机器学习 -- 概述
系列文章目录
未完待续……
目录
1、监督学习(Supervised Learning,有导师学习)
1.1.1、二分类(binary classification)
1.1.2、多分类(multi-class classification)
2、无监督学习(Unsupervised Learning,无导师学习)
3、半监督学习(Semi-Supervised Learning)
4、强化学习(Reinforcement Learning)
前言
tips:这里只是总结,不是教程哈。
标题前面加“***”的可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。
一、机器学习定义(是什么)
机器学习(Machine Learning)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能核心,是使计算机具有智能的根本途径。
-- 百度百科
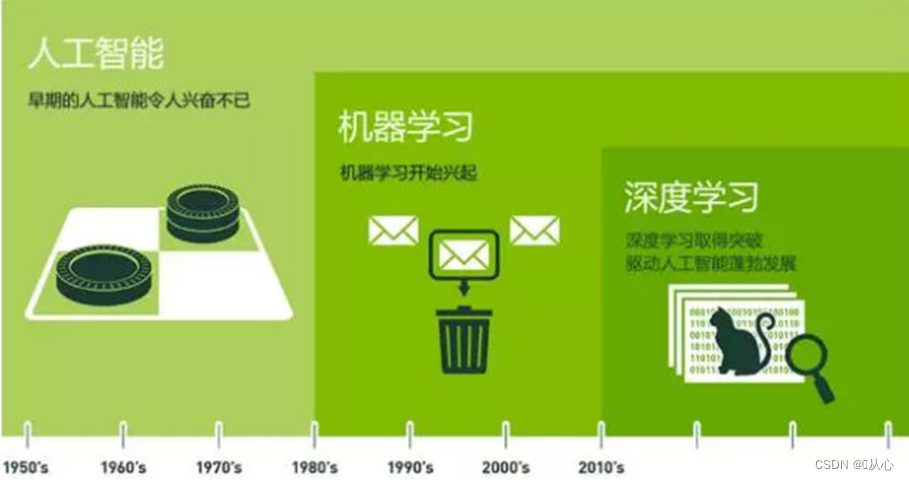
人工智能(AL)
机器学习(ML):机器学习是人工智能的一个子领域,是人工智能的核心。机器学习是从数据通往智能的技术途径,是现代人工智能的本质。
深度学习(DL):深度学习是机器学习的一个子领域,是目前最火的方向。
加入神经网络的关系表示:

二、机器学习的应用(能做什么)

模式识别(Pattern Recognition,PR)== 机器学习:计算机能够比人类更高效地读取大量的数据、学习数据的特征并从中找出数据的模式。这样的任务也被称为“机器学习”或者“模式识别”。统计学习是使用统计方法的一种机器学习。
计算机视觉(Computer Vision,CV):图像识别(人脸识别)、图像检索、物体识别等。
数据挖掘(Data Mining,DM):推荐系统等。
自然语言处理(Natural Language Processing, NLP):文本分类(Text Classification)、语言模型(Language Modeling)、机器翻译(Machine Translation)、问答系统(Question Answering)、语音识别(Speech Recognition)等。
统计学习(Statistical Learning,SL):支持向量机SVM、核方法等。
等……
三、***机器学习的流派

四、机器学习的系统定义与通俗理解
1、系统定义
假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E在T中任务上获得了性能改善,则我们就说关于T和P,该程序对E进行了学习
-- 西瓜书
机器学习 = 任务 + 方法 + 经验 + 性能
任务-T:机器学习要解决的问题? ? ? ? ? ? ? ? ? ??任务是机器学习的研究对象;
方法-A:?? 各种机器学习方法? ? ? ? ? ? ? ? ? ? ? ?? ??方法是机器学习的核心内容;
经验-E:训练模型的数据,实例? ? ? ? ? ? ? ? ??? 经验是机器学习的动力源泉;
性能-P:方法针对任务的性能评估准则? ? ??? 性能是机器学习的检验指标。
2、通俗理解
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。(类比人类)

从数据中自动分析获得模型,并利用模型对未知数据进行预测。
流程:有了历史数据 -->?通过学习算法(训练) -->?得到模型?--> 用新数据进行预测
目的:机器学习=找一个函数(模型=函数)机器学习 = 任务 + 方法 + 经验 + 性
五、机器学习的基本术语
按照流程介绍不同术语。
-- 以下内容从【西瓜书】概括而得
1、有了数据
数据集(D,data set):100个西瓜构成一个数据集。
样本(sample,示例,instance):100个西瓜中的每一个西瓜,就是一个样本。
属性(attribute,特征,feature):西瓜的色泽,根蒂,敲声。
????????属性值(attribute value):西瓜的色泽为青绿色,青绿即为属性值。
样本空间(sample space,属性空间,attribute space、输入空间)(X):属性张成的空间。“色泽”,“根蒂”,“敲声”作为三个坐标轴,则他们张成一个描述西瓜的三维空间
特征向量(feature vector):颜色、大小、敲起来的振幅。一个维度(dimensionality)
2、通过学习算法
2.1、学习(learning,训练,training)
训练数据(training data)
训练样本(training sample,训练示例,training instance、训练例)
训练集(training set)
假设(hypothesis):学得模型对应关于数据的某种潜在的规律(比如敲声清脆的可能是好瓜)。
真相(真实,ground-truth):潜在规律本身(比如敲声清脆的一定是好瓜)。
学习器(learner,模型,model):得到的模型。
2.2、样本结果信息
标记(label):((色泽=青绿;根蒂=蜷缩;敲声=浊响),好瓜),“好瓜”称为“标记”。
样例(example):拥有标记信息的示例称为样例
用(xi,yi)表示第i个样例,其中yi属于Y,是示例xi的标记。
标记空间(label space、输出空间):Y是所有标记的集合。
3、得到模型
有分类、回归、聚类等,具体后面【机器学习的分类】详讲。
4、进行预测
4.1、测试(testing):
测试样本(testing sample,测试示例,testing instance、测试例)
4.2、测试能力:
4.3、测试(testing):
泛化(generalization)能力:适应新样本(未见示例,unseen instance)的能力
--? ? ?独立同分布:假设样本空间中全体样本服从一个未知“分布”(distribution)D,我们获得的每一个样本都是独立地从这个分布上采样获得的,即“独立同分布”(independent and identically distributed,简称,i.i.d.)
5、数据集构成简单理解
结构:特征值(房子面积,房子位置、房子楼层)+目标值(这里是价格)

对于每一行数据我们可以称为样本
有些数据集可以没有目标值,如下

六、机器学习的分类
1、监督学习(Supervised Learning,有导师学习)
从有标记数据中学习模型
1.1、分类(classification) -- 离散
1.1.1、二分类(binary classification)
正类(positive class)、反类(negative class,负类)
Y={-1,+1}/{0,1}? ? ? ? (Y被分成-1,1,或者0,1)
eg:识别猫和狗。

1.1.2、多分类(multi-class classification)
|Y|>2
eg:数字识别
![]()
1.2、回归(regression) -- 连续
预测的是连续值,
Y=R(实数集)
eg:房屋价格预测:

2、无监督学习(Unsupervised Learning,无导师学习)
从无标记数据中学习模型
2.1、聚类
分为若干组,每个组称为一个“簇”(cluster)
eg:

2.2、降维
????????在原始的高维空间中,包含冗余信息和噪声信息,会在实际应用中引入误差,影响准确率;而降维可以提取数据内部的本质结构,减少冗余信息和噪声信息造成的误差,提高应用中的精度。
????????还有异常检测等……
3、半监督学习(Semi-Supervised Learning)
????????半监督学习(Semi-Supervised Learning,SSL)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作,同时,又能够带来比较高的准确性,因此,半监督学习正越来越受到人们的重视。
--? 百度百科
4、强化学习(Reinforcement Learning)
????????实质是自主决策问题,即自动进行决策,并且可以做连续决策。
????????以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏。
七、机器学习的算法
????????有的人总想先知道机器学习的算法有哪些(比如我QwQ)
1、监督学习
1.1、线性回归(Linear Regression)
1.2、逻辑回归(Logistic Regression)
1.3、决策树(Decision Trees)
1.3.1、随机森林(Random Forests)
1.4、深度学习(Deep Learning)算法,如神经网络(Neural Networks)
????????卷积神经网络(CNN)、循环神经网络(RNN)和生成对抗网络(GAN)
1.5、支持向量机(Support Vector Machines)
1.6、朴素贝叶斯(Naive Bayes)
1.7、K近邻算法(K-Nearest Neighbors)
2、无监督学习
2.1、聚类算法
????????将数据样本划分为不同的组或簇,使得同一组内的样本相似度高,不同组之间的相似度较低。
2.1.1、K均值聚类(K-Means Clustering)
2.1.2、层次聚类(Hierarchical Clustering)
2.1.3、DBSCAN
2.2、降维算法
????????将高维数据映射到低维空间,保留数据的主要信息,同时减少数据的维度。
2.2.1、主成分分析(Principal Component Analysis,PCA)
2.2.2、线性判别分析(LDA)
2.2.3、t-SNE
2.3、关联规则挖掘,关联规则学习(Association Rule Learning)
????????从数据集中发现频繁出现的项集或关联规则,用于发现数据项之间的关联性。
2.3.1、Apriori
2.3.2、FP-growth
2.4、异常检测
????????检测数据中的异常或离群点,这些数据与正常数据的行为模式不符。
2.4.1、基于统计的方法
2.4.2、基于聚类的方法
2.4.3、基于密度的方法
2.5、高斯混合模型(Gaussian Mixture Models)
? ? ? ? 暂时先放这吧!
3、半监督学习
????????标签传播算法、半监督支持向量机和深度置信网络等
4、强化学习
????????Q-learning、SARSA、策略梯度和深度强化学习
5、集成学习(多学习器组合)
5.1、随机森林(Random Forests)
5.2、梯度提升树
5.1、AdaBoost
八、机器学习的流程
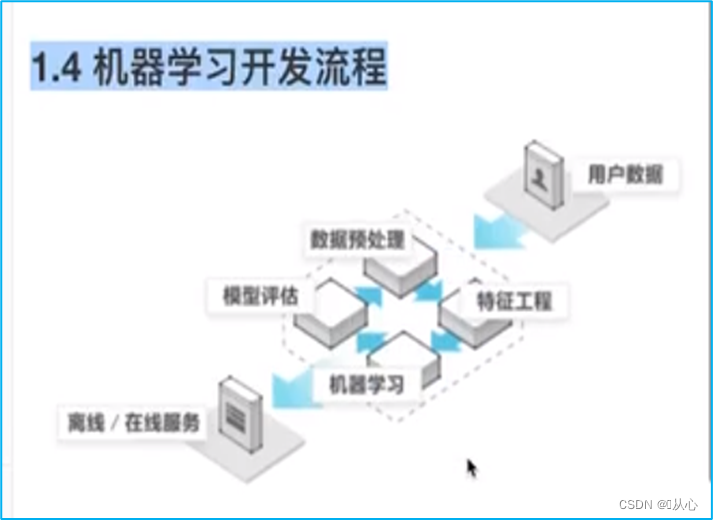
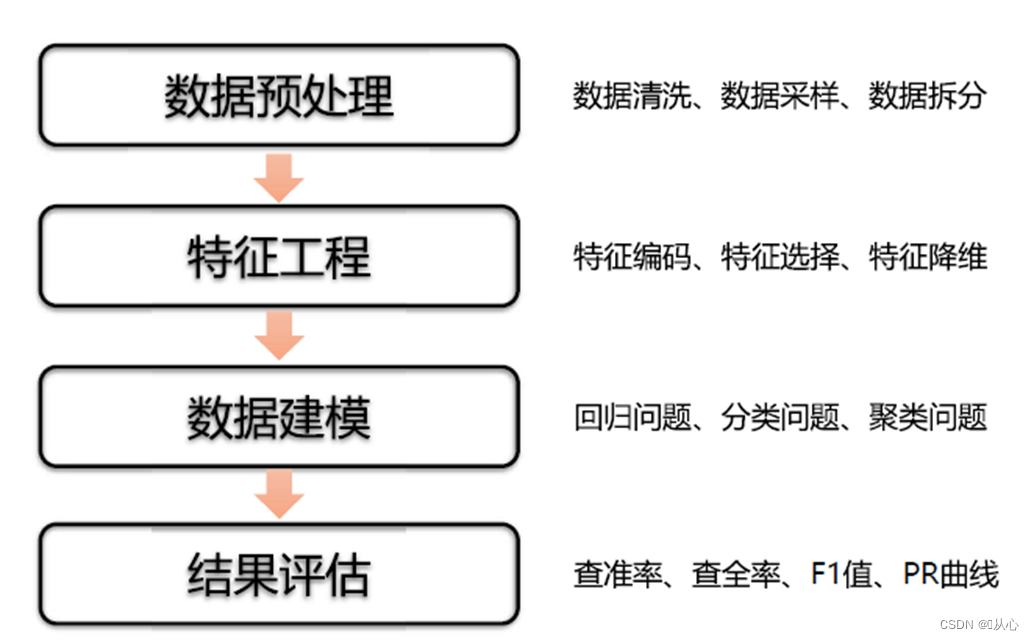
机器学习的数据集划分一般分为两个部分:
训练数据:用于训练,构建模型。一般占70%-80%(数据量越大,取得比例最好越大)
测试数据:用于模型评估,检验模型是否有效。一般占20%-30%
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 33_UI子窗口控件多少会一点之按钮类
- 新手安装MySQL(保姆级教程)
- anaconda自动切换python环境的脚本
- 在Excel中如何打开VBA,这里提供两种方法
- 【Java】子线程获取父线程ThreadLocal
- 网络安全:专科及普通本科的温柔乡
- 安全通信网络
- python里使用multiprocessing.Pool创建的子进程放到后台执行后怎样批量结束
- Spring Cloud Alibaba nacos配置中心
- 芯片禁售 AIGC爆发 元宇宙蓄能 | 且看思腾合力如何探索多元化发展之路