爬虫案例—爬取豆瓣电影最受欢迎的影评
发布时间:2024年01月15日
爬虫案例—爬取豆瓣电影最受欢迎的影评
豆瓣影评网址:https://movie.douban.com/review/best/
目标:爬取第一页的影评封面标题、评论内容、完整的评论内容
第一页页面截图如下:
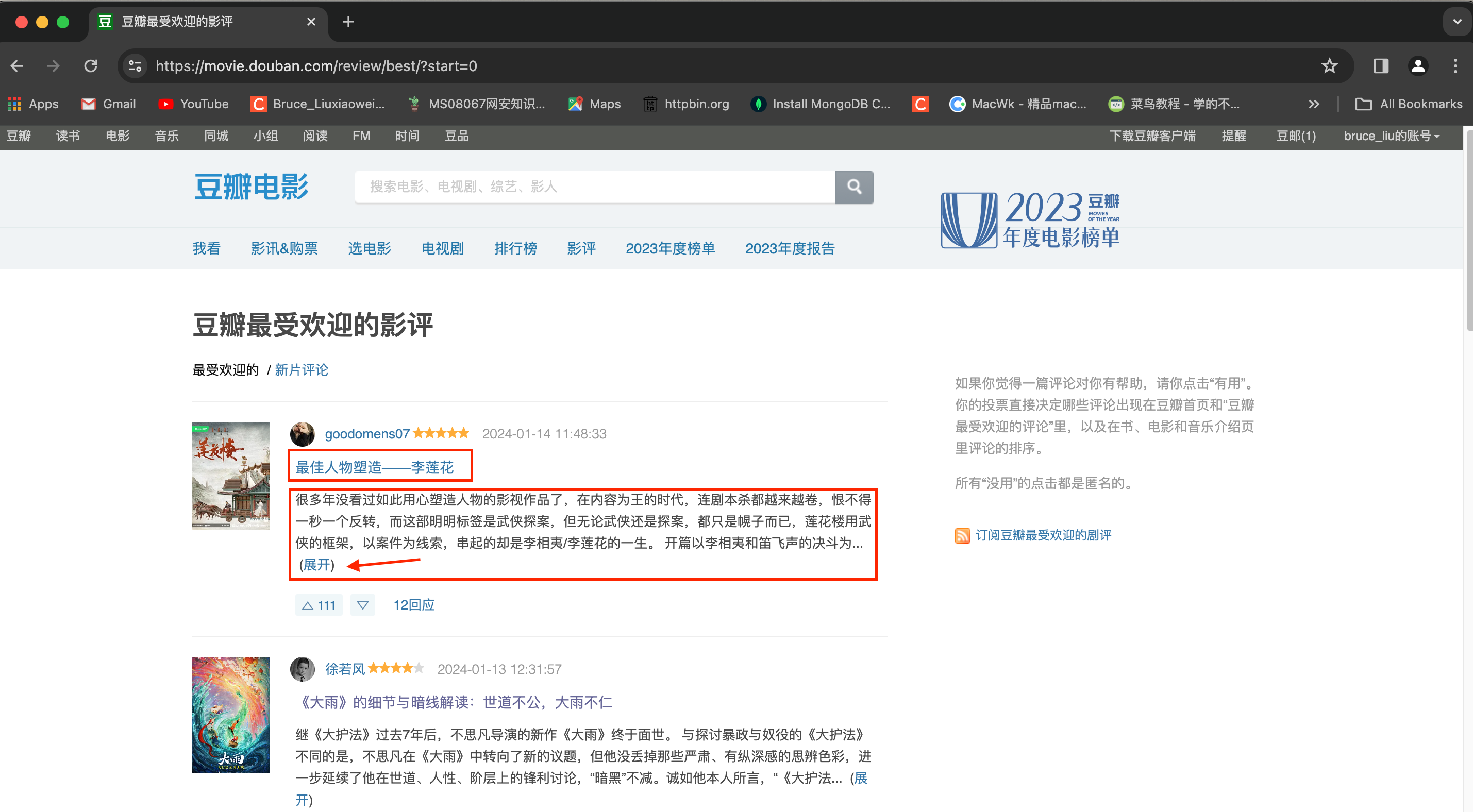
import requests
from lxml import etree
import re
from bs4 import BeautifulSoup
# headers字典里要添加cookie键值对,因为此案例抓取需要登录
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Cookie': 'll="32144"; bid=3RohyNWVHj0; _pk_id.100001.4cf6=23907e7ebb54271c.1686100051.; __yadk_uid=OGVnwlTfotLSH5XdI6JXtqA5kQsN0x89; _vwo_uuid_v2=D1E8222BE3569A942B9687BFC0D7D966C|59c360096de363c25bd7c2994af63c64; __gads=ID=0902d3edd87ac6ff-222ef5a967e2003d:T=1688109672:RT=1688109672:S=ALNI_MaZQ_lI9mzmEI5AhRb_5LLQVCGQBA; __gpi=UID=00000c7cae331650:T=1688109672:RT=1688109672:S=ALNI_MaqXeTvGSxmShelBp8foNJqyq8o4g; __utmv=30149280.25330; __utmc=30149280; __utmc=223695111; dbcl2="253305871:w8B2qq3cOOA"; ck=PU0Q; __utmz=30149280.1705207739.16._pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1705215531%2C%22https%3A%2F%2Faccounts.douban.com%2F%22%5D; _pk_ses.100001.4cf6=1; __utma=30149280.522421068.1686100051.1705207739.1705215531.17; __utmb=30149280.0.10.1705215531; __utma=223695111.711123561.1686100051.1705207739.1705215531.14; __utmb=223695111.0.10.1705215531'
}
# 第一页的影评网址
url = 'https://movie.douban.com/review/best/?start=0'
# 请求页面,获取页面响应
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
# 解码页面内容并赋值给变量data
data = res.content.decode()
# 解析字符串格式的HTML文档对象为_Element对象
tree = etree.HTML(data)
# 用xpath匹配所有的class属性值为"main-bd"的标签
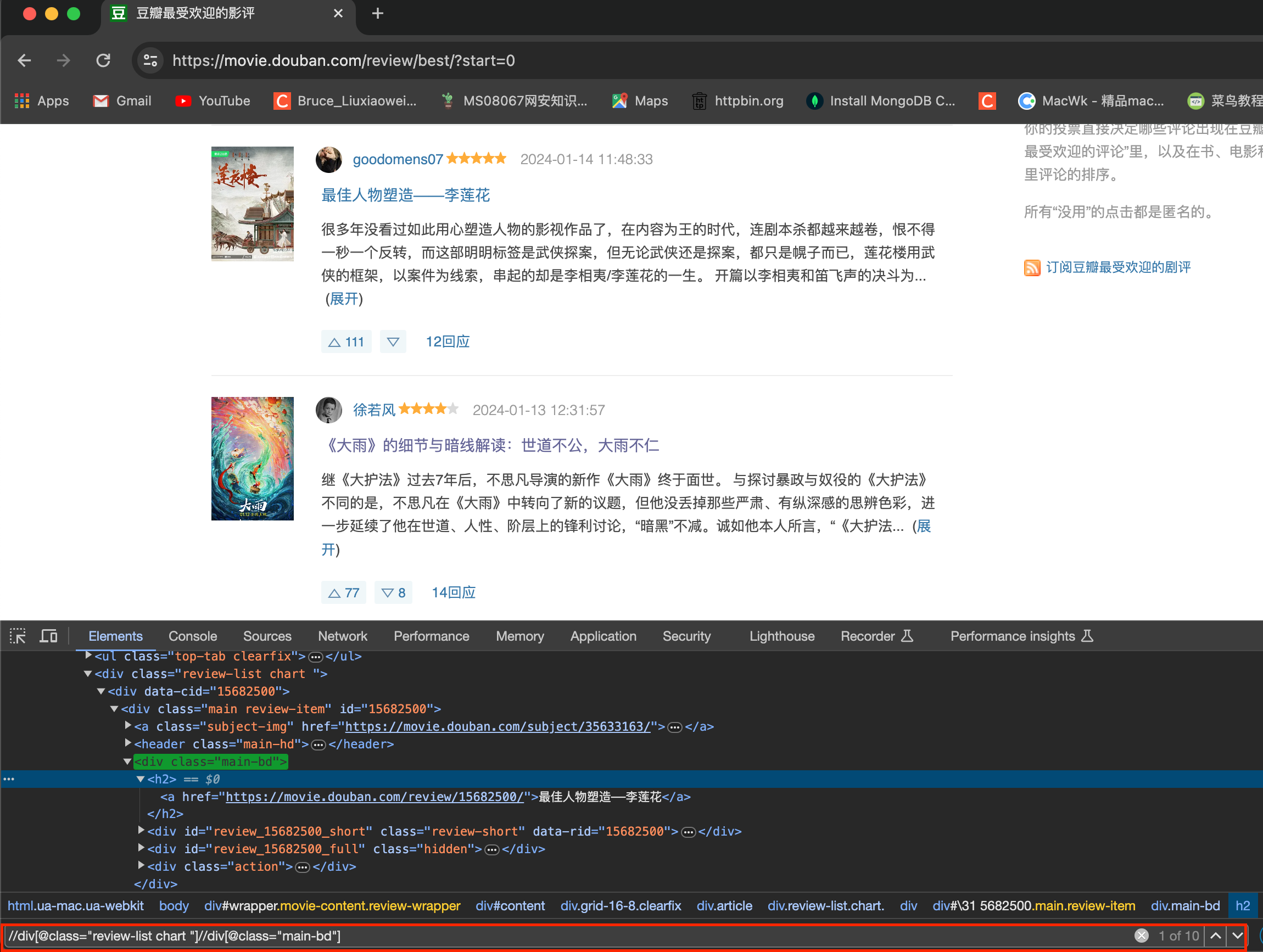
reivew_lst = tree.xpath('//div[@class="review-list chart "]//div[@class="main-bd"]')
# 遍历所有的影评div,然后再分别匹配标题title,短评,完整评论
for review in reivew_lst:
# 匹配标题
title = review.xpath('./h2/a/text()')
# 匹配短评
short_content = review.xpath('.//div[@class="short-content"]/text()')
print('标题:', title[0].strip())
print('评论内容:', ''.join(short_content).strip('()').strip().strip('()').strip())
# 匹配影评data-id,因为点击页面的展开加载完整评论,属于异步加载,需要单独请求完整评论的url
data_id = review.xpath('./div[1]/@data-rid')
# 获取完整影评的data-id并构造完整评论url
full_review_url = f'https://movie.douban.com/j/review/{data_id[0]}/full'
res = requests.get(full_review_url, headers=headers)
res.encoding = res.apparent_encoding
print('完整评论:')
# 响应值为json格式,取字典的'html'的键的值
full_content = res.json()['html']
# 用BeautifulSoup解析成lxml
soup = BeautifulSoup(full_content, 'lxml')
# 获取所有的p标签
p_lst = soup.find_all('p')
# 遍历p标签,然后获取text文本
for p in p_lst:
print(p.get_text().strip(),end='')
print()
# 打印分割线
print('~ ' * 70)
运行结果如下:

分析如下:
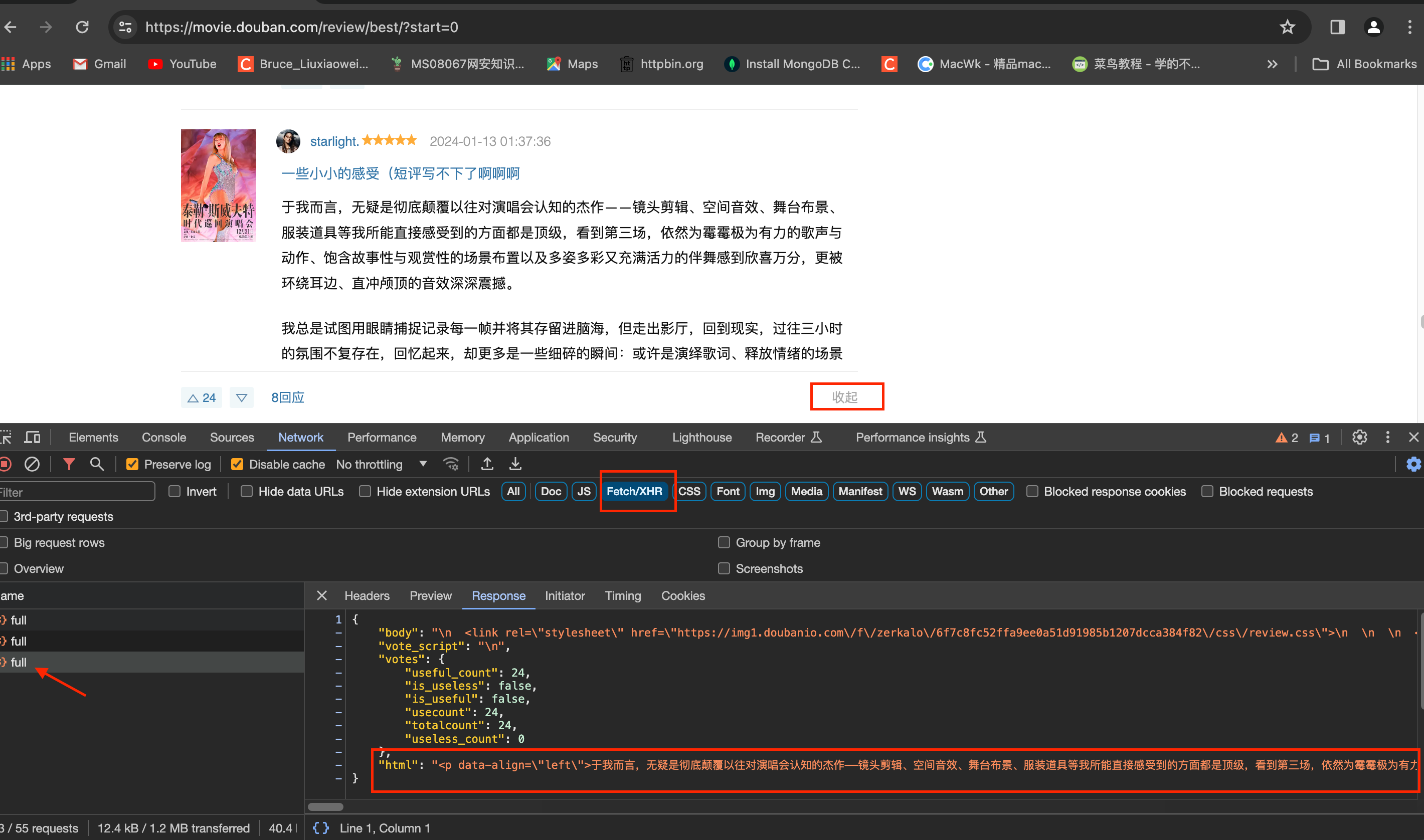
点击“展开”,之后加载全部评论,属于异步加载。如下图:
文章来源:https://blog.csdn.net/weixin_41905135/article/details/135592301
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL作业
- 普中STM32-PZ6806L开发板(HAL库函数实现-7段共阳数码管数字显示)
- 鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之线性布局容器Column组件
- 2024北京数字交通大会暨2024国际数字交通博览会
- kafka: 基础概念回顾
- 热门的容器技术:Docker 和 Kubernetes 介绍
- 基于Hadoop的智慧社区大数仓库系统设计与开发
- STL——排序算法
- Unity3D代码混淆方案详解
- 1599. 经营摩天轮的最大利润 -- 力扣 --JAVA