JAVA 学习 面试(五)IO篇
- BIO是阻塞I/O,NIO是非阻塞I/O,AIO是异步I/O。BIO每个连接对应一个线程,NIO多个连接共享少量线程,AIO允许应用程序异步地处理多个操作。
- NIO,通过Selector,只需要一个线程便可以管理多个客户端连接,当客户端数据到了之后,才会为其服务
- AIO是适合高吞吐量的应用程序,异步 IO 基于时间和回调机制实现的:也就是应用操作之后会直接返回,不会阻塞在那里,后台处理完成后,操作系统会通知相应的线程进行后续的操作。但AIO在Java中的支持相对有限,不是所有操作系统都支持。
JAVA BIO

服务端会有个ServerSocket,每一个ServerSocket都有一个与之对应ClientSocket,每一个连接都需要有一个线程来维护
JAVA NIO
1.Java NIO 全称 Java non-blocking IO,是指 JDK 提供的新 API。从 JDK1.4 开始,Java 提供了一系列改进的输入/输出的新特性,被统称为 NIO(即 NewIO),是同步非阻塞的。
Java NIO 的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。

ByteBuffer
缓冲区(ByteBuffer):缓冲区本质上是一个可以读写数据的内存块,可以理解成是一个容器对象(含数组),该对象提供了一组方法,可以更轻松地使用内存块,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况。ByteBuffer的指针有postion

Channel
NIO 的通道类似于流,主要的区别是:通道可以同时进行读写,而流只能读或者只能写。通道可以实现异步读写数据。通道可以从缓冲读数据,也可以写数据到缓冲。BIO的流是单向的,NIO的通道是双向的,可以读也可以写操作。
Selector
Java 的 NIO,用非阻塞的 IO 方式。可以用一个线程,处理多个的客户端连接,就会使用到 Selector(选择器)。Selector 能够检测多个注册的通道上是否有事件发生(注意:多个 Channel 以事件的方式可以注册到同一个 Selector),如果有事件发生,便获取事件然后针对每个事件进行相应的处理。
这样就可以只用一个单线程去管理多个通道,也就是管理多个连接和请求。只有在连接/通道真正有读写事件发生时,才会进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程。避免了多线程之间的上下文切换导致的开销。
流
- 流不能通过索引读写数据
- 流中的数据只能顺序读取
// 将流整合起来以便实现更高级的输入和输出操作。如可以把InputStream包装到BufferedInputStream中以实现缓冲,即从磁盘中一次读取一大块数据
InputStream input = new BufferedInputStream(new FileInputStream("c:\data\input-file.txt"));
OutputStream output = new BufferedOutputStream(new FileOutputStream("c:\data\output-file.txt"));
Java的IO流共涉及40多个类,实际上非常规则,都是从以上4个抽象基类派生的
-
java.io.InputStream
int read() 从输入流中读取数据的下一个字节。返回 0 到 255 范围内的 int 字节值。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。 int read(byte[] b) 从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。否则以整数形式返回实际读取的字节数。 int read(byte[] b, int off, int len) 将输入流中最多 len 个数据字节读入 byte 数组。尝试读取 len 个字节,但读取的字节也可能小于该值。 -
java.io.OutputStream
void write(int b) 将指定的字节写入此输出流。write 的常规协定是:向输出流写入一个字节。要写入的字节是参数 b 的八个低位。b 的 24 个高位将被忽略。 即写入0~255范围的。 void write(byte[] b) 将 b.length 个字节从指定的 byte 数组写入此输出流。 void write(byte[] b,int off,int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。 public void flush()throws IOException 刷新此输出流并强制写出所有缓冲的输出字节,调用此方法指示应将这些字节立即写入它们预期的目标。 -
java.io.Reader
int read() 读取单个字符。作为整数读取的字符,范围在 0 到 65535 之间 (0x00-0xffff)(2个字节的Unicode码),如果已到达流的末尾,则返回 -1 int read(char[] cbuf) 将字符读入数组。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符数。 int read(char[] cbuf,int off,int len) 将字符读入数组的某一部分。存到数组cbuf中,从off处开始存储,最多读len个字符。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符数。 -
java.io.Writer
void write(int c) 写入单个字符。要写入的字符包含在给定整数值的 16 个低位中,16 高位被忽略。 即写入0 到 65535 之间的Unicode码。 void write(char[] cbuf) 写入字符数组。 void write(char[] cbuf,int off,int len) 写入字符数组的某一部分。从off开始,写入len个字符 void write(String str) 写入字符串。 void write(String str,int off,int len) 写入字符串的某一部分。 void flush() 刷新该流的缓冲,则立即将它们写入预期目标
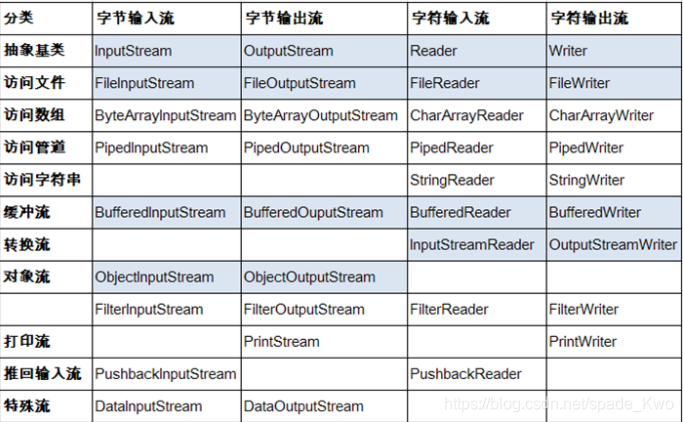
用来将文件转换为二进制字节流或字符流
- FileInputStream(二进制型数据):按顺序地读取文件中的字节,每次读取一个字节
- FileReader(字符型数据):按顺序地读取文件中的字符,每次读取一个字符
- FileOutputStream(二进制型数据):每次写入一个字节,数据按照写入顺序存储在文件当中
- FileWriter(字符型数据):每次写入一个字符,数据按照写入顺序存储在文件当中
//二进制流范例,打开一个文件的输入流,读取到字节数组,再写入另一个文件的输出流
public void test1() {
try {
FileInputStream fileInputStream = new FileInputStream(new File("a.txt"));
FileOutputStream fileOutputStream = new FileOutputStream(new File("b.txt"));
byte []buffer = new byte[128];
while (fileInputStream.read(buffer) != -1) {
fileOutputStream.write(buffer);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
// 字符流范例
public static void main(String[] args) throws IOException {
FileReader fileReader = new FileReader("file.txt");
FileWriter fileWriter = new FileWriter("file2.txt");
//一次拷贝4个字节
char[] chars = new char[1024*1024];
int read;
while ((read = fileReader.read(chars)) != -1) {
fileWriter.write(chars, 0, read);
}
fileWriter.flush();
if (fileReader != null) {
fileReader.close();
}
if (fileWriter != null) {
fileWriter.close();
}
}
Java IO中的管道为运行在同一个JVM中的两个线程提供通信的能力,所以管道也可以作为数据源以及目标媒介。不同的JVM中线程不能利用管道进行通信
//使用管道来完成两个线程间的数据点对点传递
@Test
public void test2() throws IOException {
PipedInputStream pipedInputStream = new PipedInputStream();
PipedOutputStream pipedOutputStream = new PipedOutputStream(pipedInputStream);
new Thread(new Runnable() {
@Override
public void run() {
try {
pipedOutputStream.write("hello input".getBytes());
pipedOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
byte []arr = new byte[128];
while (pipedInputStream.read(arr) != -1) {
System.out.println(Arrays.toString(arr));
}
pipedInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
不仅可以用来做缓存数据的临时存储空间,同时也可以作为数据来源或者写入目的
//字符数组和字节数组在io过程中的作用
public void test4() {
//arr和brr分别作为数据源
char []arr = {'a','c','d'};
CharArrayReader charArrayReader = new CharArrayReader(arr);
byte []brr = {1,2,3,4,5};
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(brr);
}
通过ObjectInputStream转换InputStream为Object
ObjectInputStream input = new ObjectInputStream(new FileInputStream("object.data"));
MyClass object = (MyClass) input.readObject();
input.close();
- BufferedReader:为字符输入流提供缓冲区,可以提高许多IO处理的速度(默认为8KB)
- BufferedInputStream:为原始字节输入流提供缓冲区,可以提高许多IO处理的速度
@Test
public void BufferedStreamTest() throws FileNotFoundException {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
//1.造文件
File srcFile = new File("爱情与友情.jpg");
File destFile = new File("爱情与友情3.jpg");
//2.造流
//2.1 造节点流
FileInputStream fis = new FileInputStream((srcFile));
FileOutputStream fos = new FileOutputStream(destFile);
//2.2 造缓冲流
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
//3.复制的细节:读取、写入
byte[] buffer = new byte[10];
int len;
while((len = bis.read(buffer)) != -1){
bos.write(buffer,0,len);
// bos.flush();//刷新缓冲区
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4.资源关闭
//要求:先关闭外层的流,再关闭内层的流
if(bos != null){
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//说明:关闭外层流的同时,内层流也会自动的进行关闭。关于内层流的关闭,我们可以省略.
// fos.close();
// fis.close();
}
}
通过InputStreamReader、OutputStreamWriter
@Test
public void test1() throws IOException {
FileInputStream fis = new FileInputStream("dbcp.txt");
// InputStreamReader isr = new InputStreamReader(fis);//使用系统默认的字符集
//参数2指明了字符集,具体使用哪个字符集,取决于文件dbcp.txt保存时使用的字符集
InputStreamReader isr = new InputStreamReader(fis,"UTF-8");//使用系统默认的字符集
char[] cbuf = new char[20];
int len;
while((len = isr.read(cbuf)) != -1){
String str = new String(cbuf,0,len);
System.out.print(str);
}
isr.close();
}
System.in和System.out分别代表了系统标准的输入和输出设备
默认输入设备是:键盘,输出设备是:显示器
System.in的类型是InputStream
System.out的类型是PrintStream,其是OutputStream的子类FilterOutputStream 的子类
BufferedReader br = null;
InputStreamReader isr = new InputStreamReader(System.in);
br = new BufferedReader(isr);
while (true) {
System.out.println("请输入字符串:");
String data = br.readLine();
if ("e".equalsIgnoreCase(data) || "exit".equalsIgnoreCase(data)) {
System.out.println("程序结束");
break;
}
字节流和字符流的区别
字节流:处理字节和字节数组或二进制对象(stream命名); 字符流:处理字符、字符数组或字符串(Reader、Writer命名)。
- 1、字节流在操作的时候本身是不会用到缓冲区(内存)的,是与文件本身直接操作的,而字符流在操作的时候是使用到缓冲区的
- 2、字节流在操作文件时,即使不关闭资源(close方法),文件也能输出,但是如果字符流不使用close方法的话,则不会输出任何内容,说明字符流用的是缓冲区,并且可以使用flush方法强制进行刷新缓冲区,这时才能在不close的情况下输出内容
- 字节流用于操作包含ASCII字符的文件;字符流用于读取包含Unicode字符的文件;对于英文字符文件,字节流和字符流都可以用
序列化
- 序列化 (Serialization):将对象的状态信息转换为可以存储或传输的形式的过程
- 反序列化:将字节对象或XML编码格式还原成完全相等的对象
public class 序列化和反序列化 {
?//注意,内部类不能进行序列化,因为它依赖于外部类
@Test
public void test() throws IOException {
A a = new A();
a.i = 1;
a.s = "a";
FileOutputStream fileOutputStream = null;
FileInputStream fileInputStream = null;
try {
//将obj写入文件
fileOutputStream = new FileOutputStream("temp");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(a);
fileOutputStream.close();
//通过文件读取obj
fileInputStream = new FileInputStream("temp");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
A a2 = (A) objectInputStream.readObject();
fileInputStream.close();
System.out.println(a2.i);
System.out.println(a2.s);
//打印结果和序列化之前相同
} catch (IOException e)
{ e.printStackTrace();
} catch (ClassNotFoundException e)
{ e.printStackTrace(); } } }
class A implements Serializable {
int i;
String s;
}
序列化ID
反序列化的前提是序列化ID得相同,Eclipse提供两种产生序列化ID的方法,一种是:属性名+时间戳,另一种是我们一般用1L表示。
// 虽然两个类的路径和功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化
public class A implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
public class A implements Serializable {
private static final long serialVersionUID = 2L;
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
- 序列化引擎会根据对象时候实现了
Serializable接口类,如果没有则抛NotSerializableException异常(这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于Enum、Array和Serializable类型其中的任何一种。),如果实现了则会创建ObjectOutputStream对象,绑定到输出流上 - 扫描对象中
static(因为其为类的状态)、transient关键字的字段,不对其进行序列化,Object对象流不写入,也不读出。 - 如果对象有其他对象的引用则需要递归将引用对象也进行序列化
- 如果要序列化的类有父类,要想同时将在父类中定义过的变量持久化下来,那么父类也应该集成java.io.Serializable接口,父类没实现Serializable接口那么,子类序列化时父类不会序列化。当反序列化变为对象时,因为子类对象创建会先创建父类,所以会调用父类的构造方法。子类对象的属性的值存在,父类对象的属性的值为0或者为null
- ArrayList实现了java.io.Serializable接口,可以对它进行序列化及反序列化。但是其中数组elementData(用来保存列表中的元素的)是transient的,正常不应该被序列化保存下来。
为什么ArrayList要通过重写writeObject 和 readObject 方法来实现序列化呢?
为什么数组elementData是transient的
ArrayList实际上是动态数组,每次在放满以后自动增长设定的长度值,如果数组自动增长长度设为100,而实际只放了一个元素,那就会序列化99个null元素。为了保证在序列化的时候不会将这么多null同时进行序列化,ArrayList把元素数组设置为transient
为什么要重写writeObject 和 readObject 方法
前面说过,为了防止一个包含大量空对象的数组被序列化,为了优化存储,所以,ArrayList使用transient来声明elementData。
但是,作为一个集合,在序列化过程中还必须保证其中的元素可以被持久化下来,所以,通过重写writeObject 和 readObject方法的方式把其中的元素保留下来。
writeObject方法把elementData数组中的元素遍历的保存到输出流(ObjectOutputStream)中。
readObject方法从输入流(ObjectInputStream)中读出对象并保存赋值到elementData数组中。
序列化引擎:Dubbo 框架中的 Hession、JDK 自带的 Serializable、跨语言的 Hessian、ProtoBuf、ProtoStuff
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- centos6 | 更新镜像云
- 软件测试用例经典方法 | 单元测试法案例
- knife4j的3.0.3版本文件上传不显示上传按钮【已解决】
- linux的第一个进程及由父进程生成子进程机制设计缘由
- 开发超爽的nodejs命令行程序
- 编程八股文——C++中线程(thread)原理及使用知识点
- 100GPTS计划-AI学术AcademicRefiner
- 命令执行RCE及其绕过详细总结(17000+字数!)
- QT第一天
- nodejs+vue+ElementUi婚恋交友相亲网站yne25-vscode项目