数据库开发之事务和索引的详细解析
2. 事务
场景:学工部整个部门解散了,该部门及部门下的员工都需要删除了。
-
操作:
-- 删除学工部 delete from dept where id = 1; ?-- 删除成功 ? -- 删除学工部的员工 delete from emp where dept_id = 1; -- 删除失败(操作过程中出现错误:造成删除没有成功) -
问题:如果删除部门成功了,而删除该部门的员工时失败了,此时就造成了数据的不一致。
要解决上述的问题,就需要通过数据库中的事务来解决。
2.1 介绍
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。
简而言之:事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
2.2 操作
MYSQL中有两种方式进行事务的操作:
-
自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交)
-
手动提交事务:先开启,再提交
事务操作有关的SQL语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; / begin ; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤:
第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
使用事务控制删除部门和删除该部门下的员工的操作:
-- 开启事务
start transaction ;
?
-- 删除学工部
delete from tb_dept where id = 1;
?
-- 删除学工部的员工
delete from tb_emp where dept_id = 1;-
上述的这组SQL语句,如果如果执行成功,则提交事务
-- 提交事务 (成功时执行)
commit ;
上述的这组SQL语句,如果如果执行失败,则回滚事务
-- 回滚事务 (出错时执行)
rollback ;2.3 四大特性
面试题:事务有哪些特性?
-
原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
-
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
-
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
-
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务的四大特性简称为:ACID
-
原子性(Atomicity) :原子性是指事务包装的一组sql是一个不可分割的工作单元,事务中的操作要么全部成功,要么全部失败。
-
一致性(Consistency):一个事务完成之后数据都必须处于一致性状态。
如果事务成功的完成,那么数据库的所有变化将生效。
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
-
隔离性(Isolation):多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
一个事务的成功或者失败对于其他的事务是没有影响。
-
持久性(Durability):一个事务一旦被提交或回滚,它对数据库的改变将是永久性的,哪怕数据库发生异常,重启之后数据亦然存在。
3. 索引
3.1 介绍
索引(index):是帮助数据库高效获取数据的数据结构 。
-
简单来讲,就是使用索引可以提高查询的效率。
测试没有使用索引的查询:

添加索引后查询:
-- 添加索引
create index idx_sku_sn on tb_sku (sn); ?#在添加索引时,也需要消耗时间
?
-- 查询数据(使用了索引)
select * from tb_sku where sn = '100000003145008';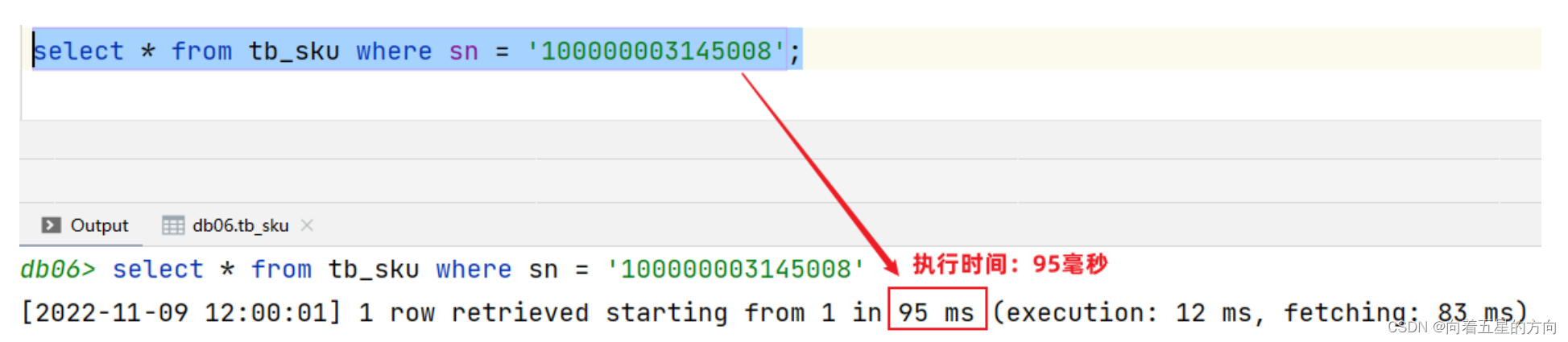
优点:
-
提高数据查询的效率,降低数据库的IO成本。
-
通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
-
索引会占用存储空间。
-
索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
3.2 结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。
我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。
在没有了解B+Tree结构前,我们先回顾下之前所学习的树结构:
二叉查找树:左边的子节点比父节点小,右边的子节点比父节点大

当我们向二叉查找树保存数据时,是按照从大到小(或从小到大)的顺序保存的,此时就会形成一个单向链表,搜索性能会打折扣。

可以选择平衡二叉树或者是红黑树来解决上述问题。(红黑树也是一棵平衡的二叉树)

但是在Mysql数据库中并没有使用二叉搜索数或二叉平衡数或红黑树来作为索引的结构。
思考:采用二叉搜索树或者是红黑树来作为索引的结构有什么问题?
?
答案
?
说明:如果数据结构是红黑树,那么查询1000万条数据,根据计算树的高度大概是23左右,这样确实比之前的方式快了很多,但是如果高并发访问,那么一个用户有可能需要23次磁盘IO,那么100万用户,那么会造成效率极其低下。所以为了减少红黑树的高度,那么就得增加树的宽度,就是不再像红黑树一样每个节点只能保存一个数据,可以引入另外一种数据结构,一个节点可以保存多个数据,这样宽度就会增加从而降低树的高度。这种数据结构例如BTree就满足。
下面我们来看看B+Tree(多路平衡搜索树)结构中如何避免这个问题:
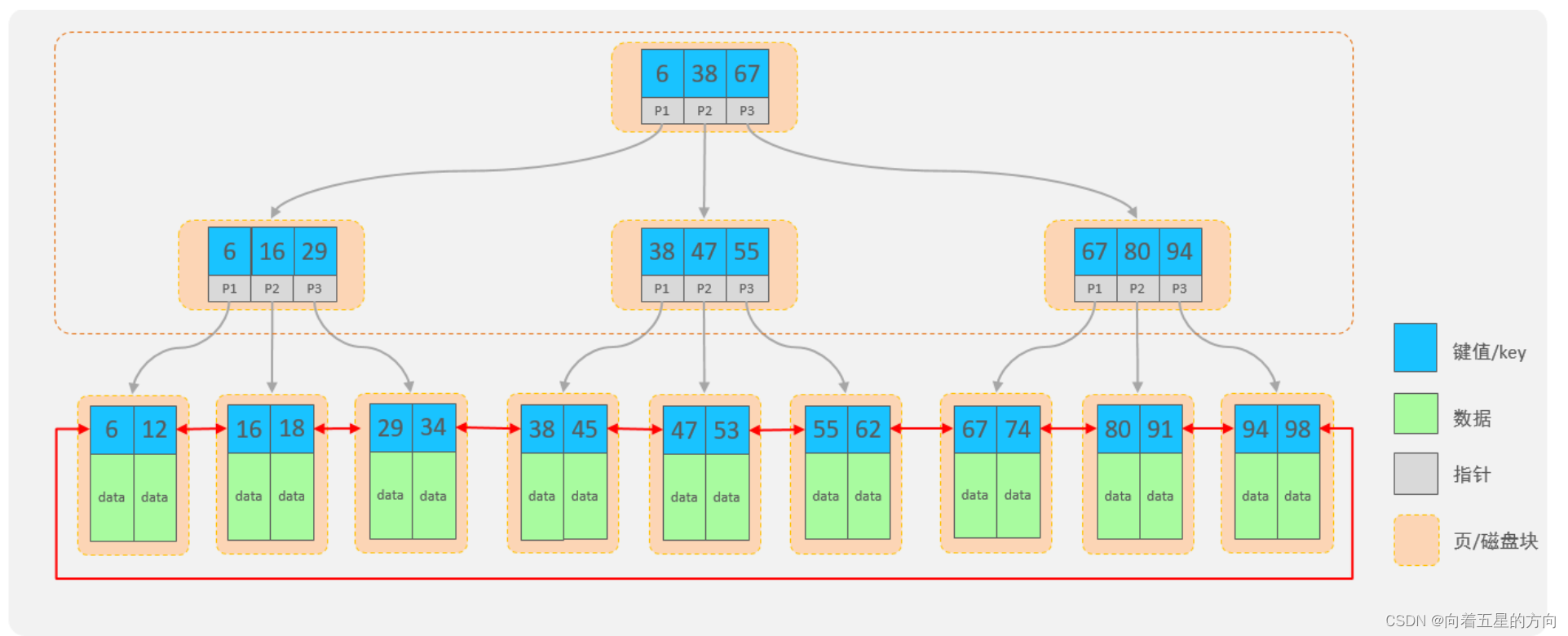
B+Tree结构:
-
每一个节点,可以存储多个key(有n个key,就有n个指针)
-
节点分为:叶子节点、非叶子节点
-
叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
-
非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针
-
-
为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
拓展:
非叶子节点都是由key+指针域组成的,一个key占8字节,一个指针占6字节,而一个节点总共容量是16KB,那么可以计算出一个节点可以存储的元素个数:16*1024字节 / (8+6)=1170个元素。
查看mysql索引节点大小:show global status like 'innodb_page_size'; -- 节点大小:16384
当根节点中可以存储1170个元素,那么根据每个元素的地址值又会找到下面的子节点,每个子节点也会存储1170个元素,那么第二层即第二次IO的时候就会找到数据大概是:1170*1170=135W。也就是说B+Tree数据结构中只需要经历两次磁盘IO就可以找到135W条数据。
对于第二层每个元素有指针,那么会找到第三层,第三层由key+数据组成,假设key+数据总大小是1KB,而每个节点一共能存储16KB,所以一个第三层一个节点大概可以存储16个元素(即16条记录)。那么结合第二层每个元素通过指针域找到第三层的节点,第二层一共是135W个元素,那么第三层总元素大小就是:135W*16结果就是2000W+的元素个数。
结合上述分析B+Tree有如下优点:
千万条数据,B+Tree可以控制在小于等于3的高度
所有的数据都存储在叶子节点上,并且底层已经实现了按照索引进行排序,还可以支持范围查询,叶子节点是一个双向链表,支持从小到大或者从大到小查找
3.3 语法
创建索引
create [ unique ] ?index 索引名 on 表名 (字段名,... ) ;案例:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name); ?
?
在创建表时,如果添加了主键和唯一约束,就会默认创建:主键索引、唯一约束

查看索引
show ?index ?from 表名;案例:查询 tb_emp 表的索引信息
show ?index ?from tb_emp;
删除索引
drop ?index 索引名 ?on 表名;案例:删除 tb_emp 表中name字段的索引
drop index idx_emp_name on tb_emp;注意事项:
主键字段,在建表时,会自动创建主键索引
添加唯一约束时,数据库实际上会添加唯一索引
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 挑战Python100题(3)
- 代码进阶-代码注意事项总结
- 【设计模式】备忘录模式
- SORT源码系列-iou_batch()计算检测框和跟踪框的IoU
- ACM32F403/F433 12 位多通道国产芯片,支持 MPU 存储保护功能,应用于工业控制,智能家居等产品中
- 04 思维导图的方式回顾ospf
- Java锁的分类
- 餐饮店如何选择合适的油烟净化器?
- 新媒体营销的相关理论
- 计算机科学速成课【学习笔记】(3)——布尔逻辑和逻辑门