Linux---进程地址空间(虚拟地址空间)
我们在学C语言的时候或多或少都会遇到类似下面的空间布局图
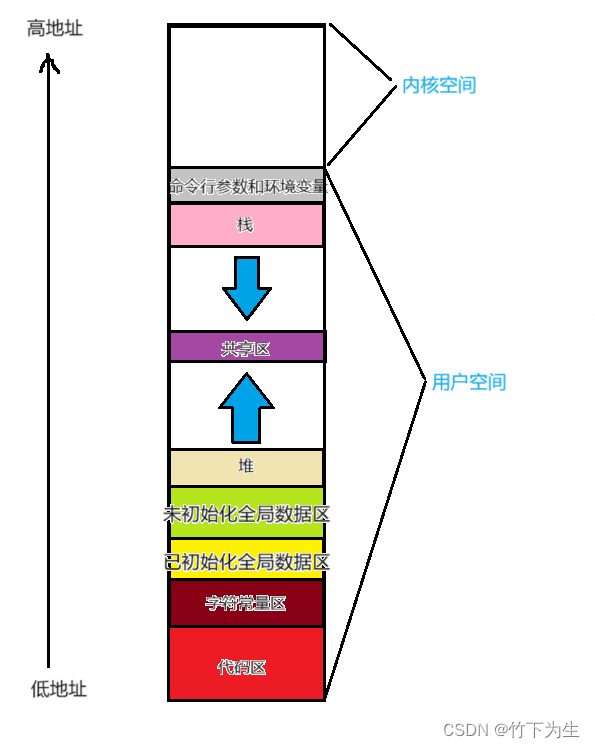
一、几个简单的问题
1.这个空间分布是否正确?
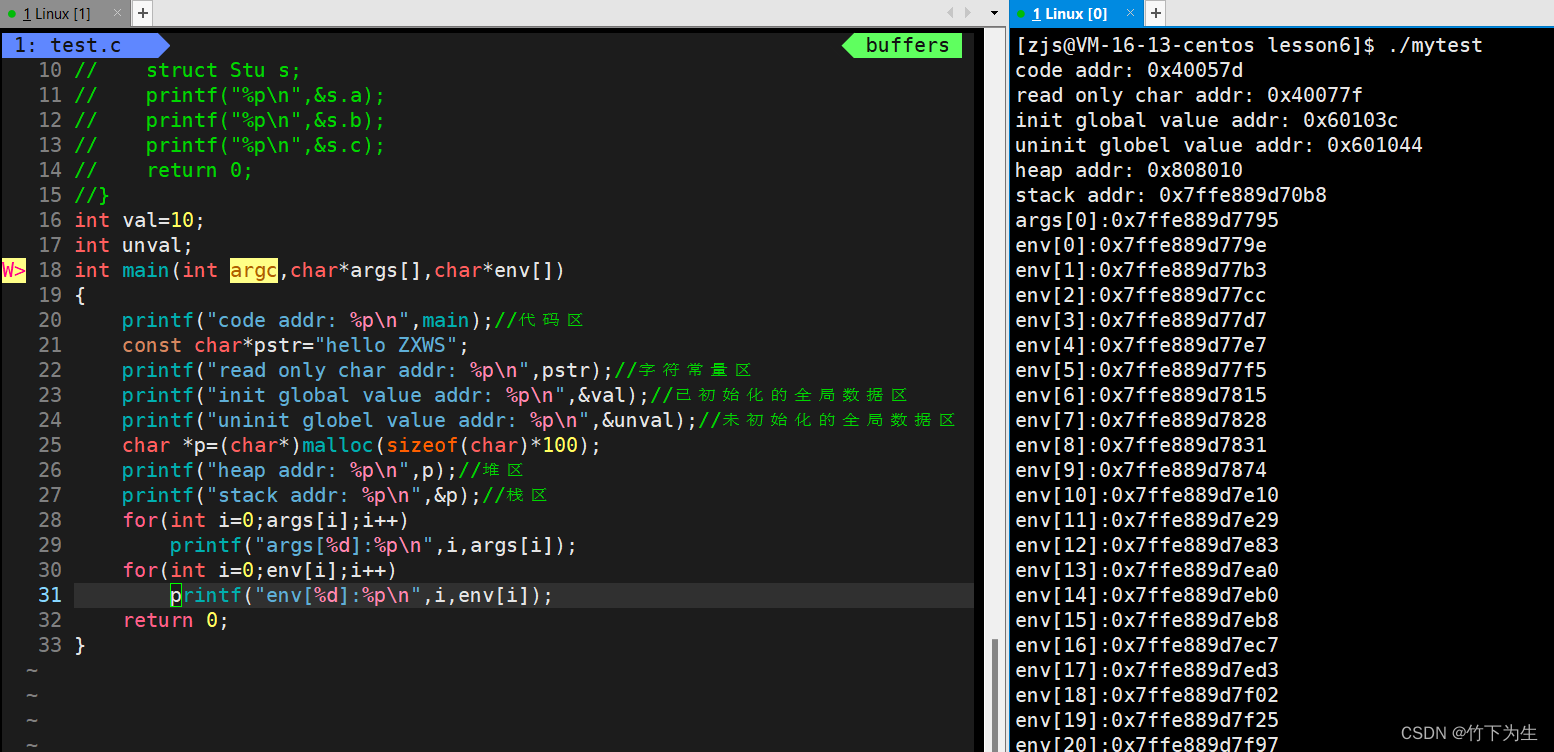
从上面的代码和执行结果来看,图上的空间分布确实是正确的
2.堆区向上增长,栈区向下增长的趋势是不是正确呢?
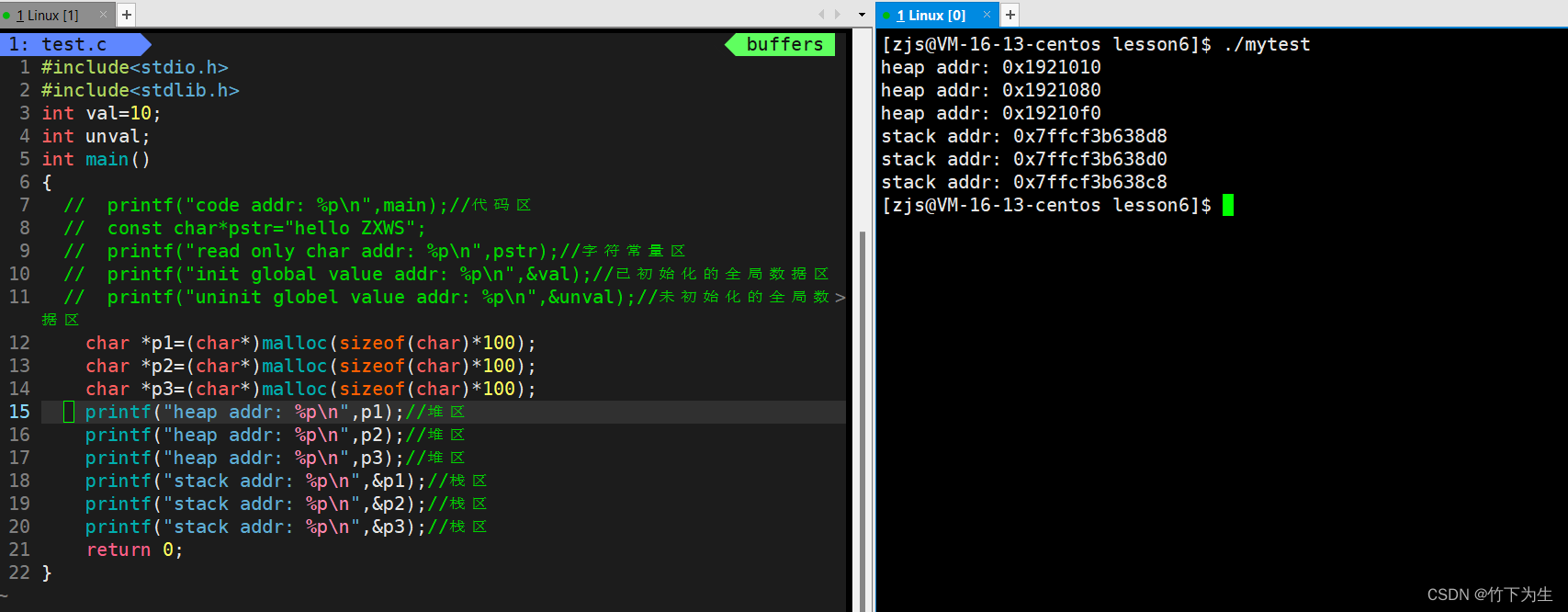
两者的增长方向也是正确的
3.几个在栈上开辟使用空间的细节问题
- 数组的首元素地址是高地址还是低地址?
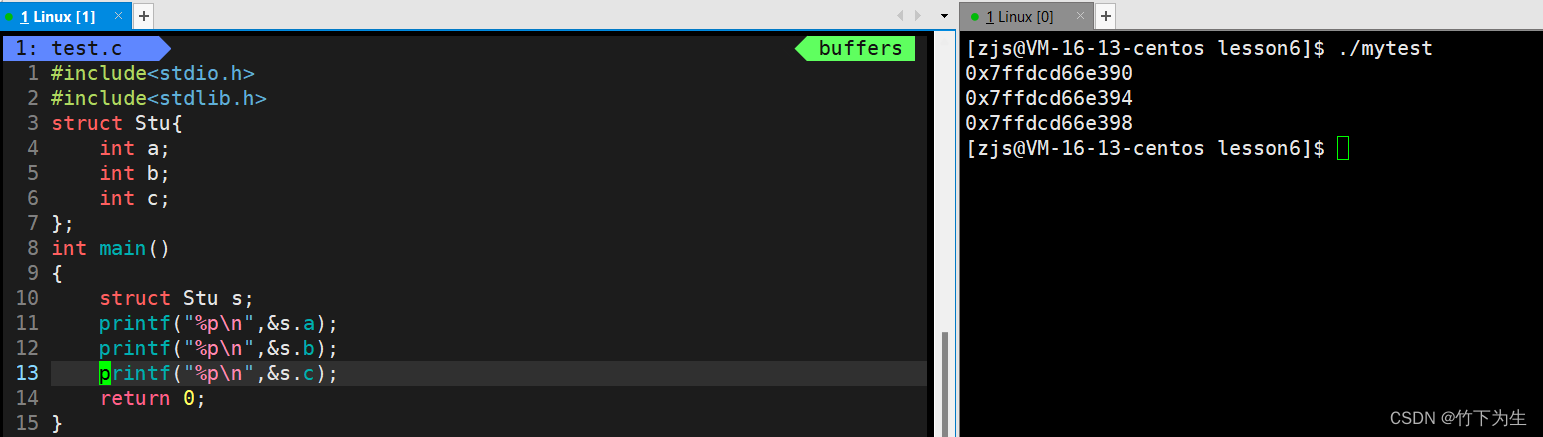
- 结构体内的第一个成员的地址是高地址还是低地址?
- int类型的变量有四个字节(每个字节对应一个地址),那么我们取地址时,取的是哪个地址?
解析:
数组的首元素地址是低地址,因为我们用指针访问数组时,会让指针++
结构体内的第一个成员的地址是低地址,如下图
我们取int类型变量的地址也是低地址(大家可以想一下int*的指针每次++,就会跳过一个整形,即地址会变大,所以int变量的地址也是取的低地址)
(这里int指针为啥++,往后跳四个字节呢?因为它是int类型,所以类型的本质其实就是偏移量)
所以,这三个问题的答案都是低地址,由此我们可以得到这样一个规律:栈上的空间,开辟时是整体向下增长,使用时以最低地址作为起始地址,局部向上使用
4.static修饰的局部变量存放的静态区是哪?
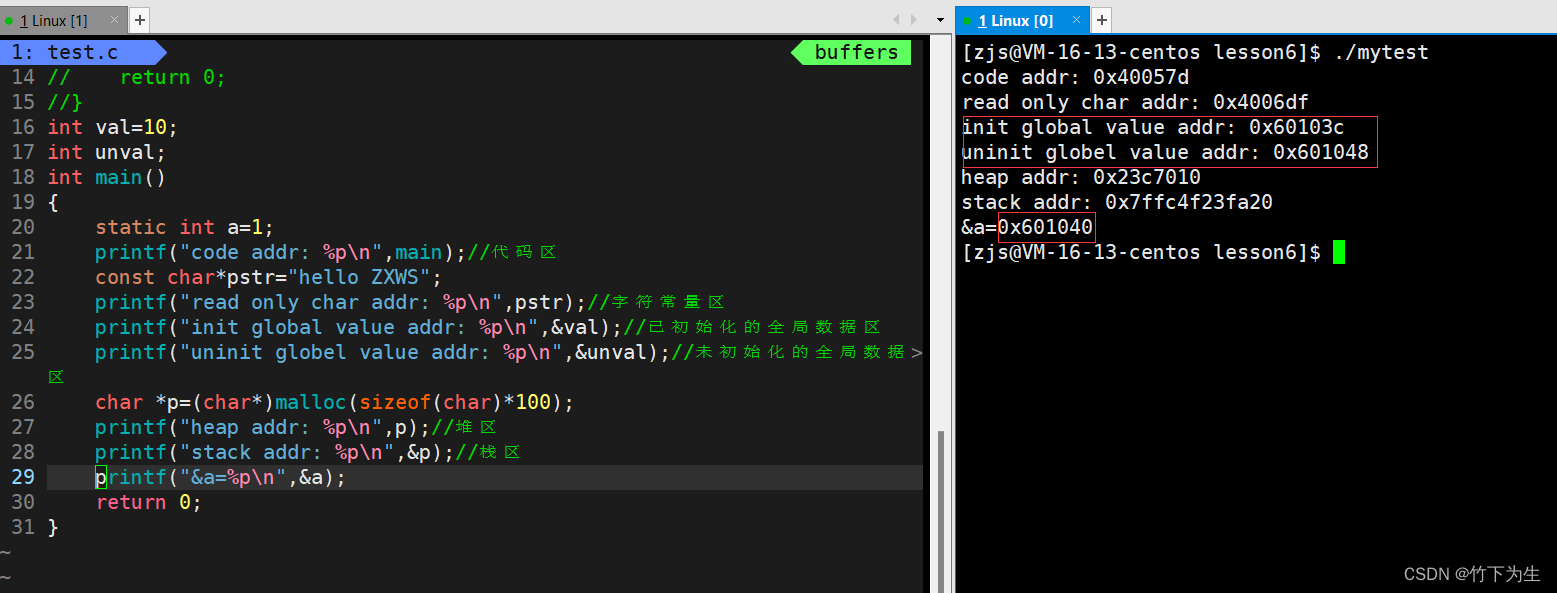
显然,static修饰的变量在全局数据区,所以static的变量初始化之后,能一直存活到程序运行结束
二、这个图所画的空间是内存吗???
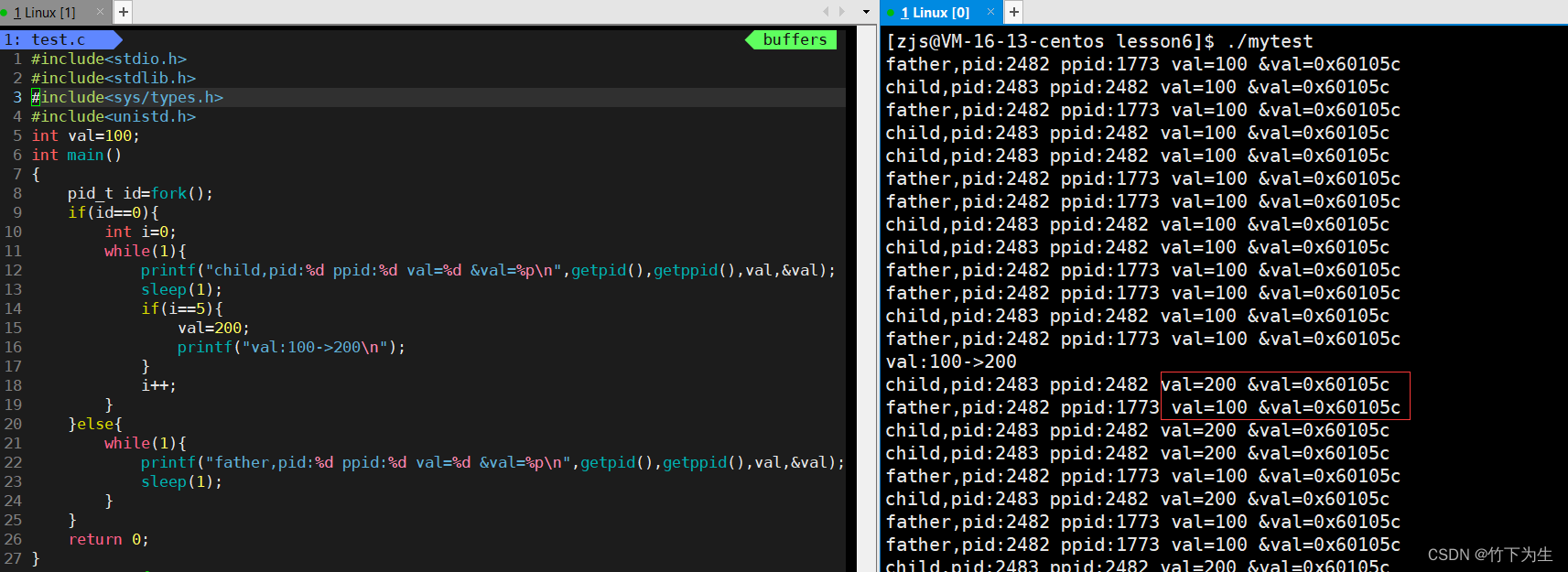
如上图,我们创建了父子进程同时打印val的值和地址,当子进程中的val被改变时,两者的地址依旧相同,如果这个空间是内存(即物理空间),那么怎么可能出现同一个地址处存放不同值的情况呢?
我们称这种地址叫做虚拟地址/线性地址,图表示的空间其实是进程(虚拟)地址空间
我们知道每一个程序在运行时都会有独立的堆栈空间存在保证程序的运行,即每个进程运行之后,都会有一个进程地址空间
每一个进程当然要知道代码的执行有没有出现栈溢出等问题,所以进程对应的pcb也应该能找到这个进程地址空间
同时,虚拟地址肯定要对应一个物理地址,因为我们需要的数据一定在内存上,而内存是物理空间,所以出现了一个叫页表的映射表,里面存放了虚拟地址和物理地址的映射关系
所以上面的代码运行过程如下图所示
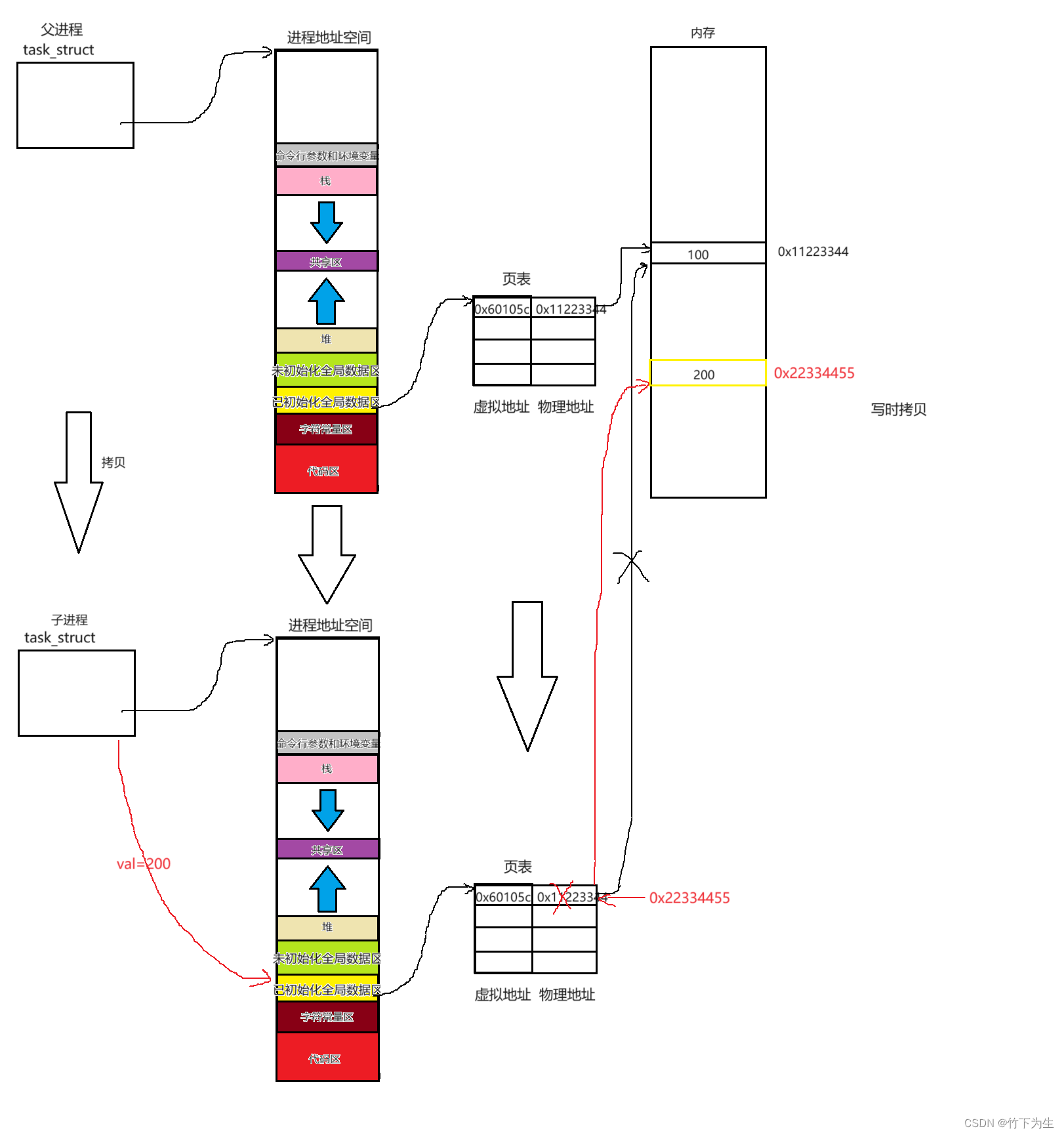
基于这个图,我们就能对val的值相同而地址不同的情况做出合理的解释,因为父子进程的页表不同,虚拟地址和物理地址的映射关系不同,所以虽然他们的虚拟地址一样,但是映射到的物理地址确是不一样的,所以得到值当然也就可以不同(fork同理)
三、什么是进程地址空间和为什么要有进程地址空间
3.1什么是进程地址空间
1.进程地址空间的大小是多少?
这个主要和硬件有关,或者说和内存有关,因为地址空间映射的是内存的空间,所以地址空间的大小为内存的大小(32位机器4G,64位机器16G),但是内存的空间并不是只给一个进程使用,所以进程地址空间仅仅只是给进程在"画大饼",具体空间够不够还得看内存空间,但是需要注意的是:每个进程地址空间的大小都是4G/16G(即每个进程都认为自己有这么大的空间可以使用,就好像你去旅游,你打开地图,全球各个地方都可以去,但是你不会一次性去所有地方)
2.为什么要有区域划分?
将地址空间划分成为代码区,字符常量区等等,这种行为叫做区域划分,很显然做区域划分本质就是为了更好的管理使用空间,但是我们如何在OS中实现区域划分呢?我们只要用结构体将区域的起始地址和结束地址确定就行(当然结构体里面不止这些),而一旦管理好范围,其实就是管理好了进程地址空间,所以进程地址空间实质上就是内核的数据结构mm_struct
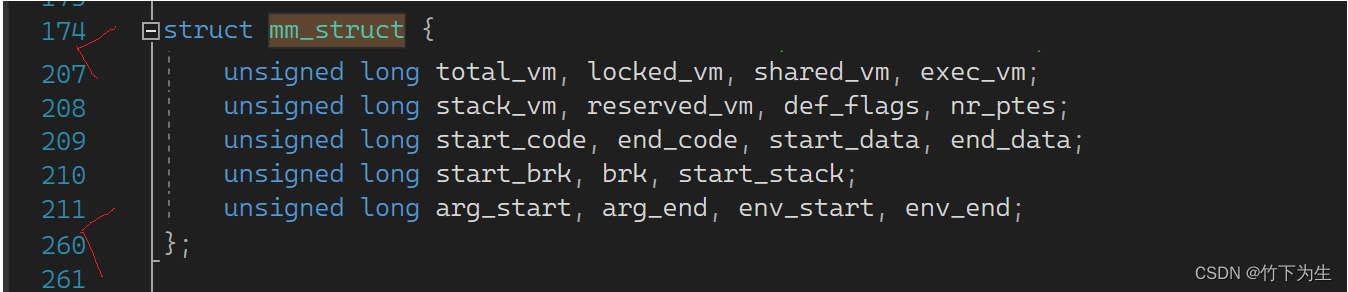
(其实这个空间划分还不够细致,在栈和堆中间的部分其实还能放一些别的数据,所以它里面还有一个结构体指针struct vm_area_struct*,用来开辟一些我们需要的一些数据区域)
(具体的结构体里面的内容,只能去看Linux的源码,下面截取了mm_struct结构体的一部分)
3.2为什么要有进程地址空间?
理由一:让进程以统一的视角看待内存,因为数据在内存上的分布是任意的(因为我们可以通过页表找数据),但是进程地址空间上的地址是有序的,我们可以通过页表映射从有序的地址空间到无序的地址中找到我们需要的数据,且所有的进程都是同样的访问方式
理由二:存在虚拟地址空间能有效的进行进程访问内存的安全检查,比如当我们要修改常量时,就会直接报错,当然这和页表的功能有关,页表中有一个字段用来控制访问权限,比如字符常量区只有r(读)权限
理由三:将进程管理和内存管理解耦,即进程的运行只和进程地址空间进行交互,进程不用操心物理地址的分配问题,内存管理会负责进程申请空间或加载数据时,物理空间的分配工作,而内存管理也不用操心进程的运行问题,它只要按照需求加载数据到内存就行
(这里和进程的挂起状态也有一定联系,当进程被挂起,数据被置换到磁盘的交换区时,页表中有一个字段用来表示物理地址是否被分配和是否有内容(用来判断进程的是否被挂起),当进程再次被执行时,页表会根据这个字段来重新将磁盘的数据加载到内存,同时修改页表的相关字段)
再次理解进程独立性:
通过对进程地址空间的了解,很明显一个进程的结束只和它自己的pcb,进程地址空间,页表有关,也只能影响它自己所映射的物理内存,并不会妨碍其他进程的运行,即进程从结构和空间两个方面都实现了独立
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- zabbix客户端配置及自定义监控
- 推荐3款高效又免费的MP4转MP3格式转换工具
- 【Py/Java/C++三种语言OD2023C卷真题】20天拿下华为OD笔试之【数学】2023C-素数之积【欧弟算法】全网注释最详细分类最全的华为OD真题题解
- prometheus alertmanager note
- Redis如何做内存优化?
- 深度学习核心技术与实践之计算机视觉篇
- 创建Vue3项目
- 200行C++代码写一个QT串口助手
- 宠物空气净化器怎么挑选?猫用空气净化器品牌性比价推荐
- (2024|ICLR reviewing,Transformer-VQ,自注意力线性计算时间,切片和滑动窗,缓存和迭代)