深度学习(3)--递归神经网络(RNN)和词向量模型Word2Vec
一.递归神经网络基础概念
递归神经网络(Recursive Neural Network, RNN)可以解决有时间序列的问题,处理诸如树、图这样的递归结构。
CNN主要应用在计算机视觉CV中,RNN主要应用在自然语言处理NLP中。
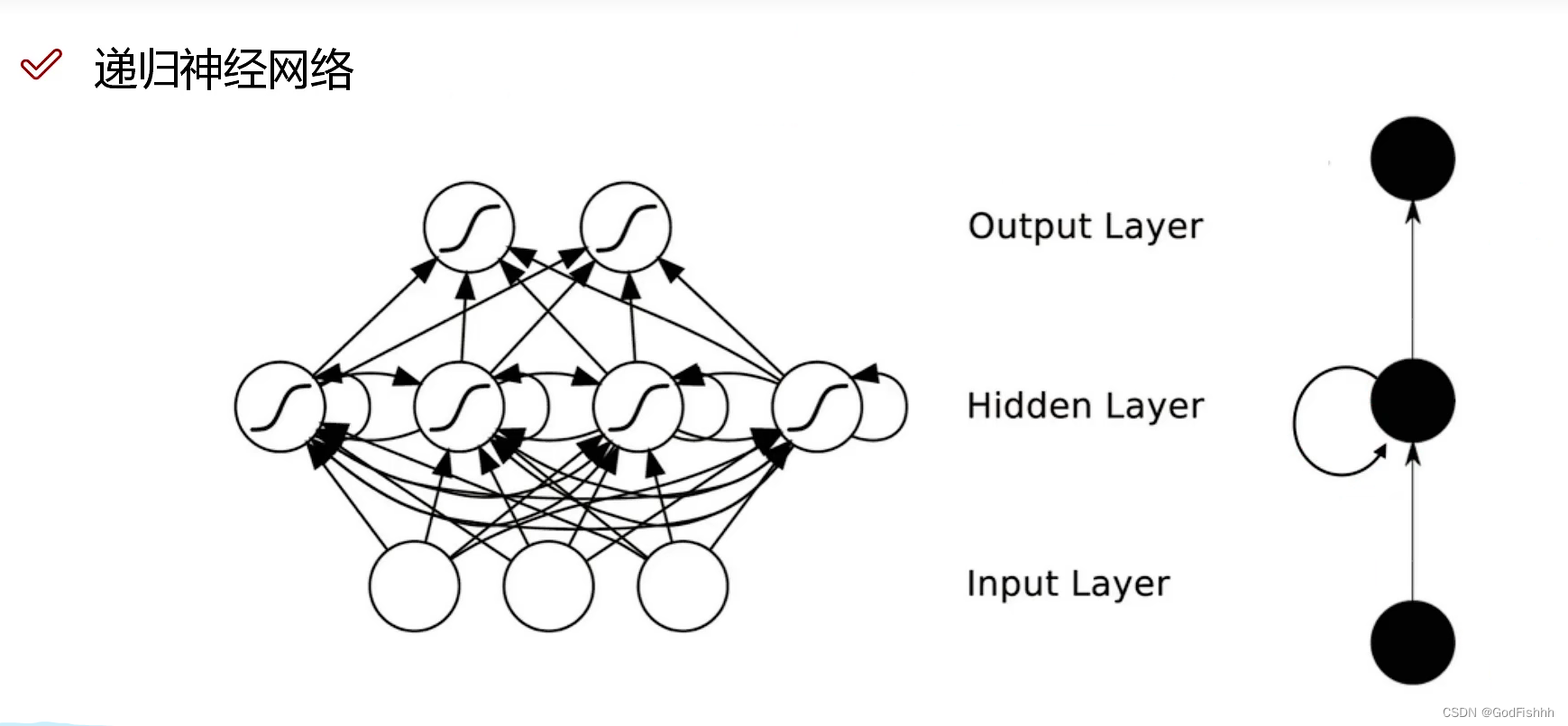

1.h0,h1.....ht对应的是不同输入得到的中间结果。
2.处理自然语言I am GodFishhh or AFish:
则对应的输入为X0 -- I,X1 -- am,X2 -- GodFishhh,X3 -- or,X4 -- AFish,再通过一定的方法将自然语言输入转换为计算机能够理解的形式(例如Word2Vec方法,将文本中的词语转换为向量形式)。
3.RNN网络最后输出的结果会考虑之前所有的中间结果,记录的数据太多可能会产生误差或者错误。
LSTM长短记忆网络是一种特殊的递归神经网络,可以解决上述记录数据太多的问题:

在普通的RNN中,t-1时刻得到的输出值h(t-1)会被简单的复制到t时刻,并与t时刻的输入值X(t)整合再经过一个tanh函数后形成输出。
而在LSTM中,对于t-1时刻得到的输出值h(t-1)会有更加复杂的操作。
二.自然语言处理-词向量模型Word2Vec
2.1.词向量模型
将文本向量化后,就可以通过不同方法(欧氏距离、曼哈顿距离、切比雪夫距离、余弦相似度等)来计算两个向量之间的相似度。

同时通常来说,向量的维度越高,能够提供的信息也越多,因此所计算出的相似度的可靠性也就越高,匹配的正确性也就越高(常用向量维度为50~300)

而词向量模型Word2Vec的作用就是把词转化为向量
例如如下训练好的词向量,将每一个词都表示为50维的向量:

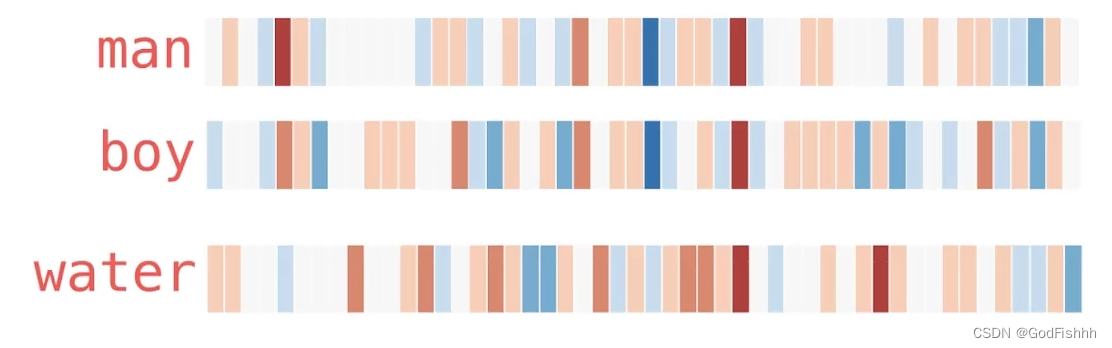
 通过比对不同词向量的热度图可以发现,有相关特性的词在热度图上较为相似,而无明显相关特性的词在热度图上则差异较大:
通过比对不同词向量的热度图可以发现,有相关特性的词在热度图上较为相似,而无明显相关特性的词在热度图上则差异较大:
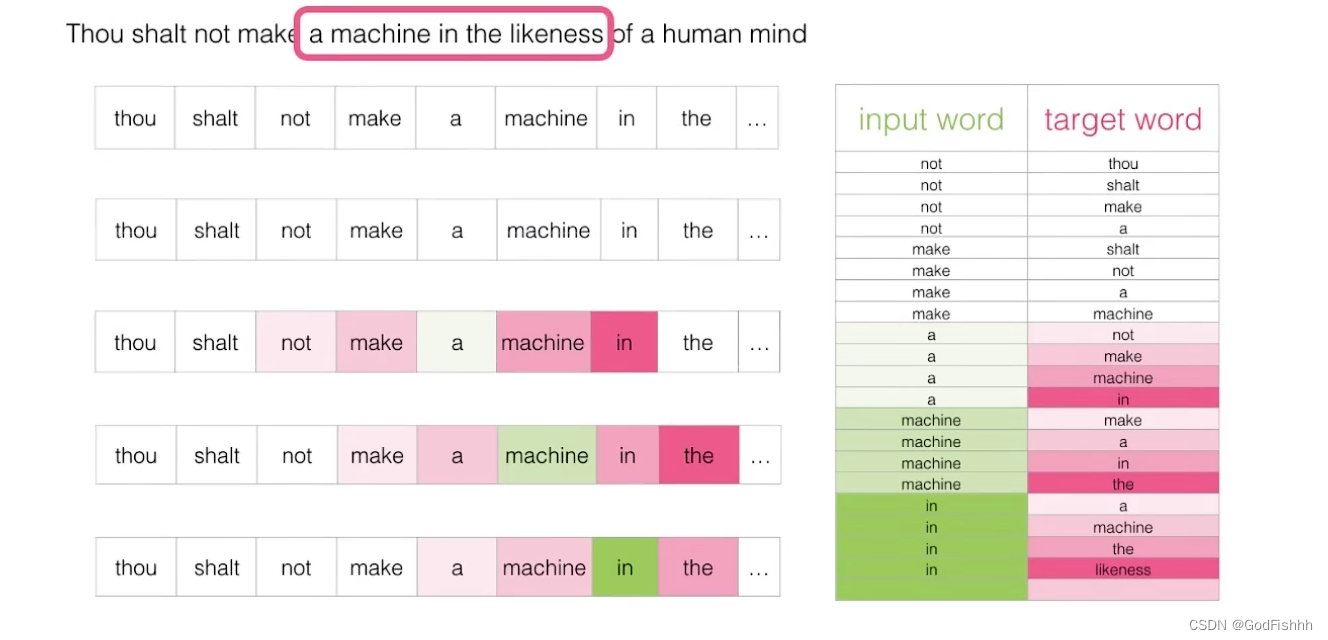
在词向量模型中,输入可以是多个词,而在模型的最后一层中连接了SoftMax,所以会输出所有词可能是下一个词的概率。

而文字的输入则是通过一个embeddings层(词嵌入层)来解决。在神经网络初始化时,会随机初始化一个N×K的矩阵,其中N为词典的大小,K为词向量的维度数。初始的词嵌入曾是随机生成的,通过反向传播进行更新优化。

2.2.常用模型对比
一切具有正常逻辑的语句都可以作为训练数据。
(1).CBOW模型
CBOW的全称是continuous bag of words(连续词袋模型)。其本质也是通过context word(背景词)来预测target word(目标词)。
该模型的输入为上下文,输出为该上下文中间的词汇:

?
(2).Skip-gram模型
该模型与CBOW模型相反,模型的输入为一个词汇,而输出是该词汇的上下文:

?示例:
2.3.负采样方案
如下图所示,将构建好的数据集丢给词模型进行训练:
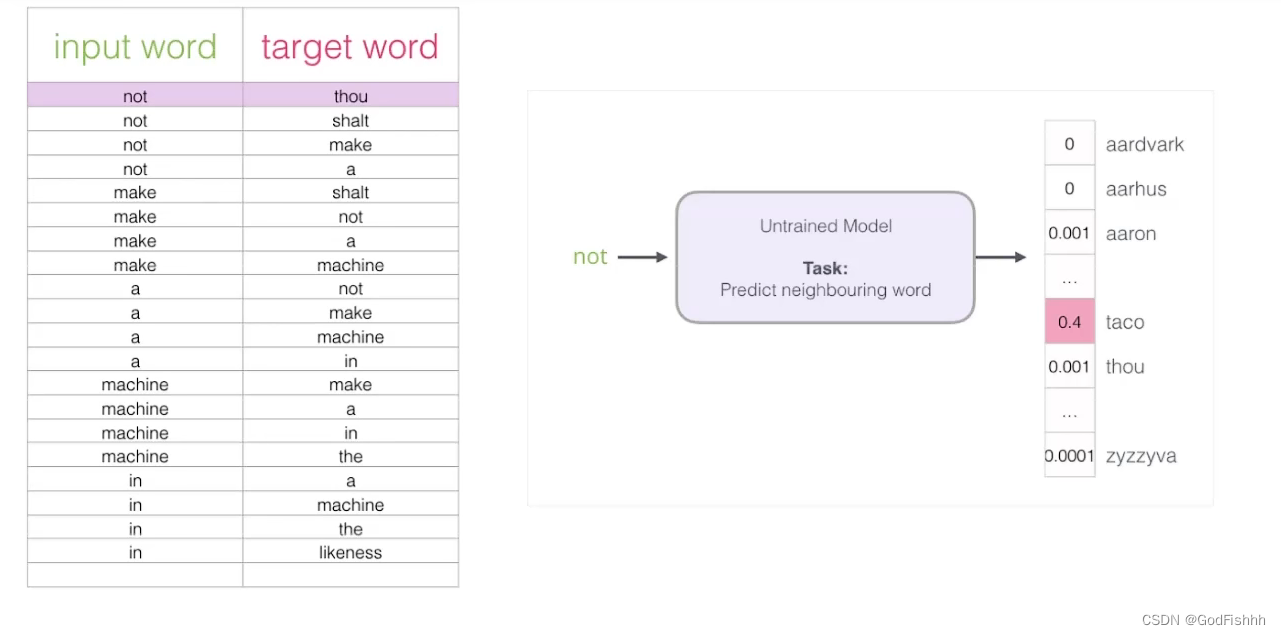
发现最后一层SoftMax的计算在语料库很大的情况下会非常耗时。
因此,有一种改进方法是将此时的输入和输出都作为输入值,做一个二分类问题,如果两个输入是邻居则输出1,不是邻居则输出0。(eg.传统模型中,输入not,希望输出是thou,但需要经过SoftMax层计算出所有词可能作为下一个词的概率,但此时则是将not和thou均作为输入,如果相邻则输出1,不相邻则输出0)
 ?
?
但此时的问题在于,训练集本身就是由上下文构建出来的,所以训练集构建出来的输出targer均为1,无法进行较好的训练。
改进方案:加入一些负样本,即不相邻的两个输入词,输出的target值为0.(一般负样本个数为5个左右)?

2.4.词向量训练过程
(1).初始化词向量矩阵


(2).训练模型
通过神经网络反向传播来训练模型,与普通的训练模型只更新权重值不同,此时不光会更新权重参数矩阵,还会更新输入数据。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 二级C语言备考5
- 设计模式之建造者模式
- 【MySQL】MySQL执行计划的type类型
- harmonyOS 时间选择组件(TimePicker)
- SpringIOC之support模块GenericApplicationContext
- 解析strlen(以及部分数组知识)
- 基于DCT算法的数字水印嵌入、检测和攻击的Matlab代码实现
- AJAX练习题:加强你的异步通信技能!
- C++ 多线程学习:目录
- 【Linux】多线程编程