【C语言编程之旅 5】刷题篇-if语句
第1题

解析
上述代码本来的想法应该是:循环10次,每次循环时如果i==5则打印i的结果。
但if语句中表达式的==写成了赋值,相当于每次循环尽量都是将i的值设置成了5,5为真,因此每次都会打印5
i每次修改成5打印后,i的值永远不会等于10,因此造成死循环
故:死循环的打印5
因此:选择C
第2题

解析
答案解析:
A:错误,if之后可以跟多条语句,跟多条语句时需要使用{}括起来
B:错误,0表示假,非零表示真
C:正确
D:不一定,要看具体的代码,如果代码不规范,可能没有对齐,比如:

上述else虽然是和外层if对齐,但是会和内部if进行匹配。
因此,选C
第3题

解析
switch的每个case之后如果没有加break语句,当前case执行结束后,会继续执行紧跟case中的语句。
func(1)可知,在调用func时形参a的值为1,switch(a)<==>switch(1),case 1被命中,因为该switch语句中所有分支下都没有增加break语句,因此会从上往下顺序执行,最后执行default中语句返回。
因此:选择D
第4题

解析
switch语句中表达式的类型只能是:整形和枚举类型
D选项为浮点类型,不是整形和枚举类型
第5题
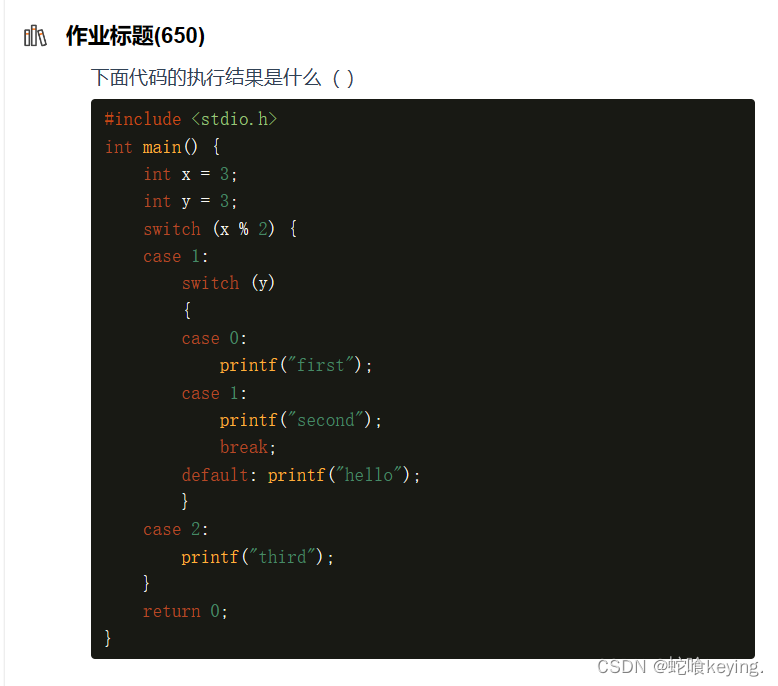

解析
switch语句时多分支的选择语句,switch中表达式结果命中那个case,就执行该case子项,如果case子项后没有跟break语句,则继续往下执行。
关于该题解析,请看以下注解:
#include <stdio.h>
int main() {
int x = 3;
int y = 3;
switch (x % 2) { // x%2的结果为1,因此执行case1
case 1:
switch (y) // y是3,因此会执行case3,而case3不存在,那只能执行default
{
case 0:
printf("first");
case 1:
printf("second");
break;
default: printf("hello"); // 打印hello,打印完之后,内部switch结束,此时外部case1结束
} // 因为外部case1之后没有添加break语句,所以继续执行case2
case 2: // 打印third
printf("third"); // 外部switch结束
}
return 0;
}
即:先在内部switch的default位置打印hello,紧接着在外部case2中打印third
因此:选择D
第6题

解析
while(条件表达式)
循环体
while循环中,当条件表达式成立时,才会执行循环体中语句,每次执行期间,都会对循环因子进行修改(否则就成为死循环),修改完成后如果while条件表达式成立,继续循环,如果不成立,循环结束
故:while循环条件将会比循环体多执行一次。
因此:选择B
第7题


解析
参考代码注释
#include <stdio.h>
int main()
{
int a = 0, b = 0;
// for循环将a和b的初始值均设置为1
for (a = 1, b = 1; a <= 100; a++)
{
if (b >= 20) break;
if (b % 3 == 1)
{
b = b + 3;
continue;
}
b = b-5;
}
printf("%d\n", a);
return 0;
}
第一次循环:a = 1,b=1—>b小于20,if不成立,b%3= =1%3==1成立,b=b+3, 此时b的值为4
第一次循环:a = 2,b=4—>b小于20,if不成立,b%3= =4%3==1成立,b=b+3, 此时b的值为7
第一次循环:a = 3,b=7—>b小于20,if不成立,b%3= =7%3==1成立,b=b+3, 此时b的值为10
第一次循环:a = 4,b=10—>b小于20,if不成立,b%3= =10%3==1成立,b=b+3, 此时b的值为13
第一次循环:a = 5,b=13—>b小于20,if不成立,b%3= =13%3==1成立,b=b+3, 此时b的值为16
第一次循环:a = 6,b=16—>b小于20,if不成立,b%3= =16%3==1成立,b=b+3, 此时b的值为19
第一次循环:a = 7,b=19—>b小于20,if不成立,b%3= =19%3==1成立,b=b+3, 此时b的值为22
第一次循环:a = 8,b=22—>b大于20,if成立,循环break提出
最后打印a:8
因此:选择C
第8题

解析
答案解析:
A:正确,可以放在任意位置,但是一般建议最好还是放在最后
B:正确,case语句后一般放整形结果的常量表达式或者枚举类型,枚举类型也可以看成是一个特殊的常量
C:错误,没有规定case必须在default之前,一般case最好放在default之前
D:正确,但一般还是按照次序来
因此:选择C
第9题

解析
/*
解题思路:
1. 3的倍数一定能够被3整除,因此i%3==0表达式成立时,则i一定是3的倍数
2. 要输出1~100之间的3的倍数,那只需要从1~100循环100次即可,每次拿到i之后,用i%3==0检测
如果成立:i是3的倍数,输出
如果不成立:i不是3的倍数
*/
#include <stdio.h>
int main()
{
int i = 0;
for(i=1; i<=100; i++)
{
if(i%3==0)
{
printf("%d ", i);
}
}
return 0;
}
第10题

解析
/*
思路:
该题比较简单,参考代码
*/
#include <stdio.h>
int main()
{
int a = 2;
int b = 3;
int c = 1;
scanf("%d%d%d",&a, &b,&c);
if(a<b)
{
int tmp = a;
a = b;
b = tmp;
}
if(a<c)
{
int tmp = a;
a = c;
c = tmp;
}
if(b<c)
{
int tmp = b;
b = c;
c = tmp;
}
printf("a=%d b=%d c=%d\n", a, b, c);
return 0;
}
第11题

解析
思路:
素数:即质数,除了1和自己之外,再没有其他的约数,则该数据为素数,具体方式如下
方法一:试除法
int main()
{
int i = 0;
int count = 0;
// 外层循环用来获取100~200之间的所有数据,100肯定不是素数,因此i从101开始
for(i=101; i<=200; i++)
{
//判断i是否为素数:用[2, i)之间的每个数据去被i除,只要有一个可以被整除,则不是素数
int j = 0;
for(j=2; j<i; j++)
{
if(i%j == 0)
{
break;
}
}
// 上述循环结束之后,如果j和i相等,说明[2, i)之间的所有数据都不能被i整除,则i为素数
if(j==i)
{
count++;
printf("%d ", i);
}
}
printf("\ncount = %d\n", count);
return 0;
}
上述方法的缺陷:超过i一半的数据,肯定不是i的倍数,上述进行了许多没有意义的运算,因此可以采用如下方式进行优化。
方法二:每拿到一个数据,只需要检测其:[2, i/2]区间内是否有元素可以被2i整除即可,可以说明i不是素数。
int main()
{
int i = 0;//
int count = 0;
for(i=101; i<=200; i++)
{
//判断i是否为素数
//2->i-1
int j = 0;
for(j=2; j<=i/2; j++)
{
if(i%j == 0)
{
break;
}
}
//...
if(j>i/2)
{
count++;
printf("%d ", i);
}
}
printf("\ncount = %d\n", count);
return 0;
}
方法二还是包含了一些重复的数据,再优化
方法三:如果i能够被[2, sqrt(i)]之间的任意数据整除,则i不是素数
原因:如果 m 能被 2 ~ m-1 之间任一整数整除,其二个因子必定有一个小于或等于sqrt(m),另一个大于或等于 sqrt(m)。
int main()
{
int i = 0;
int count = 0;
for(i=101; i<=200; i++)
{
//判断i是否为素数
//2->i-1
int j = 0;
for(j=2; j<=sqrt(i); j++)
{
if(i%j == 0)
{
break;
}
}
//...
if(j>sqrt(i))
{
count++;
printf("%d ", i);
}
}
printf("\ncount = %d\n", count);
return 0;
}
方法4
继续对方法三优化,只要i不被[2, sqrt(i)]之间的任何数据整除,则i是素数,但是实际在操作时i不用从101逐渐递增到200,因为除了2和3之外,不会有两个连续相邻的数据同时为素数
int main()
{
int i = 0;
int count = 0;
for(i=101; i<=200; i+=2)
{
//判断i是否为素数
//2->i-1
int j = 0;
for(j=2; j<=sqrt(i); j++)
{
if(i%j == 0)
{
break;
}
}
//...
if(j>sqrt(i))
{
count++;
printf("%d ", i);
}
}
printf("\ncount = %d\n", count);
return 0;
}
在这段代码中,使用了步长为2的循环(for(i=101; i<=200; i+=2))。这是因为在偶数范围内,除了2以外的所有偶数都是非素数,因为它们至少可以被2整除。因此,通过跳过所有偶数,可以减少循环的次数,提高代码的效率。
具体来说,步长为2的循环使得 i 的值只取奇数。在奇数范围内,可以避免检查偶数,因为除了2以外的偶数不可能是素数。这样可以节省一些不必要的循环迭代,从而提高算法的性能。
总结起来,步长为2的循环是一种优化手段,通过减少不必要的检查,加快素数的筛选过程。
第12题

解析
思路:
要求1000年到2000年之间的闰年,只需要知道求解闰年的方法即可。
闰年的条件:如果N能够被4整除,并且不能被100整除,则是闰年。或者:N能被400整除,也是闰年
即:4年一润并且百年不润,每400年再润一次。
#include <stdio.h>
int main()
{
int year = 0;
for(year=1000; year<=2000; year++)
{
//判断year是否为闰年
if(year%4==0) // 如果year能够被4整除,year可能为闰年
{
if(year%100!=0) // 如果year不能内100整除,则一定是闰年
{
printf("%d ", year);
}
}
if(year%400 == 0) // 每400年再润一次
{
printf("%d ", year);
}
}
return 0;
}
第13题

解析
最大公约数:即两个数据中公共约数的最大者。
求解的方式比较多,暴力穷举、辗转相除法、更相减损法、Stein算法算法
此处主要介绍:辗转相除法
思路:
例子:18和24的最大公约数
第一次:a = 18 b = 24 c = a%b = 18%24 = 18
循环中:a = 24 b=18
第二次:a = 24 b = 18 c = a%b = 24%18 = 6
循环中:a = 18 b = 6
第三次:a = 18 b = 6 c=a%b = 18%6 = 0
循环结束
此时b中的内容即为两个数中的最大公约数。
int main()
{
int a = 18;
int b = 24;
int c = 0;
while(c=a%b)
{
a = b;
b = c;
}
printf("%d\n", b);
return 0;
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 跟着cherno手搓游戏引擎【9】glm配置
- MultipartFile 和@RequestBody不能同时使用
- pytest -- 进阶使用详解
- Kubernetes-持久卷(PV、PVC)
- Python中itertools 模块的用法
- paddlepaddle在执行loss.item()的时候,报错an illegal memory access was encountered.
- 前端JS实现全屏和退出全屏的效果
- Day4Qt
- JavaEE是什么?它有什么功能?值不值得我们去学习?我们该如何去学习呢?
- Pytest中conftest.py的用法