据库连接对象。在这个队列里边存储连接的时候,是有上限的,故需要给这个队列存储的连接指定一个最大值。
如果服务器端对应的多个线程从数据库连接池里边取连接的时候,这个连接已经用完了,我们可以给这个线程指定一个超时的时长。如果没有连接了,可以等待一定的时长。如果等待了一定的时间长度还没有拿到可用的连接,有两种处理方式:
- 一种处理方式就是告诉这个线程已经没有可用的连接了。
- 另一种处理方式让这个线程继续等,直到这个数据库连接池里边有新连接了,那么把这个新连接给到对应的线程。
除此之外,还有一种情况就是这个数据库里边的空闲连接太多了,如果空闲的连接太多了,我们就需要销毁一部分,那么我们怎么知道要销毁哪些数据库连接呢?
解决方案:当我们创建出一个数据库之后,它肯定是空闲的,把这个时间点记录下来,给它一个时间戳,然后再提供一个线程专门的去检测这些数据库连接,它们都空闲了多长的时间,就是以现在的这个时间点减去对应的那个起始时间点,如果这个时间长度超过了我们规定的时长,那么就把对应的这个数据库连接给销毁掉。如果没有超过规定的时长,就让这个数据库连接继续存活。另外,在实现这个数据库连接池的时候,还涉及到一些线程相关的操作。因为多个线程它们需要访问这个数据库连接池,因此数据库连接池就是多个线程对应的共享资源。如果涉及到共享资源的访问,就需要使用互斥锁。
其中,共享资源就是数据库连接池队列,要使用互斥锁来保证连接池队列里边的数据不发生混乱。
网络通信的服务器端,它提供的这多个线程在访问数据库连接池的时候,把可用的数据库连接从连接池里边拿出去。如果用完了,之后再把这个可用的连接还给数据库连接池。因此我们可以把这两部分(多线程和连接池->网络服务器)看成是一个生产者和消费者模型。对应的消费者就是网络通信的服务器端提供的这多个线程。生产者是我们在实现数据库连接的时候,提供的一个额外的线程,这个线程需要检测连接池里边的连接数量是否足够,如果说这个连接已经不够了,这个线程它就去生成新的连接,如果说连接池里边的连接是足够的,专门用于生产数据库连接的线程就不工作了。如果它不工作了,就需要让线程阻塞。在C++11里边,让线程池阻塞需要用到条件变量。
超时时长就是让线程阻塞等待的时间长度,当线程等待了这个时间段之后,再让它尝试去连接池里取出对应的连接。如果有就给它,如果没有,可以让它去等待,或者直接告诉它没有了。
在连接池队列里边,可用的有效连接太多了,大部分都处于空闲的状态,在这种情况下,可以销毁一部分有效的数据库连接。销毁哪一个呢?
那就看哪一个数据库连接它的空闲时长到了我们指定的时间长度。如果到了就把它关闭,相当于这个数据库连接就被我们认为释放了。故还需要在这个连接池里边给它添加两个属性,
- 一个是超时时长:m_timeout
- 一个是最大的空闲时长:m_maxIdleTime
>>定义数据库连接池
#pragma once
#include <queue>
#include <mutex>
#include <condition_variable>//条件变量
#include "MysqlConn.h"
using namespace std;
class ConnPool {
public:
static ConnPool* getConnPool();// 获得单例对象
ConnPool(const ConnPool& obj) = delete; // 删除拷贝构造函数
ConnPool& operator=(const ConnPool& obj) = delete; // 删除拷贝赋值运算符重载函数
shared_ptr<MysqlConn> getConn(); // 从连接池中取出一个连接
~ConnPool(); // 析构函数
private:
ConnPool(); // 构造函数私有化
bool parseJsonFile(); // 解析json格式文件
void produceConn(); // 生产数据库连接
void recycleConn(); // 销毁数据库连接
void addConn(); // 添加数据库连接
// 连接服务器所需信息
string m_ip; // 数据库服务器ip地址
string m_user; // 数据库服务器用户名
string m_dbName; // 数据库服务器的数据库名
string m_passwd; // 数据库服务器密码
unsigned short m_port; // 数据库服务器绑定的端口
// 连接池信息
queue<MysqlConn*> m_connQ;
unsigned int m_maxSize; // 连接数上限值
unsigned int m_minSize; // 连接数下限值
int m_timeout; // 连接超时时长
int m_maxIdleTime; // 最大的空闲时长
mutex m_mutexQ; // 独占互斥锁
condition_variable m_cond; // 条件变量
};>>单例类的构造函数处理
单例模式有两种实现:
(1)懒汉模式:在使用这个实例对象的时候,才去创建它。单例模式的类肯定是有且只有一个的。懒汉模式的实现方式有很多种方式:
- 使用静态的局部变量;(在C++11里边使用静态局部变量是没有线程安全问题的)
- 互斥锁(保证创建出来的实例对象有且仅有一个)
- call_once函数(C++11提供的),可以实现懒汉模式的单例类
(2)饿汉模式:不管我们用不用这个实例对象,只要这个类被创建出来了,那么对应的这个实例对象也就有了。饿汉模式是没有线程安全的问题的。因为当我们把这个饿汉模式的实例对象创建出来此时如果有多个线程来访问这个单例对象,不涉及到对象的创建。因此多线程在访问这个单例对象的时候,肯定也是线程安全的。
把构造函数设为私有的(private),那如果我们想要得到这样的一个类的实例对象,可以通过类名来获取到这个类的实例,它能够访问的肯定是静态的函数或者静态变量。所以可以给这个类添加一个静态方法getConnPool();
ConnPool* ConnPool::getConnPool() {
static ConnPool pool;
return &pool;
}在C++11中实现懒汉模式,在getConnPool()函数里使用静态的局部变量是安全的。
静态局部变量的访问范围为当前的函数,但生命周期有多长呢?应用程序结束之后,pool指向的这块内存才能够被析构。不是每调用一次getConnPool函数,这个pool对象就会被创建一次。当第一次调用getConnPool函数的时候,这个静态的局部对象被创建出来了,第二次调用这个函数的时候,这个静态的局部对象它已经存在了。所以不管后边对这个函数调用多少次,和第一次调用的时候是一样的,得到的是同一块内存地址。只不过,这个ConnPool类型的对象的访问类型是受限的。只能够在当前的函数里边被访问。调用getConnPool函数,把这个pool地址返回给函数的调用者,就可以得到这个类唯一的实例。
另外,在实现一个单例类的时候,除了把构造函数设为私有的(private)。还有需要注意一点:通过拷贝构造函数也可以创建出对应的实例对象,所以应该把拷贝构造函数也设置成私有的(private)。或者说把这个拷贝构造函数直接删除掉。
如何删除拷贝构造函数呢?在C++11里边提供了=delete可以把对应的函数显示的删除。当把这个函数删除了,我们就不能在程序中再次使用这个函数了。
除了删除构造函数,还有一个需要删除的就是拷贝赋值运算符重载函数。如果我们创建一个类,在这个类里边其实是给我们提供了六个默认的函数:
- 无参的构造函数
- 析构函数
- 拷贝构造函数
- 移动构造函数
- 拷贝赋值运算符重载函数
- 移动赋值操作符重载
通过这个拷贝赋值运算符重载函数,也就是通过等号=,我们就能够创建出一个新的对象,其实和拷贝构造函数实现的功能是一样的。
移动赋值操作符重载,它的功能呢和移动构造函数是差不多的,移动赋值操作符重载函数,它重载的也是等号操作符,只不过它和赋值操作符重载的函数的参数是不一样的。移动赋值操作符重载和移动构造函数,它们实现的是资源的转移,而不是进行数据的拷贝。所以要把拷贝赋值运算符重载对应的等号操作符函数删除掉。其实设置为私有也可以防止对象的复制。
class ConnPool {
public:
static ConnPool* getConnPool();// 获得单例对象
ConnPool(const ConnPool& obj) = delete; // 删除拷贝构造函数
ConnPool& operator=(const ConnPool& obj) = delete; // 删除拷贝赋值运算符重载函数
private:
ConnPool(); // 构造函数私有化
};?>>添加和解析配置文件
jsoncpp的编译和使用 | 爱编程的大丙 (subingwen.cn)![]() https://www.subingwen.cn/cpp/jsoncpp/
https://www.subingwen.cn/cpp/jsoncpp/
bool parseJsonFile(); // 解析json格式文件ConnPool::ConnPool() {
// 加载配置文件
if (!parseJsonFile()) {
std::cout << "加载配置文件失败!!!" << std::endl;
return;
}
for (int i = 0; i < m_minSize; ++i) {
addConn();
}
thread producer(&ConnPool::produceConn, this);// 生产连接
thread recycler(&ConnPool::recycleConn, this);// 销毁连接
producer.detach();
recycler.detach();
}>>添加连接到连接池
void addConn(); // 添加数据库连接// 添加连接到连接池
void ConnPool::addConn() {
MysqlConn* conn = new MysqlConn;
conn->connect(m_user, m_passwd, m_dbName, m_ip, m_port);
conn->refreshAliveTime();// 记录建立连接的时候的对应的时间戳
m_connQ.push(conn);
}?>>单例类的构造函数处理
需要实时检测连接池里边的连接空闲数量是否太多了,如果太多了就需要销毁一部分。关于连接池里边的连接的创建和销毁需要交给两个线程去处理。通过这种方式,可以让数据库连接池里边的连接数量维持在一个合理的范围内。?
- 一个创建新的连接,一个销毁空闲的连接。
- 注:线程在阻塞的时候是不消耗CPU资源的。
ConnPool(); // 构造函数私有化ConnPool::ConnPool() {
// 加载配置文件
if (!parseJsonFile()) {
std::cout << "加载配置文件失败!!!" << std::endl;
return;
}
for (int i = 0; i < m_minSize; ++i) {
addConn();
}
thread producer(&ConnPool::produceConn, this);// 生产连接
thread recycler(&ConnPool::recycleConn, this);// 销毁连接
producer.detach();
recycler.detach();
}>>数据库连接池子线程任务函数的实现
(1)生产数据库连接
void produceConn(); // 生产数据库连接当连接池队列里边的这个连接的个数小于最小连接数的时候,连接不够用了。因为连接池里边需要保持一个最小的连接数,当实际数量<最小连接数的时候,需要生产出新的连接。
- 当实际数量>=最小连接数的时候,生产连接的线程它就需要阻塞了。
void ConnPool::produceConn() {
while (true) { // 生产者线程不断生产连接,直到连接池达到最大值
unique_lock<mutex> locker(m_mutexQ); // 加锁,保证线程安全
while (m_connQ.size() >= m_minSize) {
m_cond.wait(locker); // 等待消费者通知
}
addConn(); // 生产连接
m_cond.notify_all();// 通知消费者(唤醒)
}
}?(2)销毁数据库连接
void recycleConn(); // 销毁数据库连接// 回收数据库连接
void ConnPool::recycleConn() {
while (true) {
this_thread::sleep_for(chrono::milliseconds(500));// 每隔半秒钟检测一次
lock_guard<mutex> locker(m_mutexQ); // 加锁,保证线程安全
while (m_connQ.size() > m_minSize) { // 如果连接池中的连接数大于最小连接数,则回收连接
MysqlConn* conn = m_connQ.front(); // 取出连接池中的连接
if (conn->getAliveTime() >= m_maxIdleTime) {
m_connQ.pop(); // 回收连接
delete conn; // 释放连接资源
}
else {
break; // 如果连接的空闲时间小于最大空闲时间,则跳出循环
}
}
}
}>>数据库连接的获取和回收
shared_ptr<MysqlConn> getConn(); // 从连接池中取出一个连接// 从连接池中取出一个连接
shared_ptr<MysqlConn> ConnPool::getConn() {
unique_lock<mutex> locker(m_mutexQ);
while (m_connQ.empty()) {
if (cv_status::timeout == m_cond.wait_for(locker, chrono::milliseconds(m_timeout))) {
if (m_connQ.empty()) {
//return nullptr;
continue;
}
}
}
shared_ptr<MysqlConn>connptr(m_connQ.front(), [this](MysqlConn* conn) {
lock_guard<mutex>locker(m_mutexQ); // 自动管理加锁和解锁
conn->refreshAliveTime();// 更新连接的起始的空闲时间点
m_connQ.push(conn); // 回收数据库连接,此时它再次处于空闲状态
});// 智能指针
m_connQ.pop();
m_cond.notify_one(); // 本意是唤醒生产者
return connptr;
}当对应的线程把连接conn拿走之后,操作完了。数据库需要把这个连接还回来,有两种解决方案:
- 提供一个额外的函数,给这个函数指定一个参数,当这个线程把数据库连接用完之后,它通过参数把这个连接传进来,那么我们再把这个连接存储到数据库连接池对应的队列里边。
- 使用智能指针,就不需要提供一个额外的函数了。直接通过getConn函数就能够实现数据库连接回收这个功能了。
首先,把返回的指针通过智能指针管理起来,这个智能指针有两种:一种是共享的智能指针,还有一种是独占的智能指针。在本项目中这里就使用共享指针就可以了。
为了实现数据库连接的自动回收,当共享的智能指针对应的对象析构的时候,它会先析构它管理的指针,而这个指针指向的连接我们不需要让它析构的,因为我们使用数据库连接池的目的是避免数据库连接的频繁创建和销毁,那怎么办呢?
由于当共享指针对象析构的时候,不需要把智能指针管理的连接(地址)析构,而是回收。因此我们可以手动去指定这个共享的智能指针它的删除器对应的处理动作。?
在构造这个智能指针的时候,在它构造函数的第二个参数位置指定删除器,可以指定一个有名函数,也可以指定一个匿名函数。简单的方式就是写一个匿名函数。在匿名函数的中括号里边可以指定匿名函数内部它捕捉外部变量的方式 。如果指定this就在匿名函数内部可以使用当前类里边的所有的程序变量或者是程序函数。删除器的类型和它管理的这块内存地址的类型肯定是对应的。在匿名函数里边,并不是真正的要销毁这个指针指向的那块内存,而是要把它放到数据库连接池对应的队列里边。回收数据库连接,此时它再次处于空闲状态,还需要更新连接的起始的空闲时间点。?
>>数据库连接池的资源释放
// 释放数据库连接
~MysqlConn();// 释放数据库连接
MysqlConn::~MysqlConn() {
if (m_conn != nullptr) {
mysql_close(m_conn);
}
freeResult();
}>>测试数据库的数据插入和查询
int query() {
MysqlConn conn;
conn.connect("heheda", "123456", "test", "127.0.0.1", 3306);
string sql = "insert into person values(6,35,'女','乌拉那拉皇后')";
bool flag = conn.update(sql);
if (flag) cout << "插入数据成功了!!!" << endl;
else cout << "插入数据失败,耐心检查一下哪里有出差错喔!" << endl;
sql = "select * from person";
conn.query(sql);
while (conn.next()) {
cout << conn.value(0) << ", "
<< conn.value(1) << ", "
<< conn.value(2) << ", "
<< conn.value(3) << endl;
}
return 0;
}>>两个op函数,用于测试的
void op1(int begin, int end) {
for (int i = begin; i < end; ++i) {
MysqlConn conn;
conn.connect("heheda", "123456", "test", "127.0.0.1", 3306);
char sql[1024] = { 0 };
sprintf(sql, "insert into person (id,age,sex,name) values(%d,%d,'%s','%s')",
i, 6, "女", "胧月大魔王");
conn.update(sql);
}
}
void op2(ConnPool* pool, int begin, int end) {
for (int i = begin; i < end; ++i) {
shared_ptr<MysqlConn> conn = pool->getConn();
char sql[1024] = { 0 };
sprintf(sql, "insert into person (id,age,sex,name) values(%d,%d,'%s','%s')",
i, 19, "女", "安陵容");
conn->update(sql);
}
}?>>单线程模式下连接池和非连接池测试
void test1() {
#if 1
// 非连接池,单线程,用时:26276567700 纳秒, 26276 毫秒
steady_clock::time_point begin = steady_clock::now();
op1(0, 5000);
steady_clock::time_point end = steady_clock::now();
auto length = end - begin; // 计算时间差,得到操作耗时
cout << "非连接池,单线程,用时:" << length.count() << " 纳秒,"
<< length.count() / 1000000 << " 毫秒" << endl;
#else
//连接池,单线程,用时:6100671100 纳秒, 6100 毫秒
ConnPool* pool = ConnPool::getConnPool();
steady_clock::time_point begin = steady_clock::now();
op2(pool, 0, 5000);
steady_clock::time_point end = steady_clock::now();
auto length = end - begin; // 计算时间差,得到操作耗时
cout << "连接池,单线程,用时:" << length.count() << " 纳秒,"
<< length.count() / 1000000 << " 毫秒" << endl;
#endif
}
>>双线程模式下连接池和非连接池测试
void test2() {
#if 0
// 非连接池,多线程,用时:10107791500 纳秒,10107 毫秒
MysqlConn conn;
conn.connect("heheda", "123456", "test", "127.0.0.1", 3306);
steady_clock::time_point begin = steady_clock::now();
thread t1(op1, 0, 1000);
thread t2(op1, 1000, 2000);
thread t3(op1, 2000, 3000);
thread t4(op1, 3000, 4000);
thread t5(op1, 4000, 5000);
t1.join();
t2.join();
t3.join();
t4.join();
t5.join();
steady_clock::time_point end = steady_clock::now();
auto length = end - begin; // 计算时间差,得到操作耗时
cout << "非连接池,多线程,用时:" << length.count() << " 纳秒,"
<< length.count() / 1000000 << " 毫秒" << endl;
#else
// 连接池,多线程,用时:2411691800 纳秒,2411 毫秒
ConnPool* pool = ConnPool::getConnPool();
steady_clock::time_point begin = steady_clock::now();
thread t1(op2, pool, 0, 1000);
thread t2(op2, pool, 1000, 2000);
thread t3(op2, pool, 2000, 3000);
thread t4(op2, pool, 3000, 4000);
thread t5(op2, pool, 4000, 5000);
t1.join();
t2.join();
t3.join();
t4.join();
t5.join();
steady_clock::time_point end = steady_clock::now();
auto length = end - begin; // 计算时间差,得到操作耗时
cout << "连接池,多线程,用时:" << length.count() << " 纳秒,"
<< length.count() / 1000000 << " 毫秒" << endl;
#endif
}完整代码:
- main.cpp
#include <iostream>
#include <memory>
#include "MysqlConn.h"
#include "ConnPool.h"
using namespace std;
// 1.单线程:使用/不适用连接池
// 2.多线程:使用/不适用连接池
void op1(int begin, int end) {
for (int i = begin; i < end; ++i) {
MysqlConn conn;
conn.connect("heheda", "123456", "test", "127.0.0.1", 3306);
char sql[1024] = { 0 };
sprintf(sql, "insert into person (id,age,sex,name) values(%d,%d,'%s','%s')",
i, 6, "女", "胧月大魔王");
conn.update(sql);
}
}
void op2(ConnPool* pool, int begin, int end) {
for (int i = begin; i < end; ++i) {
shared_ptr<MysqlConn> conn = pool->getConn();
char sql[1024] = { 0 };
sprintf(sql, "insert into person (id,age,sex,name) values(%d,%d,'%s','%s')",
i, 19, "女", "安陵容");
conn->update(sql);
}
}
// 压力测试
void test1() {
#if 1
// 非连接池,单线程,用时:26276567700 纳秒, 26276 毫秒
steady_clock::time_point begin = steady_clock::now();
op1(0, 5000);
steady_clock::time_point end = steady_clock::now();
auto length = end - begin; // 计算时间差,得到操作耗时
cout << "非连接池,单线程,用时:" << length.count() << " 纳秒,"
<< length.count() / 1000000 << " 毫秒" << endl;
#else
//连接池,单线程,用时:6100671100 纳秒, 6100 毫秒
ConnPool* pool = ConnPool::getConnPool();
steady_clock::time_point begin = steady_clock::now();
op2(pool, 0, 5000);
steady_clock::time_point end = steady_clock::now();
auto length = end - begin; // 计算时间差,得到操作耗时
cout << "连接池,单线程,用时:" << length.count() << " 纳秒,"
<< length.count() / 1000000 << " 毫秒" << endl;
#endif
}
void test2() {
#if 0
// 非连接池,多线程,用时:10107791500 纳秒,10107 毫秒
MysqlConn conn;
conn.connect("heheda", "123456", "test", "127.0.0.1", 3306);
steady_clock::time_point begin = steady_clock::now();
thread t1(op1, 0, 1000);
thread t2(op1, 1000, 2000);
thread t3(op1, 2000, 3000);
thread t4(op1, 3000, 4000);
thread t5(op1, 4000, 5000);
t1.join();
t2.join();
t3.join();
t4.join();
t5.join();
steady_clock::time_point end = steady_clock::now();
auto length = end - begin; // 计算时间差,得到操作耗时
cout << "非连接池,多线程,用时:" << length.count() << " 纳秒,"
<< length.count() / 1000000 << " 毫秒" << endl;
#else
// 连接池,多线程,用时:2411691800 纳秒,2411 毫秒
ConnPool* pool = ConnPool::getConnPool();
steady_clock::time_point begin = steady_clock::now();
thread t1(op2, pool, 0, 1000);
thread t2(op2, pool, 1000, 2000);
thread t3(op2, pool, 2000, 3000);
thread t4(op2, pool, 3000, 4000);
thread t5(op2, pool, 4000, 5000);
t1.join();
t2.join();
t3.join();
t4.join();
t5.join();
steady_clock::time_point end = steady_clock::now();
auto length = end - begin; // 计算时间差,得到操作耗时
cout << "连接池,多线程,用时:" << length.count() << " 纳秒,"
<< length.count() / 1000000 << " 毫秒" << endl;
#endif
}
int query() {
MysqlConn conn;
conn.connect("heheda", "123456", "test", "127.0.0.1", 3306);
string sql = "insert into person values(6,35,'女','乌拉那拉皇后')";
bool flag = conn.update(sql);
if (flag) cout << "插入数据成功了!!!" << endl;
else cout << "插入数据失败,耐心检查一下哪里有出差错喔!" << endl;
sql = "select * from person";
conn.query(sql);
while (conn.next()) {
cout << conn.value(0) << ", "
<< conn.value(1) << ", "
<< conn.value(2) << ", "
<< conn.value(3) << endl;
}
return 0;
}
int main() {
//SetConsoleOutputCP(CP_UTF8);
//query();
//test1();
test2();
return 0;
}- MysqlConn.h
#pragma once
#include <mysql.h>
#include <string>
#include <chrono>
using namespace std;
using namespace std::chrono;
class MysqlConn {
public:
// 初始化数据库连接
MysqlConn();
// 释放数据库连接
~MysqlConn();
// 连接数据库
bool connect(string user, string passwd, string dbName, string ip, unsigned short port = 3306);
// 更新数据库: select,update,delete
bool update(string sql);
// 查询数据库
bool query(string sql);
// 遍历查询得到的结果集
bool next();
// 得到结果集中的字段值
string value(int index);
// 事务操作
bool transaction();
// 提交事务
bool commit();
// 事务回滚
bool rollback();
// 刷新起始的空闲时间点
void refreshAliveTime();
// 计算连接存活的总时长
long long getAliveTime();
private:
void freeResult();
MYSQL* m_conn = nullptr; // 数据库连接
MYSQL_RES* m_result = nullptr;
MYSQL_ROW m_row = nullptr;
steady_clock::time_point m_aliveTime;
};- MysqlConn.cpp
#include "MysqlConn.h"
// 初始化数据库连接
MysqlConn::MysqlConn() {
m_conn = mysql_init(nullptr);
mysql_set_character_set(m_conn, "GBK"); // 设置字符集
}
// 释放数据库连接
MysqlConn::~MysqlConn() {
if (m_conn != nullptr) {
mysql_close(m_conn);
}
freeResult();
}
// 连接数据库
bool MysqlConn::connect(string user, string passwd, string dbName, string ip, unsigned short port) {
MYSQL* ptr = mysql_real_connect(m_conn, ip.c_str(), user.c_str(), passwd.c_str(), dbName.c_str(), port, nullptr, 0);
return ptr != nullptr;
}
// 更新数据库:insert,update,delete
bool MysqlConn::update(string sql) {
if (mysql_query(m_conn, sql.c_str())) {
return false;
}
return true;
}
// 查询数据库
bool MysqlConn::query(string sql) {
freeResult(); // 释放之前查询的结果集
if (mysql_query(m_conn, sql.c_str())) {
return false;
}
m_result = mysql_store_result(m_conn); // 获取查询结果
return true;
}
// 遍历查询得到的结果集
bool MysqlConn::next() {
if (m_result != nullptr) {
m_row = mysql_fetch_row(m_result);
if (m_row != nullptr) {
return true;
}
}
return false;
}
// 得到结果集中的字段值
string MysqlConn::value(int index) {
int rowCount = mysql_num_fields(m_result);
if (index >= rowCount || index < 0) {
return string();
}
char* val = m_row[index];
unsigned long length = mysql_fetch_lengths(m_result)[index];
return string(val, length);
}
// 事务操作
bool MysqlConn::transaction() {
return mysql_autocommit(m_conn, false);
}
// 提交事务
bool MysqlConn::commit() {
return mysql_commit(m_conn);
}
// 事务回滚
bool MysqlConn::rollback() {
return mysql_rollback(m_conn);
}
// 刷新起始的空闲时间点
void MysqlConn::refreshAliveTime() {
// 这个时间戳就是某个数据库连接,它起始存活的时间点
// 这个时间点通过时间类就可以得到了
m_aliveTime = steady_clock::now();
}
// 计算连接存活的总时长
long long MysqlConn::getAliveTime() {
nanoseconds duration = steady_clock::now() - m_aliveTime;
milliseconds millsec = duration_cast<milliseconds>(duration);
return millsec.count();
}
void MysqlConn::freeResult() {
if (m_result != nullptr) {
mysql_free_result(m_result);
m_result = nullptr;
}
}
- ConnPool.h
#pragma once
#include <queue>
#include <mutex>
#include <condition_variable>//条件变量
#include "MysqlConn.h"
using namespace std;
class ConnPool {
public:
static ConnPool* getConnPool();// 获得单例对象
ConnPool(const ConnPool& obj) = delete; // 删除拷贝构造函数
ConnPool& operator=(const ConnPool& obj) = delete; // 删除拷贝赋值运算符重载函数
shared_ptr<MysqlConn> getConn(); // 从连接池中取出一个连接
~ConnPool(); // 析构函数
private:
ConnPool(); // 构造函数私有化
bool parseJsonFile(); // 解析json格式文件
void produceConn(); // 生产数据库连接
void recycleConn(); // 销毁数据库连接
void addConn(); // 添加数据库连接
// 连接服务器所需信息
string m_ip; // 数据库服务器ip地址
string m_user; // 数据库服务器用户名
string m_dbName; // 数据库服务器的数据库名
string m_passwd; // 数据库服务器密码
unsigned short m_port; // 数据库服务器绑定的端口
// 连接池信息
queue<MysqlConn*> m_connQ;
unsigned int m_maxSize; // 连接数上限值
unsigned int m_minSize; // 连接数下限值
int m_timeout; // 连接超时时长
int m_maxIdleTime; // 最大的空闲时长
mutex m_mutexQ; // 独占互斥锁
condition_variable m_cond; // 条件变量
};- ConnPool.cpp
#include "ConnPool.h"
#include <json/json.h>
#include <fstream>
#include <thread>
#include <iostream>
using namespace Json;
ConnPool* ConnPool::getConnPool() {
static ConnPool pool;
return &pool;
}
// 从连接池中取出一个连接
shared_ptr<MysqlConn> ConnPool::getConn() {
unique_lock<mutex> locker(m_mutexQ);
while (m_connQ.empty()) {
if (cv_status::timeout == m_cond.wait_for(locker, chrono::milliseconds(m_timeout))) {
if (m_connQ.empty()) {
//return nullptr;
continue;
}
}
}
shared_ptr<MysqlConn>connptr(m_connQ.front(), [this](MysqlConn* conn) {
lock_guard<mutex>locker(m_mutexQ); // 自动管理加锁和解锁
conn->refreshAliveTime();// 更新连接的起始的空闲时间点
m_connQ.push(conn); // 回收数据库连接,此时它再次处于空闲状态
});// 智能指针
m_connQ.pop();
m_cond.notify_one(); // 本意是唤醒生产者
return connptr;
}
ConnPool::~ConnPool() {
while (!m_connQ.empty()) {
MysqlConn* conn = m_connQ.front();
m_connQ.pop();
delete conn;
}
}
ConnPool::ConnPool() {
// 加载配置文件
if (!parseJsonFile()) {
std::cout << "加载配置文件失败!!!" << std::endl;
return;
}
for (int i = 0; i < m_minSize; ++i) {
addConn();
}
thread producer(&ConnPool::produceConn, this);// 生产连接
thread recycler(&ConnPool::recycleConn, this);// 销毁连接
producer.detach();
recycler.detach();
}
bool ConnPool::parseJsonFile() {
ifstream ifs("dbconf.json");
Reader rd;
Value root;
rd.parse(ifs, root);
if (root.isObject()) {
std::cout << "开始解析配置文件..." << std::endl;
m_ip = root["ip"].asString();
m_port = root["port"].asInt();
m_user = root["userName"].asString();
m_passwd = root["password"].asString();
m_dbName = root["dbName"].asString();
m_minSize = root["minSize"].asInt();
m_maxSize = root["maxSize"].asInt();
m_maxIdleTime = root["maxIdleTime"].asInt();
m_timeout = root["timeout"].asInt();
return true; // 解析成功返回true,否则返回false。
}
return false;
}
void ConnPool::produceConn() {
while (true) { // 生产者线程不断生产连接,直到连接池达到最大值
unique_lock<mutex> locker(m_mutexQ); // 加锁,保证线程安全
while (m_connQ.size() >= m_minSize) {
m_cond.wait(locker); // 等待消费者通知
}
addConn(); // 生产连接
m_cond.notify_all();// 通知消费者(唤醒)
}
}
// 回收数据库连接
void ConnPool::recycleConn() {
while (true) {
this_thread::sleep_for(chrono::milliseconds(500));// 每隔半秒钟检测一次
lock_guard<mutex> locker(m_mutexQ); // 加锁,保证线程安全
while (m_connQ.size() > m_minSize) { // 如果连接池中的连接数大于最小连接数,则回收连接
MysqlConn* conn = m_connQ.front(); // 取出连接池中的连接
if (conn->getAliveTime() >= m_maxIdleTime) {
m_connQ.pop(); // 回收连接
delete conn; // 释放连接资源
}
else {
break; // 如果连接的空闲时间小于最大空闲时间,则跳出循环
}
}
}
}
// 添加连接到连接池
void ConnPool::addConn() {
MysqlConn* conn = new MysqlConn;
conn->connect(m_user, m_passwd, m_dbName, m_ip, m_port);
conn->refreshAliveTime();// 记录建立连接的时候的对应的时间戳
m_connQ.push(conn);
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 原型设计 Axure RP 9
- 202352读书笔记|踪迹——在繁星般的黄的交错里,秦淮河仿佛笼上了一团光雾
- Qt连接数据库(内含完整安装包)
- 英语词性后缀
- Hyperledger Fabric 权限策略和访问控制
- 22、商城系统(四):项目jar包配置(重要),网关配置,商品服务基础数据设置
- 数字化风潮下的全球跨境电商演进:2024年趋势前瞻
- 重要文档如何防泄露?天锐绿盾加密软件,你一定要知道!
- Spring 注解 和SpringMVC注解
- 5-1,ZZ004 新型电力系统运行与维护赛题第五套