Nvdiffrast高性能可微渲染开发包

NSDT工具推荐:?Three.js AI纹理开发包?-?YOLO合成数据生成器?-?GLTF/GLB在线编辑?-?3D模型格式在线转换?-?可编程3D场景编辑器?-?REVIT导出3D模型插件?-?3D模型语义搜索引擎
Nvdiffrast 是一个 PyTorch/TensorFlow 库,为基于光栅化的可微渲染提供高性能基元操作。 与以前的库(例如?redner、SoftRas?或?PyTorch3D)相比,它是一个更底层的库 - nvdiffrast 没有内置相机模型、照明/材质模型等。相反,提供的操作仅封装了最以图形为中心的步骤现代硬件图形管道:光栅化、插值、纹理和抗锯齿。 所有这些操作(及其梯度)都是 GPU 加速的,通过 CUDA 或通过硬件图形管道。

使用 nvdiffrast的示例
1、安装nvdiffrast
安装nvdiffrast的最低要求如下:
- Linux 或 Windows 操作系统。
- 64 位Python 3.6。
- PyTorch(推荐)1.6 或 TensorFlow 1.14。 目前不支持 TensorFlow 2.x。
- 高端 NVIDIA GPU、NVIDIA 驱动程序、CUDA 10.2 工具包。
要下载 nvdiffrast,请前往存储库?下载 .zip 文件,或使用 git 克隆存储库:
git clone https://github.com/NVlabs/nvdiffrast1.1 Linux安装nvdiffrast
我们建议在 Docker 上运行 nvdifrast。 要构建安装了 nvdiffrast 和 PyTorch 1.6 的 Docker 映像,请运行:
./run_sample.sh --build-container我们建议使用 Ubuntu,因为某些 Linux 发行版可能没有提供所有必需的软件包。 据报道,在 CentOS 上安装有问题,但这里有个案例声称是可以成功的。
要尝试一些提供的代码示例,请运行:
./run_sample.sh ./samples/torch/cube.py --resolution 32或者,如果你已处理好所有依赖项(请参阅随附的 Dockerfile 以供参考),则可以通过在项目根目录运行以下命令在本地 Python 站点包中安装 nvdiffrast:
pip install .此外,你还可以将存储库根目录添加到 PYTHONPATH 中。
1.2 Windows安装nvdiffrast
在 Windows 上,nvdiffrast 需要外部编译器来编译 CUDA 内核。 开发是使用 Microsoft Visual Studio 2017 专业版完成的,该版本可与 PyTorch 和 TensorFlow 版本的 nvdiffrast 配合使用。 VS 2019 专业版也已被确认可与 PyTorch 版本的 nvdiffrast 配合使用。 除专业版之外的其他 VS 版本(包括社区版)应该可以工作,但尚未经过测试。
如果在 PATH 中找不到编译器二进制文件 (cl.exe),nvdifrast 将启发式搜索它。 如果失败,你可能需要通过手动添加
"C:\Program Files (x86)\Microsoft Visual Studio\...\...\VC\Auxiliary\Build\vcvars64.bat"其中确切的路径取决于你安装的 VS 的版本和版本。
要在本地站点包中安装 nvdiffrast,请运行:
# Ninja is required run-time to build PyTorch extensions
pip install ninja
# Run at the root of the repository to install nvdiffrast
pip install .同样,你也可以将存储库根目录添加到 PYTHONPATH 中。
2、基元操作
Nvdiffrast 提供四种可微分渲染基元:光栅化、插值、纹理和抗锯齿。 此处以与平台无关的方式描述原语的操作。 特定于平台的文档可以在 API 参考部分找到。
在本节中,为了清楚起见,我们忽略小批量轴并假设小批量大小为 1。 但是,所有操作都支持小批量,稍后将详细介绍。
2.1 光栅化
光栅化(rasterization)操作将顶点位置的张量和指定三角形的顶点索引三元组的张量作为输入。 顶点位置在裁剪空间(clip space)中指定,即在模型视图和投影变换之后。 执行这些转换由用户负责。 在裁剪空间中,视锥体是齐次坐标中的立方体,其中 x/w、y/w、z/w 均在 -1 和 +1 之间。
光栅化操作的输出是一个 4 通道 float32 图像,每个像素中包含元组?(u, v, z/w, triangle_id)。 值 u 和 v 是三角形内的重心坐标:顶点索引三元组中的第一个顶点为?(u,?v)?=?(1,?0),第二个顶点为?(u,?v)?=?(0,?1),第三个顶点为?(u,?v)?=?(0,?0)?。 归一化深度值?z/w?稍后由抗锯齿操作用来推断三角形之间的遮挡关系,并且它不会将梯度传播到顶点位置输入。 字段?triangle_id是三角形索引,偏移1。 没有对三角形进行光栅化的像素将在所有通道中接收到零。
光栅化是点采样的,即,与之前的一些可微分光栅化器相比,几何图形不会以任何方式平滑、模糊或部分透明。 像素的内容始终表示单个表面点,该点位于沿着穿过像素中心的光线可见的最近表面上。
点采样覆盖不会产生与遮挡和可见性效果相关的顶点位置梯度。 这是因为顶点的运动不会以连续的方式改变覆盖范围——三角形要么被光栅化为像素,要么不被光栅化。 在 nvdiffrast 中,遮挡/可见性相关的梯度是在抗锯齿操作中生成的,该操作通常发生在渲染管道的末端:
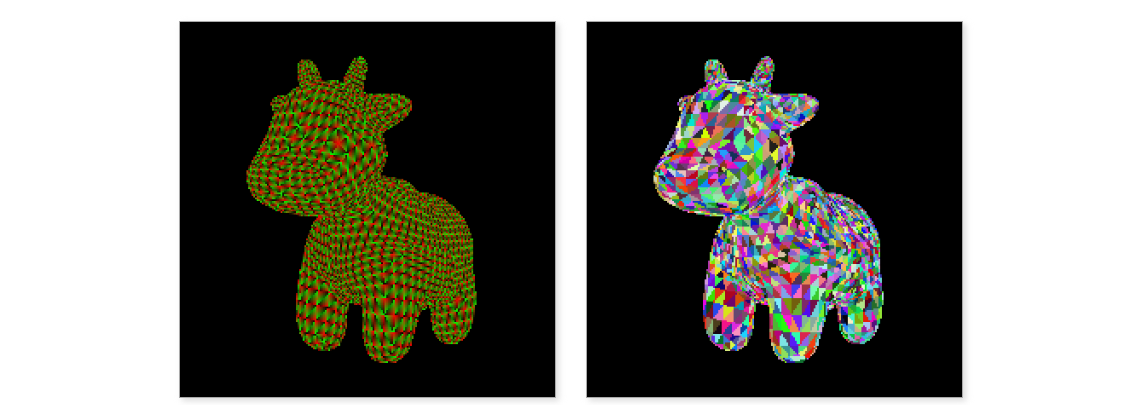
左:[..., 0:2]?= barycentrics (u,?v) 。 右:[..., 3]?=?triangle_id。
上图展示了光栅化器的输出。 左图显示了通道 0 和 1 的内容,即重心坐标(barycentric coordinates),分别呈现为红色和绿色。 右图显示通道 3,即三角形 ID,每个三角形使用随机颜色。
2.2 插值
根据着色和光照模型,网格通常在其顶点指定许多属性。 这些可以包括例如纹理坐标、顶点法线、反射矢量和材料参数。 插值操作的目的是将顶点指定的这些属性转移到图像空间。 在硬件图形管道中,这会在顶点着色器和像素着色器之间自动发生。 nvdiffrast 中的插值操作支持任意数量的属性。
具体来说,插值操作将光栅化器生成的缓冲区和指定顶点属性的缓冲区作为输入。 输出是一个图像大小的缓冲区,具有与属性一样多的通道。 未渲染三角形的像素在输出中将包含全零:

纹理坐标 (s,t)
上面是在红色和绿色通道中可视化的插值纹理坐标的示例。 该图像是使用上一步的光栅化器的输出以及包含纹理坐标的属性缓冲区创建的。
2.3 纹理化
纹理采样是硬件图形管道中的基本操作,在nvdifrast中也是如此。 基本原理很简单:给定每个像素的纹理坐标向量,从纹理中获取一个值并将其放入输出中。 在 nvdiffrast 中,纹理可能具有任意数量的通道,这在你想要学习(例如,充当管道下游神经网络的输入)的抽象字段时非常有用。
对纹理进行采样时,通常需要使用某种形式的滤波(filtering)。 大多数以前的可微光栅器最多支持双线性(bilinear)滤波,其中在纹素(texel)中心之间的纹理坐标处采样将从四个最近的纹素线性插值。 虽然在近距离查看纹理时效果很好,但从远处查看纹理时会产生严重的锯齿结果。 为了避免这种情况,需要在采样之前对纹理进行预过滤,去除与采样密度相比过高的频率。
Nvdiffrast 支持基于 mipmapping 的预过滤纹理采样。 所需的 mipmap 级别可以在纹理操作中内部生成,因此用户只需指定最高分辨率(基本级别)纹理。 目前质量最高的滤波模式是各向同性三线性(isotrophic trilinear)滤波。 缺乏各向异性滤波意味着以陡峭角度查看的纹理不会在任何方向上混叠,但在非挤压方向上可能会显得模糊。
除了标准的 2D 纹理之外,纹理采样操作还支持立方体贴图(cube maps)。 立方体贴图使用 3D 纹理坐标进行寻址,并且立方体贴图面之间的过渡经过正确过滤,因此不会有可见的接缝。 立方体贴图支持类似于 2D 纹理的三线性滤波。 没有对 1D 纹理的明确支持,但可以使用 1×n 纹理有效地模拟它们。 所有滤波、纹理贴图等都适用于此类纹理,就像它们适用于真正的 1D 纹理一样。 目前不支持 3D 体积纹理。

左:Spot纹理。 中:纹理采样操作输出。 右:用白色替换背景。
上面的中间图像显示了使用上一步中插值的纹理坐标进行纹理采样的结果。 为什么背景是粉红色的? 纹理坐标?(s,?t)?在这些像素处读取为零,但这是对纹理进行采样的完全有效的点。 Spot 的纹理(左)在其?(0,?0)?角处具有粉红色,因此背景中的所有像素都会通过纹理采样操作获得该颜色。 在右侧,我们将空像素的颜色替换为白色。 这是在 PyTorch 中执行此操作的一种方法:
img_right = torch.where(rast_out[..., 3:] > 0, img_left, torch.tensor(1.0).cuda())其中?rast_out?是光栅化操作的输出。 我们简单地测试?triangle_id?字段(即光栅化器输出的通道 3)是否大于零,表明在该像素中渲染了三角形。 如果是这样,我们就从纹理图像中获取颜色,否则我们就取常数 1.0。
2.4 抗锯齿
nvdiffrast 中最后一个基元操作是抗锯齿(antialiasing)。 根据几何输入(顶点位置和三角形),它将平滑给定图像中轮廓边缘的不连续性。 平滑基于覆盖范围的局部近似 - 像素上的近似积分是根据相关边缘的精确位置和像素中心的点采样颜色来计算的。
在这种情况下,轮廓是指仅连接到一个三角形或连接两个三角形以便一个三角形折叠在另一个三角形后面的任何边。 具体来说,这包括背景的轮廓和另一个表面的轮廓,这与之前的一些方法 (DIB-R) 不同,这些方法仅支持前一种。
值得讨论的是,为什么我们可能要经历这个麻烦来稍微改善图像。 例如,如果我们试图匹配真实世界的照片,稍微平滑的边缘可能不会比锯齿状的图像更好地匹配捕获的图像。 然而,这不是抗锯齿操作的重点—真正的目标是获得梯度。 与遮挡、可见性和覆盖范围相关的顶点位置。
请记住,渲染管道中到目前为止的所有内容都是点采样的。 特别是,覆盖范围(即哪个三角形被光栅化到哪个像素)在光栅化操作中不连续地变化。
这就是为什么以前的可微分光栅器应用具有模糊和透明度的非标准图像合成模型的原因:必须有某种东西使关于顶点位置的覆盖范围连续,如果我们希望基于图像空间损失来优化顶点位置、相机位置等。 在 nvdiffrast 中,我们对所有内容进行点采样,以便我们知道每个像素对应于一个明确定义的表面点。 这使我们可以执行任意着色计算,而不必担心诸如意外模糊轮廓上的纹理坐标,或者当接近对象边缘时属性神秘地倾向于背景颜色之类的情况。 仅在管道末端,抗锯齿操作才能确保顶点位置的运动导致轮廓的连续变化。
抗锯齿操作支持图像中任意数量的通道进行抗锯齿。 因此,如果你的渲染管道生成一个抽象表示,并将其馈送到神经网络进行进一步处理,那么这不是问题。

左:抗锯齿处理的图像。 中:抗锯齿处理之前的近景。 右:抗锯齿处理之后的近景
上面左图显示了执行抗锯齿后的结果图像。 效果非常小—一些边界像素的锯齿状变得更少,如特写所示。
值得注意的是,并非所有边界像素都经过抗锯齿处理,如下面左侧图像所示。 这是因为 nvdiffrast 中抗锯齿操作的准确性取决于三角形的渲染大小:因为我们仅存储每个像素一个表面点的知识,因此仅当包含实际几何轮廓边缘的三角形在图像中可见时才可以进行抗锯齿 。 示例图像以非常低的分辨率渲染,并且三角形与像素相比很小。 因此,三角形很容易在像素之间丢失。
这会导致抗锯齿看起来不完整,并且当边缘三角形丢失时,抗锯齿提供的渐变会变得更加嘈杂。 因此,建议以三角形足够大的分辨率渲染图像,以便至少在大部分时间在图像中显示:

左:抗锯齿处理的像素,原始分辨率。 右:以 4×4 更高分辨率渲染并进行下采样
上面左图显示了示例中哪些像素被抗锯齿操作修改。 在右侧,我们以 4×4 更高分辨率执行渲染,并将最终图像下采样回原始尺寸。 这会产生与轮廓相关的更准确的位置梯度,因此,如果你怀疑位置梯度噪声太大,可能需要尝试简单地提高完成光栅化和抗锯齿的分辨率。
出于形状优化的目的,左侧看起来稀疏的情况可能完全没问题。 即使梯度有些稀疏,它们仍然会指向正确的方向,并且无论如何你都需要使用某种形状正则化,这将大大增加对噪声形状梯度的容忍度。
3、超越基元操作
使用 nvdiffrast 渲染图像很容易,但你需要考虑一些实际的事情。 本节中的主题更详细地解释了 nvdiffrast 的操作和使用,希望可以帮助你避免任何潜在的误解和陷阱。
3.1 坐标系
Nvdifrast 遵循 OpenGL 的坐标系和其他约定。 这部分是因为我们支持 OpenGL 来加速光栅化操作,但主要是因为有一个可遵循的标准。
- 在 OpenGL 约定中,透视投影矩阵(例如在我们的示例中的?
utils.projection()?和 OpenGL 中的?glFrustum()?中实现的)将视图空间 z 视为向观察者增加。 然而,在乘以透视投影矩阵之后,齐次剪辑空间坐标?z/w?远离观察者而增加。 因此,光栅器输出张量中较大的深度值也对应于距观察者较远的表面。 - OpenGL 中以及 nvdifrast 中图像数据的内存顺序是自下而上的。 这意味着包含图像的张量的第 0 行是纹理/图像的底行,这与更常见的扫描线顺序相反。 如果你想在代码中以传统的自上而下的顺序保留图像数据,但在 nvdiffrast 中逻辑上使其以正确的方式向上,则需要在跨越边界时垂直翻转图像。
- 对于 2D 纹理,坐标原点?
(s,?t)?=?(0,?0)?位于左下角,s 向右增加,t 向上增加。 当指定立方体贴图纹理的面时,面之间的方向会有所不同,但 nvdifrast 也遵循 OpenGL 约定。
作为建议,最好掌握程序中使用的坐标系和方向。 当出现问题时,识别并修复根本原因比随机翻转坐标、图像、缓冲区和矩阵直到直接问题消失要好得多。
3.2 几何和小批量:范围模式与实例模式
如前所述,nvdifrast 中的所有操作都有效支持小批量轴。 与此相关的是,我们支持两种表示几何图形的方式:范围(range)模式和实例化(instanced)模式。 如果要在每个小批量索引中渲染不同的网格,则需要使用范围模式。 但是,如果您在每个小批量索引中渲染相同的网格,但具有可能不同的视点、顶点位置、属性、纹理等,则实例化模式将更加方便。
在范围模式下,将三角形索引三元组指定为形状为?[num_triangles, 3]?的 2D 张量,并将顶点位置指定为形状?[num_vertices, 4]?的 2D 张量。 除此之外,光栅化操作还需要一个形状为?[minibatch_size, 2]?的附加 2D 范围张量,其中每行指定一个起始索引并计入三角形张量。 因此,光栅化器会将指定范围内的三角形渲染到输出张量的每个小批量索引中。 如果有多个网格,则应将它们全部放入顶点和三角形张量中,然后通过范围张量的内容选择要栅格化到每个小批量索引中的网格。 插值运算中的属性张量的处理方式与位置相同,并且在范围模式下它的形状必须为?[num_vertices, num_attributes]。
在实例模式下,网格的拓扑将为每个小批量索引共享。 三角形张量仍然是形状为?[num_triangles, 3]?的 2D 张量,但顶点位置是使用形状为 ?[minibatch_size, num_vertices, 4]?的 3D 张量指定的。 对于 3D 顶点位置张量,光栅化器不需要范围张量输入,但会从顶点位置张量的第一维获取小批量大小。 相同的三角形被渲染到每个小批量索引,但顶点位置取自顶点位置张量的相应切片。 在这种模式下,插值中的属性张量必须是类似于位置张量的 3D 张量,即形状为?[minibatch_size, num_vertices, num_attributes]。 但是,你可以提供小批量大小为 1 的属性张量,并且它将在整个小批量中广播。
3.3 图像空间微分
我们在上面的纹理操作描述中回避了一个非常基本的问题。 为了确定对纹理采样的适当的预过滤,我们需要知道采样的密度。 但是,当每个像素只知道一个表面点时,我们如何才能知道采样密度呢?
解决方案是跟踪导致纹理采样操作的所有事物的图像空间导数。 这些与向后传递中使用的梯度不同,尽管它们都涉及微分! 考虑光栅化操作产生的重心?(u,?v)。 当在图像平面中水平或垂直移动时,它们会发生一定程度的变化。 如果我们将图像空间坐标表示为 ?(X,?Y),则重心的图像空间导数将为??u/?X、??u/?Y、??v/?X?和 ??v/?Y。 我们可以将它们组织成一个 2×2 雅可比矩阵,描述?(u,?v)?和?(X,?Y)?之间的局部关系。 该矩阵通常每个像素都不同。 为了图像空间导数的目的,X 和 Y 的单位是像素。 因此,??u/?X?是当水平方向移动一个像素的距离时 u 变化量的局部近似,依此类推。
一旦我们知道重心相对像素位置如何变化,插值操作可以使用它来确定属性如何随像素位置变化。 当属性用作纹理坐标时,我们因此可以知道纹理采样位置(在纹理空间中)在像素内移动时如何变化(即达到局部线性近似)。 这个纹理足迹告诉我们纹理应该被预过滤的比例。 更实际地说,它告诉我们在采样纹理时要使用哪个 mipmap 级别。
在 nvdiffrast 中,光栅化操作在辅助 4 通道输出张量中输出重心的图像空间导数,顺序为?(?u/?X, ?u/?Y, ?v/?X, ?v/?Y)?从通道 0 到 3。插值操作可以将此辅助张量作为输入,并计算任何被插值的属性集的图像空间导数。 最后,纹理采样操作可以使用纹理坐标的图像空间导数来确定预过滤的量。
这些图像空间导数并没有什么神奇之处。 它们是张量,例如纹理坐标本身,它们向后传播梯度,等等。 例如,如果想在采样时人为地模糊或锐化纹理,可以在将其送入纹理采样操作之前,简单地将带有纹理坐标??{s,?t}/?{X,?Y}?的图像空间导数的张量乘以标量值。 这会缩放纹理足迹,从而调整预过滤量。 如果你的损失函数更喜欢不同级别的锐度,则该乘数将收到非零梯度。
更新:从版本 0.2.1 开始,纹理采样操作还支持单独的 mip 级别偏差输入,该输入更适合此特定任务,但要点是相同的。
人们可能会想,仅根据相邻像素中的纹理坐标来确定纹理足迹是否会更容易,并跳过所有这些微分垃圾? 在简单的情况下,答案是肯定的,但轮廓、遮挡和不连续的纹理参数化将使这种方法在实践中相当不可靠。 通过分析计算图像空间导数可以使所有内容保持点状、局部且行为良好。
应该注意的是,计算与图像空间导数相关的梯度有些复杂并且需要额外的计算。 同时,它们对于训练/优化的收敛通常并不重要。 因此,nvdifrast 中的原始操作提供了禁用这些梯度计算的选项。 我们正在讨论像??Loss/?(?{u,?v}/?{X,?Y})?这样的东西,它们可能看起来是二阶的,但事实并非如此。
3.4 Mipmap 和纹理尺寸
预过滤纹理采样模式需要 mipmap,即纹理的下采样版本。 纹理采样操作可以在内部构建这些,或者您可以提供自己的 mipmap 栈,但需要考虑纹理尺寸的限制。
当内部构造 mipmap 时,每个 mipmap 级别都是通过对前一级别(或第一个 mipmap 级别的纹理本身)的 2×2 像素块进行平均来构造的。 因此,要平均的缓冲区大小必须在两个方向上都能被 2 整除。 有一个例外:边长为 1 是有效的,并且在下采样操作中将保持为 1。
例如,32×32 纹理将生成以下 mipmap 栈:
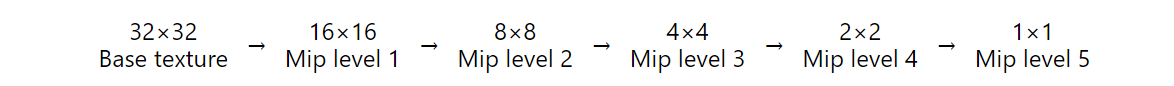
一个 32×8 的纹理,两边的幂都是 2 但不相等,将导致:
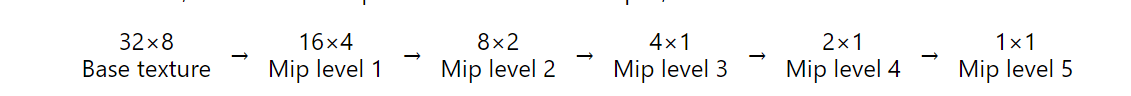
对于这样的纹理大小,一切都会自动工作,并且 mipmap 会构建为小至 1×1 像素大小。 因此,如果你希望使用预过滤纹理采样,则应将纹理缩放到二维的幂,但不必相等。
纹理图集(texture atlas)回怎么样? 你可能有一个对象,其纹理由多个单独的面片组成,或者由每个纹理网格具有唯一纹理的纹理网格集合组成。 假设我们有一个由五个 32×32 子图像组成的纹理图集,即总大小为 160×32 像素。 现在我们无法将 mipmap 级别一直计算到 1×1 大小,因为其中有一个 5×1 mipmap 无法下采样(因为 5 不是偶数):

将图集缩放到 256×32 像素会感觉很愚蠢,因为子图像的尺寸非常好,并且将不同的子图像一起下采样(这将在 5×1 分辨率之后发生)无论如何都是没有意义的 。 因此,纹理采样操作允许用户指定要构造和使用的 mipmap 级别的最大数量。 在这种情况下,设置 max_mip_level=5 将停止在 5×1 mipmap 处并防止错误。
这是一个经过深思熟虑的设计选择,nvdiffrast 不仅会在无法下采样的 mipmap 大小处自动停止,而且要求用户在纹理尺寸不是 2 的幂时指定限制。 目标是避免由于纹理尺寸奇怪而导致预过滤纹理采样神秘地不起作用的错误。 如果 256×256 纹理提供了精美的预过滤纹理样本,255×255 纹理突然完全没有预过滤,而 254×254 纹理只进行了一点预过滤(一级),但没有更多,那将会令人困惑。
如果你计算自己的 mipmap,它们的大小必须遵循上述方案。 无需将 mipmap 一直指定为 1×1 分辨率,但栈可以在任何点结束,并且其工作方式与具有 max_mip_level 限制的内部构造的 mipmap 堆栈等效。 重要的是,用户提供的 mipmap 的渐变不会自动传播到基础纹理 - 自然如此,因为 nvdiffrast 对它们之间的关系一无所知。 相反,在用户提供的 mipmap 堆栈中指定 mip 级别的张量将接收自己的梯度。
3.5 使用 CUDA 与 OpenGL 进行光栅化
从 0.3.0 版本开始,PyTorch 上的 nvdifrast 支持使用 CUDA 或 OpenGL 执行光栅化操作。 早期版本和 Tensorflow 绑定仅支持 OpenGL。
当在 OpenGL 上执行光栅化时,我们使用 GPU 的图形管道来确定哪些三角形落在哪些像素上。 GPU 拥有非常高效的硬件来完成此任务—这是它们最初存在的理由—因此利用它是有意义的。 不幸的是,某些计算环境在设计时并未考虑到这一点,因此很难让 OpenGL 正确工作并与 CUDA 干净地互操作。 在 Windows 上,兼容性通常很好,因为运行 CUDA 所需的 GPU 驱动程序也包括 OpenGL 支持。 Linux 更为复杂,因为各种驱动程序可以单独安装,并且没有标准化的方法来访问硬件图形管道。
CUDA 中的光栅化几乎扭转了这些考虑因素。 在任何支持 CUDA 的平台上,兼容性显然不是问题。 另一方面,在大规模数据并行编程模型上正确有效地实现光栅化过程并非易事。 nvdiffrast 中的 CUDA 光栅化器遵循 Laine 和 Karras 的 HPG 2011 研究论文《GPU 上的高性能软件光栅化》中描述的方法。我们的代码基于该论文公开发布的 CUDA 内核,并进行了大量修改以支持当前的硬件架构并匹配 nvdiffrast 的需求。
CUDA光栅化器不支持大于2048×2048的输出分辨率,并且两个维度都必须是8的倍数。此外,一批中可以渲染的三角形数量限制在1600万个左右。 子像素精度限制为 4 位,并且深度剥离不如 OpenGL 准确。 内存消耗取决于许多因素。
很难预测哪个光栅器提供更好的性能。 对于复杂的网格和高分辨率,OpenGL 很可能会优于 CUDA 光栅化器,尽管它具有 CUDA 光栅化器所没有的某些开销。 对于简单的网格和低分辨率,CUDA 光栅化器可能更快,但它也有自己的开销。 测量实际数据、目标平台以及整个程序的性能是唯一确定的方法。
要在 CUDA 中运行光栅化,请创建 RasterizeCudaContext 并将其提供给?rasterize()?操作。 对于 OpenGL,请改用?RasterizeGLContext。 简单!
3.6 在多个 GPU 上运行
Nvdiffrast 支持 PyTorch 和 TensorFlow 中的多个 GPU 上的计算。 按照 PyTorch 中的约定,操作始终在输入张量所在的设备上执行。 所有 GPU 输入张量必须驻留在同一设备上,并且输出张量最终将位于同一设备上也就不足为奇了。 此外,光栅化操作要求为正确的设备创建其上下文。 在 TensorFlow 中,首次执行光栅化操作时,会在光栅化操作的设备上自动创建光栅化器上下文。
本节的其余部分仅适用于 OpenGL 光栅化器上下文。 除了确保它们位于正确的设备上之外,CUDA 光栅化器上下文不需要特殊考虑。
在 Windows 上,nvdiffrast 以每个进程只能执行一次的方式实现 OpenGL 设备选择 - 创建一个上下文后,所有未来的上下文都将位于同一 GPU 上。 因此,你不能期望使用 OpenGL 上下文在同一进程中的多个 GPU 上运行光栅化操作。 尝试这样做要么会导致崩溃,要么会导致严重的性能损失。 然而,使用 PyTorch,通常通过为每个 GPU 启动单独的进程来跨 GPU 分配计算,因此这不是一个大问题。 请注意,在同一进程中创建的任何 OpenGL 上下文(即使是 GUI 窗口之类的内容)也将阻止以后更改设备。 因此,如果你想在默认 GPU 之外的其他 GPU 上运行光栅化操作,请务必在初始化任何其他 OpenGL 支持的库之前创建其 OpenGL 上下文。
在 Linux 上,一切正常,你可以在同一进程内的多个设备上创建 OpenGL 光栅化器上下文。
关于 torch.nn.DataParallel 的注意事项:
PyTorch 提供 torch.nn.DataParallel 包装类,用于跨多个线程拆分小批量的执行。 不幸的是,这个类从根本上与依赖于 OpenGL 的操作不兼容,因为它在每次调用时都会生成一组新的线程(至少从 PyTorch 1.9.0 开始)。 在这些新线程中使用之前创建的 OpenGL 上下文,即使注意不在多个线程中使用相同的上下文,也会导致它们四处迁移,从而导致 GPU 内存使用量不断增长,GPU 利用率极低。 因此,我们建议不要使用 torch.nn.DataParallel 进行依赖于 OpenGL 上下文的光栅化操作。
值得注意的是,torch.nn.DistributedDataParallel 生成的子进程更加持久。 作为初始化的一部分,子进程必须创建自己的 OpenGL 上下文,因此它们不会遇到此问题。
3.7 渲染多个深度层
有时需要渲染具有部分透明表面的场景。 在这种情况下,仅找到最靠近相机的表面是不够的,因为你可能还需要知道它们后面的内容。 为此,nvdiffrast 支持深度剥离(depth peeling),使你可以为每个像素提取多个最接近的表面。
对于深度剥离,我们首先像往常一样对最近的表面进行光栅化。 然后,我们使用相同的几何形状执行第二次光栅化,但这一次我们剔除每个像素处所有先前渲染的表面点,有效地提取第二个最接近的深度层。 这可以根据需要重复多次,以便我们可以提取任意数量的深度层。 请参阅下图,了解每个深度层都经过阴影和抗锯齿处理的深度剥离结果示例:
左:第一个深度层。中:第二个深度层。右:第三个深度层。
深度剥离的 API 基于充当上下文管理器的?DepthPeeler?对象及其?rasterize_next_layer?方法。 第一次调用?rasterize_next_layer?相当于调用传统的?rasterize?函数,后续调用会报告更多深度层。 光栅化的参数在实例化?DepthPeeler?对象时指定。 具体来说,代码可能如下所示:
with nvdiffrast.torch.DepthPeeler(glctx, pos, tri, resolution) as peeler:
for i in range(num_layers):
rast, rast_db = peeler.rasterize_next_layer()
(process or store the results)如果你最终仅提取第一个深度层,则与基本光栅化操作相比,不会有任何性能损失。 换句话说,上面?num_layers=1?的代码运行速度与调用一次?rasterize?一样快。
仅 nvdiffrast 的 PyTorch 版本支持深度剥离。 出于实现原因,深度剥离保留了光栅化器上下文,以便在剥离正在进行时(即在 with 块内)无法执行其他光栅化操作。 因此,除非使用不同的上下文,否则你无法启动嵌套深度剥离操作或在 with 块内调用 rasterize。
为了完整起见,让我们注意以下小警告:
深度剥离依赖于深度值来区分表面点。 因此,剔除“先前渲染的表面点”实际上意味着剔除与先前通道中渲染到像素中的深度相同或更接近的所有表面点。 仅当你在匹配深度处具有多层几何体时,这才重要 - 如果你的几何体仅由两个完全重叠的三角形组成,那么你将在第一遍中看到其中一个,但在后续遍中永远不会看到另一个,因为它处于已经被认为完成的精确深度。
3.8 PyTorch 和 TensorFlow 之间的差异
Nvdifrast 可以在 PyTorch 和 TensorFlow 1.x 中使用; 如果有需求,后者可能会更改为 TensorFlow 2.x。 这些框架的运行方式略有不同,这反映在各自的 API 中。 稍微简化一下,在 TensorFlow 1.x 中,你可以用持久节点构建持久图,并通过它运行多批数据。 在 PyTorch 中,没有持久图或节点,而是为每批数据构建一个新的临时图,并在之后立即销毁。 因此,操作也没有持久状态。 有 torch.nn.Module 抽象用于具有持久状态的装饰操作,但我们不使用它。
因此,作为 TensorFlow 中 nvdifrast 操作持久状态一部分的内容必须由用户存储在 PyTorch 中,并根据需要提供给操作。 实际上,这是一个非常小的差异,在大多数情况下仅相当于几行代码。
作为示例,请考虑光栅化操作使用的 OpenGL 上下文。 为了使用硬件加速渲染,必须在内部发出 OpenGL 命令之前创建并切换到 OpenGL 上下文。 创建上下文是一项昂贵的操作,因此我们不想在每次调用光栅化操作时创建和销毁上下文。 在 TensorFlow 中,光栅化操作在第一次执行时会创建一个上下文,并将其存储在持久状态中以供以后重用。 在 PyTorch 中,用户必须使用单独的函数调用创建上下文,并将其作为参数提供给光栅化操作。
同样,如果你有恒定的纹理并且想要使用预过滤的纹理采样模式,则 mipmap 堆栈只需要计算一次。 在 TensorFlow 中,你可以指定纹理是恒定的,在这种情况下,纹理采样操作仅在第一次执行时计算 mipmap 堆栈并将其存储在内部。 在 PyTorch 中,你可以使用单独的函数调用计算一次 mipmap 堆栈,然后每次将其提供给纹理采样操作。 如果不这样做,该操作将在内部计算 mipmap 堆栈并随后将其丢弃。 如果你的纹理在每次迭代时都发生变化,这正是你想要的,即使纹理恒定也没有错,只是有点低效。
最后,这同样适用于称为拓扑哈希(topology hash)的事物,抗锯齿操作使用拓扑哈希来识别潜在的轮廓边缘。 它的内容仅取决于三角形张量,而不取决于顶点位置,因此如果拓扑是恒定的,则该辅助结构只需要构造一次。 和以前一样,在 TensorFlow 中这是在内部处理的,而在 PyTorch 中提供了一个单独的函数用于离线构建。
3.9 PyTorch 中的手动 OpenGL 上下文
首先,请注意手动处理 OpenGL 上下文是一个非常小的优化。 除非你已经满怀热情地分析和优化了你的代码,并且你的任务是尽可能发挥每一点性能,否则它几乎肯定不会相关。
在 TensorFlow 中,唯一的选择是让 nvdifrast 在内部处理 OpenGL 上下文管理。 这是因为 TensorFlow 在底层使用多个 CPU 线程,并且活动的 OpenGL 上下文是线程本地资源。
PyTorch 并不那么不可预测,并且默认情况下保持在同一 CPU 线程中(尽管 torch.utils.data.DataLoader 之类的东西确实会调用额外的 CPU 线程)。 因此,nvdifrast 允许用户选择以自动或手动模式处理 OpenGL 上下文切换。 默认为自动模式,其中光栅化操作始终在每次执行开始/结束时设置/释放上下文,就像我们在 TensorFlow 中所做的那样。 这确保了光栅化器将始终使用您提供的上下文,并且上下文不会保持活动状态,因此没有其他人可以扰乱它。
在手动模式下,用户承担设置和释放OpenGL上下文的责任。 大多数时候,如果你没有任何其他使用 OpenGL 的库,只需在创建上下文后设置一次上下文,并保持它的设置直到程序退出。 但是,请记住,活动 OpenGL 上下文是线程本地资源,因此需要在使用它的同一个 CPU 线程中设置它,并且不能在多个 CPU 线程中同时设置。
4、nvdiffrast示例
Nvdiffrast 附带了一组旨在支持研究论文的示例。 每个示例都有 PyTorch 和 TensorFlow 版本。 版本之间的命令行参数、日志记录格式等详细信息可能不相同,通常应将 PyTorch 版本视为确定的。 下面的命令行示例适用于 PyTorch 版本。
所有 PyTorch 示例都支持在 CUDA 和 OpenGL 光栅化器上下文之间进行选择。 默认是在 CUDA 中进行光栅化,并通过指定命令行选项?--opengl?来切换到 OpenGL。
使用 OpenGL 光栅化时,在 Linux 上使用?--display-interval?参数启用交互式显示可能会失败。 这是因为交互式显示窗口是使用 OpenGL 显示的,而在 Linux 上,这与 nvdiffrast 中的内部 OpenGL 光栅化相冲突。 假设系统中正确安装了 OpenGL(用于显示窗口),则使用 CUDA 上下文应该可以工作。 我们的 Dockerfile 设置为仅支持无头渲染,因此无法显示交互式结果窗口。
4.1 triangle.py
这是一个最小的示例,它渲染三角形并将生成的图像保存到当前目录中的文件 (tri.png) 中。 运行此命令应该是验证所有设置是否正确的第一步。 渲染是使用光栅化和插值操作完成的,因此获得正确的输出图像意味着 OpenGL(如果在命令行上指定)和 CUDA 都在幕后按预期工作。
这是你必须在命令行上指定?--cuda?或?--opengl?的唯一示例。 其他示例默认使用 CUDA 光栅化并仅提供?--opengl?选项。
命令行示例:
python triangle.py --cuda
python triangle.py --opengl期望的输出如下:
4.2 cube.py
在此示例中,我们从半随机初始化状态开始优化立方体网格的顶点位置和颜色。 该优化基于极低分辨率(例如 4×4、8×8 或 16×16 像素)下的图像空间损失。 此示例的目标是检查当三角形大小只有几个像素时的几何收敛率。 它说明抗锯齿操作尽管是近似的,但即使在 4×4 分辨率下也能产生足够好的位置梯度,以指导优化达到目标。
命令行示例:
python cube.py --resolution 16 --display-interval 10期望的结果如下:

左:交互视图。 右:渲染管线。
上图显示了示例的实时视图。 顶行显示低分辨率渲染图像和计算图像空间损失的参考图像。 底行以高分辨率显示当前网格(和颜色)和参考网格,以便可以更容易地在视觉上看到收敛。
在管道图中,绿色框表示 nvdifrast 操作,而蓝色框是其他计算。 红色框是学习的张量,灰色是未学习的张量或其他数据。
4.3 earth.py
此示例的目标是比较使用和不使用预过滤纹理采样的纹理收敛性(convergency)。 纹理是根据随机方向和随机距离的高质量参考渲染的图像空间损失来学习的。 禁用预过滤时,由于锯齿导致梯度更新不稳定,因此无法正确学习纹理。 与启用预过滤的学习相比,这表明纹理的 PSNR 更差。 请参阅论文以进行进一步讨论。
命令行示例:
#No prefiltering, bilinear interpolation.
python earth.py --display-interval 10
#Prefiltering enabled, trilinear interpolation.
python earth.py --display-interval 10 --mip

左:交互视图,禁用预过滤。 右:渲染管线。
交互式视图显示映射到网格上的当前纹理,带有或不带有通过命令行参数指定的预过滤纹理采样。 在此示例中,没有执行抗锯齿,因为我们没有学习顶点位置,因此不需要与它们相关的梯度。
4.4 envphong.py
与之前的顶点颜色或纯纹理相比,在此示例中使用了更复杂的着色模型。 在这里,我们学习了给定已知网格的反射环境图和 Phong BRDF 模型的参数。 该优化基于随机方向上的参考渲染的图像空间损失。 镜面反射加上 Phong BRDF 的着色模型在物理上并不合理,但它作为一个相当简单的稻草人工作,不可能用以前将光栅化、着色、照明和纹理捆绑在一起的可微光栅器来实现。 该示例还说明了如何使用立方体映射来表示球形域中的学习纹理。
命令行示例:
python envphong.py --display-interval 10
左:交互视图。 右:渲染管线。
在交互视图中,我们看到使用当前环境贴图和 Phong BRDF 参数的渲染,两者在优化过程中逐渐得到改善。
4.5 pose.py
基于图像空间损失的姿态拟合(pose fitting)是可微渲染中的经典任务。 在此示例中,我们使用具有不同颜色侧面的简单立方体来解决姿态优化问题。 我们在论文中详细介绍了优化方法,但简而言之,它结合了初始化阶段的无梯度贪婪优化和微调阶段的基于梯度的优化。
命令行示例:
python pose.py --display-interval 10期望结果如下:

交互视图
交互式视图从左到右显示:目标姿势、最佳找到的姿势和当前姿势。 实时查看时,优化的两个阶段清晰可见。 在第一阶段,当找到更好的初始化时,最佳姿势会间歇性更新。 在第二阶段,解决方案通过基于梯度的优化平滑地收敛到目标。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 10_LearnOpenGL 坐标系统
- ARMv8-AArch64 的异常处理模型详解之异常类型 Exception types
- 【AivaAI】做音乐,无人能比它更专业
- Python常用类库
- 企业如何建立价值评估体系?
- 052:vue重新发布,软件热更新方面的一点经验示例
- 第三十三章 控制到 XML 模式的映射 - 其他支持 XML 的类到 XML 类型的映射
- 构建一个树
- Dash中的callback的使用 多input 6
- Docker 网络