[PyTorch][chapter 11][李宏毅深度学习][Semi-supervised Learning]
前言:
? ? ?这里面简介一下半监督学习,如何利用未打标签的数据集。
重点可以参考一下?? Graph-based Approach 方案。
目录:
- ? ?简介
- ? ?Semi-supervised Learning for Generative Model
- ? ?low-density Separation?Assumption
- ? ?Entropy-based Regularization
- ? ?semi-supervised SVM
- ? ?Smoothness Assumption
- ? Graph-based Approach
一 简介
? ? ?假设我们已经有了R 组有标签的数据集
? ? ?
? ? 还有u 组未打标签的数据集
? ? ?
? ? ?
? ? 如何利用这些未打标签的数据训练模型,?称为半监督学习
? ?半监督学习分为两类
? ? transductive learning(直推式学习):
?? ?unabeled data is the testing data
? ?
? ?Inductive learning(归纳推理 学习)
? ? unabeled data is not the testing data
? ?1.1? 为什么需要半监督学习
? ? ? ? ? 现实生活中,存在大量未打标签的数据集,需要充分利用这种未打标签的数据集
对模型性能的提升非常有帮助.
? 1.2 为什么半监督学习对分类有帮助呢?
? ??
? ? ? ? 未打标签的数据集分布也可以用于模型分类.如上图分类猫狗的例子:
? ? 如果只考虑背景颜色(蓝色,橙色点)其分类边界是红色。 但是加入
灰色的未打标签的数据集进行考虑,分类边界就会发生变化.
?
二??Semi-supervised Learning for Generative Model
? ? ? 预置条件:
? ? ? 根据已有的标签集得到
? ? ??
? ? ?迭代流程:
? ? ? ? ? ? E步? step1 :? 计算未打标签的数据集后验概率(posterior probability)
? ? ? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? M步:step2:? 更新模型,计算先验概率
? ? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? ? ? ? ? ? step3: 计算
? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ?反复迭代 step1-step3,知道?
?不再发生变化? ?
?它的理论基础是极大似然估计,对于有标签的数据集:
? ? ? ?
针对有标签和无标签的数据集:
? ? ??
其中
三? low-density Separation?
? ? 其典型的代表是self-train
? ? 1:? ?通过已打过标签的数据集训练模型,得到分类器
? ? 2:? ? 应用分类器
,对未打标签的数据集进行分类,得到
? ? ? ? ? ??
,得到伪标签
? ? 3:? 从未打标签的数据集中,选择一部分置信度高的添加到已打
? ? ? ? ? 标签的数据集中,重新训练模型
? 但是做回归算法的时候,不能使用该方案,做分类的时候,
采用Hard-label 方案
? ? ? ? ? ? ? ??

四? Entropy-based Regularization
? ? ?这种方案在训练的时候,直接加入unlabeled data 作为正规化项。
我们训练得到的模型,期望其在unlabeled data上面的Entropy 越小越好
(代表其某一类分类概率特别高)

五? ?semi-supervised SVM
半监督SVM的数学步骤可以分为以下几个步骤:步骤1:构建初始分类器
? ? ? ? 首先,我们使用少量的标记数据来构建一个初始的支持向量机分类器。这个分类器将在已知数据上找到一个良好的决策边界.步骤2:利用未标记数据
? ? ? ? ?然后,我们引入未标记数据。未标记数据不会直接影响初始分类器的决策边界,但它们会在训练过程中起到重要作用.步骤3:半监督优化
? ? ? ? ? ?半监督SVM通过考虑未标记数据的分布,调整决策边界以提高分类性能。这通常通过引入正则化项来实现,以平衡标记数据和未标记数据的影响.步骤4:重复迭代
? ? ? ? ? ? ?我们重复执行半监督优化的过程,直到达到预定的迭代次数或决策边界稳定。这个过程将最大化分类性能,并充分利用未标记数据
————————————————
原文链接:https://blog.csdn.net/DeepViewInsight/article/details/132958722
 ?30:25 秒
?30:25 秒
? ? ? ? ?
?六?? Smoothness Assumption
? ?问题:
? ? ??已经打过标签了,?
未打标签,
? ? ?到底打成
?还是?
?的标签
? ? 解决方案:
这种假设是基于:之间有大量联通区域(high density region),
所以标签可以认为和
相同.

?
6.1 例子

?如上图,中间2 可以通过右边的2经过一系列的变化得到(中间有联通的区域),
但是中间2 无法经过变化得到右边的3 ,所以其标签为2
6.2实践操作原理:
? ? ? ?1? ? 通过AE 编码器对已打标签的图像数据进行降维,
? ? ? ?2? 通过AE 编码器对输入未打标签的图形进行降维
? ? ? ?3? 最后对降维后的数据集 观察是否有联通区域进行打标签。

七? Graph-based Approach
?7.1? 问题:
? ? ?
? ? ?如何判断之间有高密度连接区域,通过graph 来表示数据。
定义?来判断
之间的相似度。
? ? ?添加edge:? k? 最邻近点
? ? ? ? ? ? ? ? ? ? ? ? e-邻近点
 ? ? ? ?
? ? ? ?

?
? ? ?7.2 相似度函数
? ? ? ? ??(针对所有所有数据,无论是打标签还是未打标签
? ? ? ? ? 如下图

?
? ? 7.3?这张图是如何计算出来的
? ? ? ? 左图:S=0.5
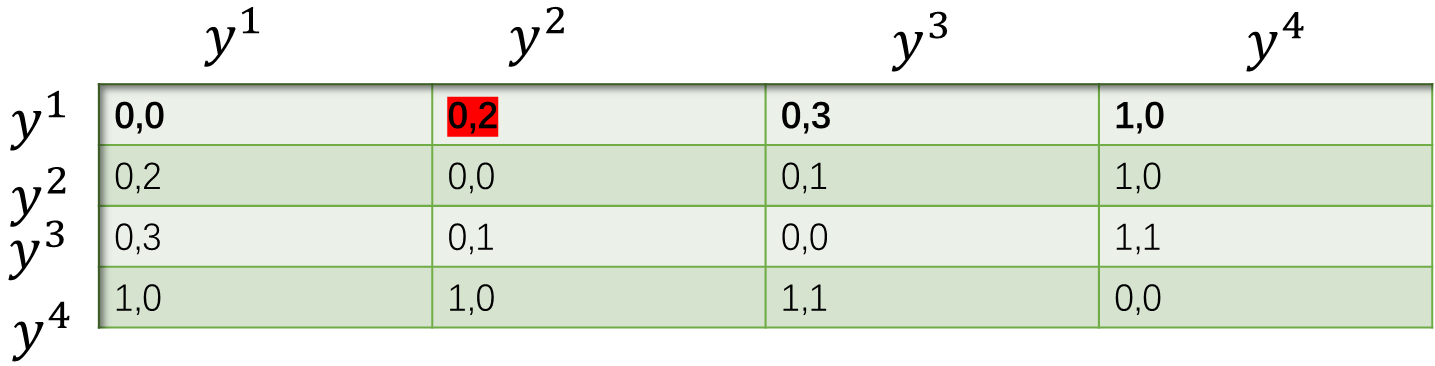
? ? 可以通过矩阵表示,比如红色部分
? ?0:
? ?2:??? ?
? ?把矩阵里面每个格子里面的元素相乘求和,再处于4(N=4)
? ? ?
右图:S=3

? ? ?
?7.4? 矩阵计算方式
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ??
? ?
? ? ? ? ? ? ? ? ? ? ? ?

? 证明如下:
??
??
?其中
? ? ? ? ? ? ? ?
? ? ? ? ? ? ??
? ? ? ? ? ? ??
? ? ? ? ? ? ? ?
所以
(i,j的维度相同,数据的标签)
7.5 利用未打标签的数据集重新定义损失函数


参考:
深入半监督学习:半监督支持向量机(Semi-Supervised SVM)_semi_supervised-CSDN博客
机器学习——概率分类(三)高斯概率密度与混合高斯模型_概率密度分类-CSDN博客
12: Semi-supervised_哔哩哔哩_bilibili
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据采集与预处理】数据传输工具Sqoop
- RocketMQ MQClientInstance、生产者实例启动源码分析
- 互联网医院系统实现高效医疗服务的数字时代里程碑
- echarts饼图绘制圆环线条
- 计算机毕业设计 | SpringBoot学生成绩管理系统(附源码)
- 利用vb开发图片加密软件怎么样?
- 在 【Linux Centos】下搭建 【Nginx Web】 服务器
- 书生大模型全链路开源体系
- Linux第29步_安装“Notepad++”软件
- sizeof和strlen的对比