基于 Hologres+Flink 的曹操出行实时数仓建设
云布道师
曹操出行创立于 2015 年 5 月 21 日,是吉利控股集团布局“新能源汽车共享生态”的战略性投资业务,以“科技重塑绿色共享出行”为使命,将全球领先的互联网、车联网、自动驾驶技术以及新能源科技,创新应用于共享出行领域,以“用心服务国民出行”为品牌主张,致力于打造服务口碑最好的出行品牌。
曹操出行业务背景介绍
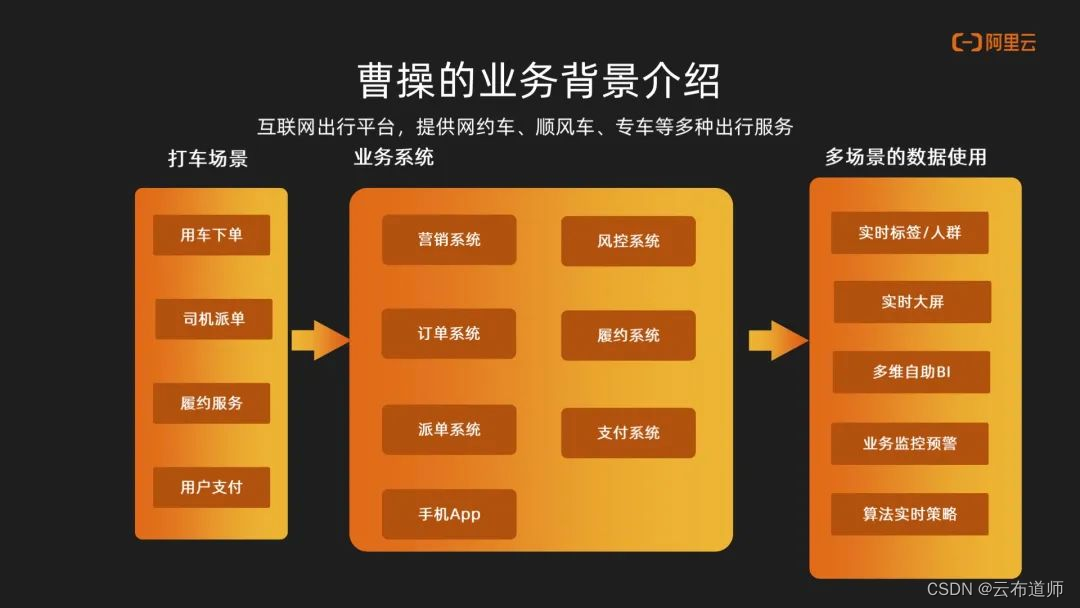
作为一家互联网出行平台,主要提供了网约车、顺风车、专车等一些出行服务。打车为其主要的一个业务场景。用户会在我们的平台中去进行下单,然后我们的系统会给司机进行派单,接到订单之后,进行履约服务。结束一次订单服务后,乘客会在平台做出支付。
曹操出行业务痛点分析
整个流程中这些数据会流转到我们的业务系统,主要会有营销、订单、派单、风控、支付、履约这些系统。这些系统的数据会进入到 RDS 数据库,流转到实时数仓中去做一个分析和处理。最终数据会进入到不同的使用场景中,比如实时的标签,实时大屏、多维 BI,还有业务监控以及算法决策。
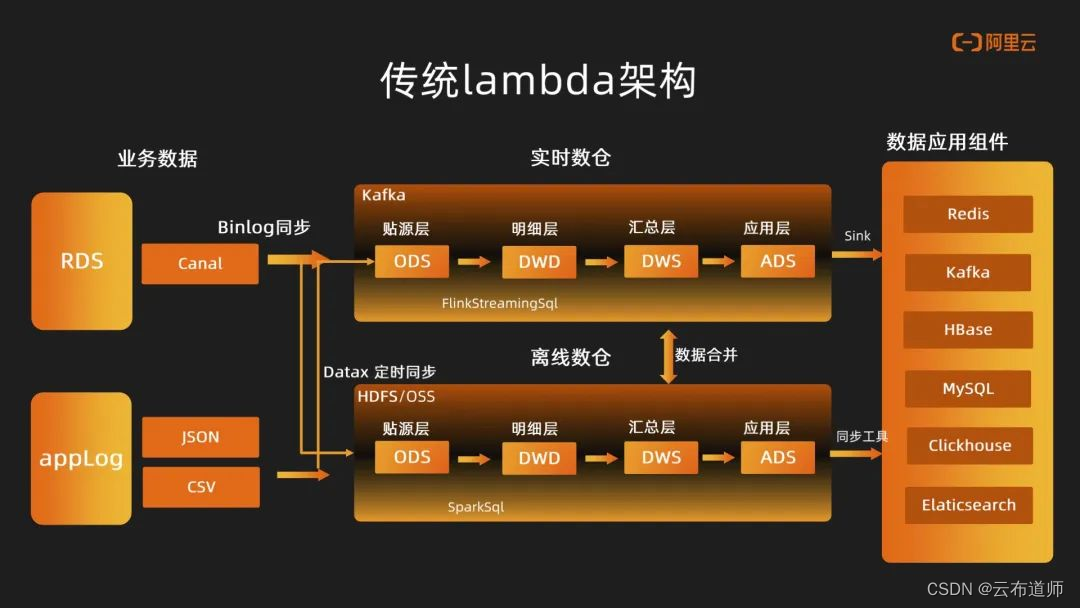
在传统 lambda 架构中,架构主要会分做实时数据流和离线数据流。在实时链路中,业务数据库会在 RDS 中通过 Canal、Binlog 同步的方式进入 Kafka,同时 app 的 log 也会通过实时采集的方式进入到 Kafka。在这些数据准备完成之后,在 Kafka 中构建实时数仓。整个数仓也是基于数仓分层理念去构建,主要是 ODS、DWD、DWS 和 ADS,整个链路中会通过 Flink Streaming Sql 去做一个串联。
在离线链路中,数据主要是通过 DataX 定时同步的方式,将 RDS 数据同步到HDFS。同时App的log会通过定时任务同步到 HDFS,整个离线数仓会通过 Spark Sql 的定时调度任务去逐层执行。数据在离线数仓中会通过不同的数据域去组织不同粒度的计算,最终数据会通过 Flink Sink 以及离线同步工具写到不同的数据应用组件中。同时为了保证某些应用场景中数据的一致性,有可能会对离线和实时两条链路的数据做些合并处理加工。

基于曹操出行整体对于成本的诉求,对于传统 lambda 架构,从架构中可以看到一些问题:
- 需要使用非常丰富的大数据组件,来适配不同应用场景。
- 研发成本非常高,不仅在实时链路中做大量的处理,而且在离线链路中也是多做一套研发。
- 运维效率较为低效,整个实时数仓是构建在 Kafka 上,因此我们这种数据探查以及这种数据订正就会变得非常困难。
- 资源成本较大,主要体现在组件使用多,需要专门的工作人员进行运维与管理;一些场景需要精准的一致性需求,因此在链路中需要做出数据的同步和计算。
- 在某些 Flink 场景中,需要处理大状态场景下,可能会造成额外性能与资源的浪费。
另外从对于公司开发者使用的角度,我们对实时数仓提出了以下几点诉求:
- 拥有统一组件满足不同业务场景诉求。
- 再实施复杂链路中保证数据的订正。
- Flink 中一些大状态下的技术难点需要克服。
Hologres+Flink 企业级实时数仓构建
Hologres 能力分析
曹操出行作为 Hologres 的深度用户,在前期调研与测试阶段,我们对 Hologres 的相关能力做了比较详细的分析,主要有以下优势:
1、业务场景能力丰富:
- 具备 OLAP 分析能力
- 具备高并发点查能力
- 具备半结构化日志分析能力
- 具备基于 PostGIS 的扩展能力,支持空间地理信息信息数据的分析与使用,对于曹操出行的业务属性来说非常重要。
2、一站式实时开发能力
- 契合数仓分层结构理念(可以像离线数仓一样去构建分层体系,数据实时流动,实时存储)
- Flink Streaming 态高度融(Flink CDC组件集成,Flink Catalog集成)
- 统一 Ad-hoc 能力,能以外表加载离线数仓中数据进行加速联邦分析
3、解决的痛点问题
- 全链路低时延
- 多流 join 场景很好提供数据打宽的能力,支持主键模型和行级,局部字段更新的能力
- 支持 Count distinct 大状态精确去重场景
Hologres 支持高并发更新
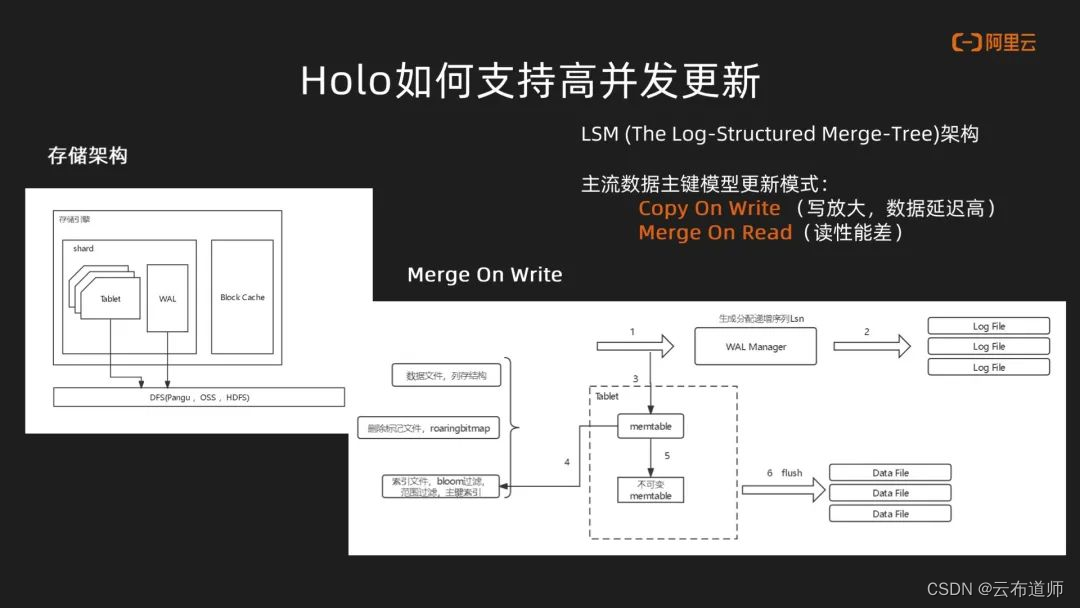
通过观察存储架构,我们发现 Hologres 在最底层是分布式存储系统,在此之上是一个存储引擎,主要是有 Block Cache,shard 是分多个 Tablet 与 WAL,市面上主流的这种服务产品大多数都是基于这种 LSM 架构。
主流数据主键模型更新模式也有 Copy On Write 和 Merge On Read。这两种场景都有各自的问题,Copy On Write 具有写放大的问题,数据的延迟会比较高。Merge On Read 由于在读的过程中需要做数据的大量合并,因此其读的性能会非常差。在 Hologres 中,行存使用 Merge On Read 方式,列存主要基于 Merge On Write。基于这种架构,一条数据在进入 Hologres 中,首先会到达 WAL Manager中,同时也会进入到 Memtable,在 Memtable 中主要会存储三类数据:数据文件、删除标志的文件、例如基于 RoaringBitmap、索引文件。当数据积累到一定阶段后会生成不可变的 Memtable,后面会通过异步的线程,定时做 flush 到 Data File。
Hologres Binlog 支持

Hologres Binlog 也是一种物理表的存储方式,其跟原表的主要区别是内置的几种自身结构,包含自身递增序列,数据修改类型以及数据修改的时间,Binlog 本质上也是分 shard 做存储,所以也为一种分布式表,并且在 WAL 之前生成,因此在数据上可以与原表保证强一致性。
其次 Hologres Binlog 修改类型也还原了 Flink 中四种 RowKind 类型。在数据更新过程中可以产生两条更新记录,并且保证更新记录是一个连续的存储。右边展示中,写入一个数据一个 PK1,然后再写入一个 PK2 数据,PK2 的数据再做更新,Binlog 中它会产生四个数据结果。
Hologres 数据模型介绍
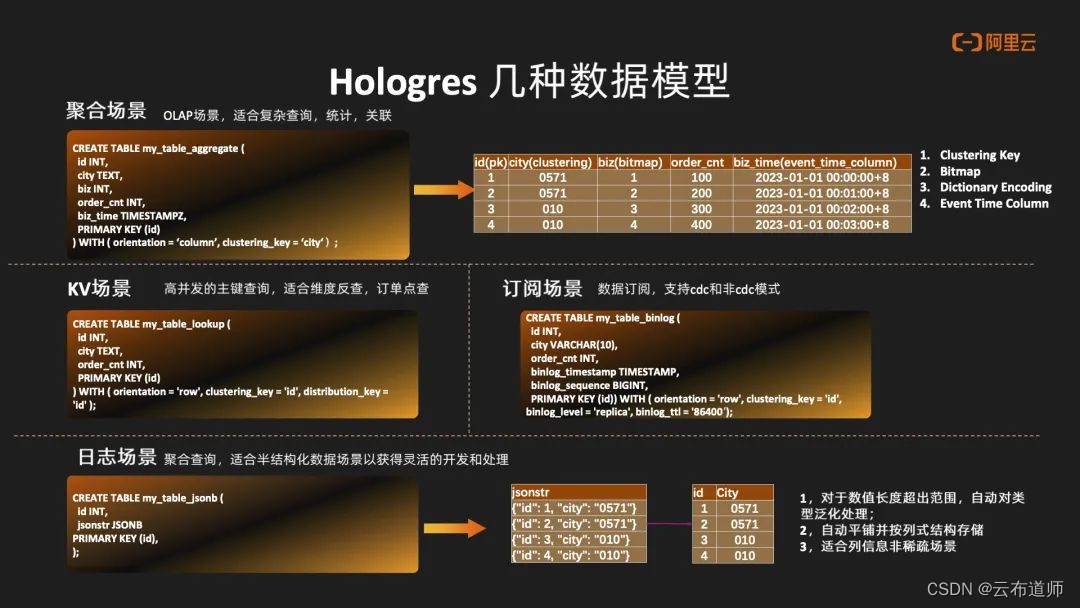
Hologres 主要会分做行存引擎以及列存引擎,包括行列共存场景。
- 在聚合场景中主要是用到列存的引擎,适合 OLAP 场景,适合复杂查询,统计,关联等场景。同时也提供了非常丰富的索引,包括技术聚簇索引,位图索引,字典,以及基于时间序列的范围索引。
- 在 KV 场景中主要是用到行存的引擎,主要支持高并发组件查询。包括在 Flink 中做维表反查也是非常适合。
- 在订阅场景中主要是用到行存的引擎,主要在表属性中要进行声明,比如说Binlog 是否开启,Binlog 的 TTL。在订阅方的话,Hologres 支持 CDC 以及非 CDC 的模式。
- 在日志场景中主要针对聚合场景,主要是支持 JsonB 数据类型。JsonB在这个数据的这种处理过程中,它能够自动地平铺成列式的存储结构,就可以做聚合场景的灵活分析。同时它可以自动去对这种数据类型做解析,包括对数据类型做泛化处理,以及数据的对齐,非常适合这种非稀疏场景。
曹操出行实时数仓构建实践
实时数仓架构设计
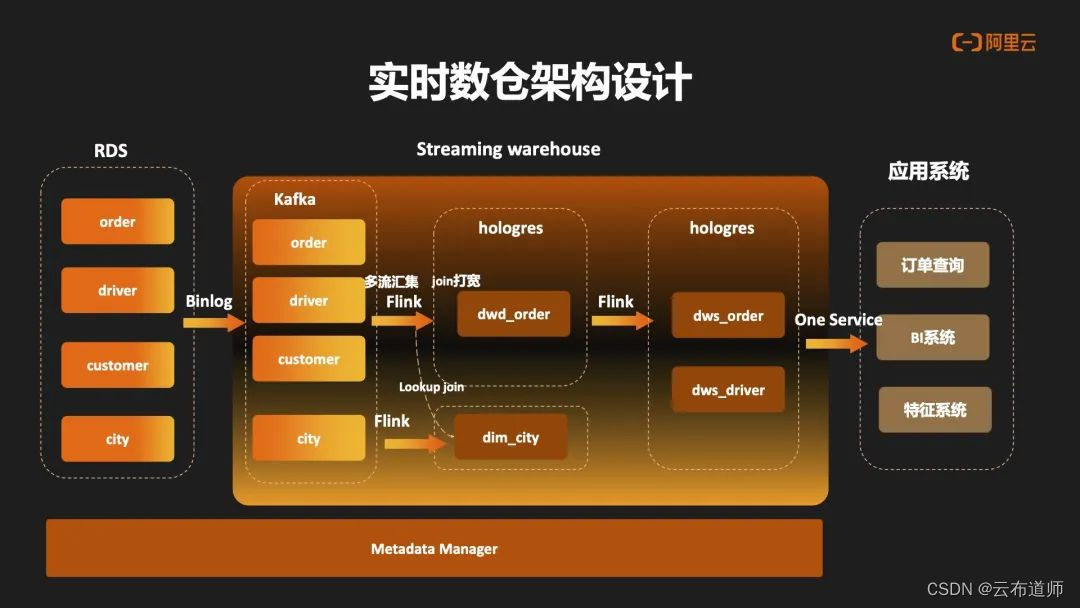
基于以上 Hologres 的能力,接下来是对于曹操内部实时数仓的架构设计,左边为RDS 数据库,最右边是应用系统,最下边为元数据管理,中间部分是实时数仓的部分。数据通过 Binlog 进入到 Kafka 的 ODS 层之后,再会通过 Flink 会写入到 Hologres 里的 DIM 层,然后再通过 Flink 做 ODS 的多流汇聚,再写入到 Hologres 的 DWD 层。在 DWD 中可以做宽表打宽的是实现。再下一层,通过 Binlog 的订阅的方式,再写入到 Hologres 的 DWS 层,后面会统一通过 One Service 的一个统一查询服务对外暴露这个服务。
dwd 宽表构建实践
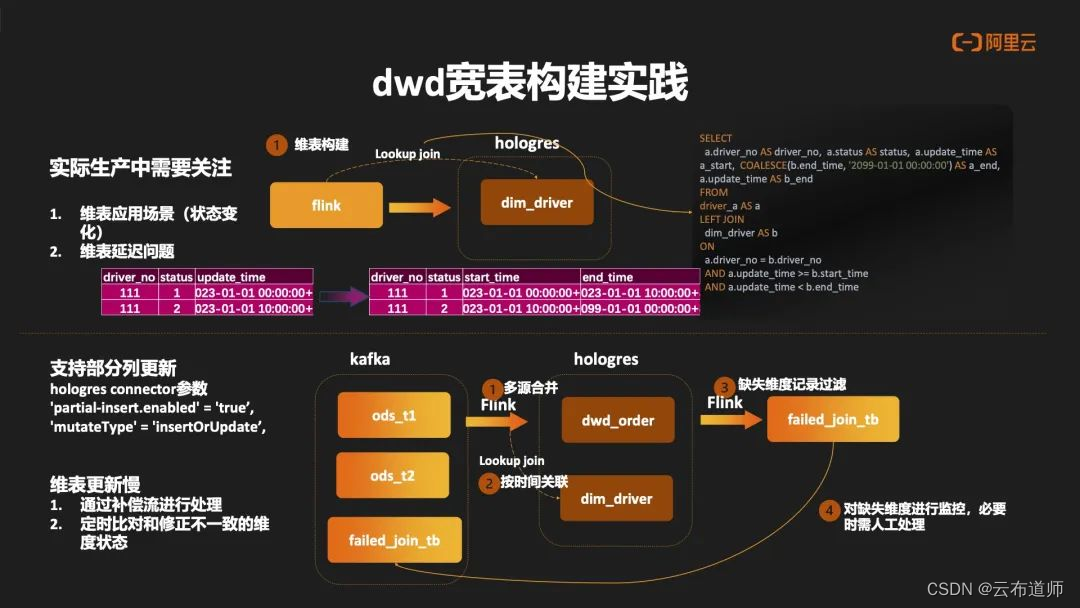
接下来介绍一下Hologres DWD宽表层的一个构建实践。基于之前提到的Hologres列更新能力,能够很好实现宽表Join能力。在整个生产过程中,首先关注维表的应用场景,其应用场景可能含有多种:一种是维表是不变的,或者缓慢的变化,另一种是维表频繁变化的。因此需要像离线的方式去构建一个维表拉链的数据,通过用过Start Time和End Time的方式去存储维度状态有效的一个周期。
其次需要关注维表延迟的问题。在实际生产过程中,维表链路与主表的链路是一个异步的过程,有可能在维表延迟的情况下,主表关联的数据是空的,或者主表关联到的一个数据是过时的维度状态。在这种场景下,需要在 Hologres 做维度缺失记录的过滤,通过补偿机制再去做维度的补偿处理,同时也需要做定时的维度检查,然后增量地把不一致的状态做一个修正。
聚合计算场景优化

接下来介绍我们对聚合场景的优化,针对我们多预聚合计算场景,将其统一收敛到Rollup 计算模型中,主要解决以下问题:
- 在 Flink 聚合场景中经常会出现状态兼容性的问题
- 整个数据的复用性非常差,研发人员收到新的需求,例如新的指标或者新增维度粒度时,为了不影响生产数据的稳定性,往往选择自己去构建新的任务,久而久之这种零散的任务会变得非常多,整个管理随之会变的非常混乱。
因此曹操出行主要优化了两点:
- 构建 MapSumAgg 算子,MapSum 主要通过对 SumAgg 算子做了重新设计,使之能够支持 Map 内部结构的求和逻辑
- 对 Grouping Sets 进行动态配置化,这样 Grouping Sets 动态增加维度粒度,使整个任务在不重启的情况下也能自动去做自适应
结合这两点,把已有的指标放入 map 结构中进行封装,这样在不改变原有的算子状态,也可以得到很好的处理。在下游中可以针对不用维度,指标做好选择,然后通过同步工具做好数据路由,提供给下游的服务。
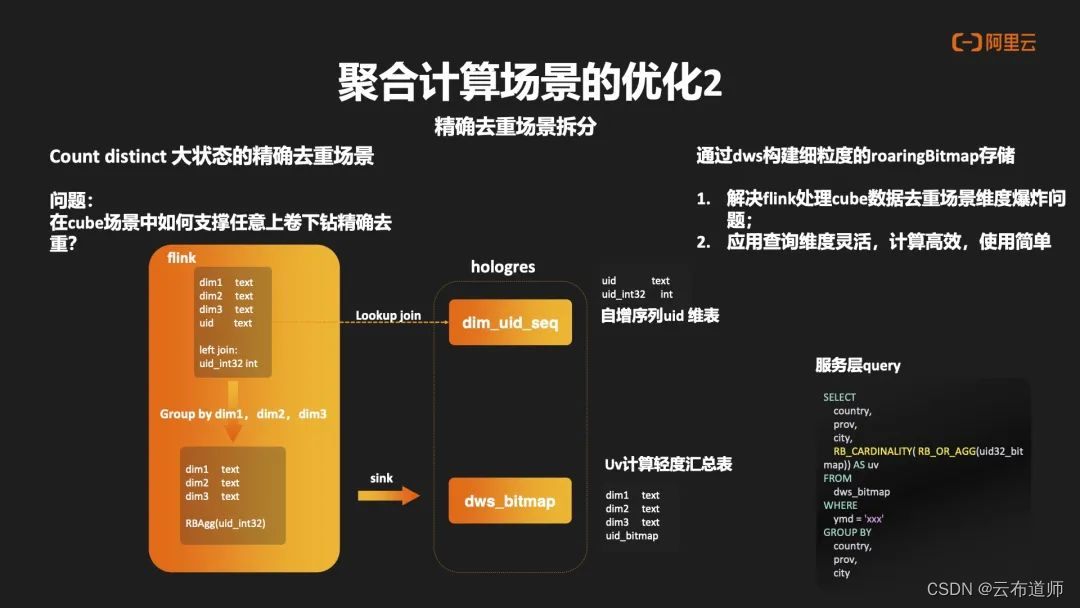
对于第二个聚合场景的优化,是对精确去重场景的拆分。在前面例子中,我们把 Count Distinct 的精确去重做了剥离,主要解决两个问题:
- 维度爆炸的问题。在 Flink 回撤机制下做精确去重时,存储的全量状态。那么在 cube 场景中,这种状态爆炸式的情况,在 Flink 中是难以持续去建设。解决思路是通过 Hologres 去构建细粒度的 RoaringBitmap 存储方案。
- 查询灵活高效的问题。整个流程中,在 Hologres 中构建自身序列的 UID 维表,在主表中通过反差逻辑将 UID 自身序列反查出来,随之在 Flink 中做出 Group by 的操作,最终通过聚合计算,算出 RoaringBitmap 的结果,随之写入 Hologres 的 DWS 层中,形成 UV 计算的轻度汇总表,解决应用端灵活维度查询时的高效性,同时也能满足解决
Flink 爆炸维度问题。
链路中吞吐能力调优
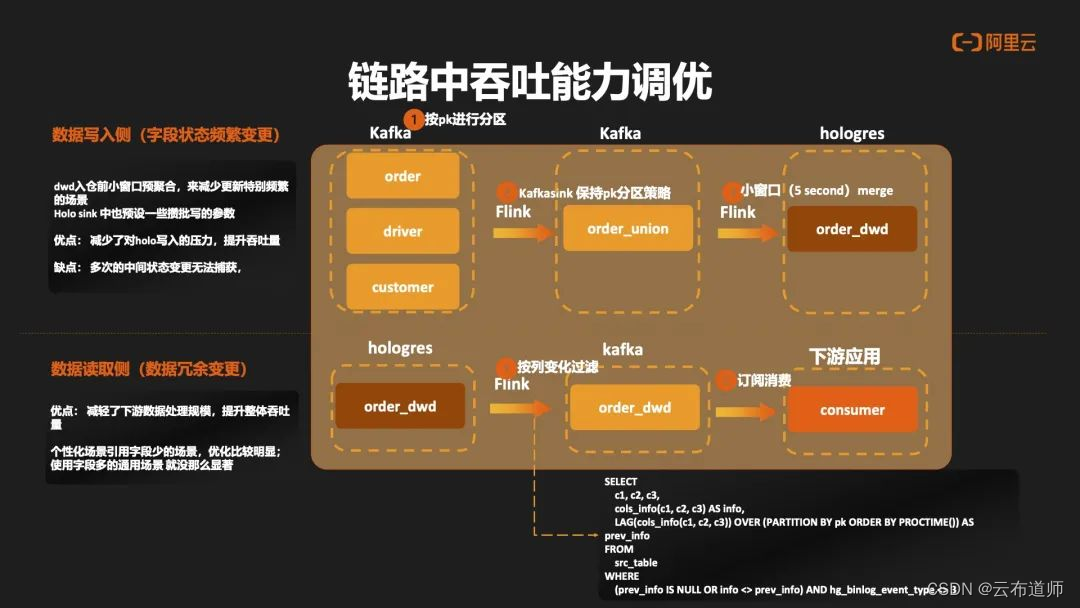
整个流链路中吞吐能力的调优主要分作两个部分:
- 数据写入侧。在 Flink 写入到 Hologres 之前,针对字段状态变更频繁的场景做了一层 Union 层,在 Union 层以及 ODS 层中,数据都是基于 PK 进行分区,然后在 Union 层中做了一层小的窗口进行预聚合的计算,这样可以大大减少对Hologres 写入压力,从而提升整个数据吞吐量,但这种方式有一个缺点就是比如一些中间状态的数据,会变得无法捕获。
- 数据读取侧。在 Binlog 中更新数据,它会产生连续的变更前后数据,在这种场景中,可以通过 lag 开窗的这种方式获取到一次变更中连续上下游数据的情况,根据两者数据之间的信息差异,可以过滤出数据的冗余变更,从而减轻整个处理下游的压力。
元数据血缘的改造
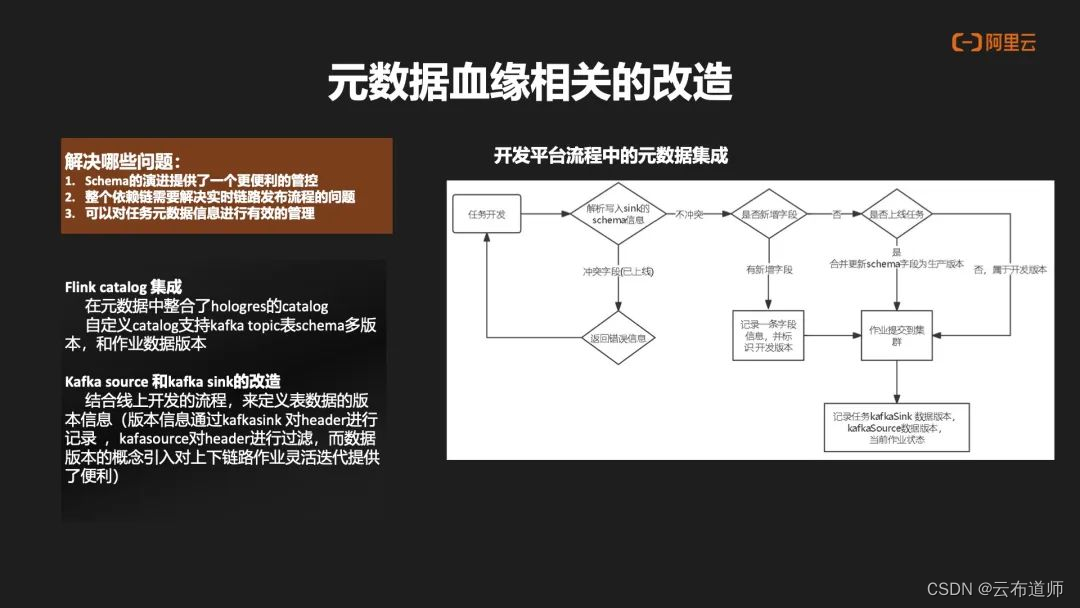
元数据血缘的改造主要解决了以下问题:
- Schema 的演进提供了一个更便利的管控
- 整个依赖链需要解决实时链路发布流程的问题
- 可以对任务元数据信息进行有效的管理
曹操出行主要进行以下措施:
- Flink Catalog 集成。在元数据中去整合 Hologres 的 Catalog,也支持 Kafka Topic 表中自定义
Catalog,支持多版本 schema 和任务数据的多版本。 - Kafka Source 和 Kafka Sink 的改造。结合整合整个上线发布的流程,对于数据的版本信息,通过 Kafka Sink 对 Header 进行记录,Kafka Source 对 header 的版本信息进行过滤,从而把数据版本引入到整个上下游的链路,提供上下游数据灵活的迭代。这种做法的好处是,在整个链路中可以感知到整个下游数据的使用情况,因此可以帮助用户在下线过程中可以快速定位到下游,还有没有任务做依赖,右边的图片主要是展示一个开发流程中元数据的集成。
链路保障体系
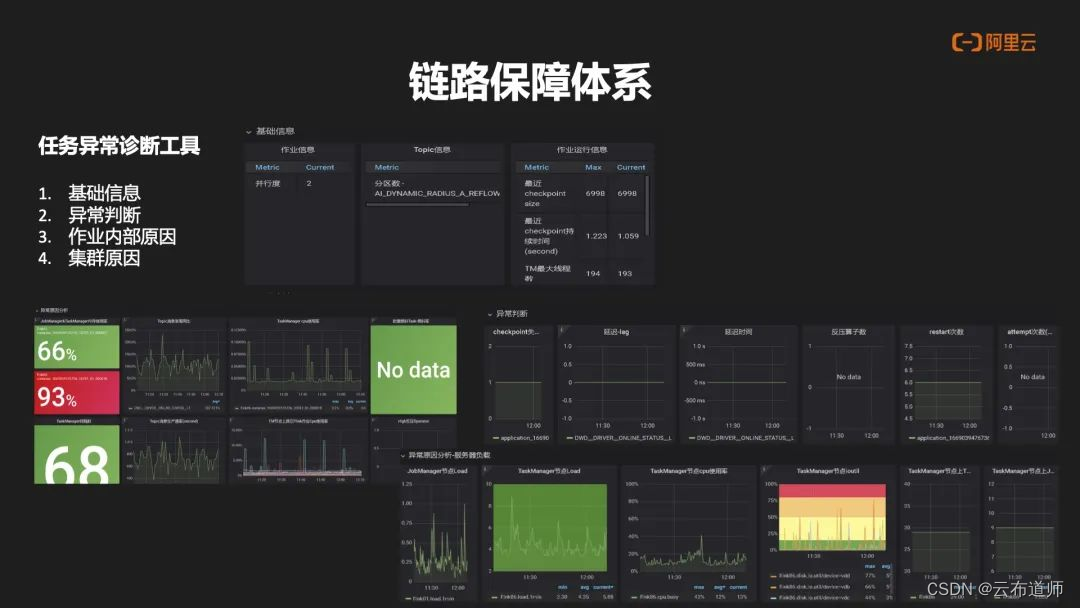
在日常开发过程中,对于任务健康以及任务出现异常后的判断和检测,都是通过异常检测诊断工具去做支持。主要体现四个方面:
- 对于基础信息采集,通过采集工具,把 Flink 内置的 Metric 以及 Kafka 信息进行采集,提供基础数据,包括作业信息,Kafka 一些 Topic 信息,作业最新指标情况。
- 对于异常的判断,通过内存以及 Topic 增长情况,包括 CPU 使用情况,以及任务有无出现反压,任务有无倾斜做出异常的判断。
- 对于异常原因的诊断-内部原因,内部原因主要会看 CheckPoint 的失败情况,Kafka LAG 具体是什么算子造成的反压,Restart的次数;
- 对于异常原因的诊断-外部原因,外部原因主要是看 Job Manager 以及 Task Manger 所在节点自身的情况,包括 CPU 的使用率,包括 ioutil,内存情况,然后做出综合判断,帮助用户去快速定位具体问题的原因。
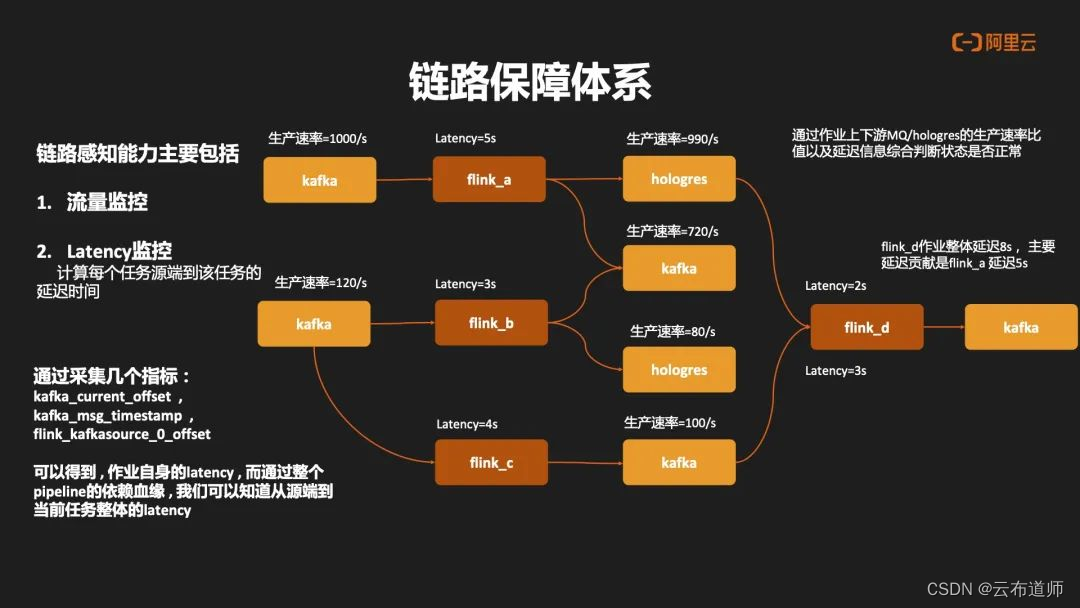
链路保障体系另外一个比较重要的环节就是全链路的感知能力。曹操出行主要是在流量监控与 Latency 监控两方面: - 流量监控层面:通过 Kafka Cueernt Offset 以及 Hologres 内置的 Offset 信息做定时的采集,从而推算出 Kafka 以及 Hologres 表的生产速率。
- Latency 监控层面:主要采集 Kafka Offset 以及 Flink Source 的 Offset 情况,结合 Kafka
Massage Timestamp 去推算出每个任务自身延迟情况,再结合整个数据血缘进行一个串联,可以得出端到任务自身整体的延迟时间,再通过任务上下游生产速率比,以及任务自身延迟情况,可以在整个生产链路中快速定位出具体异常和问题发生的节点。
数据订正能力建设
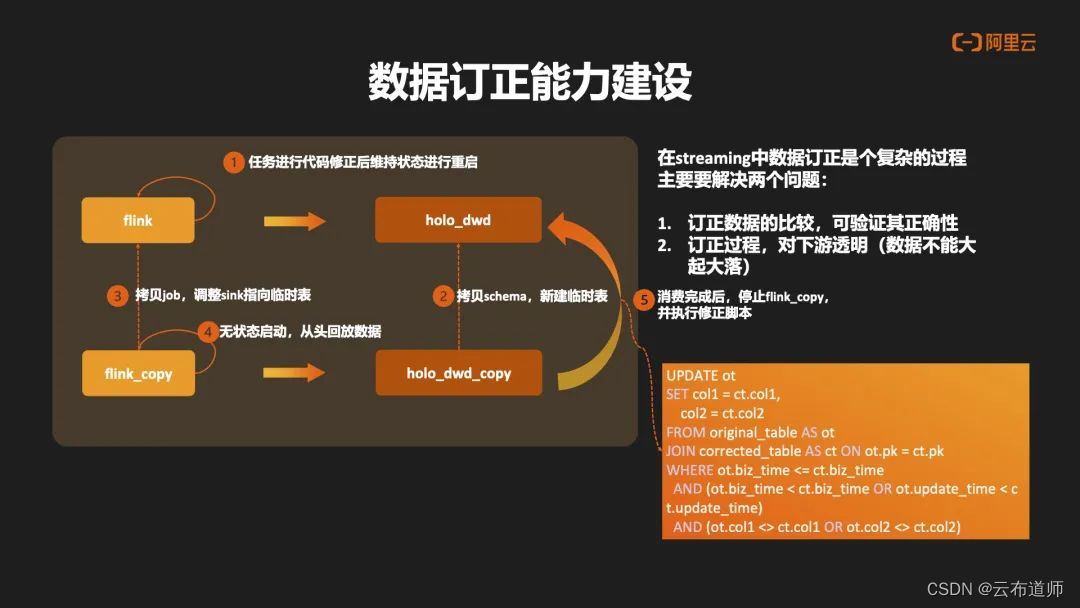
在传统的 Streaming 链路中,数据订正是一个非常复杂的过程。主要要解决两个问题:
- 如何知晓订正的数据为正确数据?验证其具有一定困难。
- 在整个验证过程中,如何保证对下游的透明?如果丢状态去做重启的订正,肯定会对下游造成很大的影响。
因此我们主要思路是基于 Hologres 去做实现。首先对于原始任务进行代码修正后,并维持原有状态去做重启。第二步将对 Hologres 表做 Schema 的拷贝,然后新建一个订正的临时表。第三步会将任务进行拷贝,并将Sink调整到订正临时表,去做无状态从头消费的重启。这样可以把订正的结果数据订正进 Hologres 订正表中。等待消费结束后停止订正任务,然后通过修正脚本去对比原表以及订正表中关键信息,去做数据的订正。由于数据的订正,它处于数据终态,对于下游来说,不会造成大起大落。并且在整个链路中,因为正确数据可以通过整个数据链路做回撤的传导,因此整个下游就可以完成数据的自动订正。
曹操出行业务成果分析

架构清晰简单:
- 对比 Lamada 架构,Hologres+Flink 整体架构更加清晰,使用数据组件大大减少
- 整体技术复杂难度降低,原先为了解决数据一致性问题,数据需要在不同的异构存储和异构链路中来回传输和计算,整个技术复杂度较高
开发效率提高:
- 整个开发模式变得简单易用,大大缩短人力周期
- 数据实时模型分层非常清晰,整体下游复用性以及使用门槛大幅度降低
运维体验提升:
- 由于数据存储在 Hologres 之上,因此数据探查更加便捷,数据订正难易程度大幅度减少。
成本减少:
- 组件维护成本减少。
- 数据的离线存储和实时存储,从双份存储降低到一份存储,以及降低了数据在异构存储之间的同步与计算成本
- 解 Fflink 中各类计算场景中大状态的成本,减少了计算开销并提升了处理性能。
未来展望
未来展望主要分为以下几个层面:
- 当前 Flink 集群还是一个自建的集群,对于这些集群我们业务最关心的是使用过程中,其业务的稳定性和可靠性。特别是在高峰场景,资源不足时,怎么去做快速的缩扩容。在高峰期过去后怎么去做到无缝缩容,降低业务风险,包括减少业务的数据中断时间。
- 在任务级别的动态感知和智能调控上。很多时候研发根据自己的经验去设置Flink的资源参数,往往有很多资源其实是多设或者是额外设置的。通过动态感知能力的引入,能够有效提升整体的资源使用情况,包括未来也可能会引入智能算法,包括自适应的机制去达到节约成本的目的。
- Flink CDC 来统一 ODS 入仓的方案。我们在离线使用 DataX 的入仓方案,后来实时使用了 Flink CDC 的入仓方案,其实本质上数据可以提供一个统一的解决思路,来解决数据的一致性和灵活性的诉求。包括在 CDC 方案中,也会有一些定制上的需求。比如说在 CDC 过程中,怎么去解决加解密的一些问题,包括 RDS 数据库中数据归档的一些问题。后续的话也会分阶段的做一些调整,包括一些高频迭代的诉求,会在后续的规划中提前去做解决。
- 关于数据服务的一个规划。因为曹操出行有很多服务的场景,特别是在线应用的这种场景,包括分析型的这种服务也在上面,需要高可用的数据服务以及服务可扩展性,那怎么样通过同一份数据来做到不同服务的扩展。后续会考虑基于 Hologres 主从隔离的能力,通过一主多从的能力去支持多种数据服务的扩展。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【毕业设计选题】计算机毕业设计(论文)选题推荐 选题指导篇
- k8s---helm
- 2023强网杯——Reverse——ezre
- 电脑风扇控制 -- Macs Fan Control Pro
- 动态规划 - 70.爬楼梯(C#和C实现)
- 多个微信的朋友圈如何高效管理?
- 阿里云Queen智能美化特效SDK如何接入iOS
- easyexcel导出报错 java.lang.NoClassDefFoundError: org/apache/poi/POIXMLTypeLoader
- 使用jasypt进行配置文件加密
- C语言初阶——分支和循环语句