大模型听课笔记——书生·浦语(5)
发布时间:2024年01月15日
LMDeploy 的量化和部署
1 大模型部署简介
模型部署:将训练好的模型在特定软硬件环境中启动的过程,使模型能够接受输入并返回结果。
为了满足性能和效率的需求。常常需要对模型进行优化,例如模型压缩和硬件加速
产品形态:云端、变韵计算端、移动端
计算设备:CPU、GPU、NPU、TPU等
大模型的特点:
内存开销巨大
庞大的参数量
采用自回归生成token, 需要缓存Attentionde k/v , 带来巨大的内存开销
动态shape
请求数不固定
Token逐个生成,且数量不定
相对视觉模型,LLM结构简单
大模型部署挑战
设备
如何应对巨大的存储
推理
如何加速token的生成速度
如何解决动态shape,让推理不间断
如何有效管理和利用内存
服务
如何提升整体吞吐量
如何降低响应时间
大模型部署方案
技术点
模型并行
低比特量化
Page Attention
transformer计算和访存优化
Continuous Batch
方案
1 huggingface transformers
2 专门的推理加速框架
云端: imdeplloy, vllm, tersorrt-lllm, deepspeed…
移动端: llama.cpp, mlc-llm…
2 LMDeploy 简介
LMDeploy是LLM是在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。
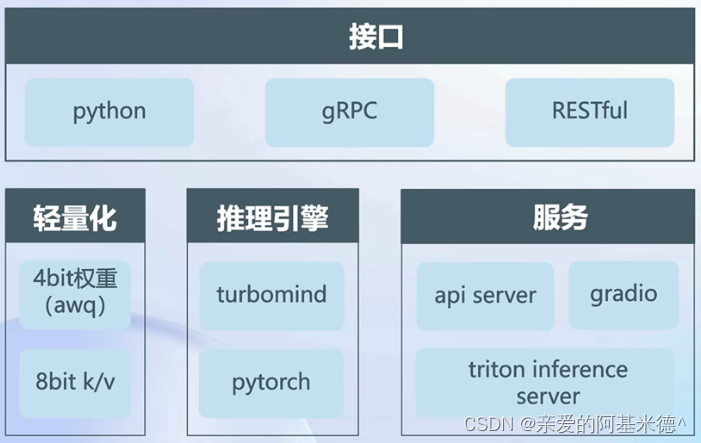
量化——核心功能
为什么做量化?
显存下降
为什么做Weight Only的量化?
LLM是典型的访存密集型任务


如何做weight only 的量化?
- LMDeploy使用MIT HAN LAB 开源的AWQ算法,量化为4bit模型
- 推理时,先把4bit权重法案量化回FP16(在kernel内部进行,从Global Memory读取时仍是4bit ),仍旧使用的是FP16计算
- 相较于社区使用较多的
GPTQ算法 AWQ的推理速度更快,量化的时间更短
推理引擎TurboMind——核心功能

持续批处理
请求队列:推理请求首先加到请求队列中
persistent线程:
1 若batch中有空闲槽位,从队列拉取请求,尽量填满空闲槽位。若无,继续对当前batch中的请求进行forward
2 Batch每forward完一次,是否有request推理结束。结束的request发生结果,释放槽位。
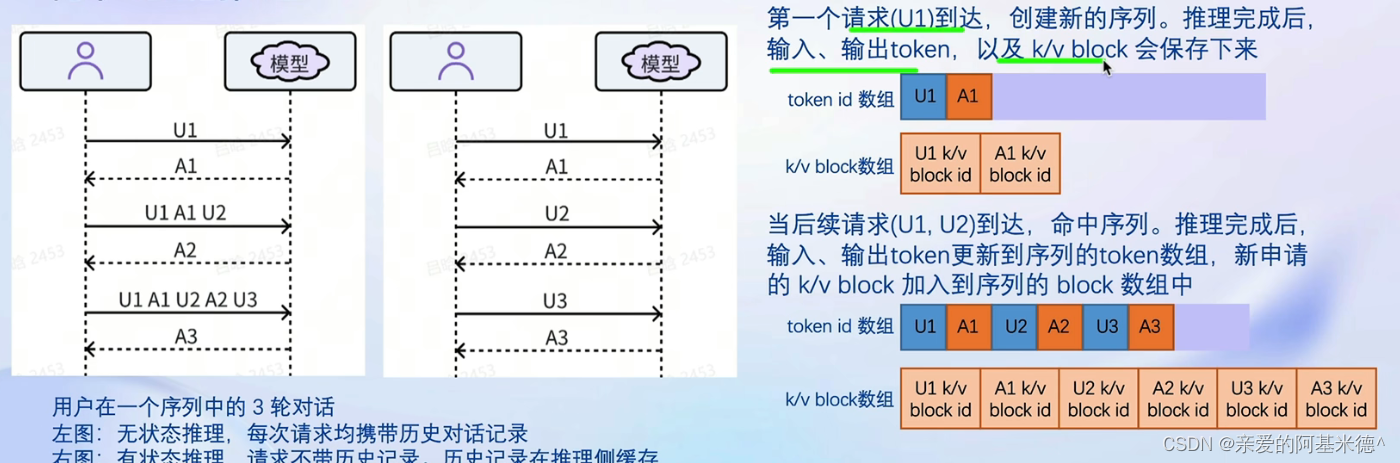
有状态的推理
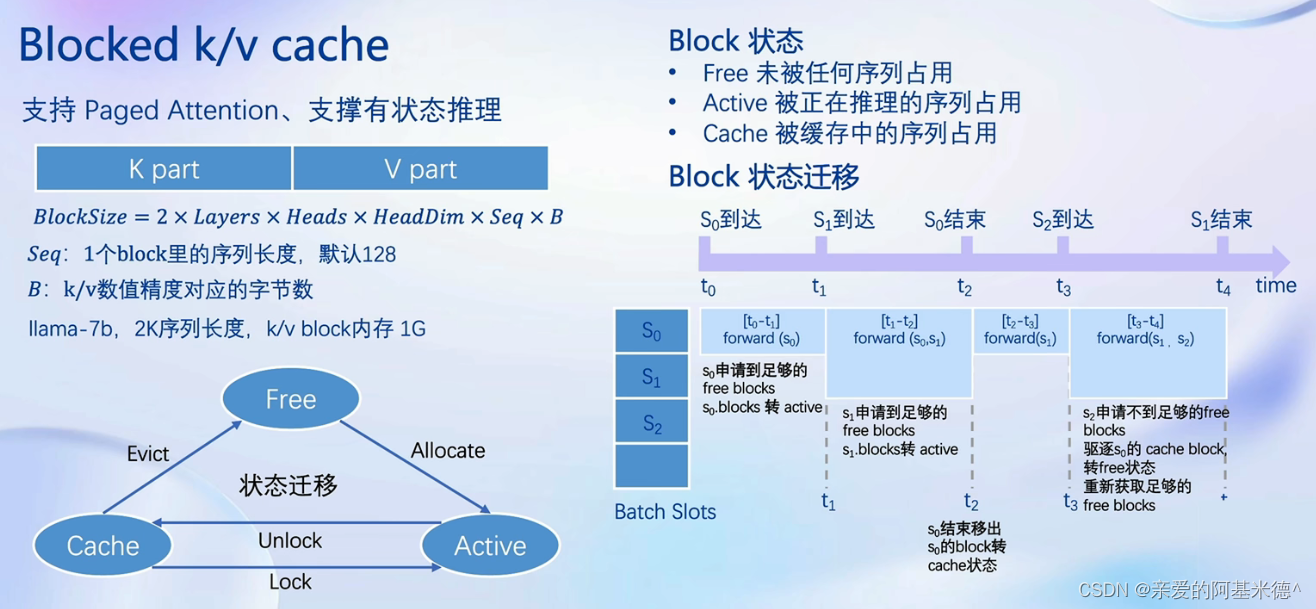
Blocked k/v cache
高性能的 cuda kernel

3 实践——安装、部署、量化
见作业(4)
文章来源:https://blog.csdn.net/rabbit9798/article/details/135559971
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AI日报:信用公司转型人工智能的长采访...或许能给你一些启发
- Netty-Netty源码分析流程图
- Redis 怎么实现分布式锁?
- 【开源】基于JAVA的高校宿舍调配管理系统
- 30、WEB攻防——通用漏洞&SQL注入&CTF&二次&堆叠&DNS带外
- c++字符串
- golang os 包用法
- ARO Robot Dynamics
- SSM框架学习笔记04 | SpringMVC
- 【开题报告】基于SpringBoot的线上日记管理系统的设计与实现