分布式共识算法---Raft初探
读Raft论文也有一段时间了,但是自己总是以目前并没有完全掌握为由拖着这篇博客。今天先以目前的理解程度(做了6.824的lab2A和lab2B)对这篇论文做一个初步总结,之后有了更深入的理解之后再进行迭代,关于本文有任何疑问欢迎评论交流。另外需要说明的是本篇博客并没有对Raft算法的背景和基础知识进行全面介绍,所以需要有一定的基础之后进行阅读。
基本概念
三种状态及相互转换关系
Raft算法中每个服务器处于这三种状态中的一个。
- 领导者(Leader):负责处理客户端请求、发送心跳、进行日志同步。正常情况下每个时刻只能有一个领导者。
- 跟随者(Follower):完全被动的处理请求,也就是处理来自领导者的日志同步请求(心跳包含在其中),以及来自候选者的投票请求,服务器大多数情况属于此状态。
- 候选者(Candidate):在特殊情况下候选者通过选举可以成为领导者,它是一个中间状态。
以下是三种状态的转换关系图。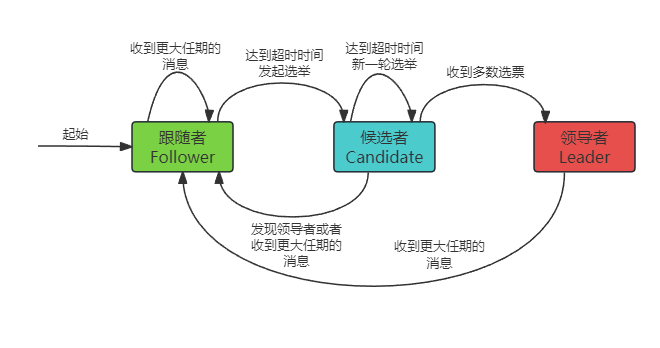
日志形式
日志以下图的形式组织,Raft算法通过索引和任期号唯一的标识一条日志条目,并且只有被存储在超过一半节点的日志条目才能认为该日志为已提交(committed)。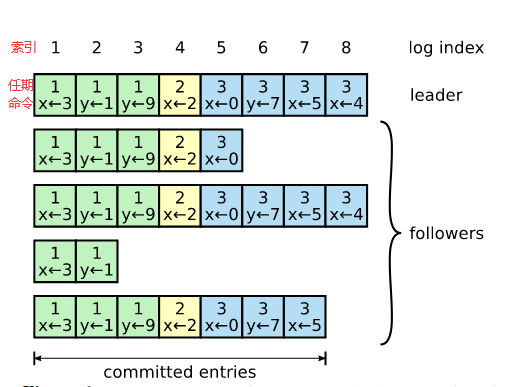
算法总览
论文中的图2给出了Raft算法的整体框架图,下面给出图二的内容。整体分为四部分,第一部分是在代码实现时Raft这个结构体需要定义的属性,第二部分是进行日志同步日志时的RPC定义,第三部分是进行投票选举的RPC的定义,第四部分是每个Server的职责和三种角色的职责。
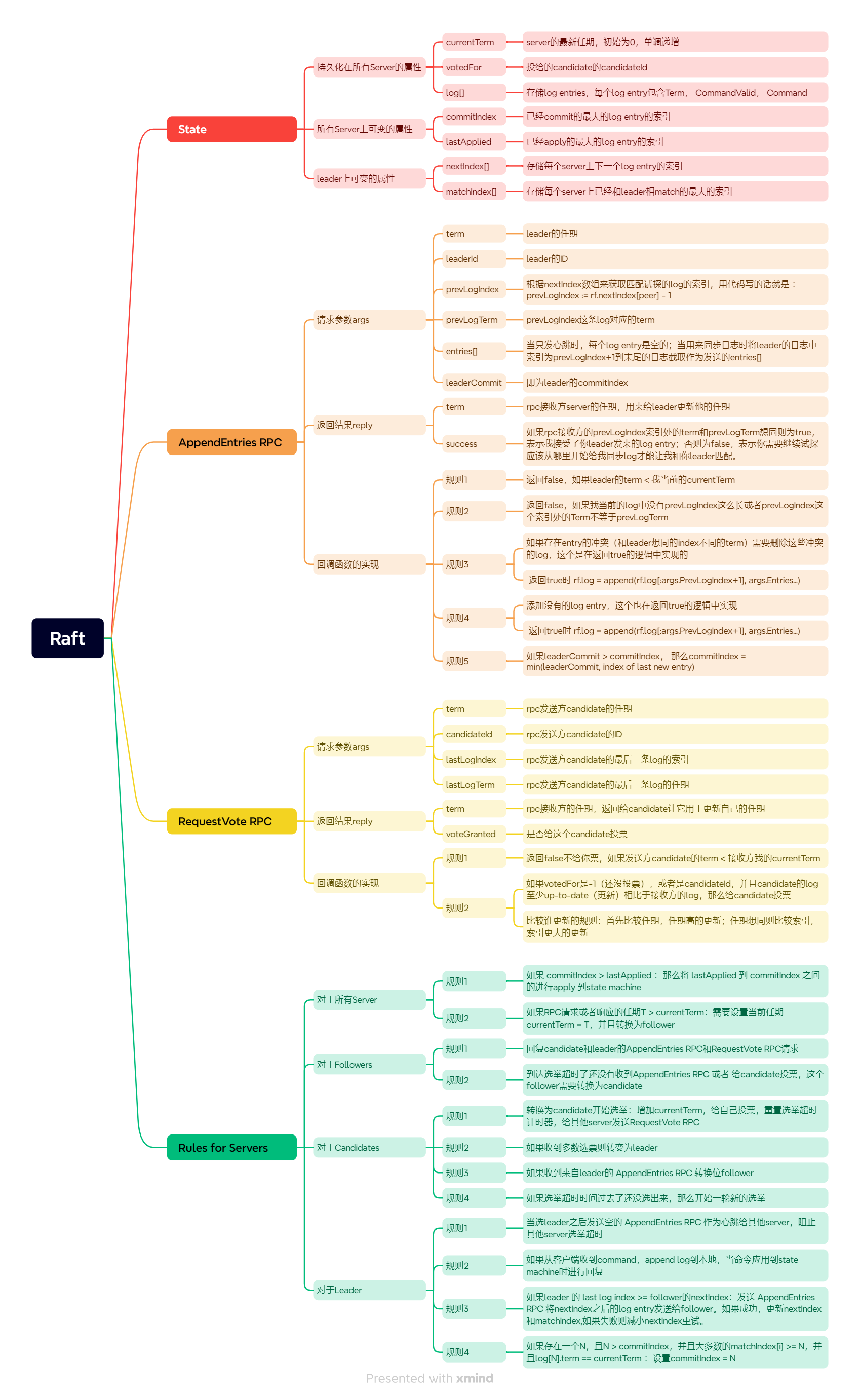
领导者选举
实现流程(理论)
起初Server是Follower,在一段时间内没有收到心跳,或者投出自己的选票则会转换为Candidate。成为Candidate的流程是状态转变为Candidate,当前的任期加一,给自己投一票,然后通过RequestVote RPC向其他节点索要选票。接下来会发生下面三种情况中的一个:(1)如果在超时时间内收到多数选票,则转为Leader并立马发送心跳;(2)如果超时时间过去了没有收到多数选票,则重新开始上面的成为Candidate的流程;(3)如果在选举过程中收到已有领导者的消息则转为Follower。
情况(1):Candidate通过RequestVote rpc向其他节点发送索要选票请求时,会将当前任期,ID,最后一条日志的索引,最后一条日志的任期作为请求参数发送到每个Follower节点。Follower节点在收到请求后会首先进行任期对齐(如果Candidate的任期比我Follower小,则返回给他我的任期,并且不给他投票);然后当我还没给别人投票时,会比较Candidate的最后一条日志与我Follower的最后一条日志谁更新(up-to-date),如果你Candidate更新,那么好我给你我的选票,不然我Follower更新的话就不给你选票。这里谁更新(up-to-date)的规则在下面的 **2.3.1.比较日志新旧规则 **部分给出。
情况(2):这种情况出现的场景就是多个Follower同时成为Candidate,选票被分割,没人当选Leader,重启新的选举流程之后选票又被分割,选不出来Leader,好像进入了死循环,这个情况怎么解决呢?在 **2.3.2.分割选票 **部分给出。
情况(3):这种情况是当Candidate收到一个AppendEntries RPC请求时,并且发送这个请求的Leader的任期大于等于Candidate的任期,则认为当前时刻已有合法的Leader,并且Candidate你需要转换成为Follower。
实现流程(代码)
这里只给出核心的代码实现逻辑。需要定义一个选举计时器,如果当前是Follower或者Candidate并且达到超时时间了,则需要转变为Candidate并开始一轮选举。
func (rf *Raft) electionTicker() {
for !rf.killed() {
rf.mu.Lock()
// rf.isElectionTimeoutLocked() 包含了随机超时时间逻辑
// 关联细节2.3.2
if rf.role != Leader && rf.isElectionTimeoutLocked() {
rf.becomeCandidateLocked() // 转变为Candidate
go rf.startElection(rf.currentTerm) // 开始选举给每个节点发送索要投票请求
}
rf.mu.Unlock()
ms := 50 + (rand.Int63() % 300)
time.Sleep(time.Duration(ms) * time.Millisecond)
}
}
转变为Candidate的实现如下:
func (rf *Raft) becomeCandidateLocked() {
if rf.role == Leader {
return
}
rf.currentTerm++ // 任期加一
rf.role = Candidate // 状态转变为Candidate
rf.votedFor = rf.me // 给自己投一票
rf.resetElectionTimerLocked() // 重置超时计时器
}
开始选举给每个节点发送索要投票请求的实现:
func (rf *Raft) startElection(term int) {
// 统计选票
votes := 0
rf.mu.Lock()
l := len(rf.log)
for peer := 0; peer < len(rf.peers); peer++ {
if peer == rf.me {
votes++
continue
}
args := &RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: l - 1, // 最后一条日志的索引
LastLogTerm: rf.log[l-1].Term, // 最后一条日志的任期
}
go askVoteFromPeer(peer, args)
}
rf.mu.Unlock()
// 定义一个给其他节点发送索要选票并对回复信息进行处理的匿名函数
askVoteFromPeer := func(peer int, args *RequestVoteArgs) {
reply := &RequestVoteReply{}
// 发送索要选票的请求
ok := rf.sendRequestVote(peer, args, reply)
rf.mu.Lock()
defer rf.mu.Unlock()
if !ok {
return
}
// 如果发送到的节点的任期更大,则说明本Candidate没资格当Leader
if reply.Term > rf.currentTerm {
rf.becomeFollowerLocked(reply.Term)
return
}
// 统计选票,获取过半数选票时转变为Leader并发送心跳
if reply.VoteGranted {
votes++
if votes > len(rf.peers)/2 {
rf.becomeLeaderLocked()
go rf.replicationTicker(term)
}
}
}
}
给一个节点发送索要投票请求的函数:
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
}
索要投票的RPC ,或者叫Follower对Candidate的请求的回调函数的定义:
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
reply.VoteGranted = false
// 如果你Candidate的任期比我小,那你该退下去了
if args.Term < rf.currentTerm {
return
}
// 如果你Candidate的任期比我大,那我如果是Candidate就得边Follower
if args.Term > rf.currentTerm {
rf.becomeFollowerLocked(args.Term)
}
if rf.votedFor != -1 {
return
}
// 比较Candidate的最后一条日志与本Follower的最后一条日志谁更新
// 关联细节2.3.1
if rf.isMoreUpToDateLocked(args.LastLogIndex, args.LastLogTerm) {
return
}
reply.VoteGranted = true
rf.votedFor = args.CandidateId
rf.resetElectionTimerLocked()
}
需要注意的细节
比较日志新旧
论文中关于两个日志谁更新的比较规则是下面这样描述的。总结一下就是首先比较任期,任期大的更新;任期相同则比较索引,索引更大的更新。
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
分割选票
关于分割选票可以采用随机超时时间的方法来解决。选举超时时间通常在[T, 2T]区间内(例如150ms~300ms)。由于随机性节点不太可能再同时开始竞选,所以先竞选的节点有足够的时间来向其他节点索要选票。
日志同步/心跳
实现流程(理论)
整体上看是:Leader服务来着客户端的请求,每个客户端请求都包含一个要由复制状态机执行的命令,Leader将命令作为新条目追加到其日志中,然后并行地向其他每个服务器发出AppendEntries RPC以同步该命令到全部节点。
详细来说:开始日志同步的过程中Leader需要通过AppendEntries RPC进行日志同步和心跳,该RPC的请求参数包含term、leaderID、prevLogIndex、prevLogTerm、entries、leaderCommit。其中prevLogIndex是根据Leader中定义的nextIndex数组中该Follower的值得到的,prevLogTerm是Leader中prevLogIndex处的日志的任期,entries则包含prevLogIndex之后的所有日志,leaderCommit是Leader已经commit的日志的索引用来推进Leader的apply和Follower日志的commit、apply。当Follower节点收到AppendEntries RPC指令之后,首先比较任期如果领导的任期小于自己则直接返回当前任期让Leader下台。接下来看Follower中prevLogIndex索引处的日志是否任期是prevLogTerm,如果是则匹配成功,接下来把请求中的entries复制到本地的日志中,并且更新该节点的nextIndex数组和matchIndex数组;否则返回返回false让Leader的prevLogIndex继续向前试探,重新发送AppendEntries RPC请求给Follower直到匹配成功。这一部分的更细节的描述见 3.3.1.日志同步请求能否成功的逻辑。
对于Leader来说:在Follower接收AppendEntries RPC并成功把日志复制到本地之后,会更新matchindex数组,这个数组更新了之后就可能使得有新的日志已经从Leader被大多数节点复制完成,这时Leader就需要更新自己的commitIndex,同时如果commitIndex一更新就需要触发apply日志的Ticker进行日志应用,具体细节见 3.3.3.apply日志的业务逻辑。这里关于commitIndex的更新有个细节就是Leader只能提交当前任期的日志而不能提交之前任期的日志,具体细节见 3.3.2.不能commit非当前任期的日志。
对于Follower来说:Follower会根据AppendEntries RPC的请求参数中的leaderCommit进行自身commitIndex的更新进而推进日志的apply。Leader发送请求的请求参数中的leaderCommit是依据自身的commitIndex来确定的,所以上面的Leader的commitIndex的更新就会使得Leader发送请求的请求参数中的leaderCommit进行更新,进而推进Follower日志的apply。Follower的commitIndex一更新就需要触发apply日志的Ticker进行日志应用,具体细节见 3.3.3.apply日志的业务逻辑。这里还有另外一个细节就是不能直接把Leader的leaderCommit赋值给Follower的commitIndex更新Follower已提交日志索引,还需要考虑Follower的长度,具体细节见 3.3.4.更新Follower的commitIndex时需注意的点。
实现细节 (代码)
承接第二部分当Candidate当选Leader后就会go一个replicationTicker协程定时发送心跳以及日志同步请求。
func (rf *Raft) replicationTicker(term int) {
for !rf.killed() {
ok := rf.startReplication(term)
if !ok {
break
}
time.Sleep(replicateInterval) // replicateInterval为一个固定的值
}
}
Leader向所有其他节点进行同步日志并对返回结果处理的逻辑如下:
func (rf *Raft) startReplication(term int) bool {
rf.mu.Lock()
for peer := 0; peer < len(rf.peers); peer++ {
if peer == rf.me {
rf.matchIndex[peer] = len(rf.log) - 1
rf.nextIndex[peer] = len(rf.log)
continue
}
// 根据要发送节点的nextIndex数组中的数值确定prevLogIndex
prevIdx := rf.nextIndex[peer] - 1
prevTerm := rf.log[prevIdx].Term
args := &AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevIdx,
PrevLogTerm: prevTerm,
Entries: rf.log[prevIdx+1:], // 将prevLogIndex之后的日志填充进来
LeaderCommit: rf.commitIndex, // 根据Leader的commitIndex确定发送的LeaderCommit
}
go replicateToPeer(peer, args)
}
rf.mu.Unlock()
return true
// Leader对单个节点发送日志同步请求并处理响应的匿名函数的定义
replicateToPeer := func(peer int, args *AppendEntriesArgs) {
reply := &AppendEntriesReply{}
ok := rf.sendAppendEntries(peer, args, reply)
rf.mu.Lock()
defer rf.mu.Unlock()
if !ok {
return
}
// 如果得到的返回任期比我Leader,那么就需要变成Follower并return
if reply.Term > rf.currentTerm {
rf.becomeFollowerLocked(reply.Term)
return
}
// 如果不匹配则需要试探更前面的日志,最后通过更新nextIndex数组来保存要试探的索引
// 关联细节3.3.1
if !reply.Success {
idx, term := args.PrevLogIndex, args.PrevLogTerm
for idx > 0 && rf.log[idx].Term == term {
idx--
}
rf.nextIndex[peer] = idx + 1
return
}
// 如果匹配成功则需要更新matchIndex,nextIndex两个数组
rf.matchIndex[peer] = args.PrevLogIndex + len(args.Entries)
rf.nextIndex[peer] = rf.matchIndex[peer] + 1
// 匹配成功则需要判断是否要更新commitIndex
majorityMatched := rf.getMajorityIndexLocked()
// 关联细节3.3.2
if majorityMatched > rf.commitIndex && rf.log[majorityMatched].Term == rf.currentTerm {
rf.commitIndex = majorityMatched
// 关联细节3.3.3
rf.applyCond.Signal() // 如果更新了commitIndex那么触发Leader节点进行apply
}
}
}
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
return ok
}
AppendEntries RPC的定义也就是Follower对Leader的日志同步请求的回调函数如下:
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
reply.Success = false
// 如果Leader任期比我Follower还小,那你应该下台
if args.Term < rf.currentTerm {
return
}
// 如果你Leader的任期比我Candidate或者Follower大,那我需要变成Follower
if args.Term >= rf.currentTerm {
rf.becomeFollowerLocked(args.Term)
}
// 如果我Leader要尝试给你同步的日志索引比你Follower的全部日志还长,
// 那说明你缺日志,不能从PrevLogIndex处开始同步
// 关联细节3.3.1
if args.PrevLogIndex >= len(rf.log) {
return
}
// 如果日志不匹配PrevLogIndex索引处的任期一致说明不匹配
// 关联细节3.3.1
if rf.log[args.PrevLogIndex].Term != args.PrevLogTerm {
return
}
// 能运行到这里说明匹配成功,就需要把你Leader要发给我的Entries我放到我的日志中
rf.log = append(rf.log[:args.PrevLogIndex+1], args.Entries...)
reply.Success = true
// 如果你Leader的已提交日志索引比我Follower大,
// 那么我就需要更新我的commitIndex并触发日志apply
if args.LeaderCommit > rf.commitIndex {
// 关联细节3.3.4
rf.commitIndex = min(args.LeaderCommit, len(rf.log)-1)
// 关联细节3.3.3
rf.applyCond.Signal()
}
rf.resetElectionTimerLocked() // 收到了心跳重置超时计时器
}
需要注意的细节
日志同步请求能否成功的逻辑
在第一部分中我们说到Raft算法通过索引和任期号唯一的标识一条日志条目,所以判断Leader发送给Follower的AppendEntries RPC的请求能否成功的关键就是看Follower的prevLogIndex索引处的任期是否等于prevLogTerm,相等则可以将请求中的entries添加的Follower的日志中,否则失败需要减小nextIndex数组中该Follower的索引值,进而减小下次试探的prevLogIndex的值。
另外还需要注意一个容易忽视的可能导致的bug就是不匹配有两种情况,一种是Follower的prevLogIndex索引处的任期不一致,还有一种就是Follower中缺日志进而导致Follower中的日志长度<=prevLogIndex,这个情况应该提前判断避免数组越界。
不能commit非当前任期的日志
在论文中给出一个反例,我们详细看一下这个反例。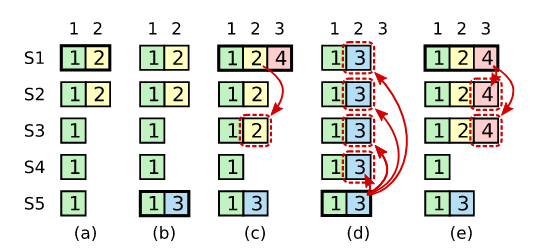
(a) S1 是领导者,复制索引2 处的日志条目到S2。
(b) S1崩溃,通过来自 S3、S4 和自身的投票,S5 被选为term 3的领导者,并在日志索引 2 处接收到一个来自客户端的跟S1、S2不同的日志条目。
? S5崩溃,S1重新启动,被选为leader,并继续复制日志到其他节点。此时,term 2中的日志条目已在大多数服务器上复制,但尚未提交。
(d) 如果S1又崩溃了,S5可以被选为leader(来自S2、S3和S4的投票),并用自己在term 3中的条目覆盖索引2的term 2的条目。
(e) 但是,如果S1在崩溃之前在大多数服务器上复制其当前任期的条目,如(e)所示,则该条目被提交(S5无法赢得选举)。此时,也提交了日志中前面的所有条目。
通过上面的(d)可以看到如果我在?处当term 2中的日志条目已在大多数服务器上复制时如果进行提交,那么在(d)处会把已提交的term 2的日志覆盖掉,这种情况是极其不允许的!而且通过(e)可以看到如果S1在崩溃之前在大多数服务器上复制其当前任期的条目,那么一方面能压制S5获取不到大多数投票,另一方面在提交当前term 4的日志时也会间接的term 2的日志进行提交。
apply日志的业务逻辑
可以分为Leader的apply日志和Follower的apply日志。
首先讨论一下Leader可能apply日志的时机,在replicateToPeer匿名函数中,Leader向单个Follower同步成功日志之后需要判断一下commitIndex需不需要更新,如果需要更新,那么说明有新的日志被提交也就会触发Leader日志apply。
其次说一下Follower可能apply日志的时机,当上一段中commitIndex更新之后由于leaderCommit = commitIndex,也就会导致leaderCommit更新,在AppendEntries函数的最后可以看到如果leaderCommit更新变大了就会触发Follower的日志apply。
更新Follower的commitIndex时需注意的点
这个是极易忽视的一点,在Follower处理AppendEntries RPC请求时,最后如果发送过来的leaderCommit参数比我Follower当前的commitIndex大,那么我Follower需要更新我的commitIndex,但是,你注意但是啊,这个commitIndex再大也不能超过我日志的总长度-1吧,这个是及其容易忽视的一点。
总结
在本文结合Raft论文和mit 6.5840(原6.824)的lab2的partA和partB实验对Raft算法的基础概念以及两大重要部分投票选举和日志同步对Raft算法进行了细致的讨论。在后面的实验中还有关于日志持久化和日志压缩的内容,之后会在学习完成之后进行相应内容的更新。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!