【Kimi帮我看论文(二)】Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models—Survey
一、论文信息
1 标题
Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment
2 作者
Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, Fu Lee Wang
3 研究机构
- Hong Kong Metropolitan University, Hong Kong
- Lingnan University, Hong Kong
- University of Southern Queensland, Queensland, Australia
二、主要内容
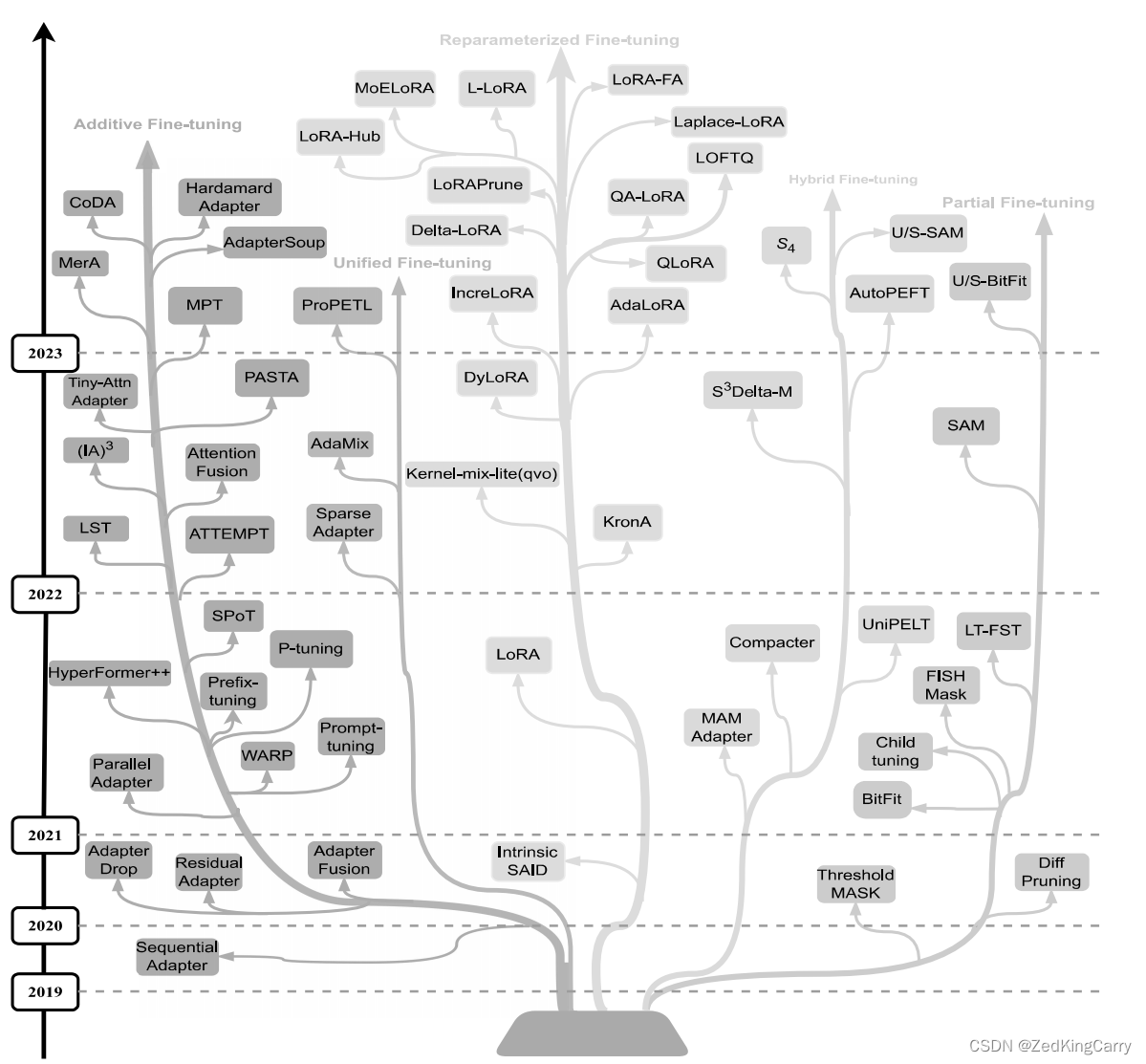
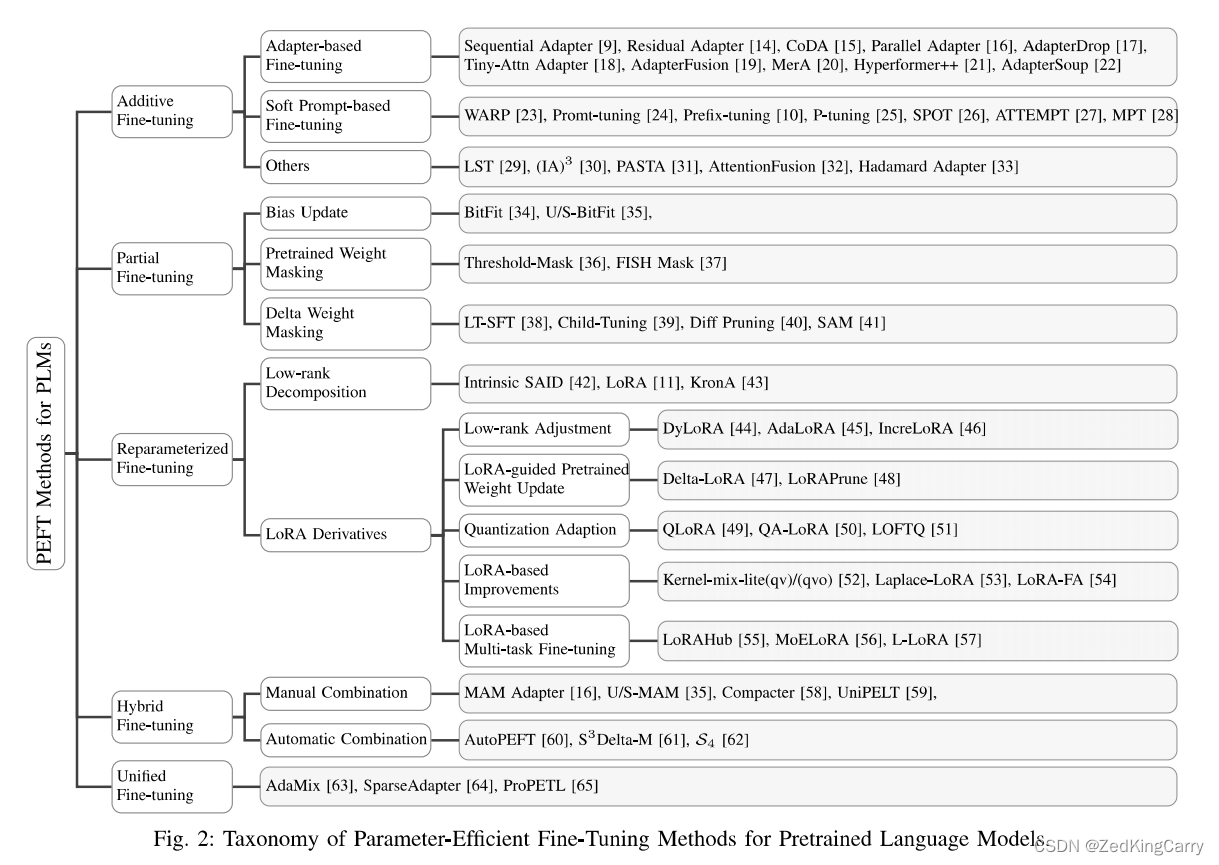
论文对参数高效的微调(PEFT)方法进行了全面的系统性回顾,这些方法用于预训练语言模型(PLMs),特别是大型语言模型(LLMs),以减少微调参数和内存使用,同时保持与全微调相当的性能。论文提出了一个全面的分类方案,将PEFT方法分为加性微调、部分微调、重参数化微调和混合微调,并建立了一个结构化框架以理解这些方法。此外,论文还通过广泛的微调实验,评估了这些方法在参数效率和内存效率方面的表现。
三、相关研究
论文指出,尽管已有一些关于PEFT方法的研究,但这些研究存在局限性,例如没有涵盖最新的工作,或者没有进行相关实验。现有的研究主要集中在PEFT方法的分类和理论分析上,但缺乏对这些方法在实际应用中性能的全面评估。
四、解决方案
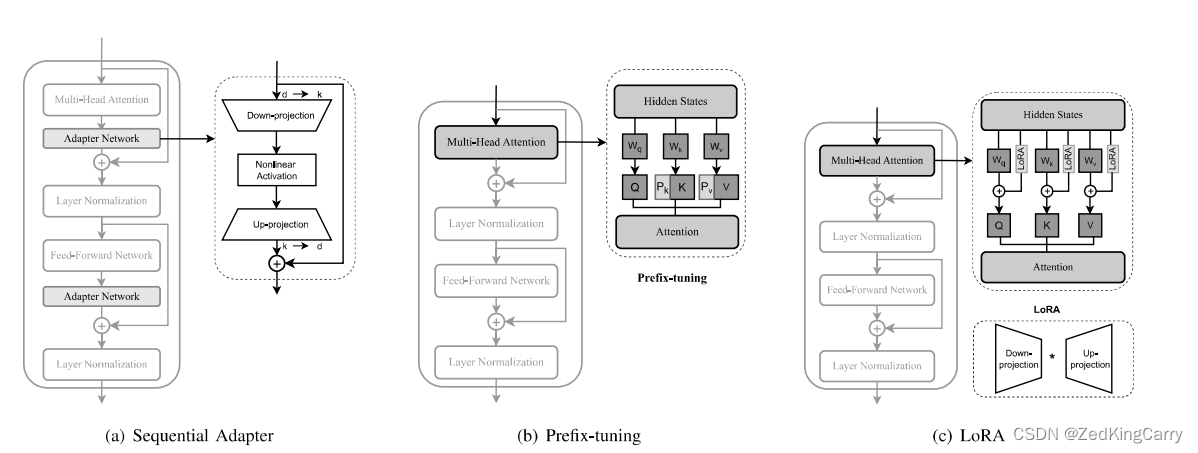
为了解决LLMs在特定下游任务上的适应性问题,PEFT方法通过引入各种深度学习技术来减少可训练参数的数量,同时更新少量额外的参数或更新预训练参数的子集,以适应目标任务并减少灾难性遗忘的风险。此外,PEFT方法还通过选择性地或不更新预训练参数来避免过拟合。
五、实验环节
论文通过使用11种代表性的PEFT方法进行广泛的微调实验,评估了这些方法在参数效率和内存效率方面的表现。实验结果表明,大多数PEFT方法在参数效率和内存效率方面都有显著的改进,并且与全微调方法相比,性能相当甚至更好。
六、进一步探索点:
- 探索PEFT方法在计算机视觉和多模态学习中的应用。
- 研究PEFT方法的可解释性和工作原理。
- 利用多种优化技术自动搜索神经网络架构和配置特定组合的PEFT模块。
- 研究如何利用PEFT方法来构建后门攻击和防御机制。
七、总结
论文提供了对PEFT方法的全面分析和回顾,识别了关键技术和方法,并将它们分类为不同的微调方法。通过广泛的实验,论文评估了这些方法在参数效率和内存效率方面的表现,并揭示了未来研究的潜在方向。这些研究为研究人员和实践者在面对LLMs带来的挑战和机遇时提供了宝贵的资源。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 元素水平垂直居中的5种方式
- 鸿蒙开发笔记(二十八): 性能提升常用方法
- 纵享丝滑!全志R128+LVGL驱动多尺寸RGB LCD屏幕流畅运行
- Mysql学习笔记系列(一)
- 网络安全最大的威胁:洞察数字时代的风险之巅
- String类的常用方法
- 记忆泊车信息安全技术要求
- STM32入门教程-2023版【2-2】stm32如何选择启动文件
- Excel密码遗失?轻松取消表格保护的实用指南!
- 大创项目推荐 目标检测-行人车辆检测流量计数