《低功耗方法学》翻译——第二章:标准低功耗方法

第二章:标准低功耗方法
有许多功率降低方法已经使用了一段时间,并且是成熟的技术。本章介绍了其中一些低功耗设计方法:
- 时钟门控
- 门级功率优化
- 多电压
- 多阈值电压
2.1 时钟门控
芯片中动态功率的相当一部分是在时钟的分布网络中。高达50%,甚至更多的动态功率可能花在时钟缓冲器。这个结果具有直观的意义,因为这些缓冲器在系统中具有最高的切换速率,它们有很多,而且它们通常有一个较高的驱动强度来最小化时钟延迟。此外,即使输入和输出保持不变,接收时钟的触发器也会消耗一些动态功率。
减少这种功率最常见的方法是在不需要它们时关闭时钟。这种方法被称为时钟门控。
现代设计工具支持自动时钟门控:它们可以识别是否可以插入自动时钟门控而不改变逻辑功能的电路。图2-1显示了这一点是如何工作的。
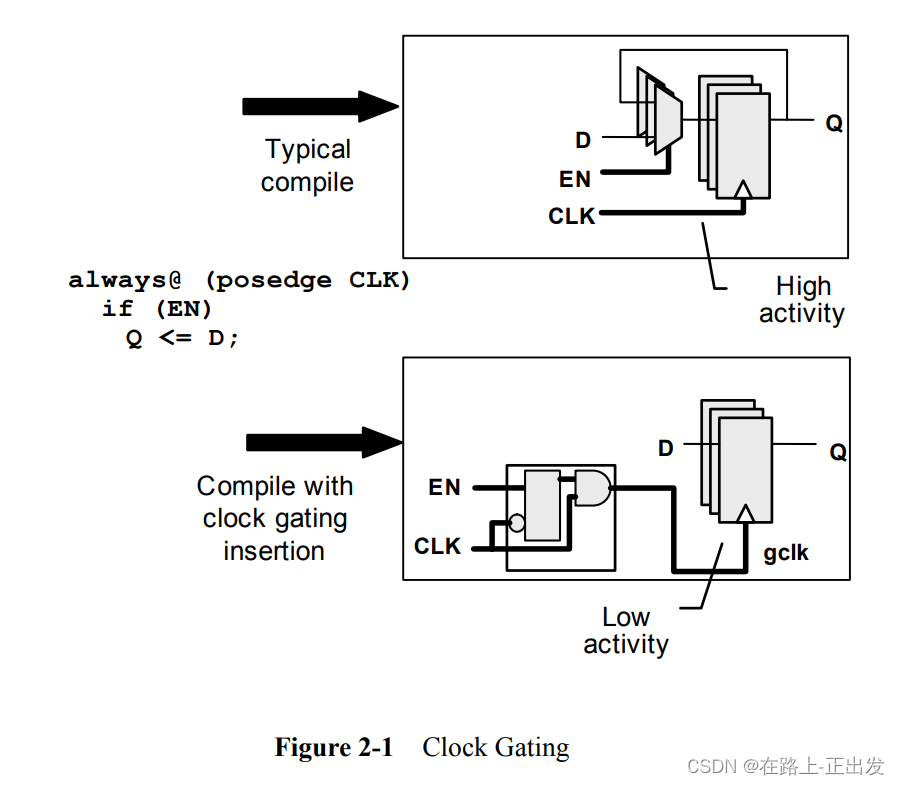
在原本的RTL中,寄存器更新与否依赖于变量EN。通过利用相同的变量对时钟门控也可以达到相同的结果。
如果所涉及的寄存器是单bit,那么就会产生少量的节省。如果它们是,例如,32位寄存器,那么一个时钟门控单元可以将时钟门控到所有32个寄存器(以及它们的时钟树中的任何缓冲区)。这可以节省相当大的功率消耗。
在RTL设计的早期,工程师会在RTL中明确地编码时钟门控电路。这种方法很容易出错——很容易创建一个在门控过程中出现故障的时钟门控电路,产生功能错误。今天,大多数单元库包括特定的被合成工具识别的时钟门控单元。显式时钟门控单元的结合和自动插入使时钟门控成为一种简单而可靠的降压方法。要实现这种风格的时钟门控,不需要更改RTL。
结果
在最近的一篇论文[1]中,Pokhrel报道了一个独特的机会,他的团队最近对比(几乎)相同的芯片,该芯片在有时钟门控和没有时钟门控的情况下实现。作为一个降功率项目,采用与时钟门控相同的技术重新实现了现有的不带时钟门控的180nm芯片。只实现了逻辑上的微小更改(一些小块被删除,并由其他块替换,以实现功能上的小幅净增加)。
Pokhrel报告称,根据操作模式的不同,面积减少了20%,功率节省了34%至43%。(这种节省是在芯片的时钟门控部分实现的;处理器是一个硬宏,而不是时钟门控。当处理器处于IDLE模式时,即处理器关闭时,对整个芯片进行功率测量。)功率测量来自实际的硅芯片。
面积节省是由于单个时钟门控单元代替多个多路复用器的事实。
Pokhre做了一些有趣的观察:
- 经过一些分析和实验,该团队决定只在位宽至少为3的寄存器上使用时钟门控。他们发现,单比特寄存器上的时钟门控并没有功率或面积上的收益效果。
- 大部分的电力节省是由于时钟门控单元放置在时钟路径的早期。大约60%的时钟缓冲区出现在时钟门控单元之后,因此它们在门控期间的活动减少到零。
2.2 门级功率优化

除了时钟门控,综合工具可以做大量的逻辑优化去最小化动态功耗。图2-2所示是两个优化的示例。
图中上面一个示例,与门输出端有相当高的活动性。因为其后接一个或非门,所以可以将该逻辑变为一个与或门和一个非门,这样高活动性的 net 就变到单元内部。原本与门输出的高活动性节点,现在驱动了更小的电容负载,降低了动态功耗。
图中下面一个示例,一个与门已经被初始映射,这样一个高活动性 net 被连接到一个高功率输入引脚,一个低活动性 net 被连接到一个低功率引脚。对于多个输入门,不同引脚的输入电容和功率可能有显著的差异。通过重新映射输入,使高活动网连接到低功率输入,优化工具可以降低动态功率。
门级功率优化的其他例子包括改变单元尺寸和插入缓冲器。在改变单元尺寸中,该工具可以选择性地增加和减少关键路径上单元驱动强度以满足时序要求,并且将动态功率降低到最小。
插入缓冲器的方法中,工具可以插入缓冲器,而不是增加门本身的驱动强度。如果在正确的情况下进行,这可能会导致较低的功率。
与时钟门控一样,门电平功率优化也由实现工具执行,并且对RTL设计者是透明的。
2.3 多电压
由于动态功耗正比于电压的平方(),对一些已选择的模块降低电压可以有效地降低动态功率。不巧的是,降低电压也会增加设计中逻辑门的延迟。
考虑图2-3所示示例。缓存RAMS工作在最高电压域,因为他们处于关键时序路径。CPU工作在较高电压域,因为其性能决定了系统性能。但它可以在比缓存略低的电压下运行,并且仍然具有由缓存速度决定的总体CPU子系统性能。芯片的其他部分可以运行在较低电压域而不会影响整体系统性能。通常,芯片的其余部分运行在比CPU更低的频率下。

因此,系统的每个主要部件都在符合满足系统时序的最低电压下运行。这种方法可以大大节省功率开支。
在不同的VDD供应下混合块增加了一些设计的复杂性——我们不仅需要添加IO引脚来供应不同的电源轨道,而且也需要更复杂的供电网络和在块之间运行的信号电平转换器。这些问题将在书的后面进行更详细的描述。
2.4 多阈值逻辑
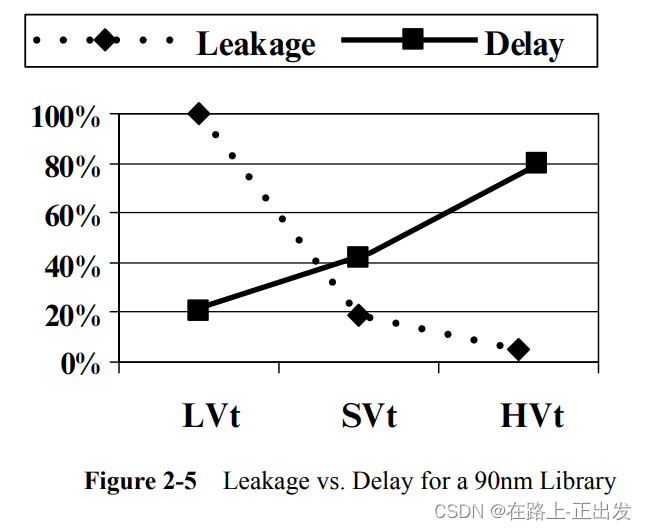
随着制造工艺几何尺寸向130nm、90nm及以下缩减,使用多阈值单元库已经成为一种降低泄露电流的常规方法。
图2-4所示是90nm工艺下,延时和泄露的关系。图2-5所示是多阈值库的泄露和延迟对比曲线。正如之前解释的那样,亚阈值泄露依赖于的e指数幂。延迟对于
的依赖性很弱。
当下很多器件库都会提供两到三个版本:低阈值,标准阈值和高阈值。实现工具可以利用那些库去同时优化时序和功率。

现在在综合过程中使用 “双阈值” 是很常见的。这种方法的目标是通过仅在需要满足时序要求的时候使用速度快、漏电高的低阈值晶体管来最小化它们的总数。这通常包括以主库为目标的初始综合,然后是针对一个(或多个)具有不同阈值的附加库的优化步骤。
通常,在优化功率之前,必须满足最低性能要求。在实践中,这通常意味着首先用高性能、高泄漏库进行综合,然后通过将不在关键路径上的单元替换为性能较低、泄漏较低的等效单元来降低功率压力。
如果最大限度地减少泄漏比达到最低性能更重要,那么这个过程可以反过来进行:我们可以首先瞄准低泄漏库,然后在速度关键区域交换性能更高、高泄漏的等效单元。
看到一个描述不同阈值器件在功率和时序平衡上的建议,截图在此分享一下:

2.5 标准低功耗技术总结
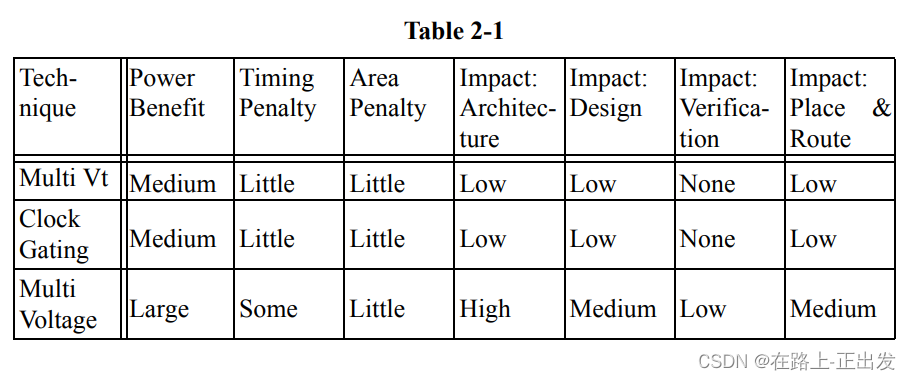
表2-1提供了一个本章所描述技术的 收益权衡 总结表:
?
参考
1. Pokhrel, K. “Physical and Silicon Measures of Low Power Clock Gating Success: An Apple to Apple Case Study”, SNUG, 2007 http://www.snug-universal.org/cgibin/search/search.cgi?San+Jose,+2007.
至此,第二章翻译结束,欢迎评论留言~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 软件验收测试计划、验收测试报告案例模板参考
- 推荐Linux和Ubuntu系统中特别有用的几个指令
- 微服务-sentinel-基本案例,持久化
- 又一大模型技术开源!有道自研RAG引擎QAnything正式开放下载
- Kali中如何新建root用户
- Java学习(十九)--反射
- AttributeError: module ‘openai‘ has no attribute ‘error‘解决方案
- 众和策略股市行情分析:炒股一定要分仓吗?
- VL171 type-c母座DisplayPort1.4与USB3.0切换开关MUX芯片
- Vue3中的`ref`和`reactive使用中遇到的一些坑