【MYSQL】-库的操作
💖作者:小树苗渴望变成参天大树🎈
🎉作者宣言:认真写好每一篇博客💤
🎊作者gitee:gitee?
💞作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法🎄
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!

文章目录
前言
今天这篇就开始介绍数据库的具体操作,和我们当初学习语言时候一样,从语法开始学起,对于数据库的层级关系大家应该知道了,我们需要创建一个数据库然后再这个数据库里面进行创建表去操作,今天这节就是介绍库的操作,话不多说,我们来看正文。
本章重点:
库的增删查改
库的操作演示中,会使用到表的操作以及其他的语句,因为需要使用这些语句的操作让数据库完整些,才可以更好的演示库的操作,一会遇到我们不给大家做具体的语法介绍了。
一、创建数据库(增)
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
说明:
大写的表示关键字(这是推荐不是必须)
[] 是可选项
CHARACTER SET: 指定数据库采用的字符集
COLLATE: 指定数据库字符集的校验规则
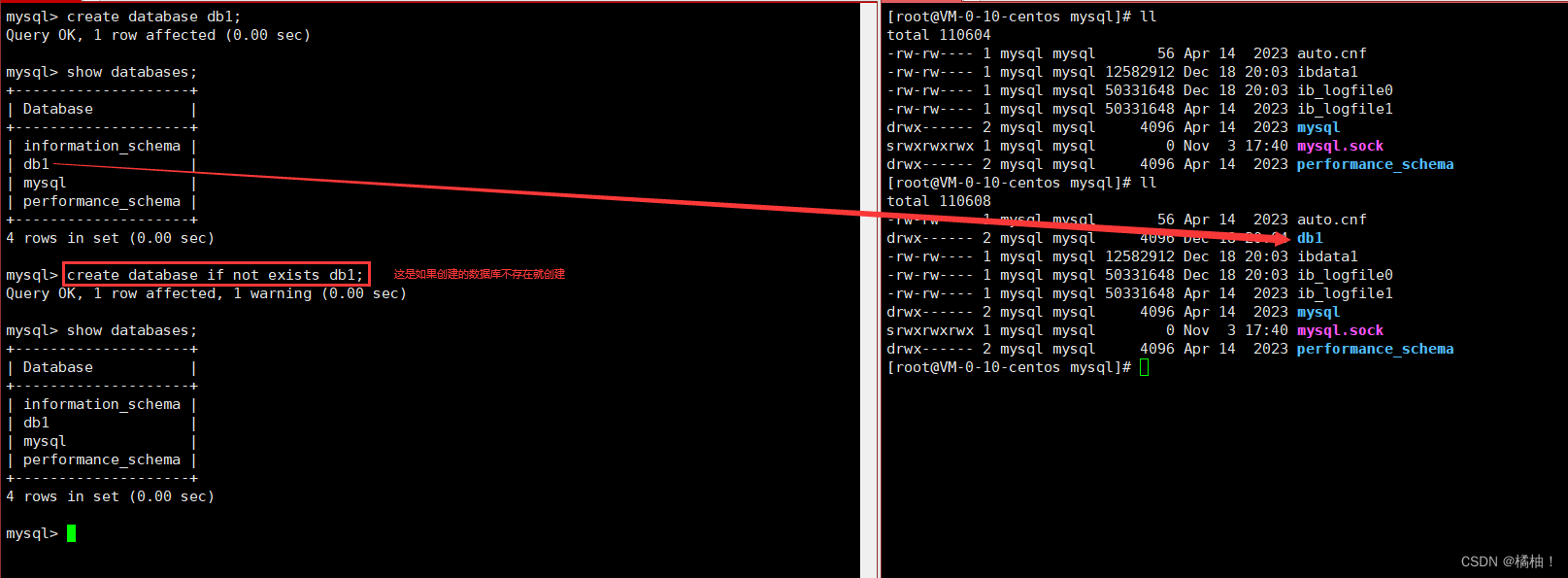
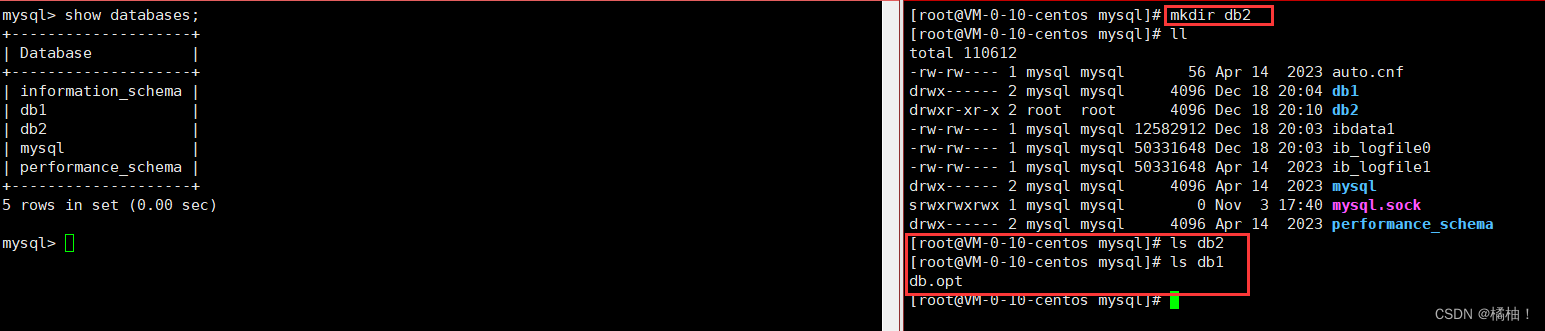
我们通过语句创建数据库本质就是再/var/lib/mysql创建一个目录。但是我们自己再此目录下创建一个目录作为数据库的目录,不要有这样的做法,使用数据库语句创建会有一个默认文件,但是自己创建就是一个普通目录里面什么也没有。
二、字符集和校验规则
我们再上一节里面的说明中,最少两点,我们再创建数据库的时候没有使用到,我想一起拿到这节去讲,以及创建一个数据库,里面默认形成的文件到底是什么,这一节讲解清楚。
因为数据库的产生不是给一个地方或者一个国家去使用的,他是要面向全球的,由于世界上语言很多,所以再存储和读取数据的时候必然存在差异,所以就需要字符集和检验规则,1. 字符集就是未来存储数据的方式(像中文必须按照可以存储中文的字符集存储进去才不会乱码,不使用数据库就看不懂存储进去的中文),2. 校验规则就是对未来读取存取的数据的校验(,但我们想要读取存储的数据,也需要按照相同的方式去读取,进行一个验证,看看读取的方式和当初存储的时候是不是一样的)
我们来看看我们mysql有多少字符集和校验规则:
show charset;//查看所以的字符集

show collation;//查看所有的校验规则
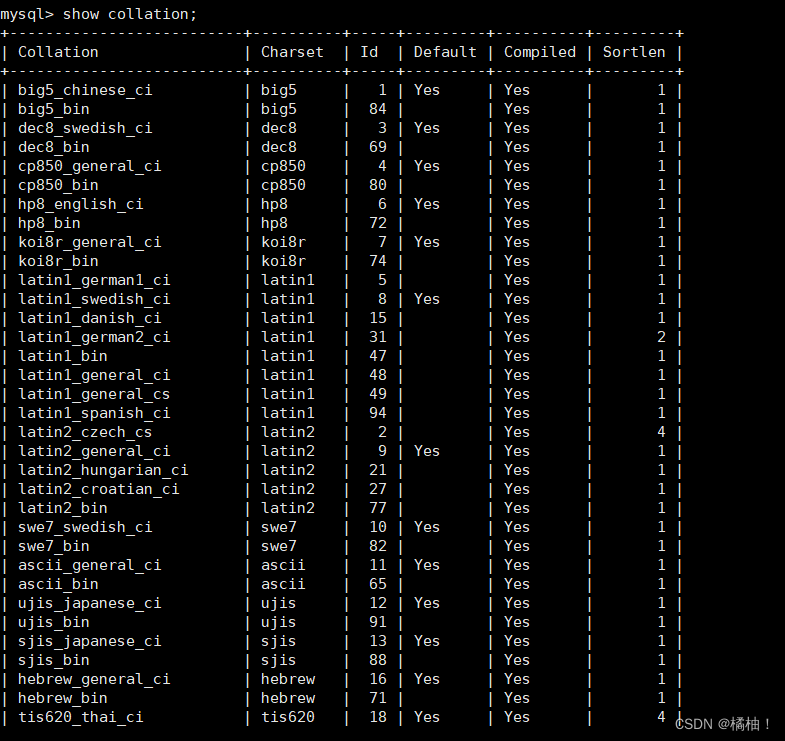
演示一部分,这个表格很好,字符集和校验规则都有对应关系。
2.1 查看系统默认字符集以及校验规则
大家如果看到博主的第一篇关于mysql博主,会看到我们的表进行插入的时候有中文,而且读取的时候没有出错,但是我们再创建数据库的时候是没有指定字符集和校验规则,所以肯定是有系统默认的,注意一点,我们的字符集和校验规则是在创建数据库的时候就已经定好了,不是创建表的时候在定。
现在可以介绍我们创建数据库时形成一个数据库的工作目录,里面有一个自动姓曾的文件db.opt,我们来看看里面是什么:

就是我们默认的字符集和校验规则,大家还记得在安装mysql那篇博客中后面,我带大家配置了
my.cnf文件,里面就有默认的。他在配置文件里面不是具体写了,但是确实是通过配置文件来确定默认的。
我们来看看系统默认的字符集和检验规则:
show variables like 'character_set_database';
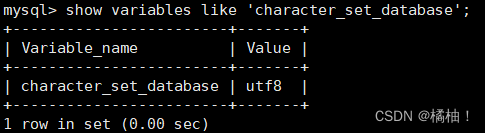
show variables like 'collation_database';
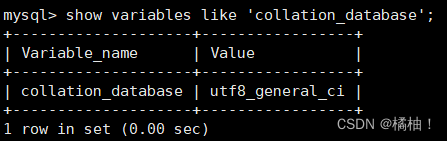
大家如果一直安装博主的操作安装的,大概率看到的和博主是一样的效果。
2.2 校验规则对数据库的影响
我们来使用不同的校验规则看看对数据读取的影响。大家看效果就可以,不要管操作。顺便给大家在创建数据库的时候使用指定的字符集和校验规则。
创建一个数据库,校验规则使用utf8_ general_ ci[不区分大小写]
create database test1 charset=utf8 collate utf8_general_ci;

在这个数据库里面创建一张表person,插入数据
use test1;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');

创建一个数据库,校验规则使用utf8_ bin[区分大小写]
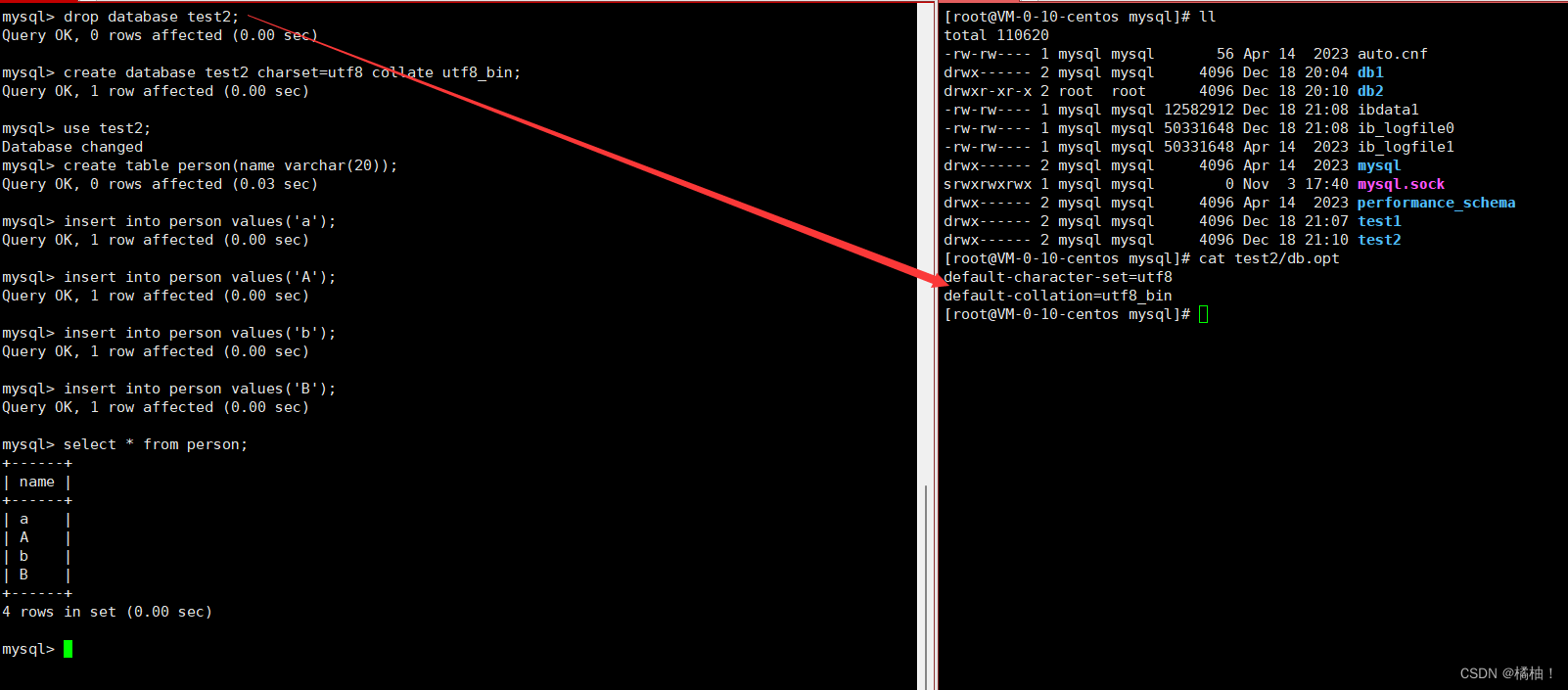
两个数据库里面有相同的表,相同的数据,唯一不同的就是校验规则不一样。
进行查询:
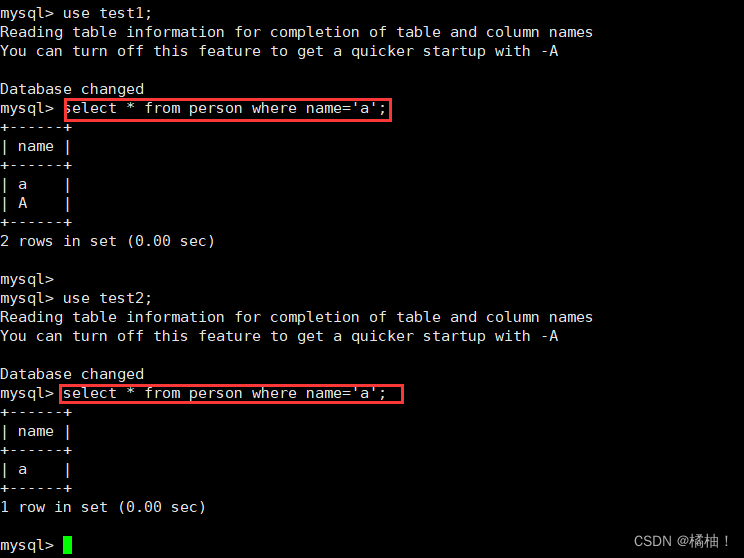
进行排序
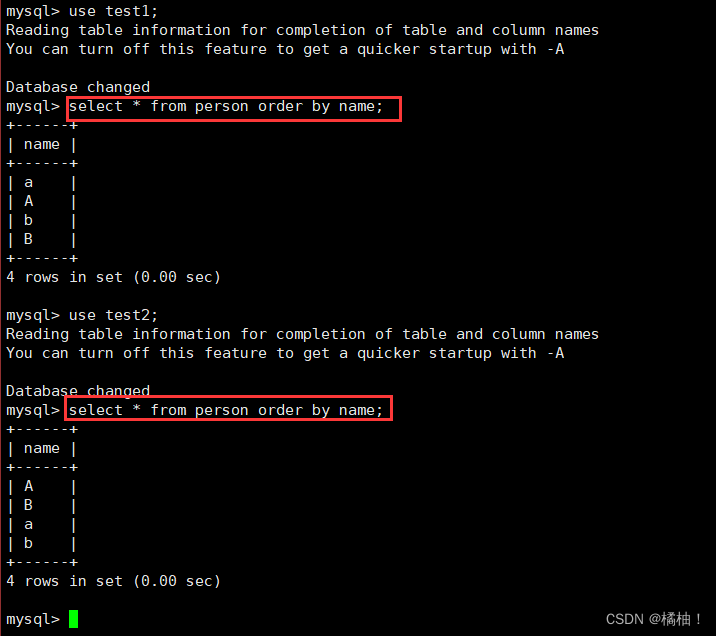
通过两种方式验证,不同的校验规则对于读取数据确实存在差异,说明字符集和校验规则对数据库影响还是很大的。并且通过这一节从创建数据库开始指定字符集和校验规则,如果我们创建的时候指定了,就使用指定的,不使用默认的。
三 操作数据库(查)
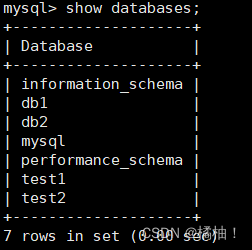
3.1查看数据库
show databases;
3.2 显示创建语句
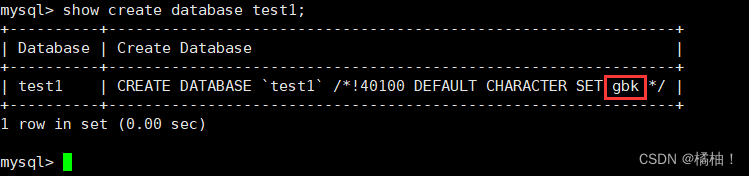
如果大家想要看创建数据库的时候做了哪些操作可以使用下面语句:
show create database 数据库名;

数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
/*!40100 default… */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话
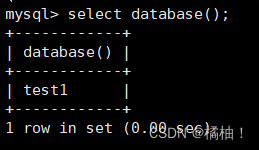
有的时候我们在数据库中来回切换操作不同的表,但是此时忘记自己在哪个数据库中,可以使用下面语句定位:
select database();
四、修改数据库(改)
语法:
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
说明:
对数据库的修改主要指的是修改数据库的字符集,校验规则
因为对于项目数据库就是操作数据的标识,所以在开发之前这个数据库名定好了,如果在中途修改就会造成其他模块的问题,如果这个问题是后面运行的时候出现了,那损失就大了,所以名字不要随意修改,对于表也是一样的。
alter database test1 charset=gbk;//修改字符集,修改校验规则也是一样的
alter database test1 collation utf*_bin;

 在博主这个版本下,没有办法修改数据库名称,但是在MySQL5.1.7这个版本可以使用
在博主这个版本下,没有办法修改数据库名称,但是在MySQL5.1.7这个版本可以使用RENAME DATABASE db_name TO new_db_name这个语句去修改,在5.1.23版本之后就去掉了,原因是此语句会造成数据丢失。
五、删除数据库(删)
语法:
DROP DATABASE [IF EXISTS] db_ name;
执行删除之后的结果:
- 数据库内部看不到对应的数据库
- 对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
注意: 不要随意删除数据库
这个很简单就不给大家演示了。
六、备份和恢复
在互联网里面最重要的就是对数据进行操作,所以数据是很重要的,而数据库又是存储数据的介质,所以他的删除是一个非必要不要去做的操作,为了避免出现问题,我们在删除之前最好先备份一下,方便下次恢复出来。
6.1 备份
语法:
# mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径
mysqldump -P 3306 -u root -p -B test1 > MYSQL/test1.sql
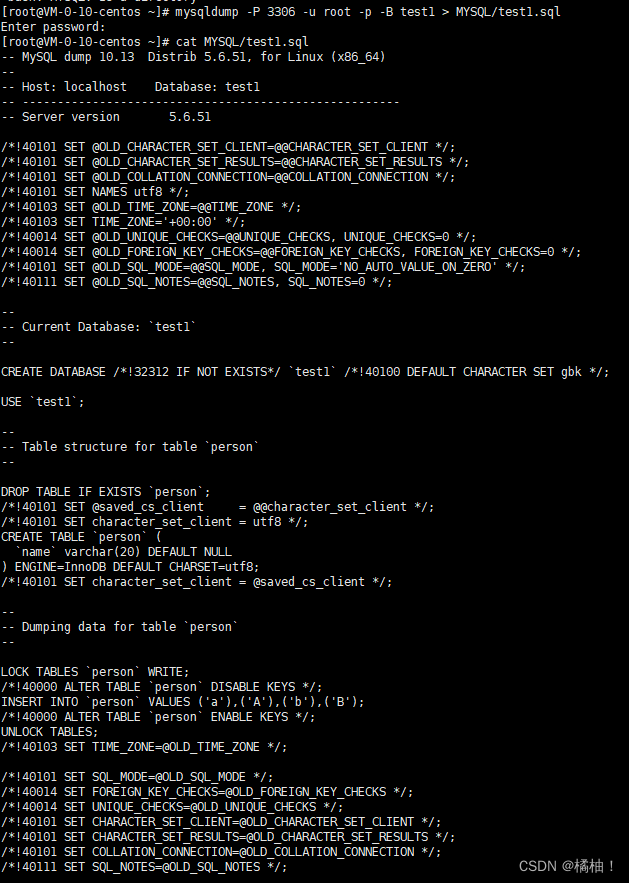
这个备份文件里面有许多信息,都是为了后来的恢复用的。
6.2 恢复
mysql> source D:/mysql-5.7.22/mytest.sql;
source /root/MYSQL/test1.sql;

恢复很简单,这个需要指定绝对路径,大家如果不清楚自己备份的文件在哪个路径下,使用pwd就可以了。
6.3注意事项
如果备份的不是整个数据库,而是其中的一张表,怎么做?
# mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
同时备份多个数据库
# mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用source来还原,大家看清楚执行备份和恢复的时候在哪个窗口下执行,并且恢复的操作都是一样的,这个就不给大家演示了。
6.4 查看连接情况
show processlist

可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。
七、总结
讲解到这里了我们对于库的操作终于讲解完毕了,还是希望大家下来可以自己去多练习一下,新东西要多练习,才能掌握。大家有不理解的评论区在问博主吧。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!