【模型解析和使用教程】2023新论文:RAM++多模态图片识别,Recognize Anything Model Plus 模型解析和使用
-------------------------------------------------不可转载-----------------------------------------
Citation: 图片均来源于原文,请看Repo link
文章名字:Open-Set Image Tagging with Multi-Grained Text Supervision
模型名称:RAM++: Recognize Anything Model Plus (16 Nov 2023)
Repo Link: GitHub - xinyu1205/recognize-anything: Open-source and strong foundation image recognition models.
Open-Set → 一些机器学习方法只能学习到固定的标签信息(Pre-defined labels),Open-set指的是的没有预先定义的标签
Multi-Grained → grain是颗粒的意思,multi-grained 可以理解成不一样大小颗粒的信息,文中指 tag supervision 和 text supervision
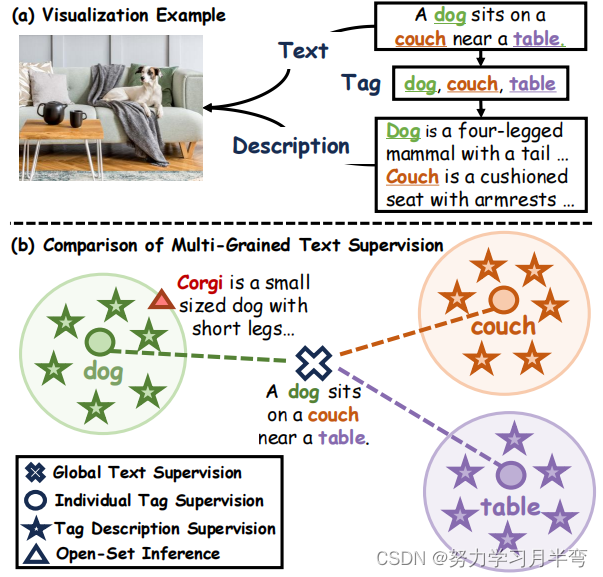 图1
图1
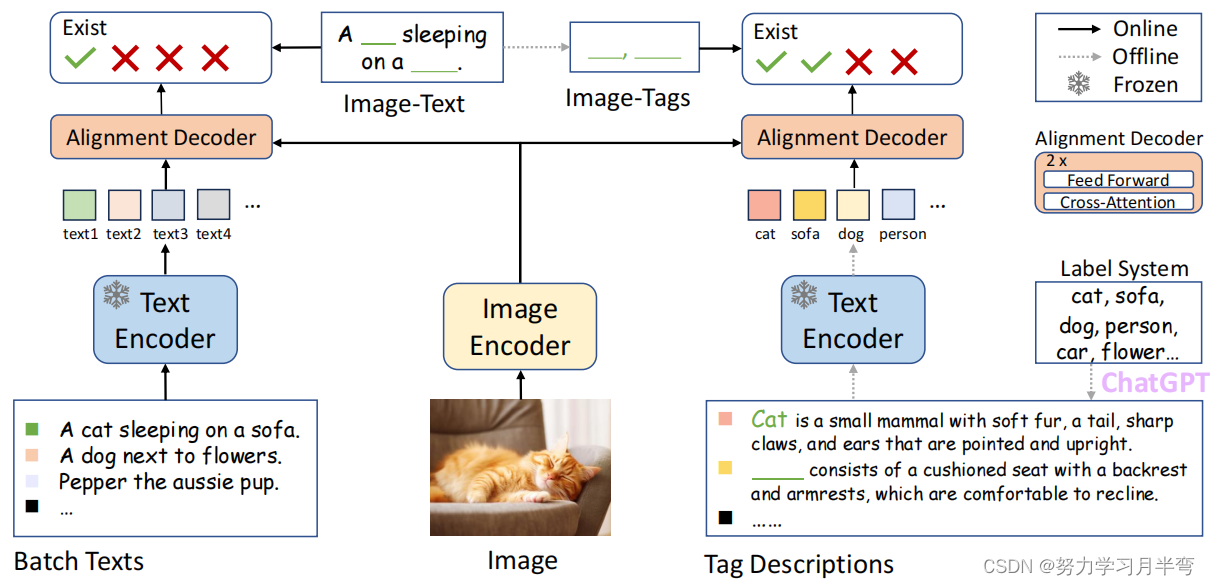 图2
图2
一、🐒文章亮点🐒:
- Multi-grained supervision: 这样做的优点是既能维持对既有标签的预测能力,又能扩展对开放集类别的预测能力。图一(a)中只用文本来做监督,然而一条文本里面涵盖了多个于一标签,这种监督方式削弱了各个标签对 embedding 的影响,导致在识别多种不一样的于一标签的时候不能做到最优。图一(b)展示了本文模型采用的 multi-grained supervision 形式,除了用 text (就是图2中的batch texts) 做监督以外还会用到 tag 做监督,作者还进一步使用 LLM 生成对tag的描述参与监督过程(图2右下角)
- 使用了大语言模型 LLM (该模型用的GPT-35-turbo) 对 tags 生成描述,增加了 tag 的视觉信息以用于监督。之前的学者也有用 tag description 做监督的,但是用的都是外部的自然语言数据集 (handcraft, Wikipedia, WordNet 等),而本文作者直接用 LLM 生成描述。
二、🐒文章成就🐒
是目前 open-set image tagging model 的SOTA
三、🐒预训练细节🐒
- 输入:(图片 - 标签 - 文本)
->图片处理:无
->文本处理: 文本 parse 成 tags
->标签处理:
#1 使用ChatGPT(GPT-35-turbo) 将标签库(Label System)里面的标签,都生成一个与之对应的描述文本;
#2 descriptions 的要求是需要diverse (diversity可以通过调整参数 temperature 进行调整), cover大多数的情况; e.g.猫是一个短毛动物(不能cover长毛猫,所以不推荐);
#3 descriptions 还要求描述与图片相关;
#4 每个类别带有50个描述句子,这50个句子最后会加权平均整合成一个 tag embedding - Pipeline描述
-> [ 图片 - 标签 - 文本 ] 经过 encoder 得到了embeddings 以后, 图片 embedding 分别和 tag embedding, text embedding 送入 相同的 alignment decoder。这个过程中用的text encoder 和 tag-description encoder 是相同的,并且冻结了权重;两个decoder 也是相同的,同时权重也是共享的、可学习的
-> 这个 alignment decoder 是一个双层 cross-attention encoder 和一个 feed-forward 层。在这一个结构里,输入的 embedding 作为 query 来查询 image feature 是否有跟 text embedding 重合的内容。这个结构很关键的一点是它消除了 tag embeddings 之间对互相的影响,由此增加了模型识别任何数量的类别同时不影响模型表现的这种能力。
-> 文章这里还拉踩了一下他们用的encoder和 CLIP, BLIP 用的 encoder, 意思就是CLIP用的encoder (dot product)太简单,BLIP用的encoder (6层的注意力机制,追求特征深度融合)太复杂计算成本大,然后他们用的encoder ITTA 因为兼顾了效率和表现就很棒棒。
-> Re-weighting of multiple tag description: encoder给的embeddings是多个text 多个tagg给出的,为了选择性地学习这些候选embedding,作者提出了 zutomatic re-weighting module,用来做最后一步工作→ 预测输入图片的有什么标签,以及这些标签的概率。公式列出如下图,其中 V_global是 image global features, V1-Vk是image spatial features, d_ij 是 第 j 个 tag 的第 i 个description (chatGPT生成的那个描述) 的embedding, g_w 和 g_v 函数是用来把不同特征投影到同一个特征空间的(使得它们的维度相同),tao 是 之前讲过的 temperature 参数,可以用来调整 LLM 的随机性 (确保diversity)
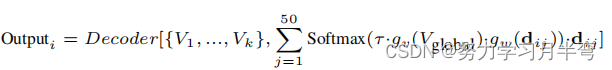
- 额外的一个设计 - offline: 因为训练过程中涉及到用LLM生成标签描述的信息,作者提出可以把生成description的过程放到线下做 (提前生成好descriptions,相当于数据预处理)。但是这个预处理的过程相当于自己制作数据集,和前人用外部自然语言数据集的做法相同。
四、🐒Inference🐒
好的现在到了大家最关心的部分,怎么使用RAM++呢?(如果有想知道怎么训练也欢迎留言和我交流)
作者制作了 RAM 的demo,可以通过这个网址访问:
RAM demo Link: https://huggingface.co/spaces/xinyu1205/recognize-anything
但是作者们并没有制作RAM++的demo,想要使用RAM++需要根据repo里面的指导在terminal运行指令
Note作者提供了两个版本inference的使用方法,一种是用训练好的模型识别已知的(预训练时用到的,predefined)标签,另一种是用训练好的模型在 open-set 标签集上进行识别。可能有些抽象,可以看一下接下来我举的例子👇
- RAM demo:
使用简单,直接拖拽图片文件进入prompt窗口,就可以得出标签信息。注意!这个是 RAM 不是RAM++,他们没有做 RAM++ demo
 2. RAM++ inference
2. RAM++ inference
在 repo 里下载 RAM++ 的checkpoint: https://huggingface.co/xinyu1205/recognize-anything-plus-model/blob/main/ram_plus_swin_large_14m.pth
这个 checkpoint 存的是训练好的模型的权重,用的是Swin-Base主干网络,训练数据集用了 COCO, VG, SBU, CC3M, CC3M-val, CC12M,在 terminal 里面运行这个命令,注意替换成你自己放图片和模型的路径:
python inference_ram_plus.py --image /image/03.jpg --pretrained pretrained/ram_plus_swin_large_14m.pth
这里是单张图片的处理方式,如果需要运行一批图片要自己该 inference_ram_plus.py 这个文件,需要的朋友留言告诉我,我弄完了可以直接用,但是代码文件就不发这个教程里了。
对同一张图(上面那个红色背景的男人打球的图)的结果如下:

- RAM++ inference on open-set:
运行:
python inference_ram_plus_openset.py --image/image/01.jpg --pretrained pretrained/ram_plus_swin_large_14m.pth --llm_tag_des datasets/openimages_rare_200/openimages_rare_200_llm_tag_descriptions.json
应该是能加入自己定义的标签 json 文件用于预测的,这个po主还没有尝试过,如果有需要试了我会更新。
结果:

注意: 只能输出英文标签
小结:有中文标签,对一些用中文的下游应用有帮助。但是生成结果会包括一些抽象概念(beat,swing),而且似乎会对同一物体打上不同标签(可以自己用一些图片试一下),可能会一些下游应用(比如给出物体位置信息)造成干扰。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python绘制三维图表 :windows平台,安装python,安装pip,安装三维图表库matplotlib
- 【Spring】10 BeanFactoryAware 接口
- JavaScript中Document的常用属性
- AI大模型引领未来智慧科研暨ChatGPT在地学、GIS、气象、农业、生态、环境等领域中的高级应用
- Required request parameter ‘ids‘ for method parameter type List is not present]
- 插槽的使用
- img.resize
- 跨平台应用程序开发软件,携RAD Studio 12新版上线
- MLP:深度学习的先锋
- 数据库数据加密方式有哪些?