计算机视觉基础(13)——深度估计
前言
本节是计算机视觉的最后一节,我们将学习深度估计。从深度的概念和度量入手,依次学习单目深度估计和双目/多目深度估计,需要知道深度估计的经典方法,掌握深度估计的评价标准,注意结合对极几何进行分析和思考。
一、深度的概念和度量方式
1.1? 深度的概念

- 深度指场景中物体表面到相机的距离,即图中𝑷 (𝑐)点的𝑍 (𝑐)坐标
- 采用深度图(Depth Map)表征,图中每点的取值代表对应像素的深度值
1.2? 深度的度量方式与设备
1.2.1? 结构光
- 结构光:将特殊结构图案(如离散光斑、条纹、编码结构光等)投影到空间物体表面上,用另一个相机观察在三维物理表面成像的畸变情况,进行图像匹配比较并计算出深度
- 属于主动光探测方案
- 技术成熟、便携、低延时,适用于较近距离

1.2.2? ToF
- Time-of-Flight (ToF):向目标连续发送光脉冲,用传感器接收从物体返回的光,通过探测光脉冲的往返飞行时间测距
- 属于主动光探测方案
- 适用于较远距离,传感器复杂、成本高、深度图稀疏

1.2.3? 双目视觉
- 双目视觉技术:利用两个标定好的RGB摄像头采集图像,通过匹配对应点,获取的二维图像像素点的深度
- 属于被动光探测方案
- 精度依赖于双目匹配算法,易受到光照变化等因素影响,适用于较近距离
- 但是,遇到重复纹理、?边缘特征时,识别的效果就会很差

二、计算机视觉中的深度估计问题
深度估计:设计计算机视觉算法,根据输入图像,估计出对应的深度图。

根据输入图像的数目分为单目深度估计(Monocular)、双目深度估计(Binocular)、多视角立体视觉 (Multi-View Stereo, MVS)。
与基于传感器硬件的解决方案相比,软件算法的深度估计方案成本较低

三、深度估计的应用
3.1? 自动驾驶、机器人导航

3.2? 3D重构(三维建模、三维地图、3D打印)



3.3? 增强现实


3.4? 单目3D拍照

3.5? 浅景深渲染

3.6??RGB-D 语义分割/目标检测/视觉跟踪
将深度作为额外的辅助信息应用在传统视觉任务中?RGB-D:RGB-D 语义分割/目标检测/视觉跟踪

四、单目深度估计
4.1? 单目深度估计的概念
? 目标:利用能够反映深度的线索/提示信息(Cues),从单幅图像中预测出对应的深度图
? 对弱纹理等挑战区域具有更强的鲁棒性
? 单目深度估计本身具有较强挑战性
4.2? 单目深度线索
4.2.1? 近大远小
近大远小:对常见物体的尺寸有大致的估计,根据其在图像中的大小,判断相对位置/距离

4.2.2? 纹理的丰富程度
纹理丰富程度:近距离的区域更为清晰,纹理也较为丰富。

4.2.3? 遮挡关系
遮挡关系:被遮挡的背景物体距离较远,前景距离较近

4.2.4? 平行线与消失点
平行线与消失点:在远离相机的过程中,3D空间的平行线在2D图像上的投影逐渐接近,直至相较于消失点

4.2.5? 光影/明暗/纹理
通过光影、明暗与纹理变化,可以轻易推断出物体的三维形状

4.3? 单目深度估计的主流方法
- 单目深度线索较为繁杂多样,手工设计的方法很难全面涵盖上述所有线索
- 卷积神经网络通过端到端数据驱动的方式,可以很好地学习并集成上述线索,并且适合处理二维图像数据,因而成为单目深度估计的主流方法
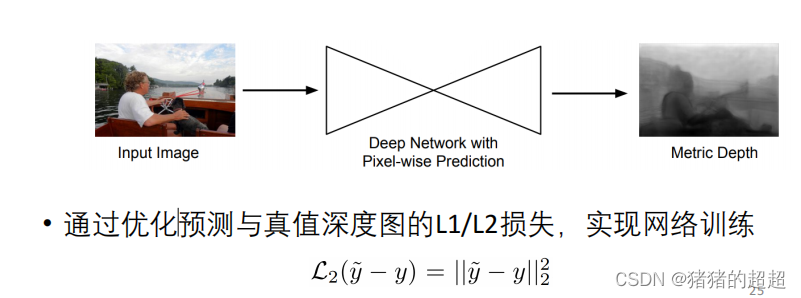
4.3.1? 基于卷积网络

4.3.2? 基于全卷积网络

4.3.3? 基于Transformer

4.3.4? 基于多任务

4.3.5? 基于弱监督
- 与分割、检测等数据不同,深度真值不适合手工标注,主要依赖于深度传感器采集
- 由于深度传感器应用场景受限,场景多样化的深度训练数据不易获取,导致模型的场景泛化性能较差

? 为解决上述问题,Chen et al. 于2016年提出一种人工标注稀疏深度真值的方法,即从每一张图像中随机选两点,人工标出两点对应的前后顺序
? 通过上述标注方法构建了Depth-in-the-Wild (DIW)数据集
? DIW数据集规模大(49.6万张图片),场景多样化,真值标注稀疏且是相对的 (每张只包含两个点的相对前后顺序)


? 由于每张图像仅包含一个深度真值,因而上述网络训练过程属于弱监督学习
? 由于DIW数据集场景多样化,即使采用弱监督学习,在DIW上训练的模型相较于其他数据集训练的模型具有更强的泛化性能

4.4? 相对深度估计



4.5? 常见的单目深度估计数据集

4.6? 常见的深度估计评价指标(重点)

五、双目/多目立体匹配
5.1? 双目/多目深度估计线索

5.2? 对极几何回顾

5.3? 特殊矫正后的情况
? 通过矫正两个相机的朝向与位置,使极线为水平线
? 同一点在两幅图中的视差 (Disparity) 𝑑 = 𝑥1 + 𝑥2 与其深度𝑍成反比



5.4? 未经矫正的情况


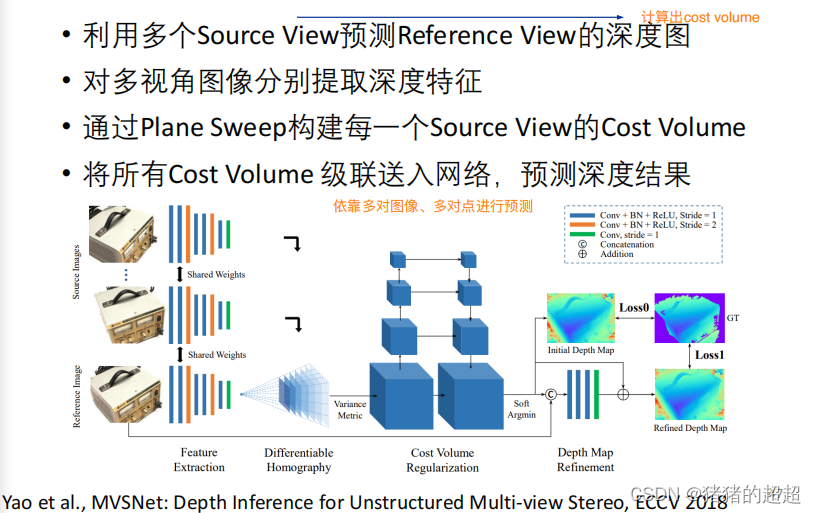
5.5? 基于深度学习的MVS:MVSNet
总结
在本节中,我们学习了深度估计的相关知识。读者需要重点掌握深度的概念和度量方式,单目深度估计和双目深度估计的主流方法,其中,深度估计的评价指标和对极几何是重点。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Hackathon | Mint Blockchain 启动全球 NIP 创意提案黑客松活动!
- 23.会话技术
- Mybatis-Plus基础之Mapper增删改
- Q-Tester:适用于开发、生产和售后的诊断测试软件
- UniApp小程序使用vant引入vant weapp
- java.io.IOException: Error: End-of-File, expected line at offset 5855
- 丢掉破解版,官方免费了!!!
- 145 删除链表的第N个节点的3种方式
- 数据库设计和数据库对象
- Hive数学函数讲解