【AIGC-文本/图片生成视频系列-9】MagicVideo-V2: 多阶段高美感视频生成
最近得益于扩散模型的快速发展,文本到视频(T2V)模型的激增。
今天要介绍的是字节的MagicVideo-V2,一个新颖的多阶段 T2V 框架,它集成了文本到图像 (T2I)、图像到视频 (I2V)、视频到视频 (V2V) 和视频帧插值 (VFI)?模块到端到端的视频生成管线。
一. 项目概述与贡献
MagicVideo-V2 是一个多阶段端到端视频生成管线,能够根据文字描述生成高审美视频、高分辨率的视频。
包含以下关键模块:
-
文本到图像模型,可根据给定的文字描述生成高保真的审美图像。
-
图像到视频模型,使用文本提示和生成的图像作为生成关键帧的条件。
-
视频到视频模型,对关键帧进行细化和超分辨率处理,生成高分辨率的视频。
-
视频帧插值模型,对关键帧之间的帧进行插值,以平滑视频运动
-
最后生成高分辨率、流畅、极具美感的视频。
二.?方法详解
MagicVideo-V2 概述。
T2I 模块生成描述场景的 1024×1024 图像。随后,I2V 模块对该静态图像进行动画处理,生成 600×600×32 帧的序列,通过潜在噪声先验确保与初始帧的连续性。V2V 模块将这些帧增强至 1048×1048 分辨率,同时细化视频内容。最后,插值模块将序列扩展至 94 帧,得到分辨率为 1048×1048 的视频,该视频既具有高美感又具有时间平滑性。
在T2I模块,?MagicVideo-V2兼容不同的T2I模型。具体来说,MagicVideo-V2使用内部开发的基于扩散的的T2I模型可输出高美感图像。
在I2V模块,MagicVideo-V2利用T2I模块的参考图来增强该模块。主要体现在三个方面:
1. 使用外观编码器提取参考图像特征,并通过交叉注意力机制注入模型;
2.?采用潜在噪声先验策略来提供起始噪声潜码中的布局条件。具体的,这些帧是从标准高斯噪声初始化的,其平均值已从零转向参考图像潜在值;
3.?使用ControlNet模块直接从图像中提取RGB信息参考图像并将其应用到所有帧。
在V2V模块,V2V模块与I2V模块具有类似的设计。它与 I2V 共享相同的主干和空间层模块。它的运动模块在高分辨率的视频子集上进行一个单独的微调来实现高分辨率视频生成。
在VFI模块?,VFI模块使用内部训练的基于GAN的VFI 模型。它采用与 VQ-GAN 配对的增强型可变形可分离卷积 (EDSC) 头 。这点没什么好说的,也是用内部的方案。
三. 文本生成视频相关结果



四. 与其他方法对比结果
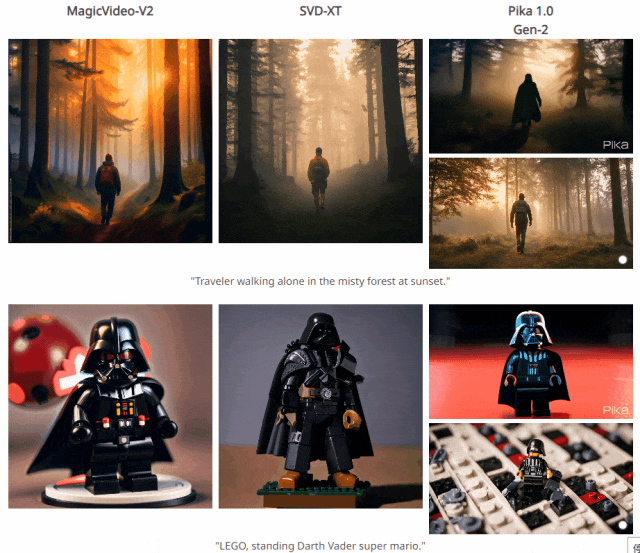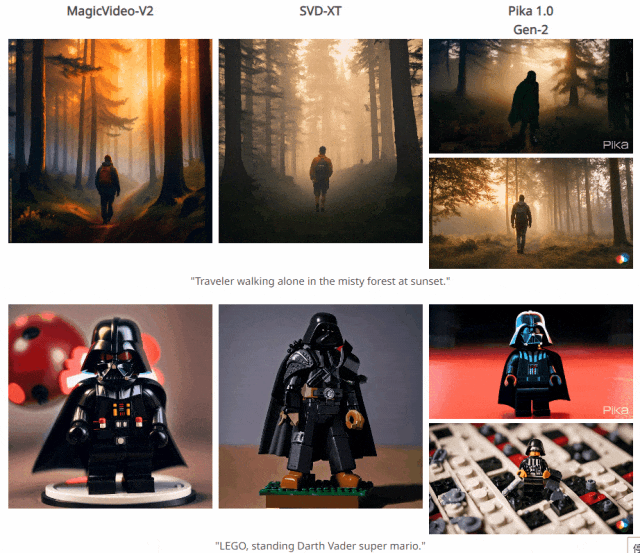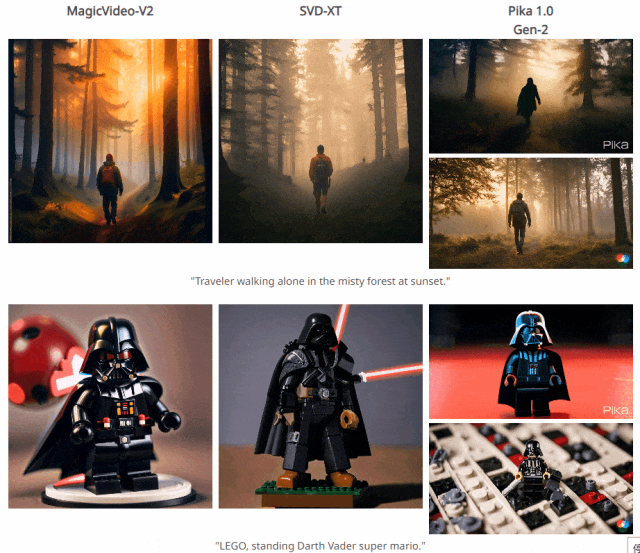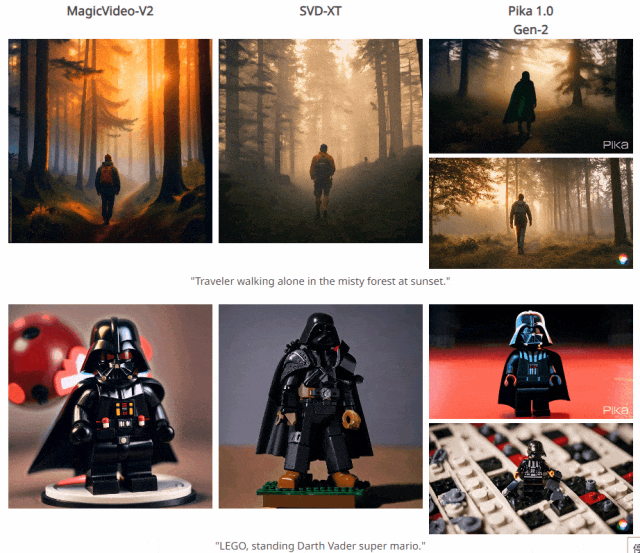





五. 个人感悟
字节的这个工作有点东西,没有辜负美感这个词,将平平无奇的一阶段文生图扩展成多阶段以此来增强最后的生成结果,工作量还是挺大的。
另外文章中多处提到用了字节内部的东西,看来字节还是憋了不少好东西的。对于字节内部的数据,我想说的是,字节手握抖音和tiktok两大高质量数据源,可以炼出不少好东西,比如上次的MagicAnimate,还有这次高质量图片生成以及利用高分辨率视频微调。这些优势也是个人或是一些公司不具备的。AIGC依旧是数据为王的时代!
欢迎加入AI杰克王的免费知识星球,海量干货等着你,一起探讨学习AIGC!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Docker数据持久化
- 黑客(网络安全)技术30天速成
- 使用OpenGL实现光源投射器(Light Casters)- C/C++实现
- Flutter组件GridView使用介绍
- PINN物理信息网络 | 泊松方程的物理信息神经网络PINN解法
- (三)Java 基本数据类型
- Promise
- 基于Java技术的校园防疫管理系统设计与实现-计算机毕业设计源码80315
- MySQL 行格式详解
- Acwing858_Prim算法求最小生成树