深入理解MySQL索引底层数据结构
听课问题(听完课自己查资料)
- 什么是二叉树 二叉树是怎么存储数据的
- 一个链表是一个集合的数据结构 List是怎么便利找到指定下标元素为什么会快?
- 什么是红黑树 红黑树是怎么存储数据的
- 什么是B TREE 是怎么存储数据的
- 什么是B+TREE 是怎么存储数据的
疑惑答案
a. 二叉树是按照插入的顺序依次排序

比如依次插入的数据 为 : 5、4、6、5、5、5、5
他们存储的时候为 :
- 5是第一个存进去的 所以放在了第一个也就是根节点
- 4第二个放进去小于根节点 5 所以在 左边
- 6第三个放进去大于根节点放在右边
- 5第四个放进去等于(不小于根节点)根节点所以放在根节点5右边 又因为右边有6了 小于6所以放在了6的左边
- 5第五个放进去不小于根节点5放左边 又小于6放左边又不小于5放右边
- 剩下的同理....
ⅰ. 查询方法
比如查询 6 会发现根节点为5 因为6大于5所以去右边找然后就找到了5
ⅱ. 二叉树优点
查询速度快, 比如查询6 这样直接就去右边节点找了可以直接排除左边的数据,而不用去对比全部的数据了
ⅲ. 二叉树缺点
可能会出现偏移的特别厉害 比如1、2、3、4、5依次插入 就会导致形成一个链表,这样二叉树就没必要了
b. 二叉树会形成链表 那么链表为什么会快呢?
例如Java中的链表
ArrayList是一个带有下标的数组
而LinkedList是一个不带有下标的链表根据插入的顺序串在一起的链表,他的查询速度会比较慢是因为 每次查询都要遍历所有的元素
所以他们中ArrayList是一个查询比较快的List 主要是因为 一个数组他是可以通过下标获取元素的
而二叉树中如果形成了类似于一个链表就会导致和LinkedList一样每次查询都会遍历所有的元素
c. 平衡二叉树
可以看这个视频

如果不平衡 解决办法 找到一个不平衡那两条线中最长的一条线 然后取出邻近根节点最近的三个元素 重新组成一个小的树 其他没设计到这条最长路线的元素原封不动 设计到的重新进行排序进去
ⅰ. 平衡二叉树优缺点
优点: 保证了不会出现链表结构
缺点:每次都需要左右旋 每次新增需要的步骤太多 而且可能会导致树的高度很高 查询性能也会下降
d. 什么是红黑树 红黑树是怎么存储元素的
红黑树首先保证以下几点
- 根节点必须是黑色
- 红色上级和下级必须是黑色
- 叶子节点必须是红色
- 新插入的必须是红色

例题:

如果发现 位置出现了调换,那么涉及到调换的地方涉及到的元素在重组后重新排序添加进去
ⅰ. 红黑树优点
红黑树复杂的要求都是为了保证了树的平衡和树的高度不那么高
ⅱ. 红黑树缺点
对于mysql为什么不用红黑树是因为 一个张表可能存储上千万数据 一个节点存储的数据有限也会导致树的深度太高
什么是B TREE
可以理解为很多个红黑树组合而成 只不过他们的根节点有很多个 这样就会降低树的深度 从而查询快
B TREE是对红黑树的整合 只不过B TREE是每个节点都会存储地址值

只不过中间节点上会存储它对应的数据
e. 什么是B + TREE
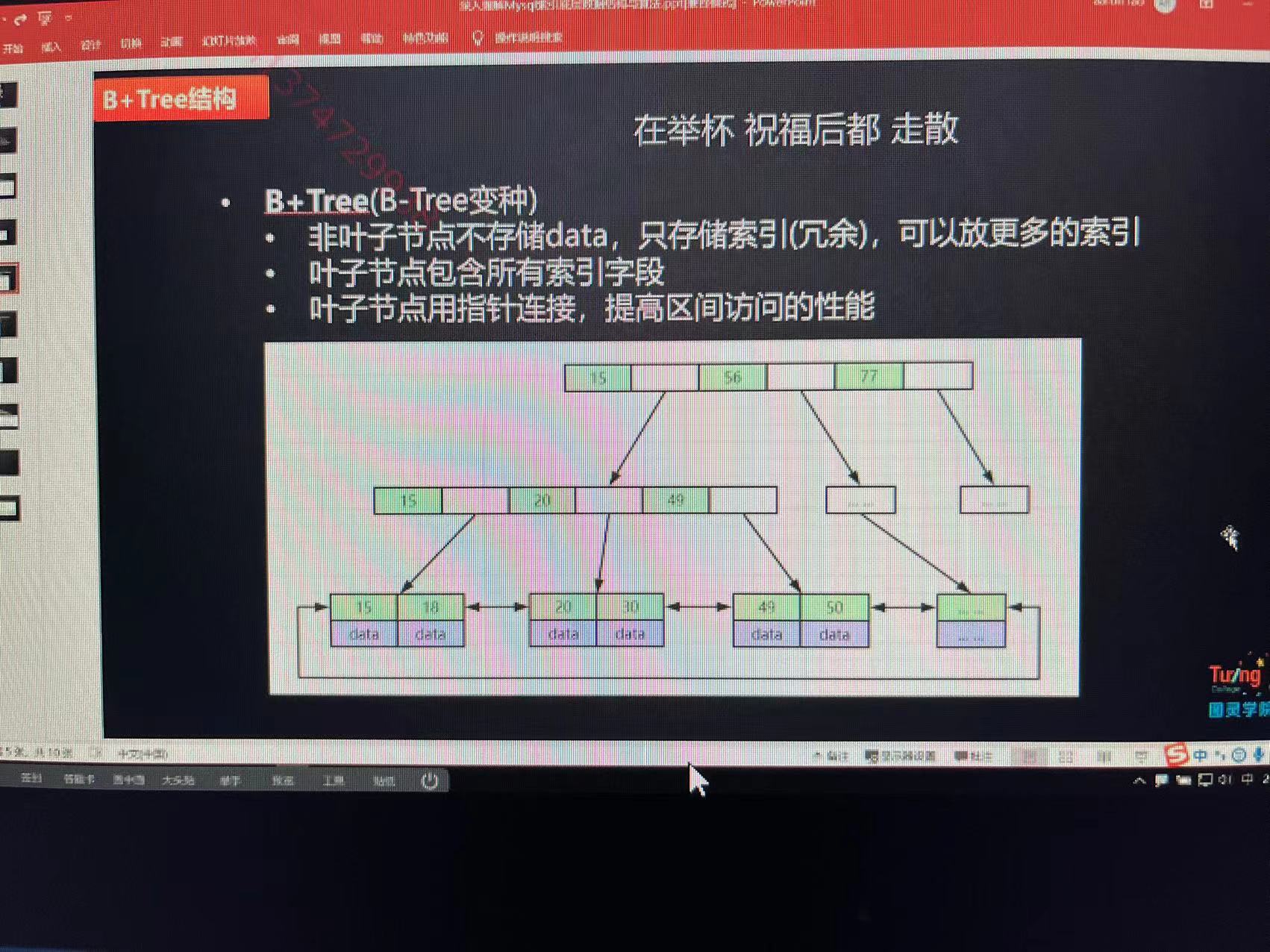
因为B TREE 根节点会存储 对应的数据 加入一个 数据为 1k 根节点一共是16k的数据 这样会导致存储的节点数量减少 进而导致子节点减少 导致存储的总数据减少
而 B + TREE 把存储的数据都放到了叶子节点 这样根节点的 16kb 内存全部存储 子节点的地址 可以增加存储的数量 就可以做到降低树的高度提高查询效率
ⅰ. 一个B+TREE三层可以存储多少数据计算
第一层:假设一个BigInt类型的数据大小为 8b 而mysql中一个地址值为 6b 他们加起来是 14b 16kb/14b = 1142
第二层:同理子节点也为 1142一个
第三层:叶子节点 一个索引就会对应一个数据或者地址值 因为innerdb 存储的是数据 mysiam存储的是地址值 假设他们都为1k最大 那么就是 可以存储16个
最终也就是 三层总数量为 1142 * 1142 * 16 = 20,866,624 差不多两千万数据
1. 聚集索引
不需要回表
a. db引擎如果是主键索引 非叶子节点存储的什么?
主键索引存储的都是该主键对应的一条数据,所以db引擎查询比非聚集引擎快
b. db引擎如果是非主键索引非叶子节点存储的什么
其实非主键索引 并不是聚集索引 因为他要回表
非主键索引非叶子节点存储的其实是主键 通过条件去非主键索引构建的树中找到对应的非叶子节点,非叶子节点存储的是数据对应的主键(比如id,rowid) 通过找到的主键再去主键索引中找到对应的数据(去主键索引中找对应的数据就是一次回表操作,相比较于主键索引会慢,因为主键索引不用回表,找到了对应数据就直接返回)
c. db使用联合索引或者某一个字段(非主键字段)当作索引 那么非叶子节点存储的是什么?
非叶子节点存储的就是主键 如果该表中没有主键 那么mysql就会自己找一行没有重复的数据当作主键,如果每行数据都会有重复的那么就会自己生成一个隐藏的 rowId作为主键 他们就会存储到 联合索引构成的树中的非叶子节点中作为值,找到以后通过回表主键索引找到对应的数据。
d. db引擎为什么非主键索引非叶子节点存储的是主键id或者rowid?
因为这样可以减少空间存储 我们平常公司中使用的一块内存其实都是比较昂贵的,如果我们一个非主键索引使用的联合索引,那么非叶子节点如果存储对应的索引字段,就会非常占用空间,因为我们存储的是联合索引,有好几个字段共同组成的,一次性存储了好几个字段值会比较浪费空间
2. 非聚集索引
需要回表
非聚集索引就是需要回表 mysiam存储的其实就是 myd磁盘文件中对应的数据地址
比如 通过主键或者非主键索引维护的树,聚集索引中主键索引非叶子节点存储的就是对应的一行数据,但是mysiam中非叶子节点存储的就是该条数据对应的磁盘文件地址。通过条件找到对应非叶子节点,通过非叶子节点中对应磁盘文件地址去myd文件中找到对应数据再返回。因为多了一次回表操作所以一般会比聚集索引慢
3. hash运算
MySQL中hash算法其实比B TREE算法快。因为每次都是计算一次hash就直接判断出来在那个位置放着,找到该位置直接放到该位置的链表中就行了。
查询: 通过条件就可以直接定位到该元素在那个位置,找到该链表就可以找到对应元素磁盘文件地址值,再去对应磁盘文件中找到该数据返回 参照HashMap 是比较快的
缺点: 只能进行精确匹配 如果使用 > 或者 like 查询 是不支持的只能全表查询
因为 他是进行hash计算的
如果 一个 hmh 比如计算的hash 是 50 现在通过 h进行模糊匹配 h 对应hash比如是 20 那么找到对应的位置其实并不是 hmh对应的位置所以不支持模糊
4. 联合索引
a. 为什么只有走最左前缀才能走索引

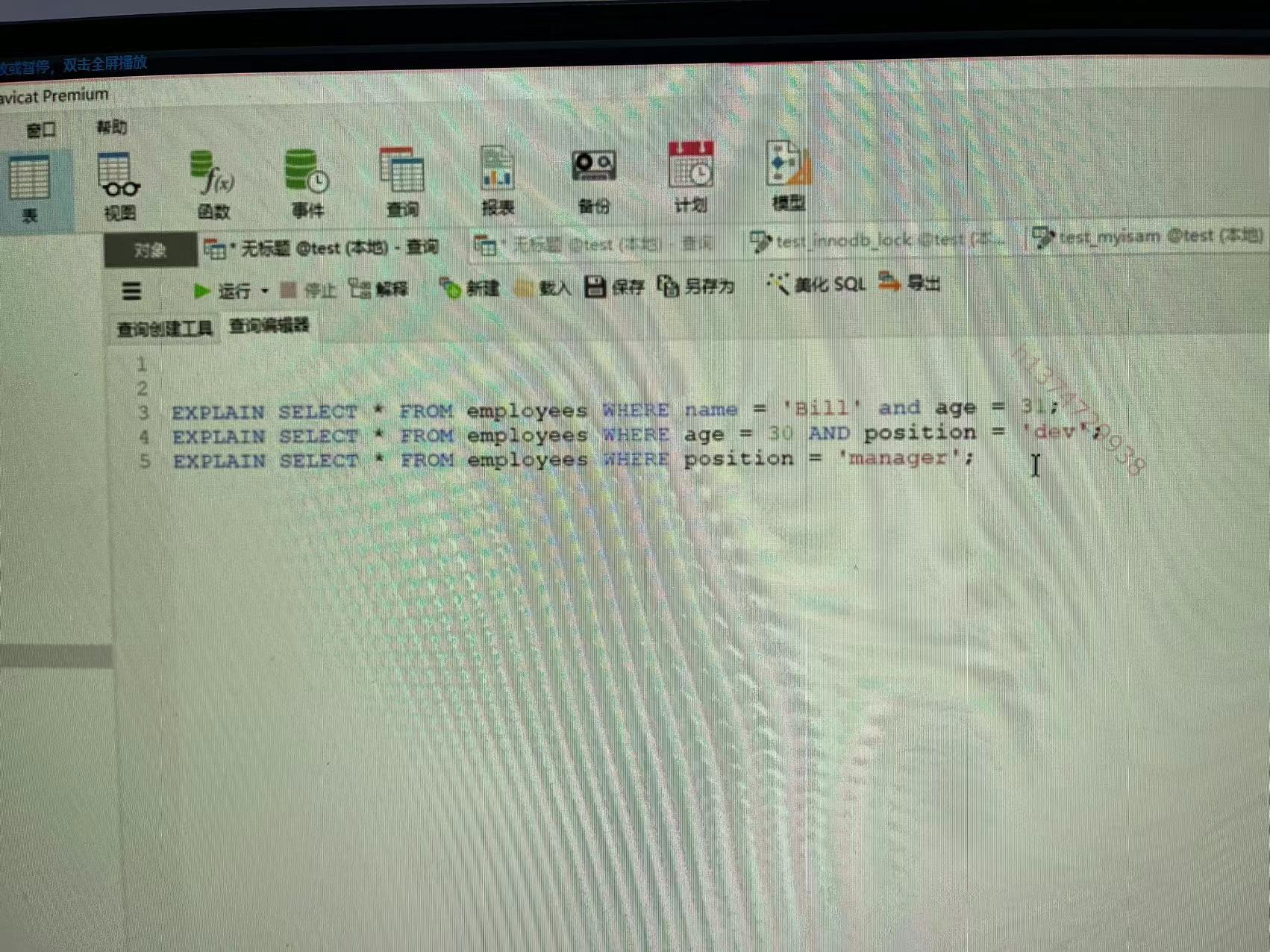
上边两张图片 比如联合索引为 name age position 那么第二张图片分别为三次查询。判断谁走索引谁不走?
第一条肯定是走的 因为联合索引为 name age position 构建索引树的时候首先会先根据name进行排序 如果name相同就会根据age排序 如果name和age都一样根据 position排序
第一条sql走索引 因为 先去找name字段对应的Bill的数据 可以找到一个区间 因为已经根据name排好序了 再给这个区间找到 age为3的,age也排序了所以也很好找
第二条不走索引 因为第一张图也可以看到 他们先通过name排序的 如果有好几个人age一样但是name不一样他们首先再通过name排序的时候就会被打散 会分布到不同区间 所以需要全表找
第三条和第二条同理 不走索引
5. 面试问题
a. 聚集索引和非聚集索引那个快?
聚集索引快,因为聚集索引不需要进行回表操作
b. 为什么db引擎推荐使用自增作为主键
因为索引本身就是需要进行排序的 如果不使用自增作为主键 那么再构建树的时候就会频繁的改变树的结构 如果使用自增作为主键 再插入数据的时候直接往后面新增就完全可以了,即使改变结构也是新增那一块小地方需要该
c. 索引使用uuid和int自增那个比较好?为什么?
使用int自增比较好,因为int不浪费磁盘空间 一个根节点和叶子节点只能存储16kb大小 如果索引越小就代表可以平铺下来更多的节点数据
d. db索引如果没有主键那么数据是怎么做成树的
首先会找到所有列中值不重复的一列作为主键 如果发现没有不重复的列 那么就会自己生成一个rowId作为主键
自学笔记,各位大佬如果有错的地方欢迎指正。谢谢
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Springboot日志框架logback与log4j2
- js基础:函数、对象、WebAPIs-DOM
- 59、resnet50 权值和参数保存
- 力扣103. 二叉树的锯齿形层序遍历
- IP地址证书的申请场景与流程详解
- vue:使用【3.0】:拖拽数据
- 扎心!圣诞礼物含“毒”量极高,当心惊喜变惊吓!
- QC/PD快充电源产品如何选型
- java获取linux和window序列号
- 【图像分类】【深度学习】【轻量级网络】【Pytorch版本】ShuffleNet_V2模型算法详解