AWS 专题学习 P8 (ECS、EKS、Lambda、CloudFront、DynamoDB)
发布时间:2024年01月21日
文章目录
- 什么是 Docker?
- Amazon ECS
- Amazon ECR
- Amazon EKS 概述
- Serverless 概述
- Amazon DynamoDB
什么是 Docker?
- Docker 是一个用于部署应用程序的软件开发平台
- Docker 容器可以在任何操作系统上运行,应用程序运行在容器中
- 应用程序运行过程相同,无论它们在何处运行 —> 行为可预测
- 无兼容性问题,更易于维护和部署
- 减少工作量
- 使用案例:微服务架构、将应用程序从本地直接迁移到 AWS 云,…
操作系统上的 Docker
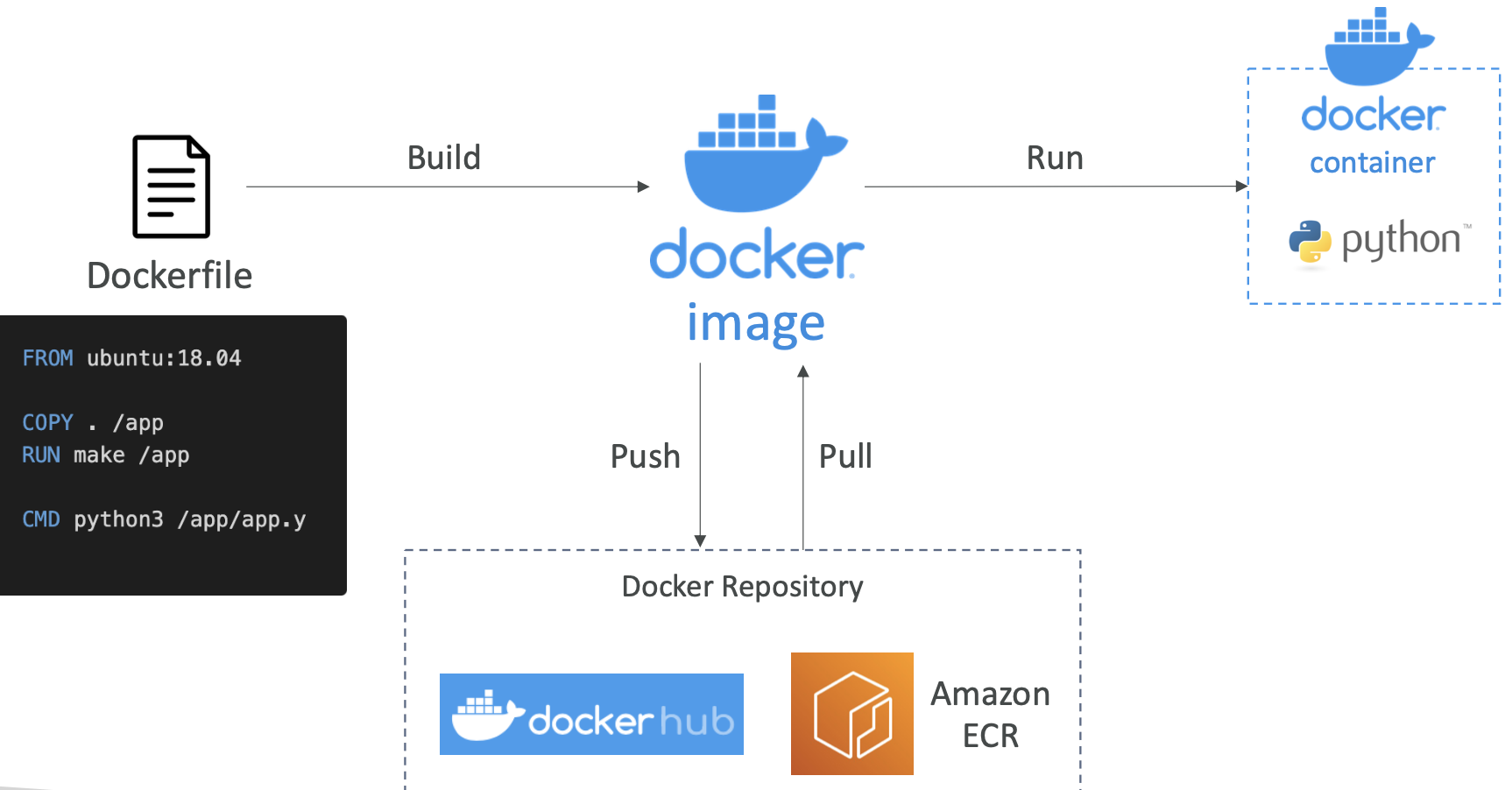
Docker 镜像存储
- Docker 镜像存储在 Docker Repositories
- Docker Hub (https://hub.docker.com)
- 公共存储库
- 查找多种技术或操作系统的基础映像(例如 Ubuntu、MySQL…)
- Amazon ECR(Amazon Elastic Container Registry)
- 私有存储库
- 公共存储库(Amazon ECR Public Gallery: https://gallery.ecr.aws)
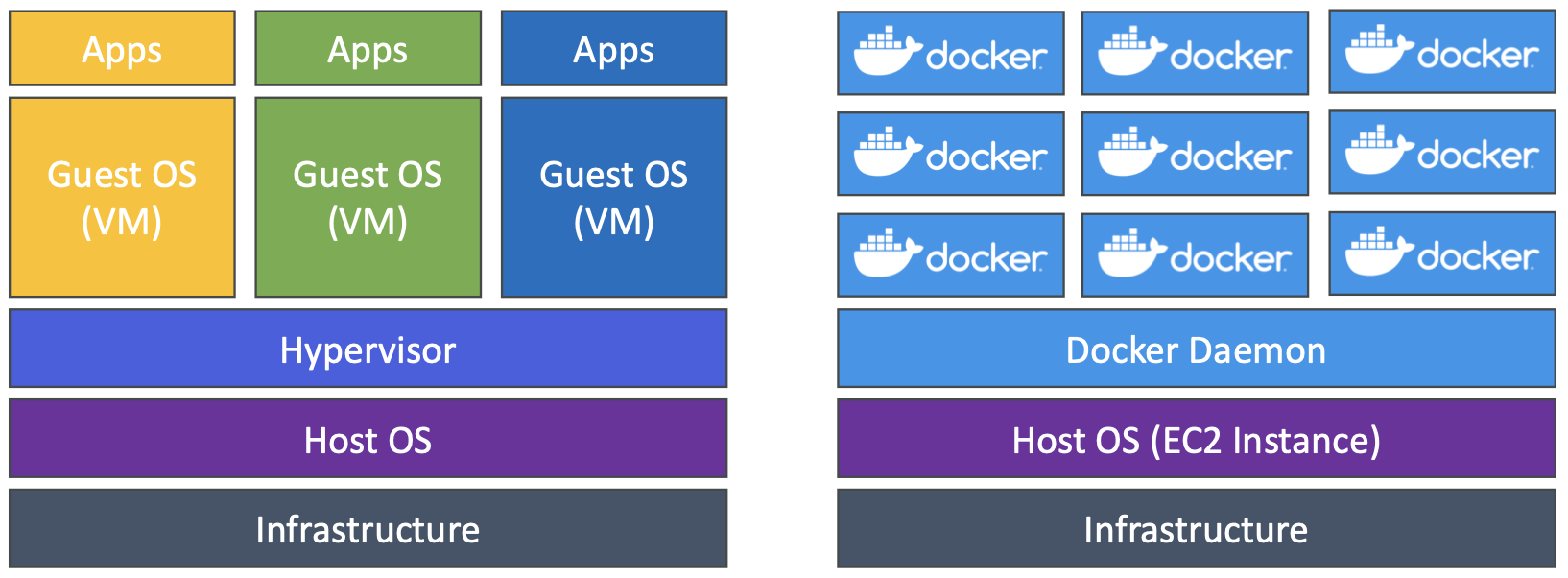
Docker vs. Virtual Machines
- Docker 趋近于一种虚拟化技术,但并不完全是
- 区别:与主机共享资源 => 一台服务器上有许多容器
Docker 入门
AWS 中的 Docker Containers Management
- Amazon 弹性容器服务 (Amazon ECS)
- Amazon 自己的容器平台
- Amazon Elastic Kubernetes 服务 (Amazon EKS)
- Amazon 托管的 Kubernetes(开源)
- AWS Fargate
- Amazon 自己的无服务容器平台
- 可与 ECS 和 EKS 配合使用
- Amazon ECR:
- 存储容器的镜像
Amazon ECS
EC2 Launch Type
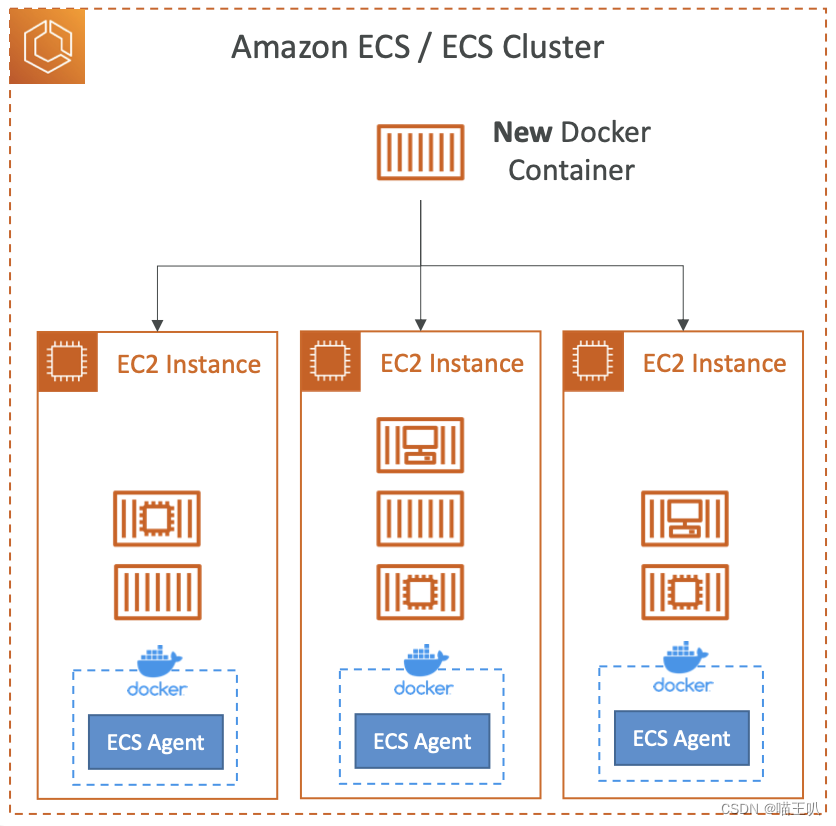
- ECS = 弹性容器服务
- 在 AWS 上启动 Docker 容器 = 在 ECS 集群上启动 ECS Tasks
- EC2 启动类型:用户必须配置和维护基础设施(EC2 实例)
- 每个 EC2 实例必须运行 ECS Agent 才能在 ECS 集群中注册
- AWS 负责启动/停止容器
Fargate Launch Type
- 在 AWS 上启动 Docker 容器
- 用户无需配置基础设施(无需管理 EC2 实例)
- 一切都是无服务的!
- 用户只需创建任务定义
- AWS 只是根据用户需要的 CPU/RAM 为用户运行 ECS Tasks
- 如果要扩展,只需增加 Task 数量即可。 简单 —— 不会有更多的 EC2 实例
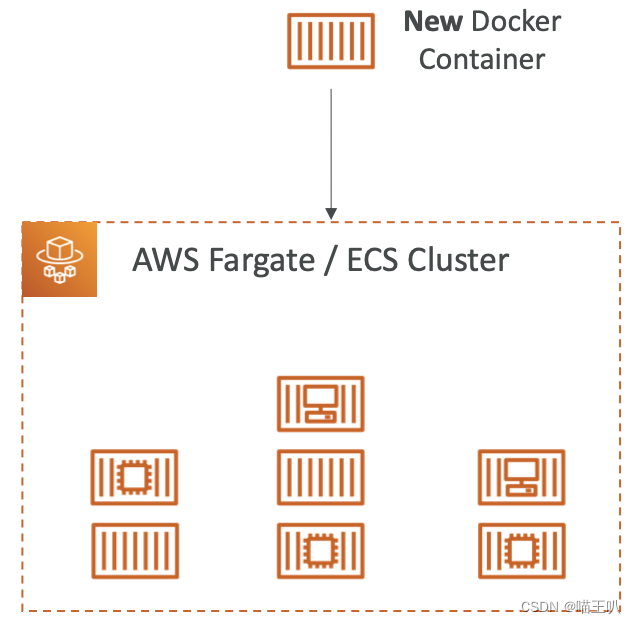
ECS 的 IAM Roles
- EC2 实例配置文件(仅限 EC2 启动类型):
- 由 ECS Agent 使用
- 对 ECS 服务进行 API 调用
- 将容器日志发送到 CloudWatch Logs
- 从 ECR 拉取 Docker 镜像
- 引用 Secrets Manager 或 SSM 参数存储中的敏感数据
- ECS Task Role:
- 允许每个任务具有特定的角色
- 对不同 ECS 服务使用不同的角色
- Task Role 是在 Task Definition 中定义
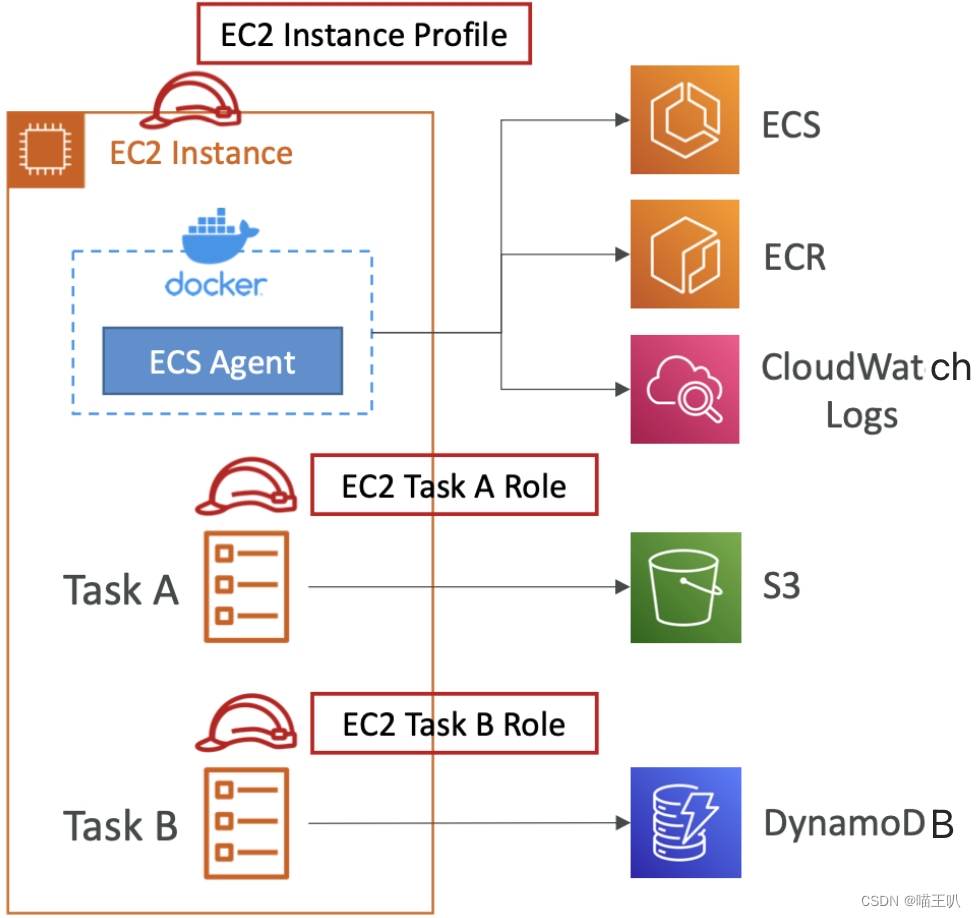
Load Balancer Integrations
- 应用程序负载均衡器(ALB):支持并适用于大多数用例
- 网络负载均衡器(NLB):建议仅用于高吞吐量/高性能用例,或将其与 AWS Private Link 配对
- 弹性负载均衡器(ELB):支持但不推荐(无高级功能 - 如 Fargate)
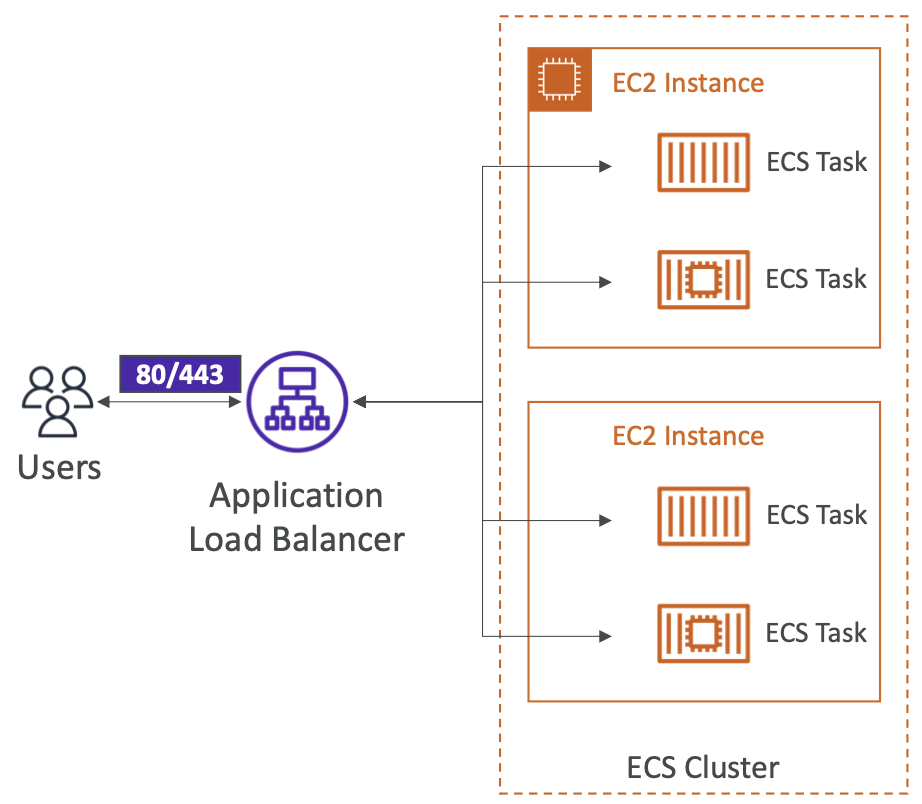
Data Volumes (EFS)
- 将 EFS 文件系统挂载到 ECS Tasks 上
- 适用于 EC2 和 Fargate 启动类型
- 在任何 AZ 中运行的任务将共享 EFS 文件系统中的相同数据
- Fargate + EFS = Serverless
- 使用案例:EFS 作为多可用区共享存储,实现容器的持久化
- 注意:
- Amazon S3 无法作为文件系统安装
- Amazon S3 无法作为文件系统安装
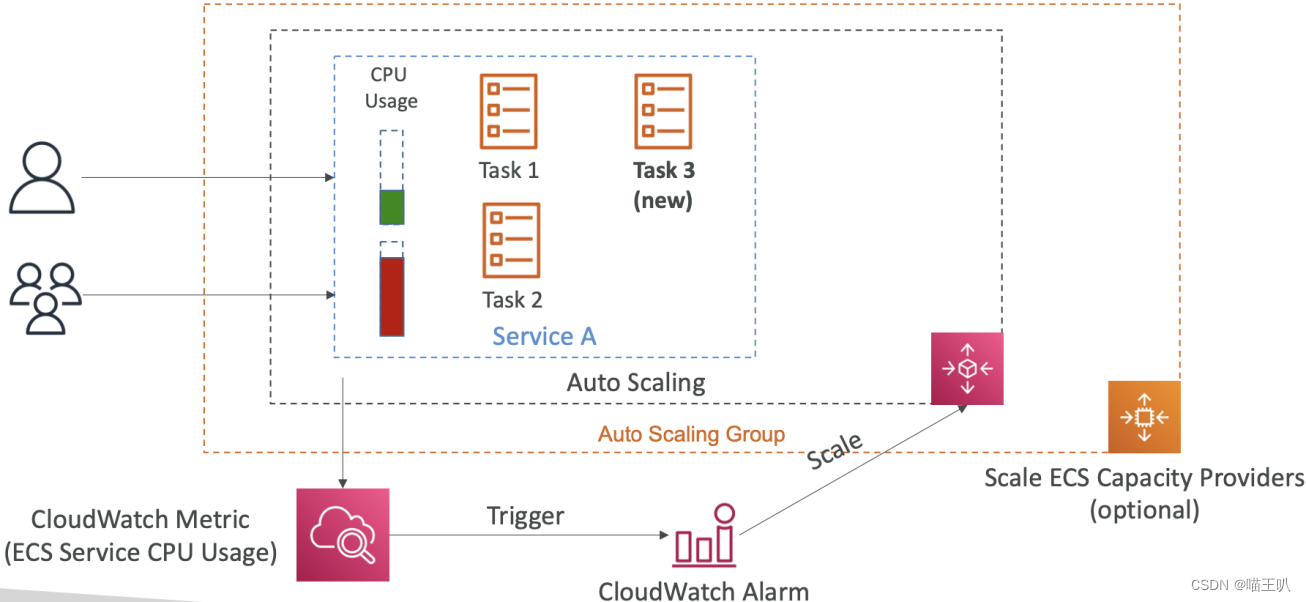
ECS Service Auto Scaling
- 自动增加/减少所需的 ECS Tasks 数量
- ECS 实现自动扩展的方式是使用 AWS Application Auto Scaling 服务
- ECS 服务平均 CPU 利用率
- ECS 服务 RAM 上的 平均内存利用率规模
- 每个目标的 ALB 请求计数 (来自 ALB 的指标)
- 目标跟踪(Target Tracking): 根据特定 CloudWatch 指标的目标值进行扩展
- 步进扩展(Step Scaling): 根据指定的 CloudWatch 警报进行扩展
- 计划扩展(Scheduled Scaling): 根据指定日期/时间进行扩展(可预测的变化)
- ECS Service Auto Scaling(任务级别)≠ EC2 Auto Scaling(EC2 实例级别)
- Fargate Auto Scaling 更容易设置(因为无服务)
EC2 Launch Type – Auto Scaling EC2 实例
- 通过添加底层 EC2 实例来适应 ECS 服务扩展
- Auto Scaling Group (ASG)
- 根据CPU 利用率扩展用户的 ASG
- 随着时间的推移添加 EC2 实例
- ECS Cluster Capacity Provider
- 用于自动配置和扩展 ECS Tasks的基础设施
- 通常与 ASG 配合使用
- 当用户缺少容量(CPU、RAM…)时添加 EC2 实例
ECS Scaling - Service CPU 使用示例
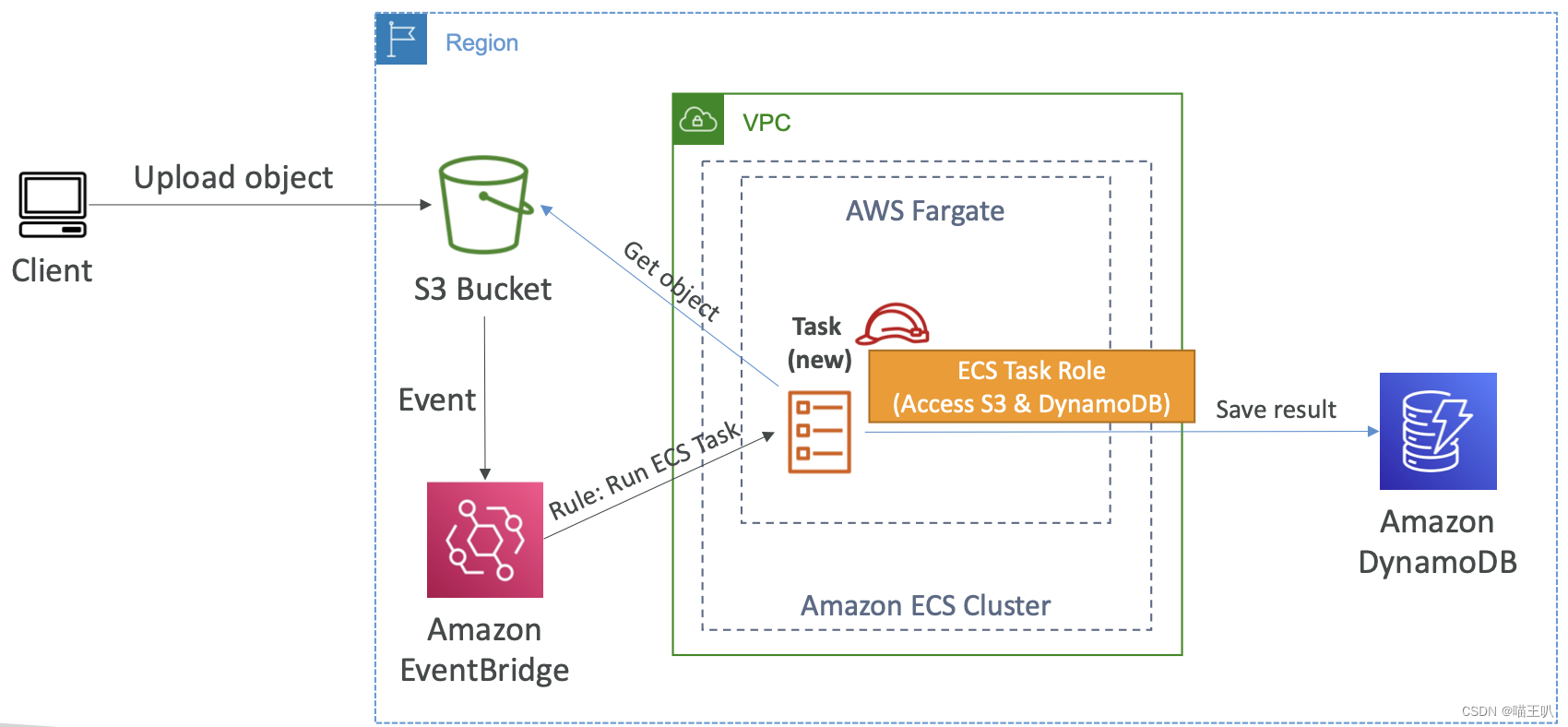
Event Bridge 调用的 ECS Tasks
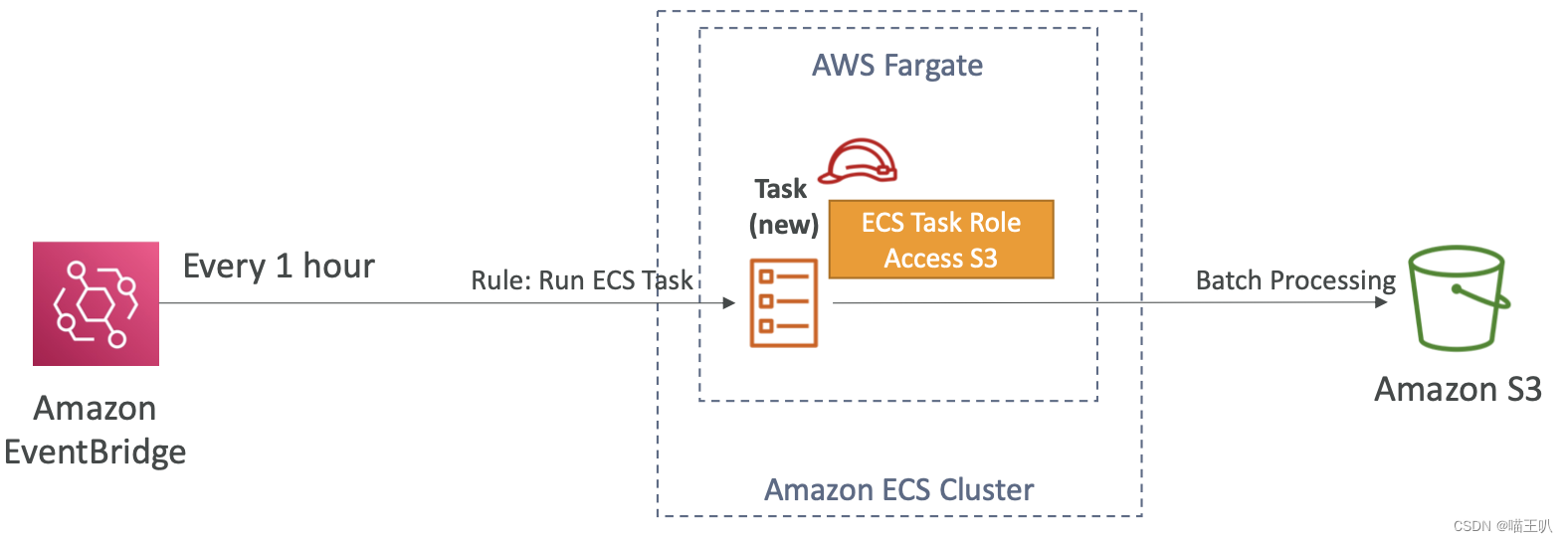
Event Bridge Schedule 调用的 ECS Tasks
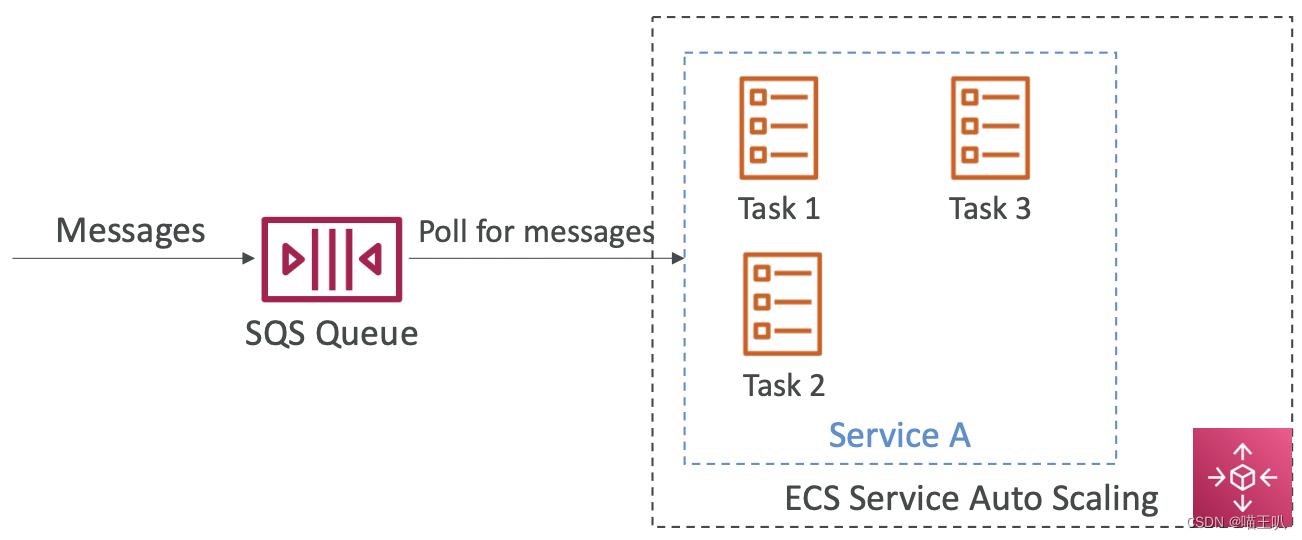
ECS – SQS 队列示例
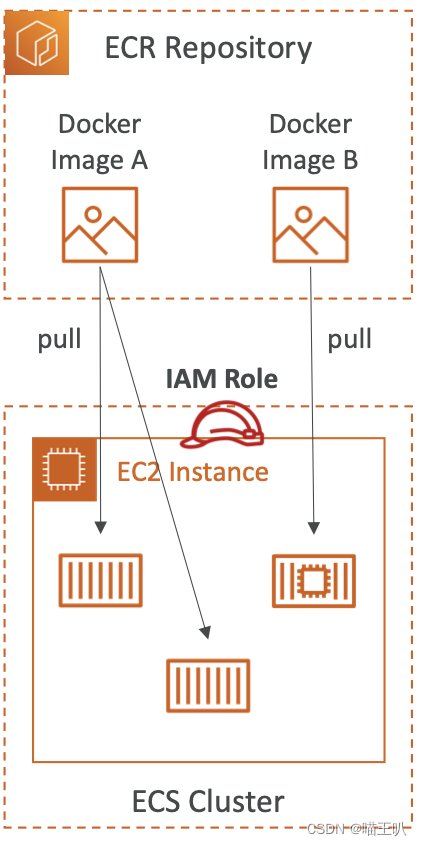
Amazon ECR
- ECR = Elastic Container Registry
- 在 AWS 上存储和管理 Docker 映像
- 私有和公共存储库(Amazon ECR 公共库 https://gallery.ecr.aws)
- 与 ECS 完全集成,由 Amazon S3 支持
- 访问通过 IAM 控制(权限错误 => 策略)
- 支持镜像漏洞扫描、版本控制、镜像标签、镜像生命周期…
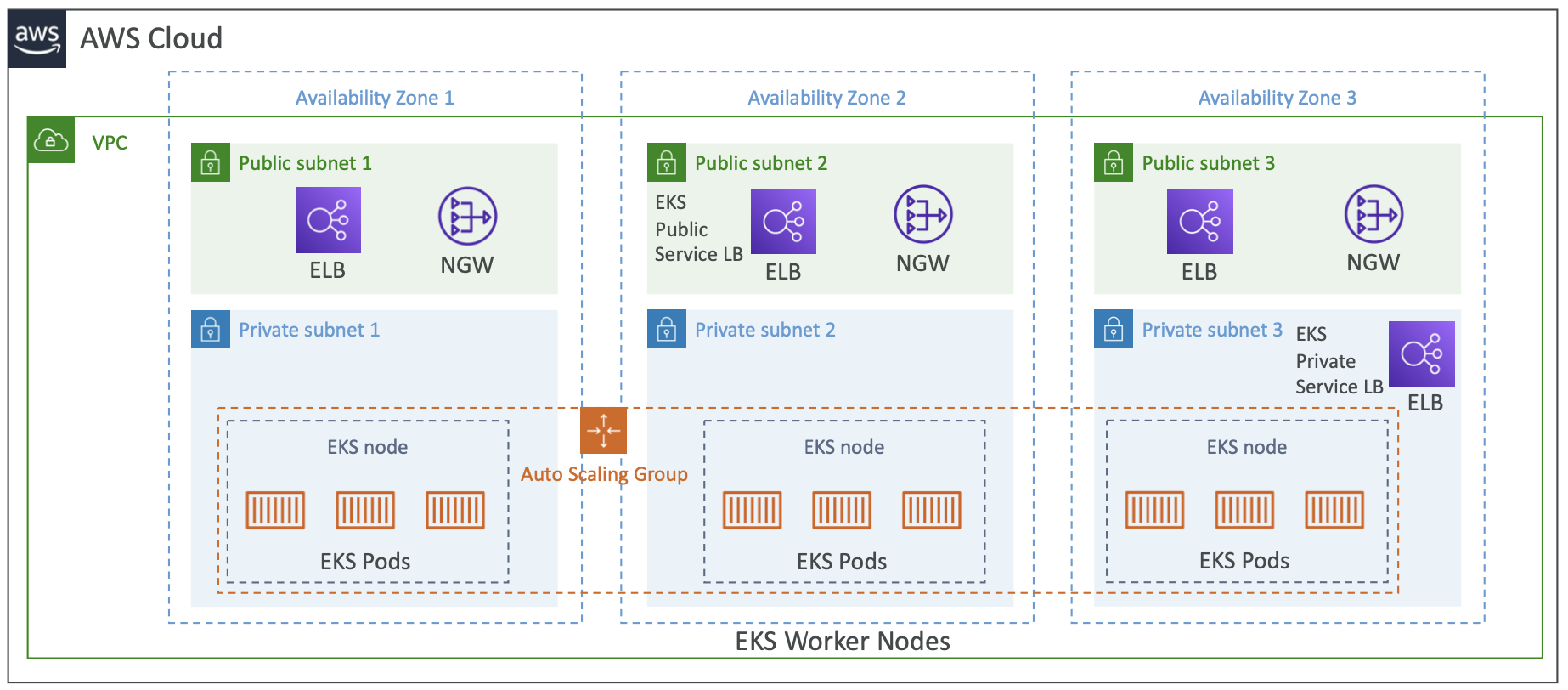
Amazon EKS 概述
- Amazon EKS = Amazon Elastic Kubernetes Service
- 这是在 AWS 上启动托管 Kubernetes 集群的一种方法
- Kubernetes 是一个开源系统,用于自动部署、扩展和管理容器化(通常是 Docker)应用程序
- EKS 是 ECS 的一种替代方案,目标类似但 API 不同
- EKS 支持 EC2(如果要部署工作节点),也支持 Fargate(如果要部署无服务器容器)。
- 使用案例:如果用户的公司已在本地或其他云中使用 Kubernetes,并且希望使用 Kubernetes 迁移到 AWS
- Kubernetes 与云无关(可以在任何云中使用 – Azure、GCP…)
- 对于多个区域,需要在每个区域部署一个 EKS 集群
- 使用 CloudWatch Container Insights 收集日志和指标
Amazon EKS - Diagram
Amazon EKS – 节点类型
- 受托管节点组
- 为用户创建和管理节点(EC2 实例)
- 节点是EKS 管理的ASG 的一部分
- 支持按需实例或 Spot 实例
- 自我管理节点
- 由用户创建并注册到 EKS 集群并由 ASG 管理的节点
- 用户可以使用预构建的 AMI - Amazon EKS 优化的 AMI
- 支持按需实例或 Spot 实例
- AWS Fargate
- 无需维护; 没有管理节点
Amazon EKS – 数据卷
- 需要在 EKS 集群上指定 StorageClass 清单
- 利用 Container Storage Interface (CSI) 兼容的驱动程序
- 支持…
- Amazon EBS
- Amazon EFS(与 Fargate 配合使用)
- Amazon FSx for Lustre
- 适用于 NetApp ONTAP 的 Amazon FSx
AWS App Runner
- 完全托管的服务,可以轻松大规模部署 Web 应用程序和 API
- 无需基础架构经验
- 从源代码或容器映像开始
- 自动构建和部署 Web 应用程序
- 自动扩展、高可用性、负载均衡器、加密
- VPC 访问支持
- 连接到数据库、缓存和消息队列服务
- 使用案例:Web 应用程序、API、微服务、快速生产部署
Serverless 概述
什么是无服务?
- 无服务是一种新范式,开发人员无需再管理服务器…
- 只部署xx代码、xx功能!
- 最初,无服务 == FaaS(函数即服务)
- 无服务由 AWS Lambda 开创,但现在还包括任何托管内容:“数据库、消息传递、存储等”。
AWS 中的无服务
- AWS Lambda
- DynamoDB
- AWS Cognito
- AWS API Gateway
- Amazon S3
- AWS SNS & SQS
- AWS Kinesis Data Firehose
- Aurora Serverless
- Step Functions
- Fargate
 |
|
为什么选择 AWS Lambda
- Amazon EC2
- 云中的虚拟服务器
- 受 RAM 和 CPU 限制
- 连续运行
- 扩展意味着需要人工干预去添加/删除服务器
- Amazon Lambda
- 虚拟功能——无需管理服务器!
- 受时间限制 - 执行时间短
- 按需运行
- 缩放是自动的!
AWS Lambda 的优点
- 轻松定价:
- 按请求和计算时间付费
- 提供免费的使用额度,包括1,000,000个AWS Lambda请求和400,000 GB的计算时间
- 与整个 AWS 服务套件集成
- 与多种编程语言集成
- 通过AWS CloudWatch 轻松监控
- 轻松为函数获取更多资源(高达 10GB RAM!)
- 增加 RAM 也能提高CPU和网络性能
AWS Lambda 语言支持
- Node.js (JavaScript)
- Python
- Java(兼容 Java 8)
- C#(.NET 核心)
- Go 语言
- C# / Powershell
- 红宝石
- 自定义运行时 API(社区支持,例如 Rust)
- Lambda 容器映像
- 容器映像必须实现Lambda Runtime API
- ECS / Fargate 是运行任意 Docker 镜像的首选
AWS Lambda 集成
Main ones
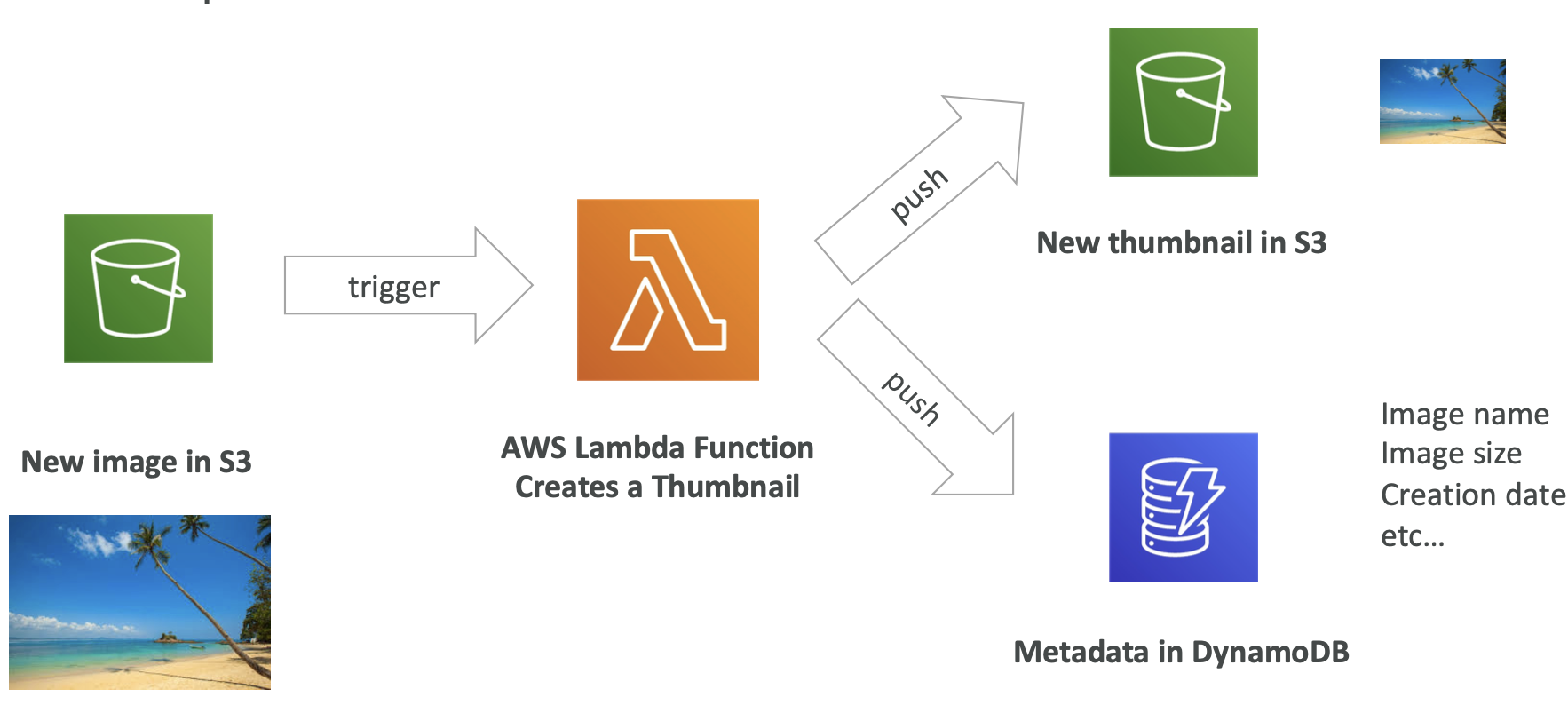
示例:无服务缩略图创建
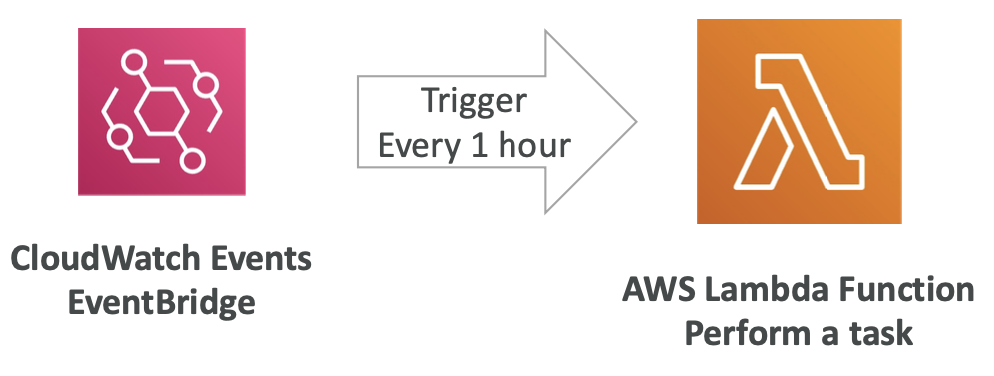
示例:无服务 CRON 作业
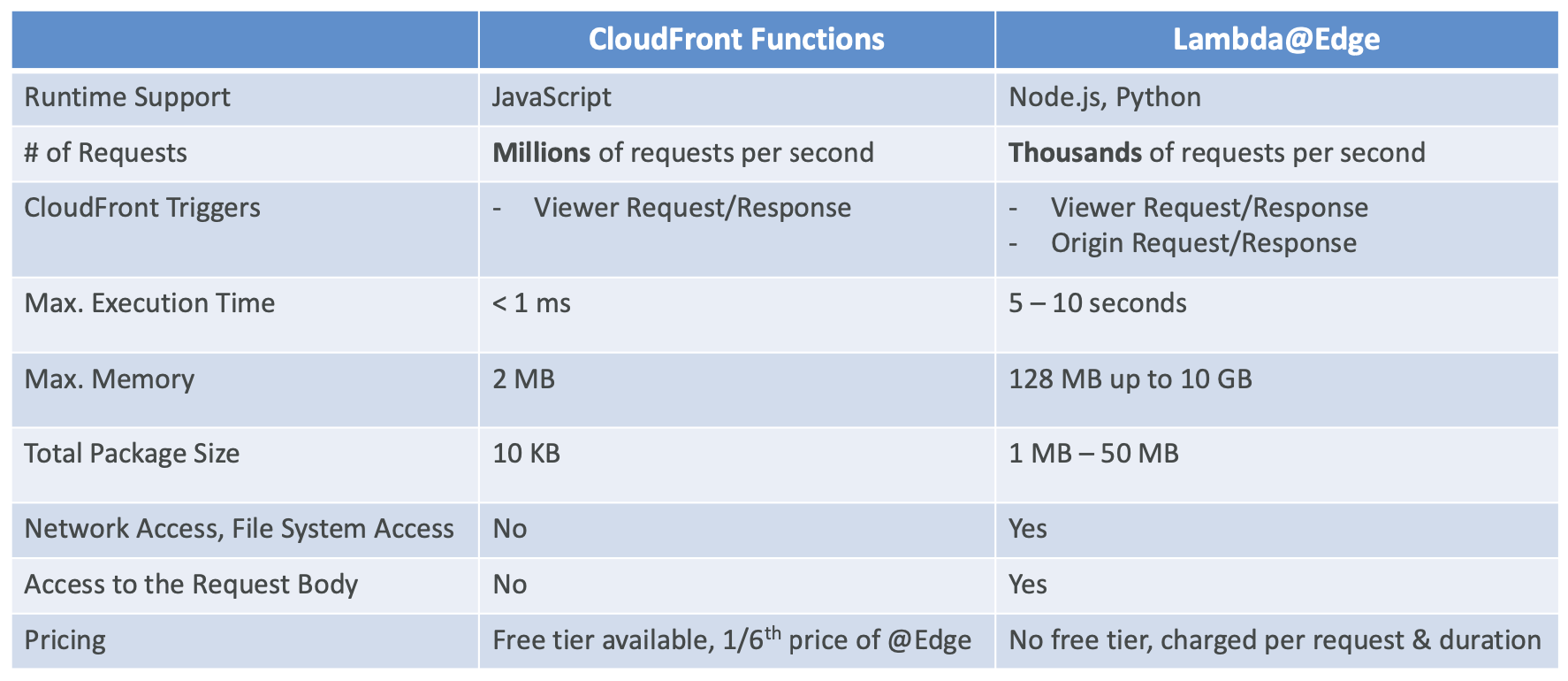
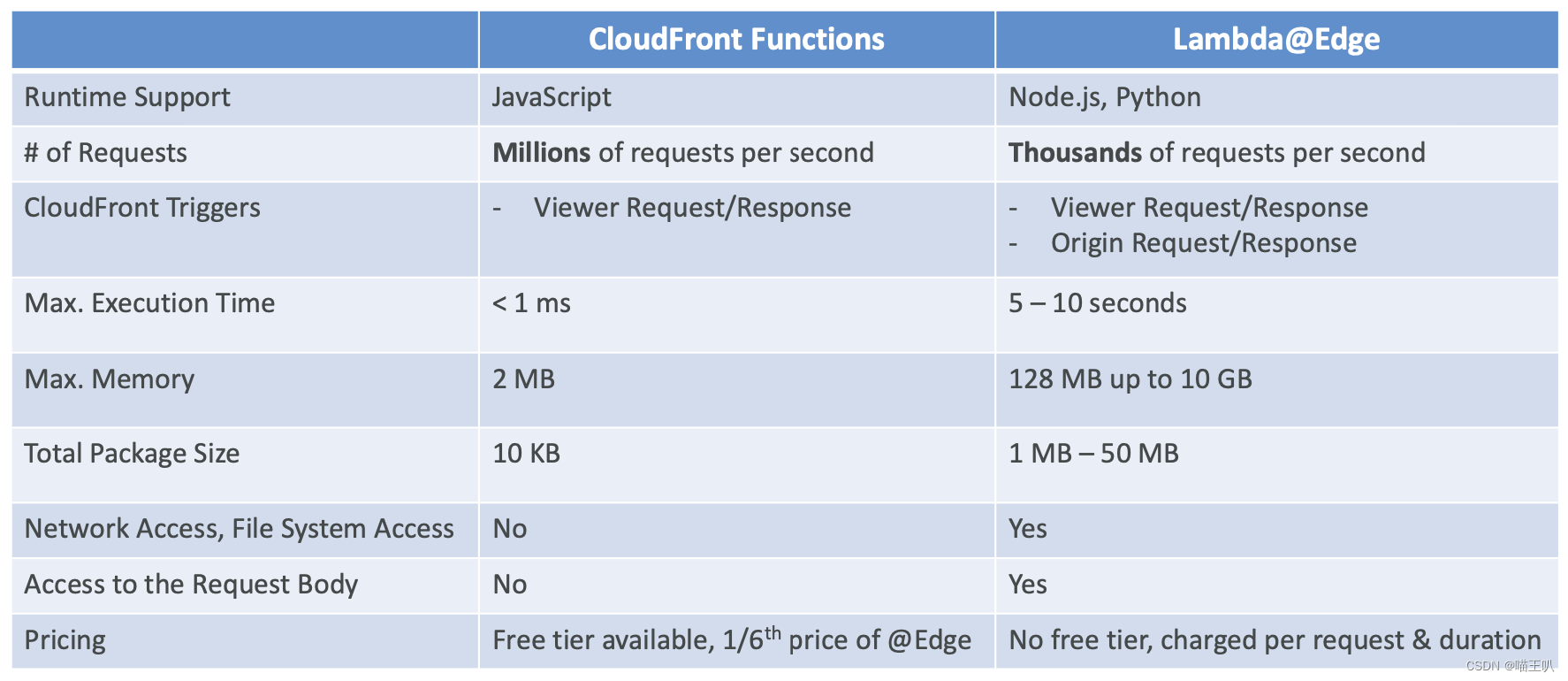
AWS Lambda 定价:示例
- 用户可以在此处找到总体定价信息:
https://aws.amazon.com/lambda/pricing/ - 按调用量付费:
- 前 1,000,000 个请求免费
- 此后每 100 万个请求 0.20 美元(每个请求 0.0000002 美元)
- 按持续时间付费:(以 1 毫秒为增量)
- 每月免费 400,000 GB-秒 的计算时间
- exp: 400,000 秒(如果函数为 1GB RAM)
- exp: 3,200,000 秒(如果函数为 128 MB RAM)
- 此后 600,000 GB 秒 1.00 美元
- 每月免费 400,000 GB-秒 的计算时间
- 运行 AWS Lambda 通常非常便宜,因此非常受欢迎
AWS Lambda 的限制(per region)
- 执行:
- 内存分配:128 MB ~ 10GB(1 MB 增量)
- 最长执行时间:900 秒(15 分钟)
- 环境变量 (4 KB)
- “功能容器”中的磁盘容量(/tmp):512 MB 至 10GB
- 并发执行:1000(可以增加)
- 部署:
- Lambda 函数部署大小(压缩的.zip):50 MB
- 未压缩部署的大小(代码+依赖项):250 MB
- 可以使用/tmp目录在启动时加载其他文件
- 环境变量的大小:4 KB
Customization At The Edge
- 许多现代应用程序在边缘执行某种形式的逻辑
- 边缘功能:
- 用户编写并附加到 CloudFront 分配的代码
- 靠近用户运行以最大限度地减少延迟
- CloudFront 提供两种类型:CloudFront Functions 和 Lambda@Edge
- 用户无需管理全球部署的任何服务器
- 使用案例:定制CDN 内容
- 仅按使用量付费
- 完全无服务
CloudFront Functions vs. Lambda@Edge
用例:
- 网站安全和隐私
- 边缘的动态 Web 应用程序
- 搜索引擎优化(SEO)
- 智能路由跨源和数据中心
- 边缘机器人缓解
- 实时图像转换
- A/B 测试
- 用户身份验证和授权
- 用户优先级
- 用户跟踪和分析
CloudFront Functions
- 用 JavaScript 编写的轻量级函数
- 适用于大规模、延迟敏感的 CDN 定制
- 亚毫秒级启动时间,每秒数百万个请求
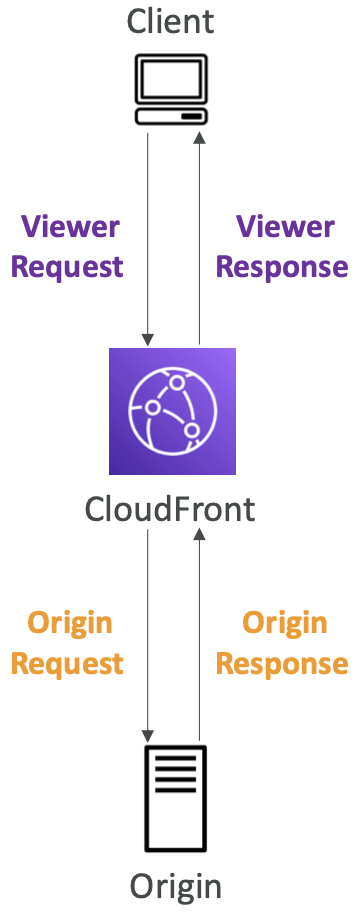
- 用于更改查看器请求和响应:
- 查看者请求:CloudFront 收到查看者的请求后
- 查看器响应:在 CloudFront 将响应转发给查看器之前
- CloudFront 的本机功能(完全在 CloudFront 内管理代码)
Lambda@Edge
- 用 NodeJS 或 Python 编写的 Lambda 函数
- 可扩展到每秒 1000 个请求
- 用于更改 CloudFront 请求和响应:
- 查看者请求:CloudFront 收到查看者的请求后
- 源请求:在 CloudFront 将请求转发到源之前
- 源响应:CloudFront 收到来自源的响应后
- 查看器响应:在 CloudFront 将响应转发给查看器之前
- 在一个 AWS 区域 (us-east-1) 中编写用户的函数,然后 CloudFront 复制到其位置
总结
CloudFront Functions
- 缓存键规范化
- 转换请求属性(标头、cookie、查询字符串、URL)以创建最佳缓存键
- Header 操作
- 在请求或响应中插入/修改/删除 HTTP 标头
- URL 重写或重定向
- 请求身份验证和授权
- 创建并验证用户生成的令牌(例如 JWT)以允许/拒绝请求
- 创建并验证用户生成的令牌(例如 JWT)以允许/拒绝请求
Lambda@Edge
- 较长的执行时间(几毫秒)
- 可调节CPU或内存
- 用户的代码依赖于第三个库(例如,用于访问其他 AWS 服务的 AWS SDK)
- 网络访问以使用外部服务进行处理
- 文件系统访问或对 HTTP 请求正文的访问
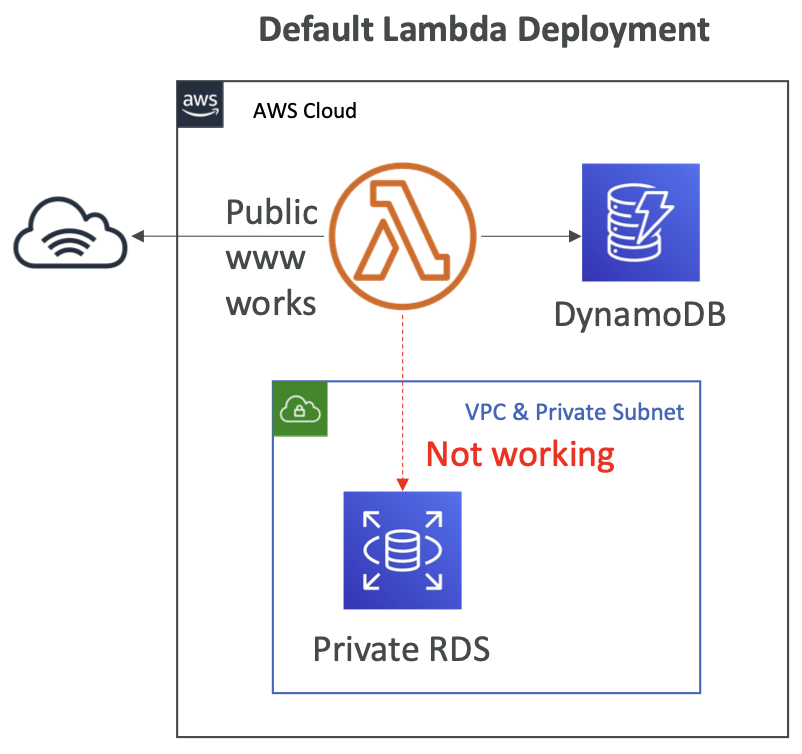
默认的 Lambda
- 默认情况下,用户的 Lambda 函数在用户自己的 VPC 外部(在 AWS 拥有的 VPC 中)启动
- 因此,它无法访问用户的VPC 中的资源(RDS、ElastiCache、内部ELB…)
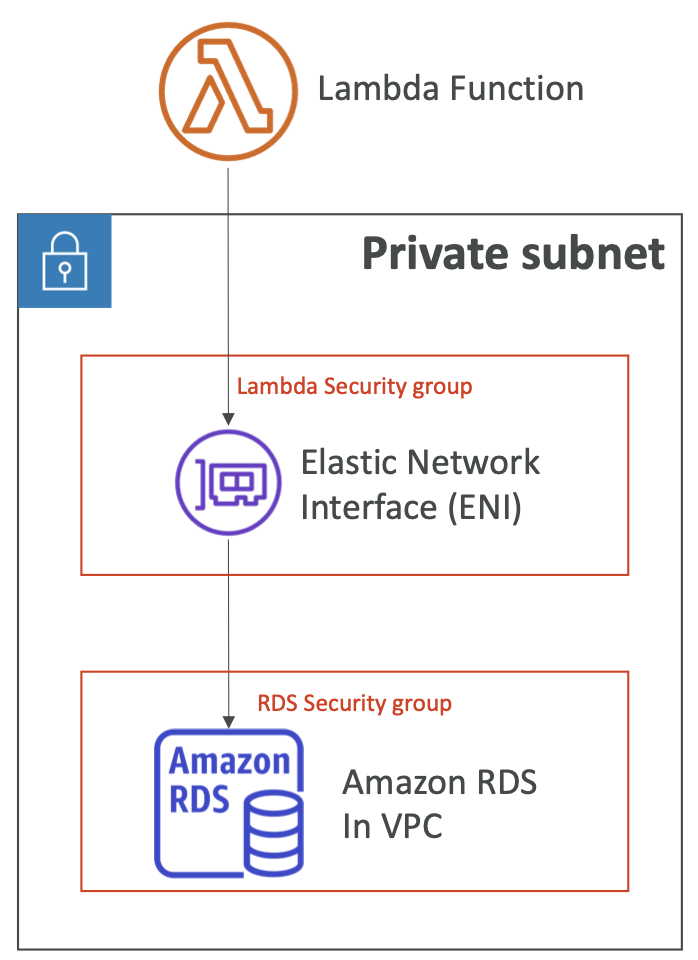
VPC 中的 Lambda
- 用户必须定义 VPC ID、子网和安全组
- Lambda 将在用户的子网中创建 ENI(弹性网络接口)
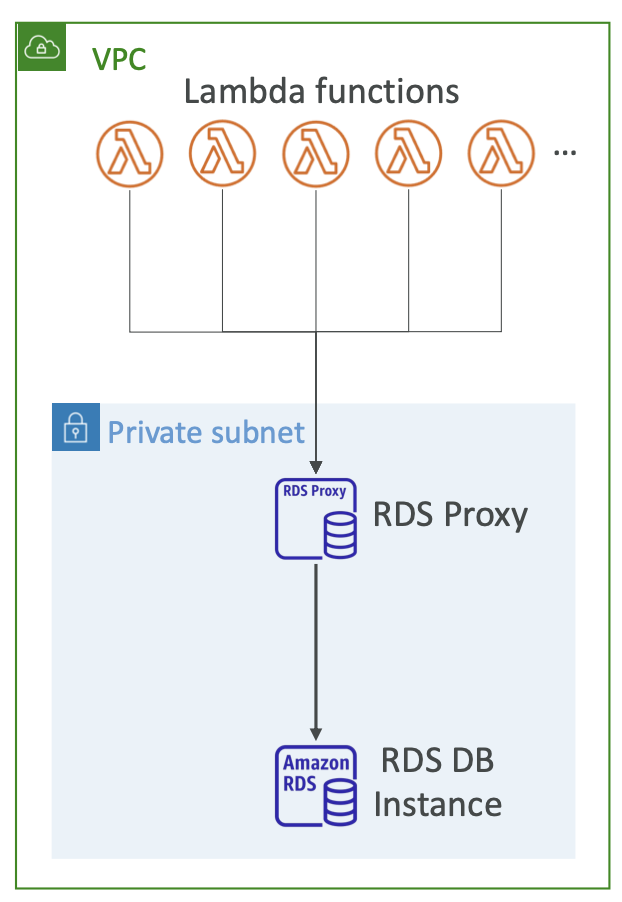
带有 RDS 代理的 Lambda
- 如果 Lambda 函数直接访问用户的数据库,它们可能会在高负载下打开太多连接
- RDS 代理
- 通过池化和共享数据库连接来提高可扩展性
- 通过减少 66% 的故障转移时间并保留连接来提高可用性
- 通过在 Secrets Manager 中强制执行 IAM 身份验证和存储凭证来提高安全性
- Lambda 函数必须部署在用户的 VPC 中,因为 RDS Proxy 永远无法公开访问
Amazon DynamoDB
- 完全托管、高度可用,可跨多个可用区进行复制
- NoSQL 数据库,具有事务支持
- 可扩展到海量工作负载、分布式数据库
- 每秒数百万个请求、数万亿行、数百TB 存储
- 快速且一致的性能(个位数毫秒)
- 与 IAM 集成以实现安全、授权和管理
- 低成本和自动扩展功能
- 无需维护或修补,始终可用
- 标准和不频繁访问 (IA) 表类
DynamoDB - 基础知识
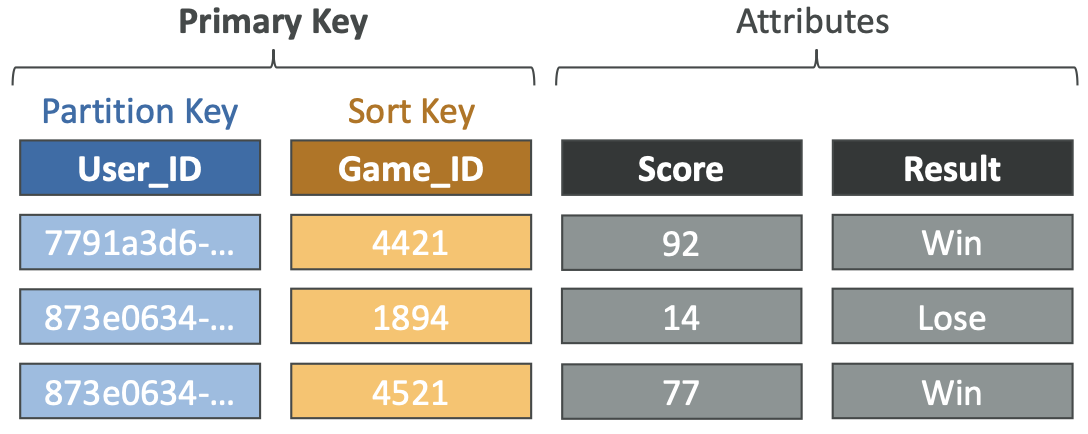
- DynamoDB 由表组成
- 每个表都有一个主键(必须在创建时决定)
- 每个表可以有无限数量的项目(= 行)
- 每个项目都有属性(可以随着时间的推移添加 - 可以为空)
- 项目的最大大小为 400KB
- 支持的数据类型有:
- 标量类型 – 字符串、数字、二进制、布尔值、空值
- 文档类型 – 列表、地图
- 集合类型 – 字符串集合、数字集合、二进制集合
- 因此,在 DynamoDB 中,用户可以快速发展架构
DynamoDB – 表示例
DynamoDB – 读/写容量模式
- 控制管理表容量的方式(读/写吞吐量)
- 配置模式(默认)
- 用户指定每秒读/写的数量
- 用户需要提前规划容量
- 支付预配置的读取容量单位 (RCU) 和写入容量单位 (WCU) 费用
- 可以为 RCU 和 WCU 添加自动缩放模式
- 点播模式
- 读/写会根据用户的工作负载自动扩展/缩减
- 无需进行容量规划
- 按使用量付费,价格更高 ($$$)
- 非常适合不可预测的工作负载、陡峭的突然峰值
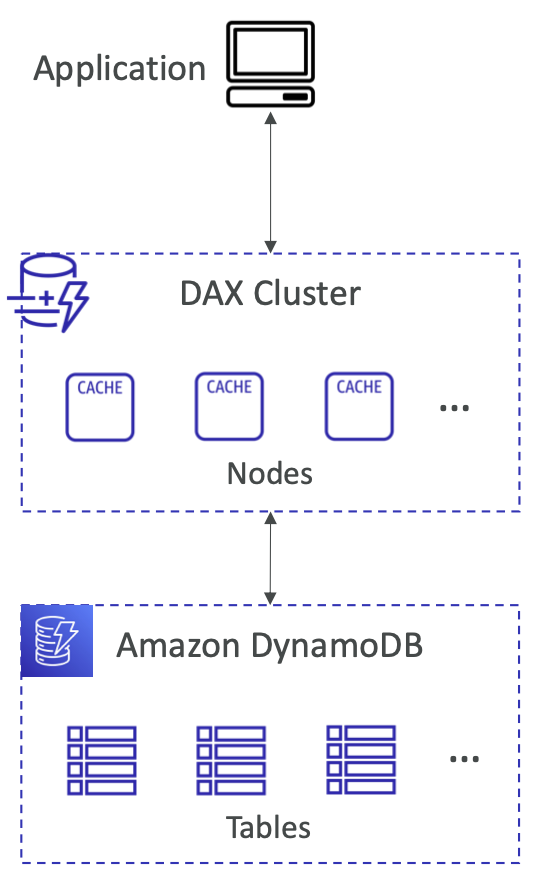
DynamoDB 加速器 (DAX)
- DynamoDB 的完全托管、高可用性、无缝内存缓存
- 通过缓存帮助解决读取拥塞
- 缓存数据的微秒级延迟
- 不需要修改应用程序逻辑(与现有的DynamoDB API 兼容)
- 5 分钟 TTL 缓存(默认)
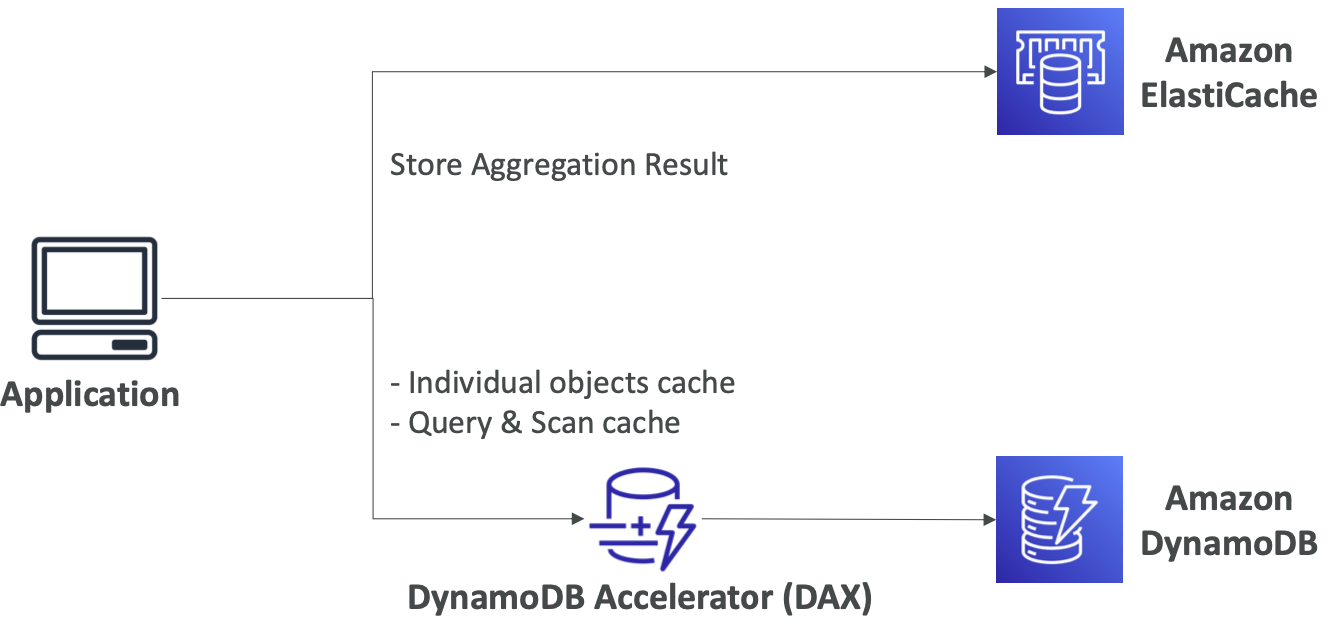
DynamoDB 加速器 (DAX) vs. ElastiCache
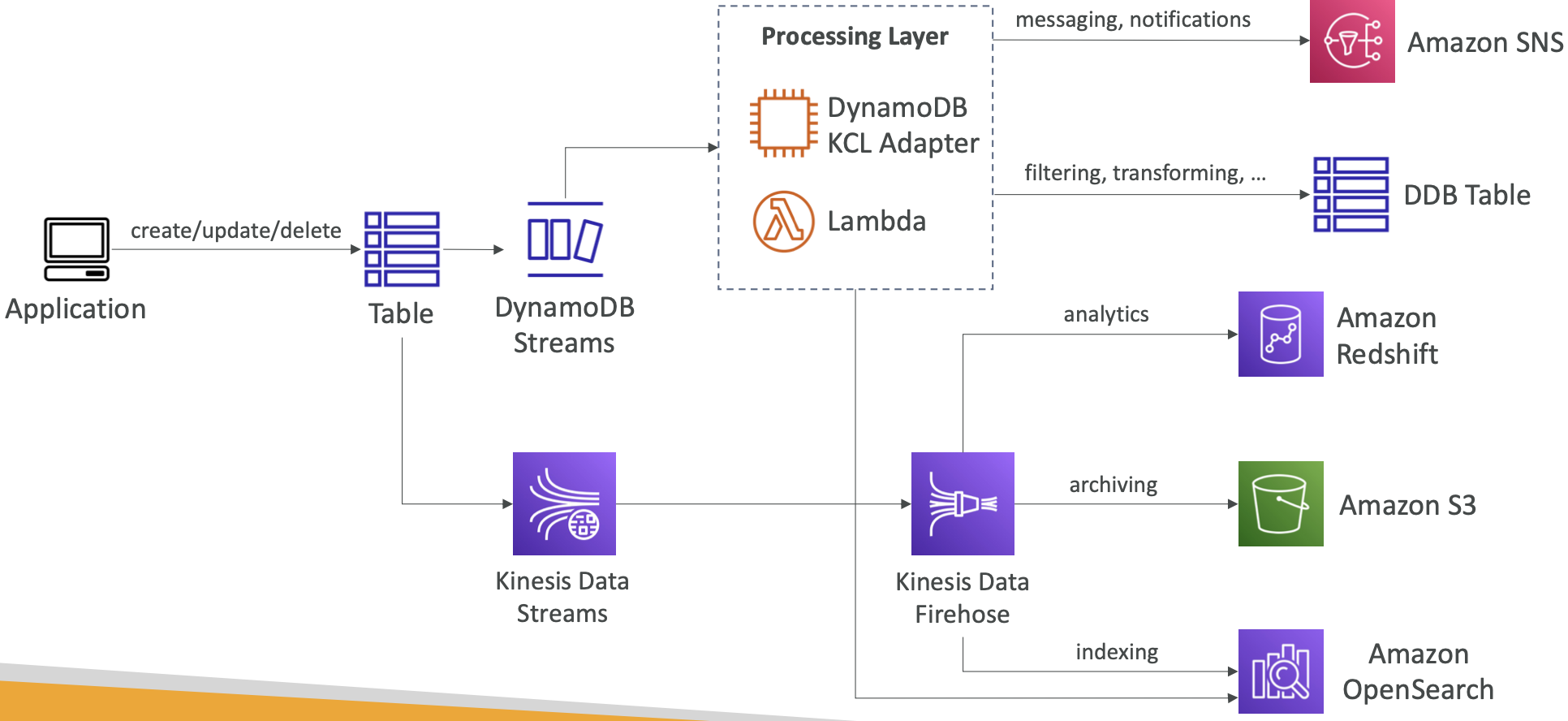
DynamoDB – 流处理
- 表中项目级修改(创建/更新/删除)的有序流
- 用例:
- 实时响应变化(向用户发送欢迎电子邮件)
- 实时使用情况分析
- 插入衍生表
- 实施跨区域复制
- 对 DynamoDB 表的更改调用 AWS Lambda
DynamoDB 流
- 24 小时保留期
- 消费者数量有限
- 使用 AWS Lambda 触发器或 DynamoDB Stream Kinesis 适配器进行处理
Kinesis Data Streams(较新)
- 保留 1 年
- 消费者数量多
- 使用 AWS Lambda、Kinesis Data Analytics、Kineis Data Firehose、AWS Glue Streaming ETL 进行处理…
DynamoDB 流
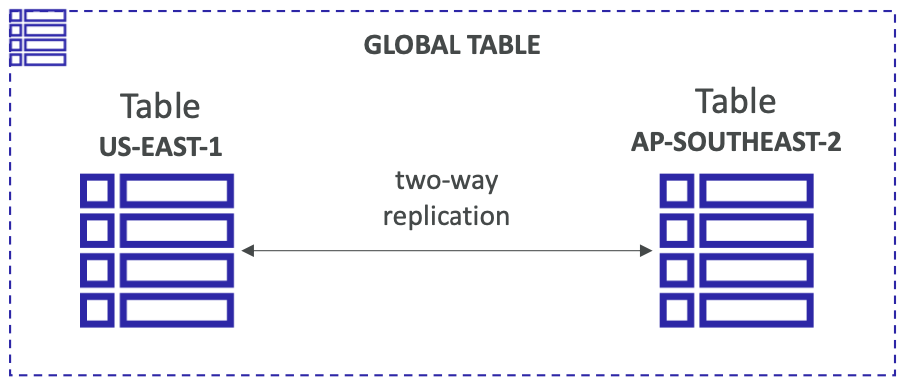
DynamoDB Global Tables
- 使 DynamoDB 表可在多个区域中以低延迟进行访问
- 主动-主动复制
- 应用程序可以读取和写入任何区域的表
- 必须启用 DynamoDB Streams 作为先决条件
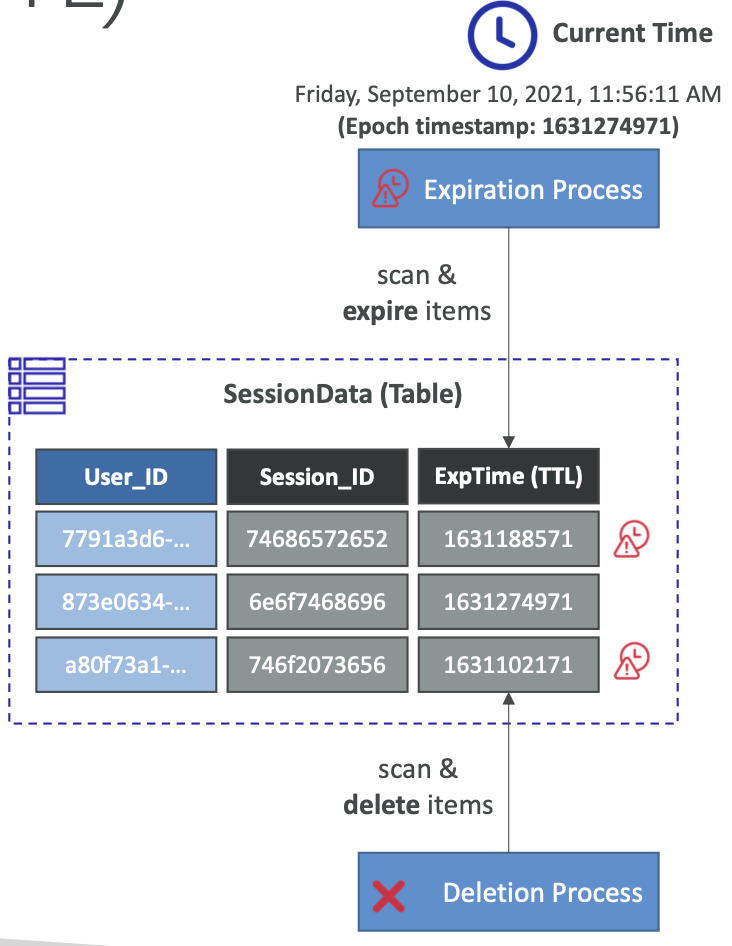
DynamoDB – 生存时间 (TTL)
- 在过期时间戳后自动删除项目
- 使用案例:通过仅保留当前项目来减少存储的数据、遵守监管义务、Web 会话处理…
DynamoDB – 用于灾难恢复的备份
- 使用时间点恢复 (PITR) 进行连续备份
- 可选择在过去 35 天内启用
- 时间点恢复到备份窗口内的任何时间
- 恢复过程创建一个新表
- 按需备份
- 完整备份可长期保留,直至明确删除
- 不影响性能或延迟
- 可以在AWS Backup 中进行配置和管理(支持跨区域复制)
- 恢复过程创建一个新表
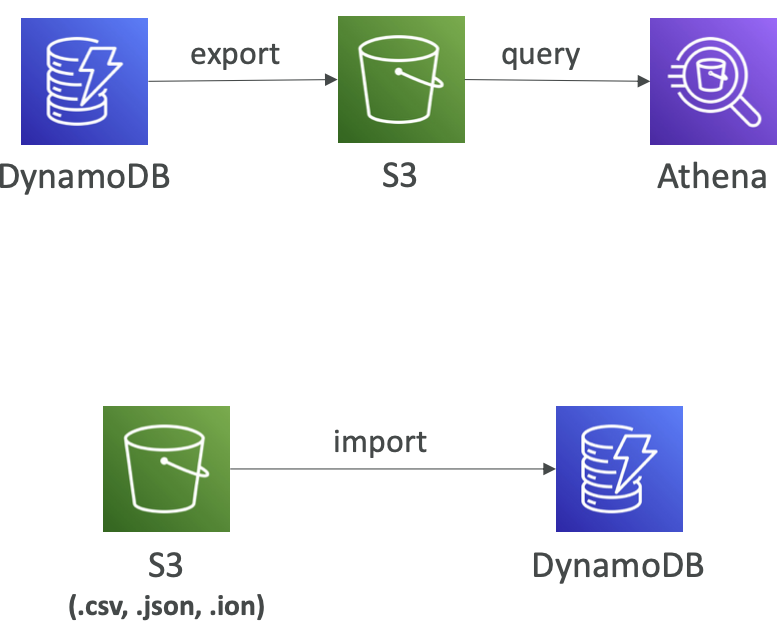
DynamoDB – 与 Amazon S3 集成
- 导出到S3(必须启用PITR)
- 适用于过去 35 天内的任何时间点
- 不影响表的读取容量
- 在DynamoDB 之上执行数据分析
- 保留快照以供审核
- 在导入回 DynamoDB 之前对 S3 数据进行 ETL
- 以DynamoDB JSON 或ION 格式导出
- 导入到 S3
- 导入 CSV、DynamoDB JSON 或 ION 格式
- 不消耗任何写入容量
- 创建一个新表
- 导入错误记录在CloudWatch Logs 中
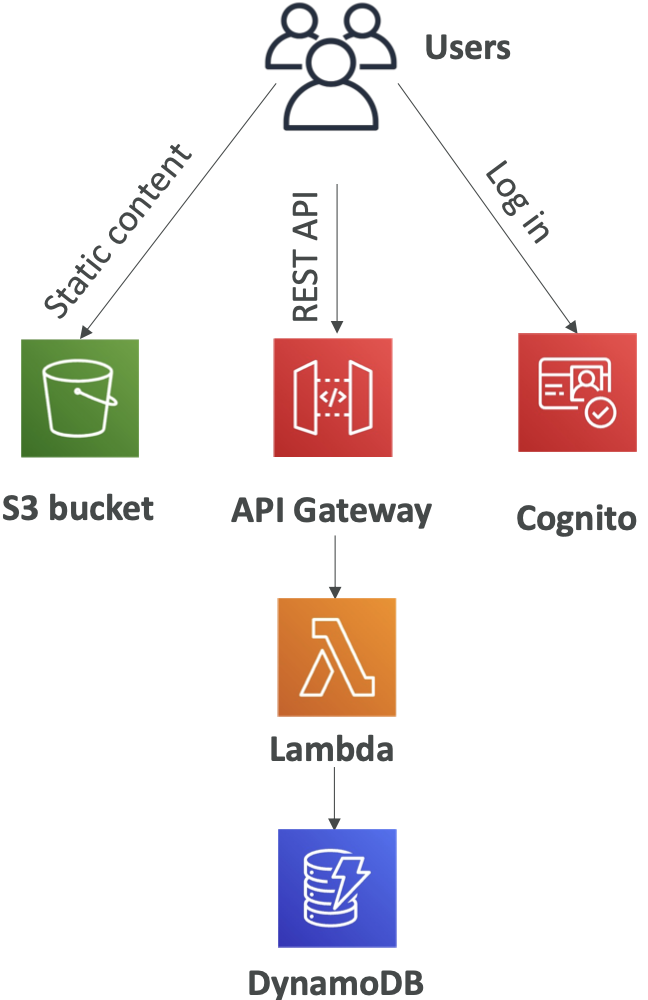
示例:构建无服务 API
文章来源:https://blog.csdn.net/weixin_40815218/article/details/135591408
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 宣传照(私密)勿转发
- nvm如何使用
- 壹基金“安全家园”项目瑞金市城北社区志愿者救援队成立
- Semtech LoRa与FSK几款芯片性能指标介绍
- 计数排序(Java语言)
- 张驰咨询:软件开发必学——用六西格玛设计(DFSS)让产品零缺陷
- [Firefly-Linux] RK3568在Ubuntu上安装内核头文件实现本地编译驱动程序
- 鸿蒙OS应用开发之切换按钮
- Vue3学习与实践
- CSS:权威指南读书笔记 第一章 CSS基础