MapReduce 初级编程实践
发布时间:2024年01月08日
(一)编程实现文件合并和去重操作**
对于两个输入文件,即文件 A 和文件 B,请编写 MapReduce 程序,对两个文件进行合并, 并剔除其中重复的内容,得到一个新的输出文件 C。下面是输入文件和输出文件的一个样例供参考。
输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 x
输入文件 B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 x
启动hadoop:
cd /usr/local/hadoop
./sbin/start-dfs.sh
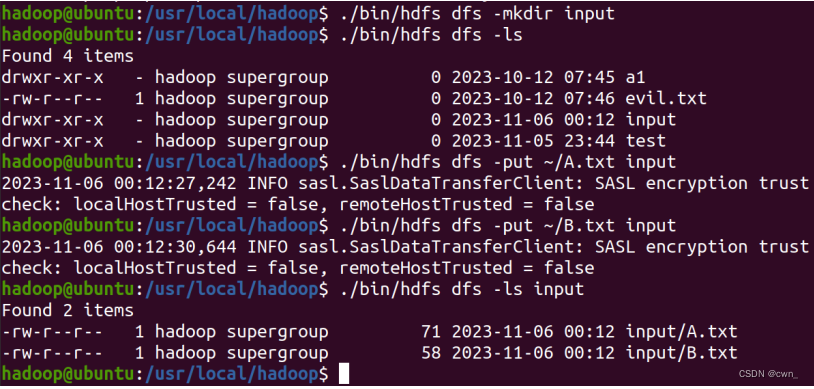
新建input文件夹,向hdfs上传文件,将家目录下的A.txt和B.txt上传到hdfs的/user/hadoop/input下
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -ls
./bin/hdfs dfs -put ~/A.txt input
./bin/hdfs dfs -put ~/B.txt input
./bin/hdfs dfs -ls input
启动eclipse,编程实现文件合并和去重操作:
package mapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MergeHeavy {
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text text = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
text = value;
context.write(text, new Text(""));
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context ) throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String[] otherArgs = new String[]{
"input","output"};
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
Job job = Job.getInstance(conf,"Merge and duplicate removal");//设置环境参数
job.setJarByClass(MergeHeavy.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);//设置输出类型
job.setOutputValue
文章来源:https://blog.csdn.net/whdehcy/article/details/135452664
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 云计算:OpenStack 分布式架构管理FLAT网络(单控制节点与多计算节点)
- 探索 Vue3 (四) keep-alive缓存组件
- 探索未知:最新发布的顶级浏览器,为你带来前所未有的浏览体验
- 【深度学习:数据增强】计算机视觉中数据增强的完整指南
- 深入探究 JavaScript 中的 String:常用方法和属性全解析(上)
- Java:语法速通
- springCould中的gateway-从小白开始【9】
- 数模学习day12-相关系数
- 2024.1.4 Spark Core ,RDD ,算子
- Python实现读取超100G的数据文件