算法02哈希法
算法01之哈希法
1.哈希法理论基础
1.1哈希表
(1)哈希表
哈希表是一种数据结构,用于存储键值对(key-value pairs)。它通过将键(key)通过哈希函数映射到一个特定的索引位置来实现快速的数据访问。这个索引位置在内存中的数组或桶(buckets)中,使得在常数时间复杂度内可以进行查找、插入和删除操作。
想象一下你的家里有一个带有标签的抽屉。每个标签都对应着一个抽屉里的物品。当你需要某样东西时,你不必搜索整个房子,而是直接根据标签找到对应的抽屉,这就像哈希表根据键找到对应的数值一样。这种快速定位的方式使得你能够在瞬间找到你需要的物品,就像哈希表可以在常数时间内找到相应的值。
(2)哈希函数
哈希函数是一种将输入数据映射为固定长度散列值(哈希值)的函数。其主要目的是将任意长度的数据转换为固定长度的输出,通常是一个固定大小的数字或字节序列。
哈希函数具有以下特性:
- 确定性: 相同的输入始终产生相同的哈希值。
- 高效性: 计算速度快,能在合理时间内完成计算。
- 离散性: 输入数据的微小变化应该导致输出哈希值的显著变化。
- 不可逆性: 理论上不可通过哈希值逆向计算出原始输入数据。
常见的哈希函数有MD5、SHA-1、SHA-256等,它们被广泛用于数据加密、数据完整性验证、密码存储等领域。
想象你是一位魔术师,你有一个魔法箱子用来存放各种物品。你的目标是将每样物品放进箱子里,并在箱子的每个格子上放置一个标签。这个标签不仅告诉你物品存放在哪里,还得保证这个标签是独一无二的。你使用一个特殊的变化魔法(哈希函数),这个魔法会将每件物品都转化成一个独特的魔法标签,让你可以快速地找到它们。所以,当你需要取出某样物品时,你只需使用这个特殊魔法,它会让你知道这个物品的魔法标签,而这个标签对应着箱子的一个格子。这就好像哈希函数把数据变成一个特殊的“标签”,让你可以迅速找到存放的位置。而哈希函数的“魔法”在于,无论你放进去什么样的物品,它总是能给你一个独一无二的标签,就像每件物品都有一个特殊的魔法标签一样。
(3)哈希碰撞
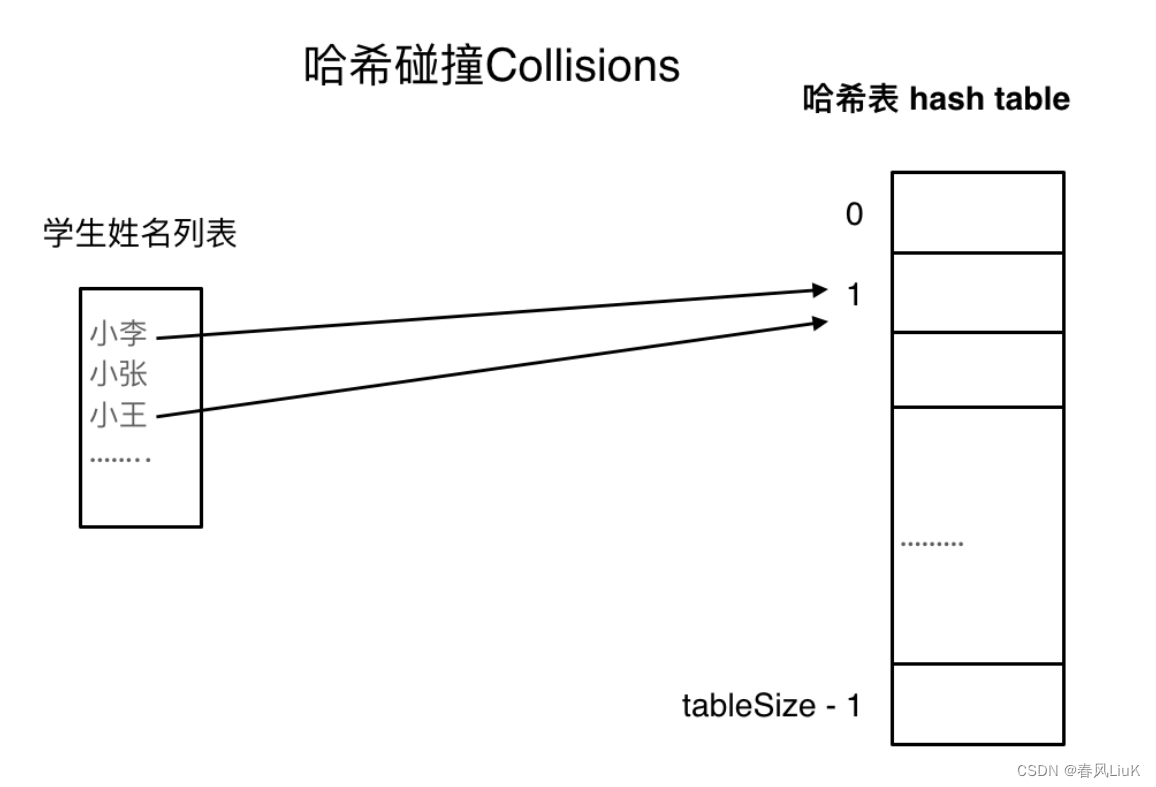
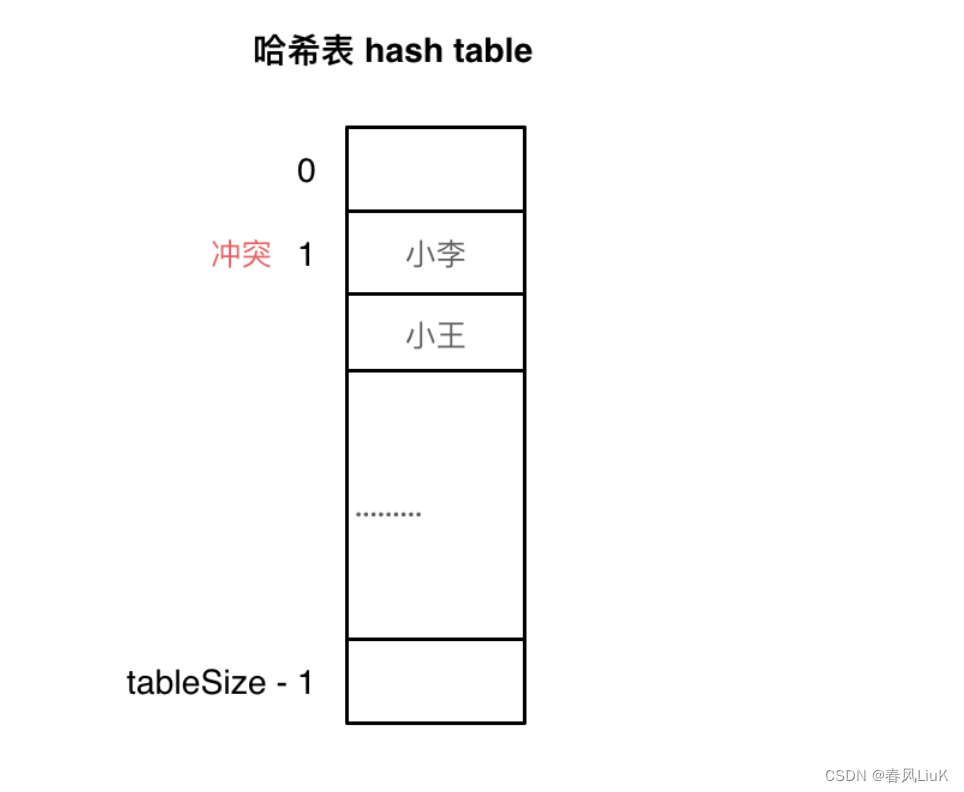
哈希碰撞指的是不同的输入数据经过哈希函数计算后得到了相同的哈希值。在理想情况下,哈希函数应该能够将不同的输入映射到不同的哈希值,但在实际应用中,由于哈希函数将无限的输入空间映射到有限的输出空间,发生哈希碰撞是可能的。
想象一下你是一个魔术师,你的“蓝条”是有限的,当你的蓝条不足时,你的魔术可能会失灵而不准确。在你的魔法失效时,这就可能会发生原来是一个标签对应一个物品的情况而编程一个标签对应两个或两个以上的物品。“蓝条”就相当于是哈希表的存储空间,一个标签对应多个物品就是哈希碰撞。
哈希冲突可以通过以下几种方法解决:
- 开放寻址法(Open Addressing):这种方法在哈希冲突发生时,会寻找哈希表中的下一个可用位置,并尝试将数据存储在那里。这包括线性探测、二次探测、双重哈希等技术,逐个检查直到找到空槽来解决冲突。
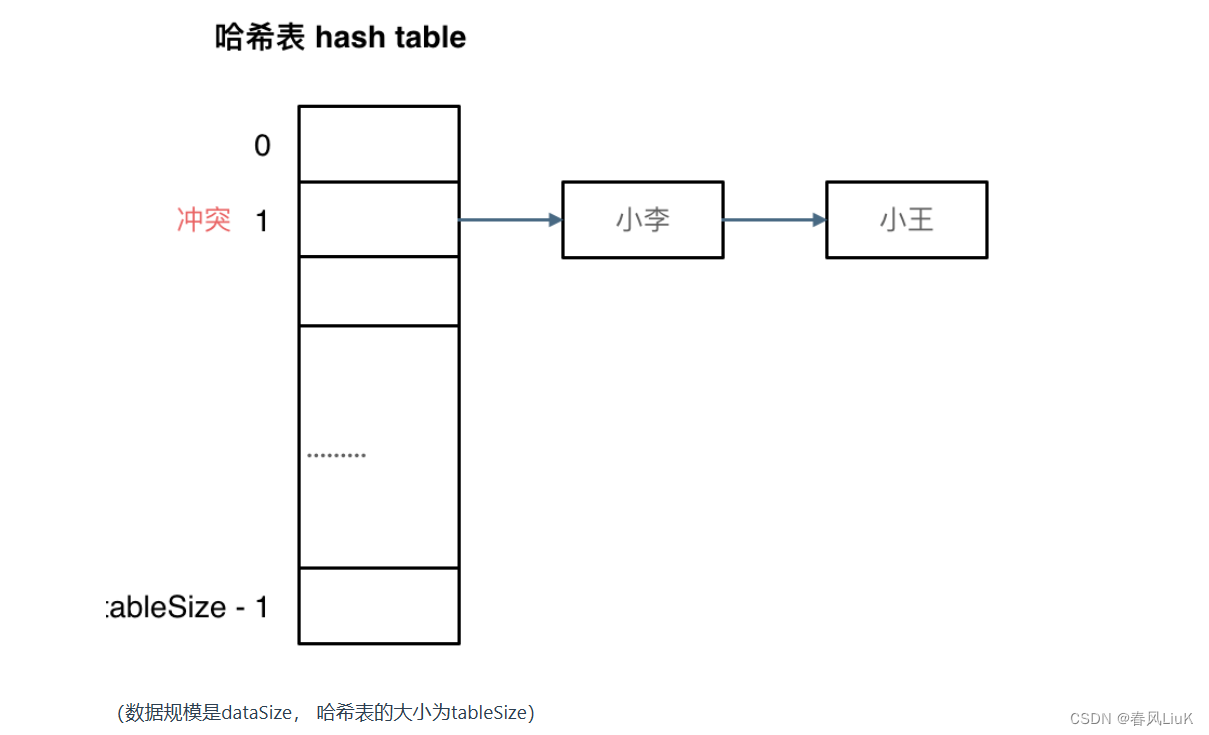
- 链表法(Chaining):哈希表中的每个槽位不只是一个单独的位置,而是一个链表或其他数据结构。当发生哈希冲突时,将新的键值对添加到该位置的链表中。这样,相同哈希值的元素都可以存储在同一个位置上,而不会发生覆盖。
-
再哈希(Rehashing):当哈希表负载因子过高时,可以重新调整哈希表的大小,通常是增大容量,然后重新哈希所有的键值对到新的表中。这可以减少冲突的发生,因为新的更大的表提供了更多的空间来均匀分布键值对。
-
完美哈希函数(Perfect Hashing):这是一种在特定情况下能够完全避免冲突的方法。完美哈希函数能够保证每个键都映射到不同的位置,但在实际中找到完美哈希函数可能比较困难。
选择哪种方法取决于应用的需求和数据特性。链表法在处理冲突时比较灵活,但需要更多的存储空间。开放寻址法则在空间效率上更高,但可能需要更多的探测步骤来解决冲突。再哈希和完美哈希函数则更多地关注于降低冲突的概率。
1.2哈希法基本思想
哈希法是一种基于哈希函数和哈希表的技术,用于将数据映射到一个固定范围的索引位置,以实现快速的查找、插入和删除操作。这个技术的核心是哈希函数,它将数据转换为哈希值,然后将该哈希值映射到哈希表中的特定位置。
1.3哈希法适用场景与最常用的哈希结构
在算法问题中,哈希法通常用于:
- 快速查找: 哈希函数将数据映射为索引,使得在哈希表中能够以常数时间复杂度(O(1))进行查找操作。
- 判断元素是否存在: 通过哈希表的结构,可以快速判断一个元素是否在集合中。
- 去重操作: 将数据存储在哈希表中,可以自动去除重复元素,只保留唯一的元素。
2.LeetCode242:有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
示例 1:
输入: s = “anagram”, t = “nagaram” 输出: true
示例 2:
输入: s = “rat”, t = “car” 输出: false
提示:
1 <= s.length, t.length <= 5 * 104 s 和 t 仅包含小写字母
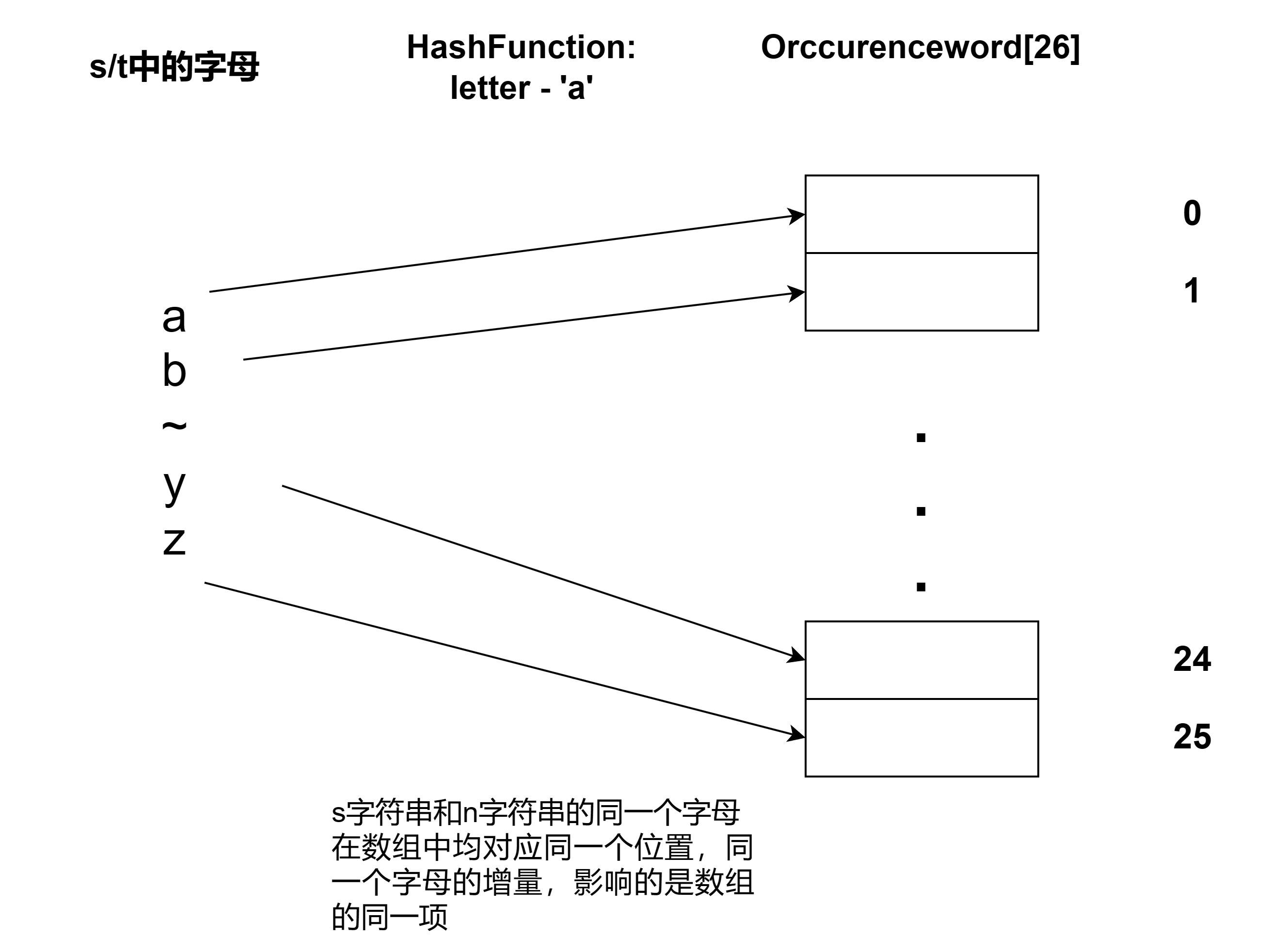
(1)图解本题的哈希内核
(2)cpp代码
//在s中出现的一个字母,我们就增加其在OrccrenceWord中的值
//在t中出现该字母,我们就减少其在orccrenceWord中的值
//如果s和t字符串是有效字母的异位词,OrccurenceWord的每一项最后应该都是0
//因为对一组异位词,s对一个字母提供的正增量刚好等于t对一个字母提供的负增量
class Solution {
public:
bool isAnagram(string s, string t) {
int OrccrenceWord[26] = {0};
for(int i: s)
{
OrccrenceWord[i - 'a']++;
}
for(int i: t)
{
OrccrenceWord[i - 'a']--;
}
for(int i = 0; i < 26; i++)
{
if(OrccrenceWord[i] != 0)
{
return false;
}
}
return true;
}
};
3.LeetCode349:两个数组的交集
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2] 输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4] 输出:[9,4] 解释:[4,9] 也是可通过的
提示:
1 <= nums1.length, nums2.length <= 1000 0 <= nums1[i], nums2[i] <=
1000
(1)图解本题哈希内核
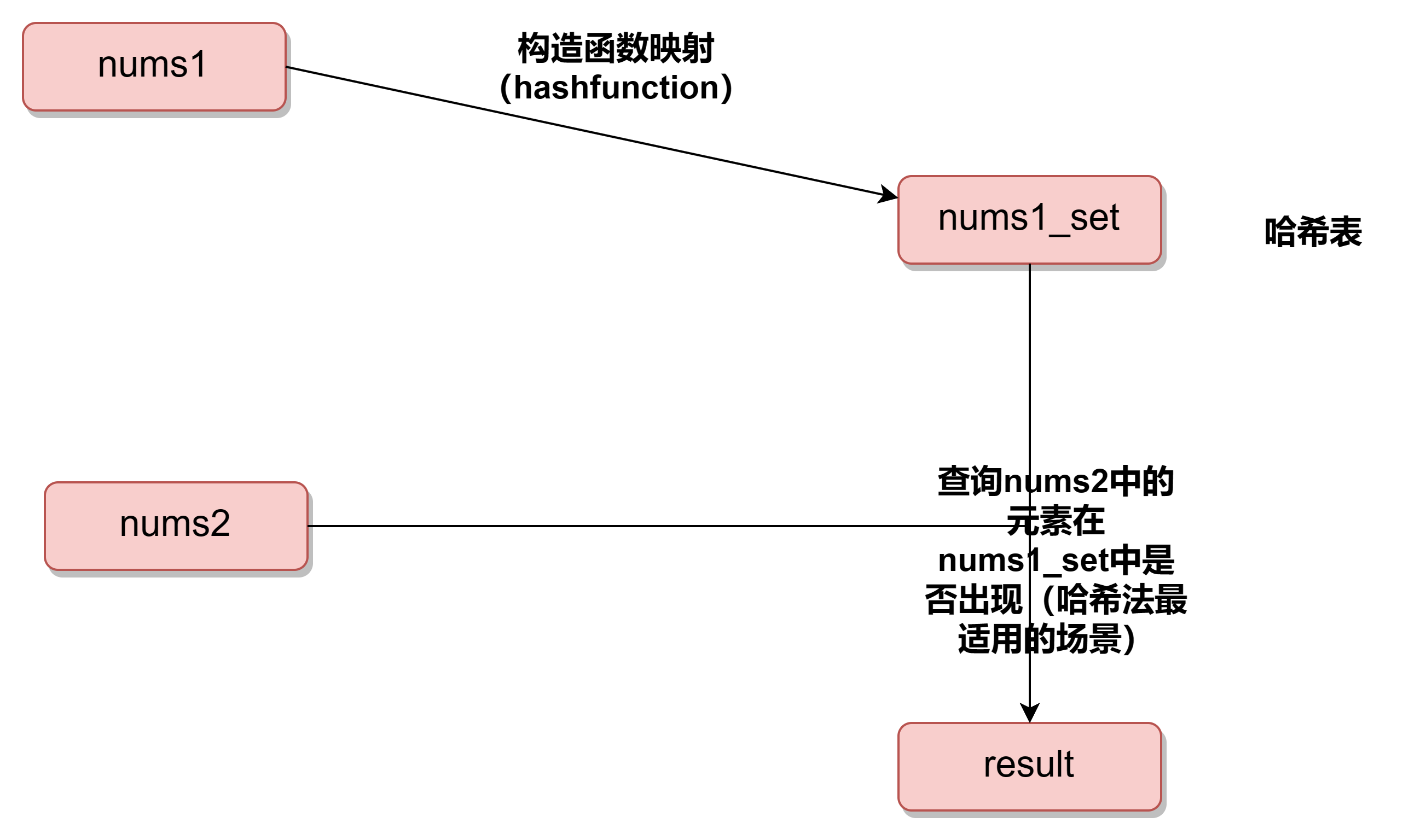
(2)cpp代码
//unordered_set是一种常用的数据结构,适合在原数据规模很大或者原数据十分离散的情况
//unordered_set就像我们数学中的集合一样,满足两个主要特性:1.无需;2.不重复
//result存储结果
//nums1_set利用这个数据结构(类)的构造函数,哈希映射nums1,对齐进行去重
//遍历nums2,如果nums2中的元素在nums1中出现了,就把它插入到结果哈希表(result)中,最后返回结果哈希表
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result;
unordered_set<int> nums1_set(nums1.begin(), nums1.end());
for(int n: nums2)
{
if(nums1_set.find(n) != nums1_set.end())
{
result.insert(n);
}
}
return vector<int>(result.begin(), result.end());
}
};
4.LeetCode202:快乐数
5.LeetCode1:1. 两数之和
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!