vllm 加速推理通义千问Qwen经验总结
发布时间:2023年12月21日
1. 简介
1.1. 功能说明
vLLM is a fast and easy-to-use library for LLM inference and serving.
vLLM is fast with:
-
- State-of-the-art serving throughput
- Efficient management of attention key and value memory with PagedAttention
- Continuous batching of incoming requests
- Optimized CUDA kernels
vLLM is flexible and easy to use with:
-
- Seamless integration with popular Hugging Face models
- High-throughput serving with various decoding algorithms, including parallel sampling, beam search, and more
- Tensor parallelism support for distributed inference
- Streaming outputs
- OpenAI-compatible API server
1.2. GitHub项目
原始项目:https://github.com/vllm-project/vllm (支持awq量化,暂不支持gptq量化)
拓展项目:https://github.com/chu-tianxiang/vllm-gptq (支持gptq量化)
2. 架构
官方文档:vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention | vLLM Blog
中文文档:vLLM框架原理——PagedAttention - 知乎
2.1. 官方测试性能
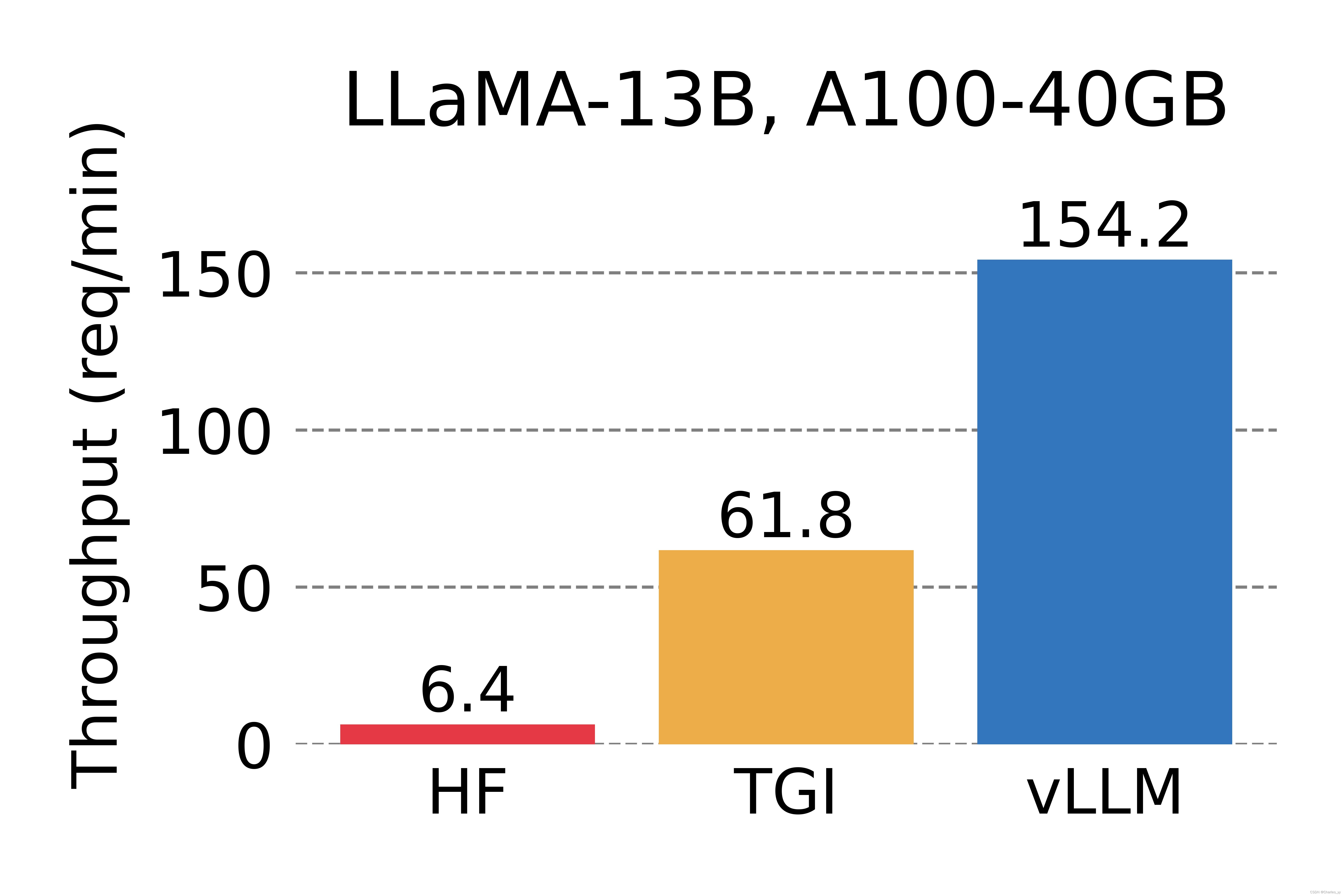
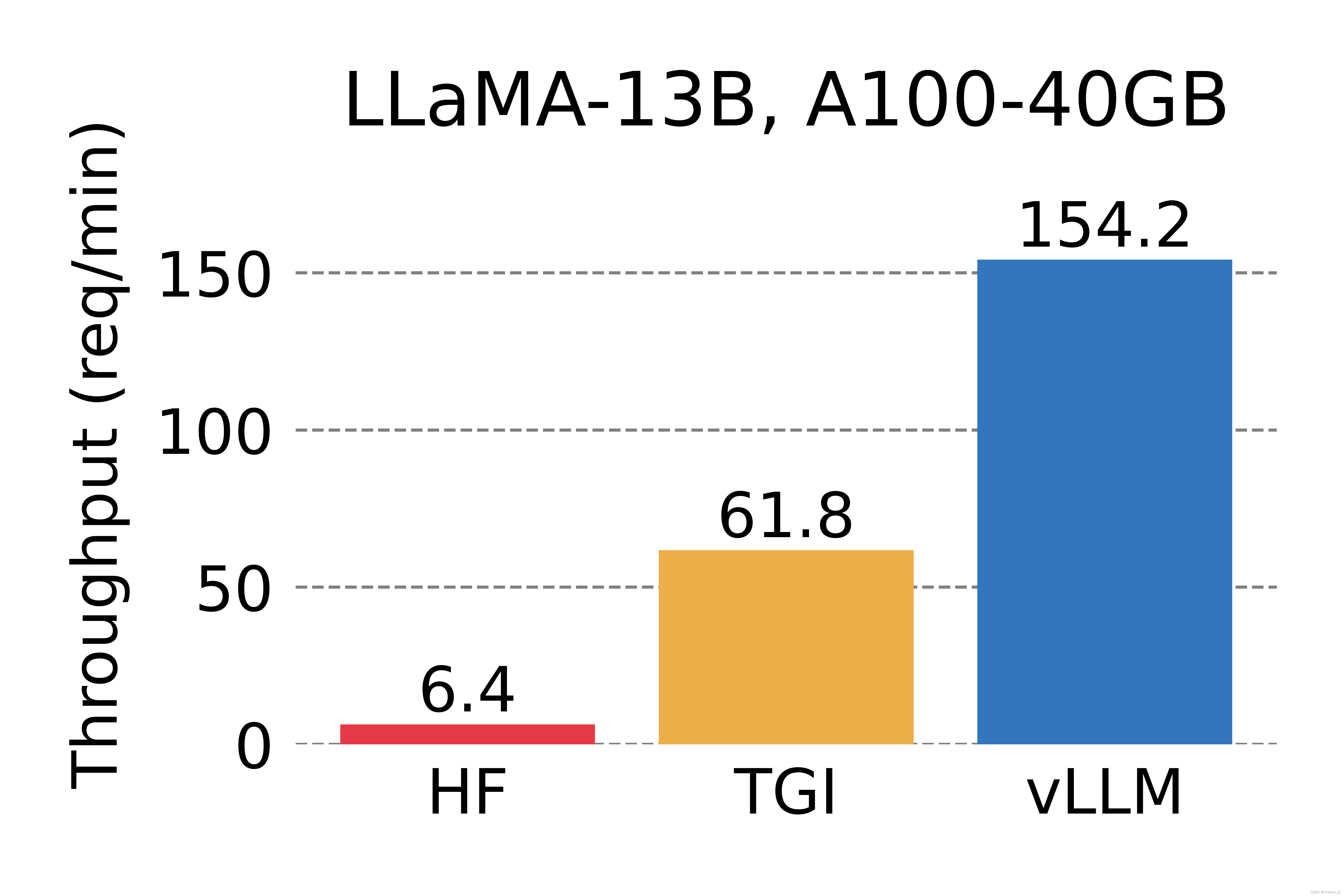
2.2. 主要功能说明
2.2.1. PagedAttention
问题:由于碎片化和过度预留,现有的系统浪费了60%-80%的内存
解决方法:将序列中token按固定长度划分为多个块,并与系统内存进行映射,解决不连续填满问题。
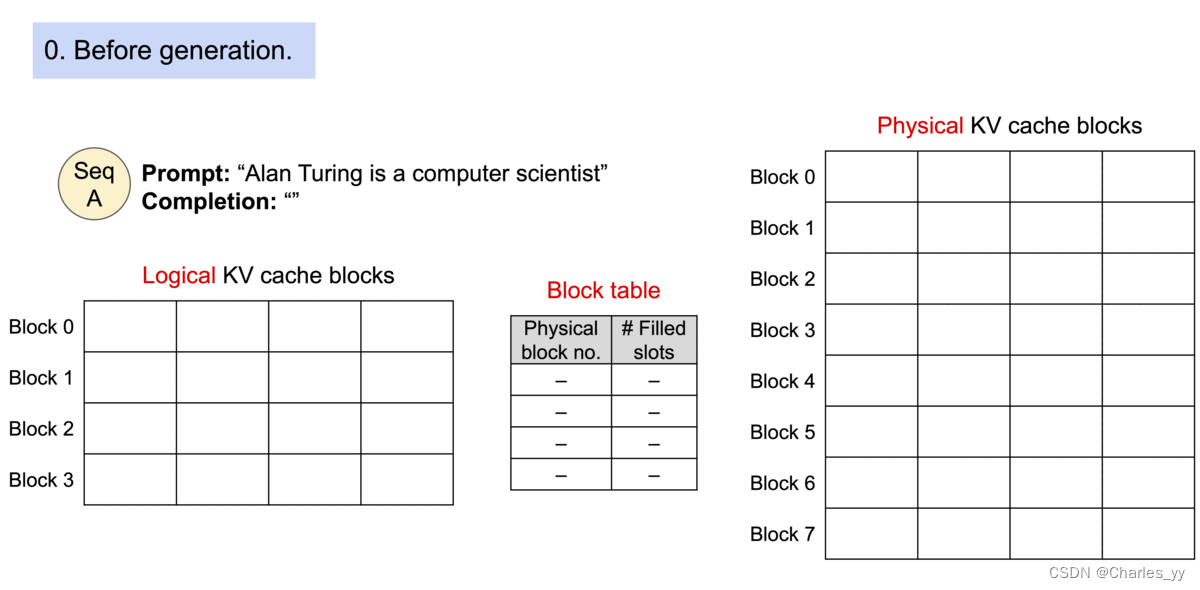
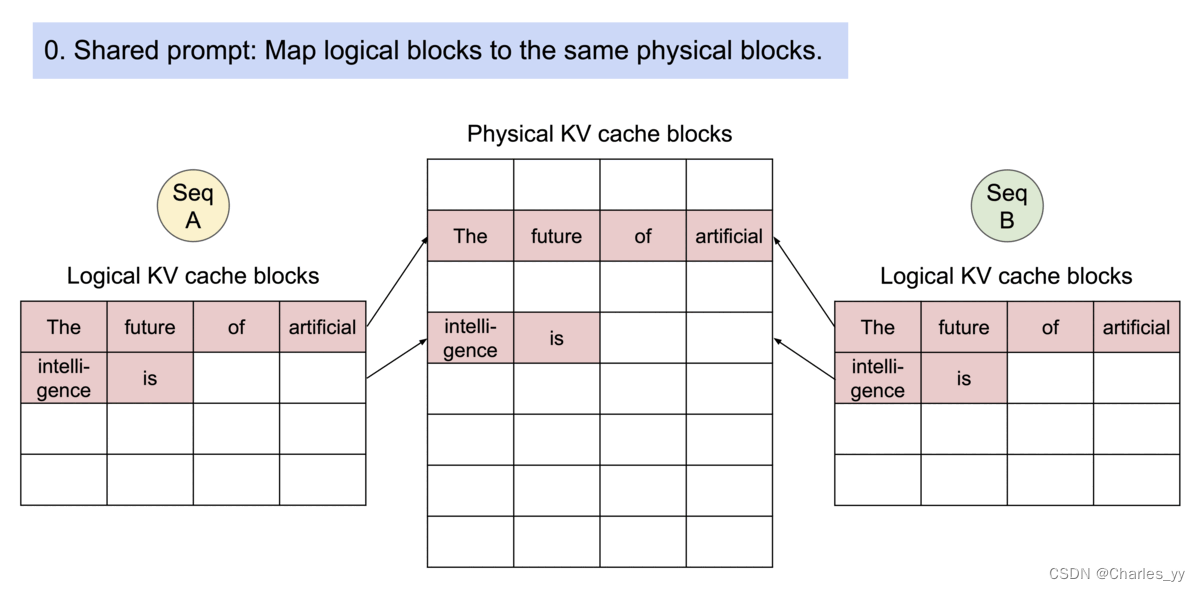
亮点:高效内存利用和共享
高效内存利用示意图:
physical blocks 是横坐标,filled slots是纵坐标
高效内存共享示意图:
3. 实现方案
如果要用gptq量化需要用:https://github.com/chu-tianxiang/vllm-gptq
pip install -e .
3.1. 离线模式
pip install vllm
from vllm import LLM
prompts = ["Hello, my name is", "The capital of France is"] # Sample prompts.
llm = LLM(model="/data/jupyter/LLM/models/Qwen-14B-Chat-Int4-hf",
trust_remote_code=True,
quantization="gptq",
gpu_memory_utilization=0.5,
) # Create an LLM.
outputs = llm.generate(prompts) # Generate texts from the prompts.3.2. 服务模型
# 指定模型名称或模型路径
CUDA_VISIBLE_DEVICES=3 python -m vllm.entrypoints.openai.api_server \
--model /data/jupyter/LLM/models/Qwen-14B-Chat-Int4-hf/ \
--trust-remote-code \
--port 30003 \
--gpu-memory-utilization 0.5 \
--tensor-parallel-size 1 \
--served-model-name Qwen/Qwen-14B-Chat-Int4-hf \
--quantization gptq# curl请求
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen-14B-Chat-Int4-hf",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
文章来源:https://blog.csdn.net/u010899985/article/details/135132223
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!