第三课:GPT
发布时间:2024年01月20日
文章目录
第三课:GPT
1、学习总结:
GPT出现的原因
未标注的文本数据远多于已标注的文本数据,并且对于不同的下游任务会存在不同的标注方式
GPT的方法原理
半监督学习
- 基于大量未标注的文本数据,训练预训练语言模型
- 使用已标注文本数据,对模型针对某一特定下游任务进行finetune,只更改output layer(线性层)
目前存在的问题
- 自然语言处理的下游任务非常多元,难以有统一的优化目标
- 难以将预训练模型的信息完全传递到finetune的下游任务中
无监督的预训练
优化目标

模型结构
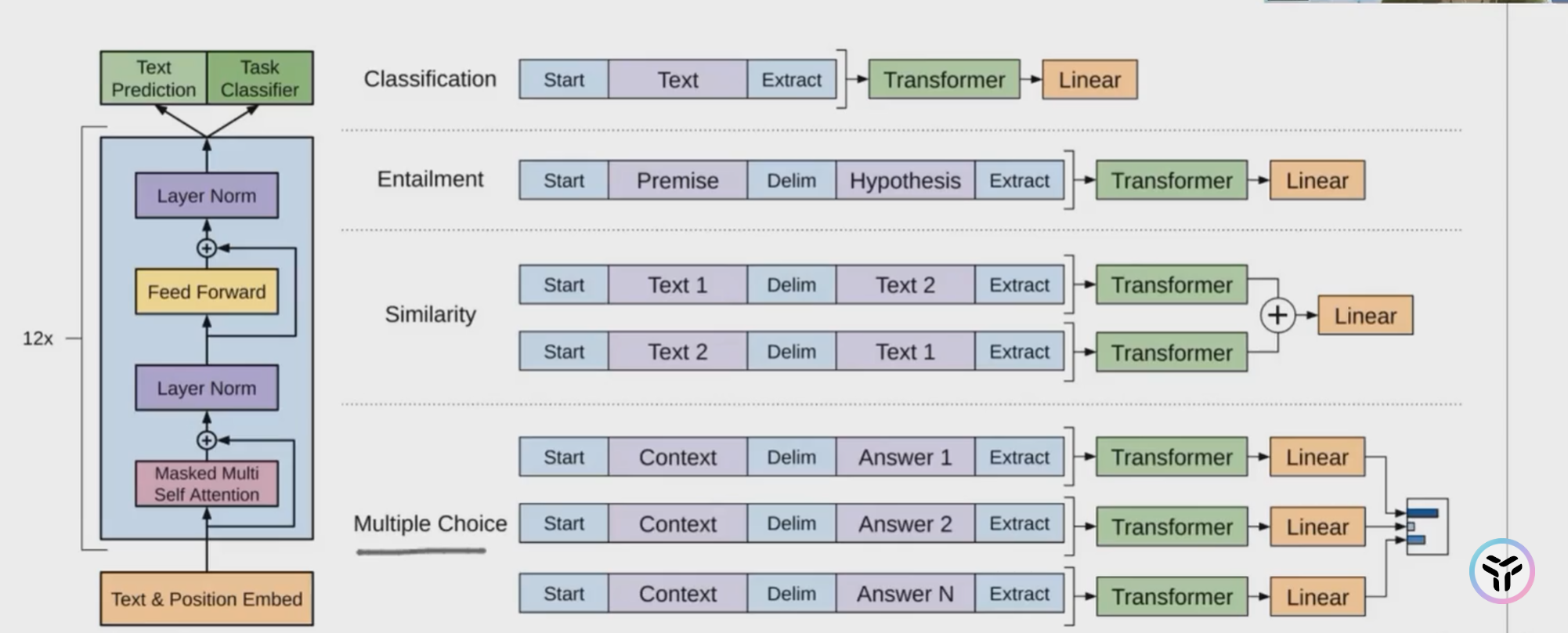
由于训练objective的选择,gpt在模型选择上不应该看见当前token后的信息,故模型应设计为单向网络,即transformer中的decoder结构。
import os
import logging
import numpy as np
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor
from mindspore.common.initializer import initializer, Normal
from mindnlp.models.gpt.gpt_config import GPTConfig
from mindnlp._legacy.nn import Dropout
from mindnlp.abc import PreTrainedModel
from mindnlp.models.utils import Conv1D, prune_conv1d_layer, find_pruneable_heads_and_indices
from mindnlp.models.utils import SequenceSummary
from mindnlp.models.activations import ACT2FN
from mindnlp import GPTConfig
# Feed-Forward 实现
class MLP(nn.Cell):
r"""
GPT MLP
"""
def __init__(self, n_state, config):
super().__init__()
n_embd = config.n_embd
self.c_fc = Conv1D(n_state, n_embd)
self.c_proj = Conv1D(n_embd, n_state)
self.act = ACT2FN[config.afn]
self.dropout = Dropout(p=config.resid_pdrop)
def construct(self, x):
h = self.act(self.c_fc(x))
h2 = self.c_proj(h)
return self.dropout(h2)
# Multi-head attention 实现
class Attention(nn.Cell):
r"""
GPT Attention
"""
def __init__(self, nx, n_positions, config, scale=False):
super().__init__()
n_state = nx
if n_state % config.n_head != 0:
raise ValueError(f"Attention n_state shape: {n_state} must be divisible by config.n_head {config.n_head}")
self.bias = Tensor(np.tril(np.ones((n_positions, n_positions))), mindspore.float32).view(1, 1, n_positions, n_positions)
self.n_head = config.n_head
self.split_size = n_state
self.scale = scale
self.c_attn = Conv1D(n_state * 3, n_state)
self.c_attn = Conv1D(n_state * 3, n_state)
self.c_proj = Conv1D(n_state, n_state)
self.attn_dropout = Dropout(p=config.attn_pdrop)
self.resid_dropout = Dropout(p=config.resid_pdrop)
self.pruned_heads = set()
self.output_attentions = config.output_attentions
def prune_heads(self, heads):
"""
Prunes heads of the model.
"""
if len(heads) == 0:
return
head_size = self.split_size//self.n_head
heads, index = find_pruneable_heads_and_indices(heads, self.n_head, head_size, self.pruned_heads)
index_attn = ops.cat([index, index + self.split_size, index + (2 * self.split_size)])
self.c_attn = prune_conv1d_layer(self.c_attn, index_attn, axis=1)
self.c_proj = prune_conv1d_layer(self.c_proj, index, axis=0)
self.split_size = (self.split_size // self.n_head) * (self.n_head - len(heads))
self.n_head = self.n_head - len(heads)
self.pruned_heads = self.pruned_heads.union(heads)
def _attn(self, q, k, v, attention_mask=None, head_mask=None):
w = ops.matmul(q, k)
if self.scale:
w = w / ops.sqrt(ops.scalar_to_tensor(v.shape[-1]))
b = self.bias[:, :, : w.shape[-2], : w.shape[-1]]
w = w * b + -1e9 * (1 - b)
if attention_mask is not None:
w = w + attention_mask
w = ops.softmax(w)
w = self.attn_dropout(w)
if head_mask is not None:
w = w * head_mask
outputs = (ops.matmul(w, v),)
if self.output_attentions:
outputs += (w,)
return outputs
def merge_heads(self, x):
"""merge heads"""
x = x.transpose(0, 2, 1, 3)
new_x_shape = x.shape[:-2] + (x.shape[-2] * x.shape[-1],)
return x.view(new_x_shape)
def split_heads(self, x, k=False):
"""split heads"""
new_x_shape = x.shape[:-1] + (self.n_head, x.shape[-1] // self.n_head)
x = x.view(new_x_shape)
if k:
return x.transpose(0, 2, 3, 1)
return x.transpose(0, 2, 1, 3)
def construct(self, x, attention_mask=None, head_mask=None):
x = self.c_attn(x)
query, key, value = ops.split(x, self.split_size, axis=2)
query = self.split_heads(query)
key = self.split_heads(key, k=True)
value = self.split_heads(value)
attn_outputs = self._attn(query, key, value, attention_mask, head_mask)
a = attn_outputs[0]
a = self.merge_heads(a)
a = self.c_proj(a)
a = self.resid_dropout(a)
outputs = (a,) + attn_outputs[1:]
return outputs
class Block(nn.Cell):
r"""
GPT Block
"""
def __init__(self, n_positions, config, scale=False):
super().__init__()
nx = config.n_embd
self.attn = Attention(nx, n_positions, config, scale)
self.ln_1 = nn.LayerNorm((nx,), epsilon=config.layer_norm_epsilon)
self.mlp = MLP(4 * nx, config)
self.ln_2 = nn.LayerNorm((nx,), epsilon=config.layer_norm_epsilon)
def construct(self, x, attention_mask=None, head_mask=None):
output_attn = self.attn(
x,
attention_mask=attention_mask,
head_mask=head_mask
)
a = output_attn[0]
n = self.ln_1(x + a)
m = self.mlp(n)
h = self.ln_2(n + m)
outputs = (h,) + output_attn[1:]
return outputs
class GPTPreTrainedModel(PreTrainedModel):
"""BertPretrainedModel"""
convert_torch_to_mindspore = torch_to_mindspore
pretrained_model_archive_map = PRETRAINED_MODEL_ARCHIVE_MAP
config_class = GPTConfig
base_model_prefix = 'transformer'
def _init_weights(self, cell):
"""Initialize the weights"""
if isinstance(cell, nn.Dense):
cell.weight.set_data(initializer(Normal(self.config.initializer_range),
cell.weight.shape, cell.weight.dtype))
if cell.has_bias:
cell.bias.set_data(initializer('zeros', cell.bias.shape, cell.bias.dtype))
elif isinstance(cell, nn.Embedding):
embedding_table = initializer(Normal(self.config.initializer_range),
cell.embedding_table.shape,
cell.embedding_table.dtype)
if cell.padding_idx is not None:
embedding_table[cell.padding_idx] = 0
cell.embedding_table.set_data(embedding_table)
elif isinstance(cell, nn.LayerNorm):
cell.gamma.set_data(initializer('ones', cell.gamma.shape, cell.gamma.dtype))
cell.beta.set_data(initializer('zeros', cell.beta.shape, cell.beta.dtype))
class GPTModel(GPTPreTrainedModel):
"""
The bare GPT transformer model outputting raw hidden-states without any specific head on top
"""
def __init__(self, config):
super().__init__(config)
self.config = config
self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd)
self.positions_embed = nn.Embedding(config.n_positions, config.n_embd)
self.drop = nn.Dropout(p=config.embd_pdrop)
self.h = nn.CellList([Block(config.n_positions, config, scale=True) for _ in range(config.n_layer)])
self.position_ids = ops.arange(config.n_positions)
self.n_layer = self.config.n_layer
self.output_attentions = self.config.output_attentions
self.output_hidden_states = self.config.output_hidden_states
def get_input_embeddings(self):
"""
return the input embeddings layer
"""
return self.tokens_embed
def set_input_embeddings(self, value):
"""
set the input embeddings layer
"""
self.tokens_embed = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
"""
for layer, heads in heads_to_prune.items():
self.h[layer].attn.prune_heads(heads)
def construct(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
):
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
if input_ids is not None:
input_shape = input_ids.shape
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.shape[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if position_ids is None:
position_ids = self.position_ids[None, : input_shape[-1]]
if attention_mask is not None:
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
attention_mask = attention_mask.to(dtype=next(self.parameters()).dtype)
attention_mask = (1.0 - attention_mask) * Tensor(np.finfo(mindspore.dtype_to_nptype(self.dtype)).min,
self.dtype)
head_mask = self.get_head_mask(head_mask, self.n_layer)
if inputs_embeds is None:
inputs_embeds = self.tokens_embed(input_ids)
position_embeds = self.positions_embed(position_ids)
if token_type_ids is not None:
token_type_ids = token_type_ids.view(-1, token_type_ids.shape[-1])
token_type_embeds = self.tokens_embed(token_type_ids)
else:
token_type_embeds = 0
hidden_states = inputs_embeds + position_embeds + token_type_embeds
hidden_states = self.drop(hidden_states)
output_shape = input_shape + (hidden_states.shape[-1],)
all_attentions = ()
all_hidden_states = ()
for i, block in enumerate(self.h):
if self.output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
outputs = block(hidden_states, attention_mask, head_mask[i])
hidden_states = outputs[0]
if self.output_attentions:
all_attentions = all_attentions + (outputs[1],)
hidden_states = hidden_states.view(*output_shape)
if self.output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
return (hidden_states, all_hidden_states, all_attentions)
监督微调
在已经预训练好的GPT上额外加一层线性层
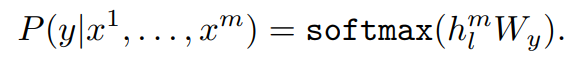
并通过缩小目标与计算结果的误差进行模型优化
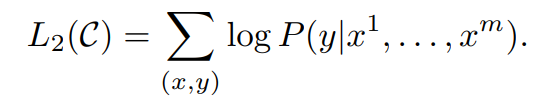
最终为加速模型收敛及提高模型的泛化性,融入pretrain时language modelling的优化目标
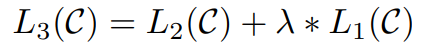
# 文本序列分类任务
class GPTForSequenceClassification(GPTPreTrainedModel):
"""
The Original GPT Model transformer with a sequence classification head on top (linear layer).
GPTForSequenceClassification uses the last token in order to do the classification, as other causal
models (e.g. GPT-2) do. Since it does classification on the last token, it requires to know the position of the
last token. If a `pad_token_id` is defined in the configuration, it finds the last token that is not a padding
token in each row. If no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since
it cannot guess the padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take
the last value in each row of the batch).
"""
def __init__(self, config):
super().__init__(config)
self.config = config
self.num_labels = config.num_labels
self.transformer = GPTModel(config)
self.score = nn.Dense(config.n_embd, self.num_labels, has_bias=False)
self.pad_token_id = self.config.pad_token_id
problem_type = config.problem_type
if problem_type is None:
self.loss = None
else:
if self.num_labels == 1:
self.problem_type = "regression"
self.loss = nn.MSELoss()
elif self.num_labels > 1:
self.problem_type = "single_label_classification"
self.loss = nn.CrossEntropyLoss()
else:
self.problem_type = "multi_label_classification"
self.loss = nn.BCEWithLogitsLoss()
def construct(
self,
input_ids = None,
attention_mask = None,
token_type_ids = None,
position_ids = None,
head_mask = None,
inputs_embeds = None,
labels = None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in
`[0, ...,config.num_labels - 1]`.
If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
transformer_outputs = self.transformer(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
hidden_states = transformer_outputs[0]
logits = self.score(hidden_states)
if input_ids is not None:
batch_size, _ = input_ids.shape[:2]
else:
batch_size, _ = inputs_embeds.shape[:2]
if self.pad_token_id is None and batch_size != 1:
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
if self.pad_token_id is None:
sequence_lengths = -1
else:
if input_ids is not None:
sequence_lengths = ops.ne(input_ids, self.pad_token_id).sum(-1) - 1
else:
sequence_lengths = -1
pooled_logits = logits[:, sequence_lengths]
loss = None
output = (pooled_logits,) + transformer_outputs[1:]
if labels is not None:
if self.num_labels == 1:
loss = self.loss(pooled_logits.squeeze(), labels.squeeze())
elif self.num_labels > 1:
loss = self.loss(pooled_logits.view(-1, self.num_labels), labels.view(-1))
else:
loss = self.loss(pooled_logits, labels)
if loss is not None:
output = (loss,) + output
return output
课程ppt及代码地址
2、学习心得:
? 通过本次学习,熟悉了Mindspore这个国产深度学习框架,也对GPT的基本技术原理有所了解,同时也学会了如何在IMDb数据集上微调GPT完成一个情感分类的任务,比较有成就感!!!另外就是Selina小姐姐讲课的氛围比较轻松,学起来比较快乐!
3、经验分享:
? 在启智openI上的npu跑时记得使用mindspore1.7的镜像,同时安装对应mindnlp的版本,不然可能会因为版本不兼容而报错。另外就是IMDB情感分类任务的微调练习一定要做,这样能比较get到整个微调的全流程是怎样的,后面再去学习llama等模型的微调时就会更加得心应手。
4、课程反馈:
? 本次课程中的代码串讲我觉得是做的最好的地方,没有照着ppt一直念,而是在jupyter lab上把代码和原理结合到一块进行讲解,让学习者对代码的理解更加深入。我觉得内容的最后可以稍微推荐一下与Mindspore大模型相关的套件,让学习者在相关套件上可以开发出更多好玩和有趣的东西!
5、使用MindSpore昇思的体验和反馈:
MindSpore昇思的优点和喜欢的方面:
- 灵活性和可扩展性: MindSpore提供了灵活的编程模型,支持静态计算图和动态计算图。这种设计使得它适用于多种类型的机器学习和深度学习任务,并且具有一定的可扩展性。
- 跨平台支持: MindSpore支持多种硬件平台,包括CPU、GPU和NPU等,这使得它具有在不同设备上运行的能力,并能充分利用各种硬件加速。
- 自动并行和分布式训练: MindSpore提供了自动并行和分布式训练的功能,使得用户可以更轻松地处理大规模数据和模型,并更高效地进行训练。
- 生态系统和社区支持: MindSpore致力于建立开放的生态系统,并鼓励社区贡献,这对于一个开源框架来说非常重要,能够帮助用户更好地学习和解决问题。
一些建议和改进方面:
- 文档和教程的改进: 文档和教程并不是很详细,希望能够提供更多实用的示例、详细的文档和教程,以帮助用户更快速地上手和解决问题。
- 更多的应用场景示例: 提供更多真实场景的示例代码和应用案例,可以帮助用户更好地了解如何在实际项目中应用MindSpore。
6、未来展望:
? 大模型的内容还是很多的,希望自己能坚持打卡,将后面的内容都学习完,并做出一些有趣好玩的东西来!
文章来源:https://blog.csdn.net/weixin_46227276/article/details/135722820
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HarmonyOS开发实战:如何实现一个运动排名榜页面
- 自定义SpringBoot项目启动时控制台图标(如来佛祖,永不宕机)
- electron + selenium报错: Server terminated early with status 1
- 本人最开始使用类GPT做的记录
- AE/PR插件-去朦胧除雾霾增强色彩对比清晰画面调色插件ClearPlus
- Git教程学习:05 撤销操作
- 【MAC】M2 安装mysql
- rabbitmq延迟队列讲解
- 多维时序 | MATLAB实CNN-BiGRU-Mutilhead-Attention卷积网络结合双向门控循环单元网络融合多头注意力机制多变量时间序列预测
- 自己开发的软件中微信登录无法跳转怎么办?