Impala-查询Kudu表详解(超详细)
前言
随着大数据时代的到来,数据存储和处理的需求也在不断增长。Apache Kudu和Impala作为大数据处理领域的两个重要工具,为数据的存储和处理提供了强大的支持。Kudu是一个分布式列式存储系统,可以高效地存储和处理大规模数据。而Impala是一个分布式SQL查询引擎,可以快速地查询和分析数据。
本文将介绍如何使用Impala查询Kudu表,以及Impala对Kudu表的DDL和DML支持。通过阅读本文,您将了解如何在Impala中创建、配置和操作Kudu表,从而更好地利用这两个工具来处理和分析大规模数据。
一、使用Impala查询kudu表介绍
1. 使用Impala与Kudu表的好处
-
可以使用Impala查询由Apache Kudu存储的表。这种能力使得方便地访问一个针对不同工作负载进行调优的存储系统,与Impala默认的方式相比。
-
默认情况下,Impala表以各种文件格式在HDFS上存储数据文件。HDFS文件非常适合批量加载(追加操作)和使用全表扫描进行查询,但不支持原地更新或删除操作。
-
Kudu是由Impala使用的一种替代性存储引擎,它既可以进行原地更新(用于混合读/写工作负载),又可以快速扫描(用于数据仓库/分析操作)。在Impala中使用Kudu表可以通过避免额外步骤来隔离和重新组织新到达的数据来简化ETL流程。
-
某些特定的 Impala SQL 语句和子句只适用于 Kudu 表, 如
DELETE、UPDATE、UPSERT和PRIMARY KEY。其他语句和子句, 如LOAD DATA、TRUNCATE TABLE和INSERT OVERWRITE不适用于 KUDU 表。
在需要重点关注扫描性能、数据以小批量连续到达或需要进行更新而不完全替换的表格中,Kudu和Impala的组合效果最佳。基于HDFS的表格可能需要大量开销来替换或重新组织数据文件以适应新到达的数据。Impala可以在Kudu表中执行高效查找和扫描操作,并且还可以高效地执行更新或删除操作。您还可以使用Kudu Java、C++和Python API在Impala之外进行摄取或转换操作,并且随时可以通过Impala查询当前数据。
2. 配置Impala以使用Kudu
要使Impala daemon正确连接到Kudu服务器,需要设置-kudu_master_hosts配置属性。通常,此设置的所需值为kudu_host:7051。在高度可用的Kudu部署中,请指定多个Kudu主机的名称,用逗号分隔。
如果未设置-kudu_master_hosts配置属性,您仍然可以通过在CREATE TABLE语句中指定TBLPROPERTIES('kudu.master_addresses')子句或使用ALTER TABLE语句更改TBLPROPERTIES('kudu.master_addresses')值来关联每个表的适当值。
如果您使用Cloudera Manager,对于每个Impala服务,转到配置选项卡,并在Kudu服务字段中指定要使用的Kudu服务。
3. Kudu副本因子
默认情况下,通过 Impala 创建的 Kudu 表使用表格副本因子为 3。要为 Kudu 表更改副本因子,请在 CREATE TABLE 语句中使用 TBLPROPERTIES 指定副本因子,如下所示,其中 n 是您要使用的副本因子:
TBLPROPERTIES ('kudu.num_tablet_replicas' = 'n')
Kudu 表的副本数量必须为奇数。
在表创建后更改 kudu.num_tablet_replicas 属性将不会产生任何效果。
二、Impala DDL增强功能
可以使用Impala的CREATE TABLE和ALTER TABLE语句来创建和调整Kudu表的特征。
1. Kudu表的主键列
- 主键由一个或多个列组成,其值组合在一起并在查询期间用作查找键。
- 这些列组成的元组必须是唯一的,不能包含任何NULL值,且一旦插入就不能更新。
- 对于Kudu表,所有分区键列都必须来自主键列的集合。
主键具有物理和逻辑方面:
-
在物理方面,它用于将数据值映射到特定表,以便快速检索。由于由主键值组成的主键是唯一的,因此主键列通常是高度选择的。
-
在逻辑方面,唯一性约束允许您避免表中出现重复数据。例如,如果INSERT操作在途中失败,表中可能只存在一些新行。您可以重新运行相同的INSERT操作,并且只有缺少的行才会被添加。或者,如果表中的数据过时,您可以运行UPSERT语句来使数据保持最新,而不会产生现有行的重复副本。
注意:Impala仅允许在Kudu表上使用PRIMARY KEY子句和NOT NULL约束。这些约束由Kudu强制执行。
2. Kudu表特定的列属性
CREATE TABLE语句中的列列表可以包括以下属性,这些属性仅适用于Kudu表:
1. 主键属性
-
Kudu表的主键是一列(或一组列),可以唯一地标识每一行。主键值也是表中值的自然排序依据。每行主键值基于列值的组合。
-
所有主键列的值都必须是非空的,在PRIMARY KEY子句中指定列会隐含地为该列添加NOT NULL属性。
-
主键列必须在CREATE TABLE语句中首先指定。
-
主键概念仅适用于Kudu表。每个Kudu表都需要主键。主键由一个或多个列组成。
-
主键列的值不能通过UPDATE或UPSERT语句更改。包含过多列的主键(超过5或6列)可能会降低写入操作的性能。
对于单一列的主键,您可以将PRIMARY KEY属性直接放在列定义中,或者作为列列表末尾的单独子句指定:
CREATE TABLE pk_inline
(
col1 BIGINT PRIMARY KEY,
col2 STRING,
col3 BOOLEAN
)PARTITION BY HASH(col1)PARTITIONS 2 STORED AS KUDU;
CREATE TABLE pk_at_end
(
col1 BIGINT,
col2 STRING,
col3 BOOLEAN,
PRIMARY KEY(col1)
)PARTITION BY HASH(col1)PARTITIONS 2 STORED AS KUDU;
对于多列主键,必须在列列表的末尾使用一个单独的PRIMARY KEY(c1,c2,…)子句指定主键:
CREATE TABLE pk_multiple_columns
(
col1 BIGINT,
col2 STRING,
col3 BOOLEAN,
PRIMARY KEY(col1,col2)
)PARTITION BY HASH(col2)PARTITIONS 2 STORED AS KUDU;
SHOW CREATE TABLE语句始终将PRIMARY KEY指定表示为列中的单独项:
CREATE TABLE inline_pk_rewritten
(
id BIGINT PRIMARY KEY,
s STRING
)
PARTITION BY HASH(id)PARTITIONS 2 STORED AS KUDU;
执行SHOW CREATE TABLE inline_pk_rewritten;后将显示以下内容:
CREATE TABLE user.inline_pk_rewritten(
id BIGINT NOT NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
s STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
PRIMARY KEY(id)
)
PARTITION BY HASH(id) PARTITIONS 2
STORED AS KUDU
TBLPROPERTIES ('kudu.master_addresses'='host.example.com')
2. NULL | NOT NULL属性
-
对于Kudu表,您可以指定哪些列可以包含空值或不允许包含空值。这个约束为Kudu表提供了额外的层次一致性强制。如果应用程序需要某个字段始终被指定,请在相应的列定义中包含NOT NULL子句,Kudu将阻止具有该列空值的行的插入。
-
对于非Kudu表,Impala允许任何列包含NULL值,因为对于使用外部工具和ETL过程准备的数据文件,在HDFS上强制执行“非空”约束是不现实的。
-
在性能优化过程中,Kudu可以利用不允许空值的知识来跳过对每行输入的某些检查,从而加快查询和连接操作。因此,在适当的情况下指定NOT NULL约束。
-
NULL子句是所有不属于主键的列的默认条件。您可以省略它,或者指定它以澄清您已经故意做出了允许列中存在空值的设计决策。
-
因为主键列不能包含任何NULL值,所以NOT NULL子句不需要为主键列,但您可能仍然指定它以使代码具有自描述性。
3. DEFAULT属性
您可以在Kudu表中为列指定默认值。默认值可以是一个常量表达式,例如,组合字面值、算术和字符串操作。它不能包含对列或非确定性函数调用的引用。
以下示例展示了DEFAULT子句中不同类型的表达式。使用常量值的要求意味着您可以填写占位符值,如NULL、空字符串、0、-1、'N/A’等,但您不能引用函数或列名。
CREATE TABLE default_vals
(
id BIGINT PRIMARY KEY,
name STRING NOT NULL DEFAULT 'unknown',
address STRING DEFAULT upper('no fixed address'),
age INT DEFAULT -1,
earthling BOOLEAN DEFAULT TRUE,
planet_of_origin STRING DEFAULT 'Earth',
optional_col STRING DEFAULT NULL
)PARTITION BY HASH(id) PARTITIONS 2 STORED AS KUDU;
注意: 在设计全新的模式时,请尽量使用NULL作为未知或缺失值的占位符,因为这是数据库系统之间的通用约定。空值可以被高效存储,并且可以使用IS NULL或IS NOT NULL操作轻松检查。
4. ENCODING属性
Kudu表中的每个列可以使用编码,这是一种低开销的压缩形式,可以减少磁盘上的大小,但在查询期间需要额外的CPU周期来重建原始值。通常,高度可压缩的数据受益于减少从磁盘读取数据的I/O。
Impala中的编码关键字如下:
-
AUTO_ENCODING:根据列类型使用默认编码,分别为数值类型列使用BIT_SHUFFLE,字符串类型列使用DICT_ENCODING。
-
PLAIN_ENCODING:保留值的原有二进制格式。
-
RLE:通过包含计数器压缩重复值(按主键顺序排序)。
-
DICT_ENCODING:当不同字符串值的数量较低时,用数字ID替换原始字符串。
-
BIT_SHUFFLE:重新排列值的位,以便有效地压缩基于主键顺序的相同值或仅略有变异的值序列。编码后的数据还使用LZ4进行压缩。
-
PREFIX_ENCODING:压缩字符串值中的常见前缀;主要用于Kudu内部。
以下示例展示了代表编码类型的Impala关键字。
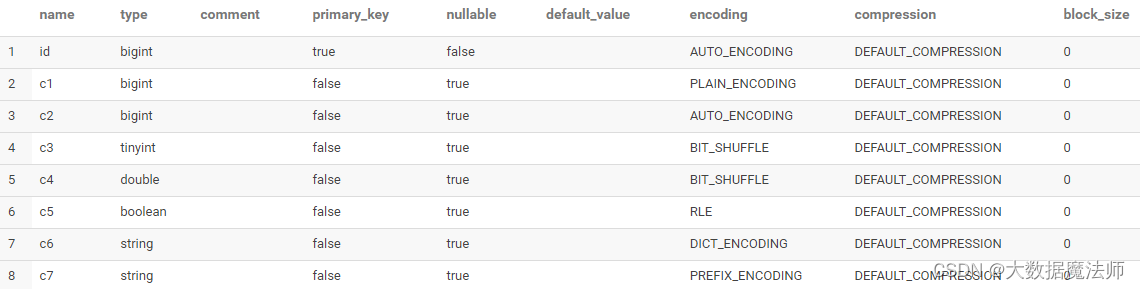
CREATE TABLE various_encodings
(
id BIGINT PRIMARY KEY,
c1 BIGINT ENCODING PLAIN_ENCODING,
c2 BIGINT ENCODING AUTO_ENCODING,
c3 TINYINT ENCODING BIT_SHUFFLE,
c4 DOUBLE ENCODING BIT_SHUFFLE,
c5 BOOLEAN ENCODING RLE,
c6 STRING ENCODING DICT_ENCODING,
c7 STRING ENCODING PREFIX_ENCODING
) PARTITION BY HASH(id) PARTITIONS 2 STORED AS KUDU;
DESCRIBE输出显示了创建表后编码的报告方式,并且省略编码(在此例中为ID列)与指定DEFAULT_ENCODING相同。
DESCRIBE various_encodings;
5. COMPRESSION属性
- 可以为Kudu表中的每个列指定一个压缩算法。
- 此属性在检索值时比ENCODING属性占用更多的CPU开销。因此,主要用于较长字符串列。
- COMPRESSION可选的压缩算法有LZ4、SNAPPY和ZLIB。
注意:
使用BITSHUFFLE编码的列已经使用LZ4进行压缩,因此通常不需要任何额外的COMPRESSION属性。
以下示例展示了针对具有不同分布特性的多个STRING列的设计考虑,包括ENCODING和COMPRESSION属性的选择。
CREATE TABLE blog_posts
(
user_id STRING ENCODING DICT_ENCODING,
post_id BIGINT ENCODING BIT_SHUFFLE,
subject STRING ENCODING PLAIN_ENCODING,
body STRING COMPRESSION LZ4,
spanish_translation STRING COMPRESSION SNAPPY,
esperanto_translation STRING COMPRESSION ZLIB,
PRIMARY KEY (user_id, post_id)
) PARTITION BY HASH(user_id, post_id) PARTITIONS 2 STORED AS KUDU;
6. BLOCK_SIZE属性
尽管Kudu内部不使用HDFS文件,因此不会受到HDFS块大小的影响,但它确实有一个底层的I/O单元,称为块大小。BLOCK_SIZE属性允许您设置任何列的块大小。
注意:块大小属性是一个相对高级的功能。这是一个不受支持的功能,被视为实验性功能。
三、Kudu表分区
Kudu表使用特殊机制在底层表格服务器之间分配数据。尽管我们将这类表称为分区表,但它们与传统的Impala分区表的区别在于CREATE TABLE语句中使用了不同的子句。Kudu表使用PARTITION BY、HASH、RANGE和范围指定子句,而不是HDFS支持表的PARTITIONED BY子句,后者只指定一个列名,并为每个不同的值创建一个新的分区。
注意:
用于Kudu表的Impala DDL语法与早期的Kudu版本不同,后者使用了Impala代码的实验性分支。例如,DISTRIBUTE BY子句现在是PARTITION BY, INTO n BUCKETS子句现在是PARTITIONS n,范围分区语法被重新设计,用涉及比较操作符的更具表现力的语法替换SPLIT ROWS子句。
1. 哈希分区
哈希分区是Kudu表中最简单的分区类型。对于哈希分区的Kudu表,插入的行通过将HASH子句中指定的列的值应用哈希函数,被划分到固定数量的“桶”中。哈希确保具有相似值的行均匀分布在不同的桶中,而不是全部集中在同一个桶中。以这种方式在桶之间分布新行允许插入操作在多个表格服务器上并行工作。将哈希值分离可能会在查询中产生额外开销,因为使用基于范围的谓词的查询可能需要读取多个表格以获取所有相关值。
示例:
- 1百万行,每50个哈希分区约为每个分区2万行。
- 每个分区中的值不是连续的,而是基于哈希函数。
- 行1、99999和123456可能位于相同的分区。
CREATE TABLE million_rows
(
id string primary key,
s string
)
PARTITION BY HASH(id) PARTITIONS 50
STORED AS KUDU;
- 由于ID值是唯一的,我们期望行在表中的分布大致均匀。
INSERT INTO million_rows SELECT * FROM billion_rows ORDER BY id LIMIT 1e6;
注意:
需要注意的是,分区数量的最大值取决于集群中的表格服务器数量,而最小值为2。对于大型表,建议使用大约10个分区每个服务器。
创建Kudu表时,可以根据以下原则设置分区数量:
- 初始分区数量:根据集群中的表格服务器数量和预期负载设置。例如,如果有5个表格服务器,可以考虑使用50个分区。
- 动态调整:根据实际查询性能和资源使用情况,动态调整分区数量。如果发现某些分区的数据量过大或过小,可以适当增加或减少分区。
- 避免过度分区:避免使用过多的分区,以免导致管理复杂性和资源消耗增加。一般来说,每个服务器不超过10个分区是比较合适的。
- 调整分区大小:可以根据数据量和查询需求调整分区大小。较大的分区可以提高查询性能,但可能导致存储空间浪费。相反,较小的分区可以节省存储空间,但查询性能可能受到影响。
总之,在创建Kudu表时,要根据实际需求和集群资源状况合理设置分区数量。在运行过程中,要关注分区使用情况,适时进行调整以保持良好性能。
2. 范围分区
对于范围分区的Kudu表,在表中创建数据值之前必须存在一个适当的范围。如果尝试创建的列值落在指定的范围之外,则任何INSERT、UPDATE或UPSERT语句都会失败。范围检查是在Kudu侧进行的;Impala将指定的范围信息传递给Kudu,并返回任何错误或警告,如果范围无效。(对于DDL语句,无效的范围指定将导致错误,但对于DML语句,只发出警告。)
-
范围分区允许您根据单个值或多个列中的值的范围精确地指定分区。
-
范围分区Kudu表使用一个或多个范围子句,其中包括常量表达式、VALUE或VALUES关键字以及比较运算符的组合。
2.1 哈希分区与范围分区结合使用
Kudu 表还可以使用哈希和范围分区相结合的方式。
示例1:
create table million_rows_one_range
(
id string primary key,
s string
)
partition by hash(id) partitions 10,
range (partition 'a' <= values < '{')
stored as kudu;
-
partition by hash(id) partitions 50: 这表示根据"id"列进行哈希分区,并将数据划分到10个不同的分区中。哈希函数将根据"id"值计算出每条记录所属的特定分区。
最后, -
range (partition ‘a’ <= values < ‘{’): 这表示基于值范围进行额外划分。具体地说,在此示例中,“a”到“{”之间(不包括“{”本身)所有可能取值都将形成一个单独的范围(即一个分区)。
示例2:
create table million_rows_two_ranges
(
id string primary key,
s string
)
partition by hash(id) partitions 10,
range (
partition 'a' <= values < '{',
partition 'A' <= values < '[')
stored as kudu;
示例3:
create table million_rows_three_ranges
(
id string primary key,
s string
)
partition by hash(id) partitions 10,
range (
partition 'a' <= values < '{',
partition 'A' <= values < '[',
partition value = '00000')
stored as kudu;
此语句建立了10个哈希分区(10个桶),建立了三个范围分区。当使用show partitions million_rows_one_range查看分区时,会有10*3=30个分区,相当于每个hash分区都有这三个范围分区。
2.2 范围不连续分区
示例:
partition by range (year) (partition 1885 <= values <= 1889, partition 1893 <= values <= 1897)
partition by range (letter_grade) (partition value = 'A', partition value = 'B',
partition value = 'C', partition value = 'D', partition value = 'F')
2.3 添加范围分区
当添加一个范围时,新范围不能与之前的范围重叠;也就是说,它只能在之前的范围之间填补空隙。
alter table test_scores add range partition value = 'e';
alter table year_ranges add range partition 1890 <= values < 1893;
2.4 删除范围分区
当一个范围被删除时,表(无论表是内部还是外部表)中所有相关的行都将被删除。
alter table test_scores drop range partition value = 'e';
alter table year_ranges drop range partition 1890 <= values < 1893;
2.5 查看分区
查看建表语句:
SHOW CREATE TABLE million_rows_three_ranges
查看所有kudu分区:
show partitions million_rows_three_ranges
或
SHOW TABLE STATS million_rows_three_ranges
查看范围分区:
SHOW RANGE PARTITIONS million_rows_three_ranges
2.6 使用kudu处理 Date,Time,或Timestamp类型数据
创建时间分区表:
create table native_timestamp
(
id bigint,
when_exactly timestamp,
event string,
primary key (id, when_exactly)
)
partition by hash (id) partitions 10,
range (when_exactly)
(
partition '2015-01-01' <= values < '2016-01-01',
partition '2016-01-01' <= values < '2017-01-01',
partition '2017-01-01' <= values < '2018-01-01'
)
stored as kudu;
四、Impala对Kudu表的DML支持
Impala仅支持某些DML语句用于Kudu表。UPDATE和DELETE语句让您在不对大量表数据进行重写的情况下修改Kudu表中的数据。UPSERT语句是一种INSERT和UPDATE的组合,在主键不存在的情况下插入行,并在主键已存在于表中时更新非主键列。
Kudu表的INSERT语句遵循主键列的唯一性和非空要求。
由于Impala和Kudu不支持事务,任何INSERT、UPDATE或DELETE语句的效果都是立即可见的。例如,您不能执行一系列UPDATE语句,并且仅在所有语句完成后才使更改可见。此外,如果DML语句在执行过程中失败,已经插入、删除或更改的行仍然留在表中;没有回滚机制来撤销更改。
特别是,引用要插入的表的INSERT … SELECT语句可能会插入比预期更多的行,因为SELECT部分语句检查到一些新行正在插入,并再次处理它们。
注意:涉及操作HDFS数据文件的LOAD DATA语句不适用于Kudu表。
总结
本文首先介绍了使用Impala查询Kudu表的好处,包括提高数据访问效率、简化ETL流程等。然后,我们学习了如何配置Impala以使用Kudu,包括设置-kudu_master_hosts配置属性。
接下来,我们探讨了Impala DDL增强功能,包括主键列、NULL | NOT NULL属性、DEFAULT属性、ENCODING属性、COMPRESSION属性和BLOCK_SIZE属性。这些特性使得我们可以更好地设计和优化Kudu表。
此外,我们还学习了Kudu表的分区机制,包括哈希分区和范围分区。分区可以提高查询性能,并使数据在多个表格服务器上分布更均匀。
最后,我们探讨了Impala对Kudu表的DML支持,包括INSERT、UPDATE、DELETE和UPSERT语句。这些语句使得我们可以在不重写大量数据的情况下修改Kudu表中的数据。
希望本教程对您有所帮助!如有任何疑问或问题,请随时在评论区留言。感谢阅读!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 系列七、Typora安装 & 配置
- python ffmpeg将mp4文件实时转码为ts,并指定pid等信息,输出到udp
- React Native性能优化指南
- 《代码整洁之道:程序员的职业素养》读后感
- 数据结构排序——选择排序与堆排序(c语言实现)
- EasyRecovery16永久免费的破解激活码
- 图片分类的脚本
- 探索 PyTorch 中的 torch.nn 模块(2)
- 【小程序】如何在微信公众号中申请小程序?
- C++系列-第1章顺序结构-9-字符类型char