【C++】POCO学习总结(十八):XML
【C++】郭老二博文之:C++目录
1、XML文件格式简介
1)XML文件的开头一般都有个声明,声明是可选
<?xml version="1.0" encoding="UTF-8"?>
2)根元素:XML文件最外层的元素
3)元素和属性:
<元素名elementName 属性attributeName = " attrValue " >
元素内容
< / elementName >
4)注释
<!——注释——>
5)处理指令,用的不多
详细解释参考博客:https://blog.csdn.net/gavin_john/article/details/51511180
<?name data?>
6)CDATA
用于转义包含字符的文本块,否则这些字符将被视为标记
<xml><!CDATA[Escape <things><like></that>]]></xml>
7)示例
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<!--
This is a comment.
-->
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
<head>
<link rel="stylesheet" href="styles.css" type="text/css"/>
<?xml-stylesheet href="styles.css" type="text/css"?>
<title>A XHTML Example</title>
</head>
<body>
<h1>XHTML Example</h1>
<p>This is a XHTML example page.</p>
<img src="example.gif" width="256" height="192" alt="Example Picture" border="0"/>
<![CDATA[
The following <tag attr="value">is inside a CDATA section</tag>.
]]>
</body>
</html>
2、POCO的XML接口
2.1 说明
POCO支持两个接口来处理(读和写)XML数据:
- XML的简单API(SAX),基于事件的处理
- 文档对象模型,基于树的处理
2.2 SAX基于事件处理的优点和缺点
1)优点:
基于事件处理非常类似于流媒体,分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。一般来说,SAX 还比它的替代者 DOM 快许多。
2)缺点:
由于应用程序没有以任何方式存储数据,使用 SAX 来更改数据或在数据流中往后移是不可能的。
2.3 DOM基于树的优点和缺点
1)优点:
由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。
它可以在任何时候在树中上下导航,而不是像 SAX 那样是一次性的处理。
DOM 使用起来也要简单得多。
2)缺点:
在内存中构造这样的树涉及大量的开销。大型文件完全占用系统内存容量的情况并不鲜见。
创建一棵 DOM 树可能是一个缓慢的过程。
2.4 如何选择 SAX 和 DOM
选择 DOM 还是选择 SAX,这取决于下面几个因素:
1)应用程序的目的:如果打算对数据作出更改并将它输出为 XML,那么在大多数情况下,DOM 是适当的选择。并不是说使用 SAX 就不能更改数据,但是该过程要复杂得多,因为您必须对数据的一份拷贝而不是对数据本身作出更改。
2)数据容量: 对于大型文件,SAX 是更好的选择。
数据将如何使用:如果只有数据中的少量部分会被使用,那么使用 SAX 来将该部分数据提取到应用程序中可能更好。 另一方面,如果您知道自己以后会回头引用已处理过的大量信息,那么 SAX 也许不是恰当的选择。
3)对速度的需要: SAX 实现通常要比 DOM 实现更快。
3、SAX
3.1 说明
XML的简单API,简称为SAX,最初是java接口,POCO仿照java接口,使用C++来实现。
SAX是一个事件驱动的接口。XML文档不会作为一个整体加载到内存中进行解析。相反,解析器扫描XML文档,对于它找到的每个XML结构(元素、文本、处理指令等),调用处理程序对象的某个成员函数。
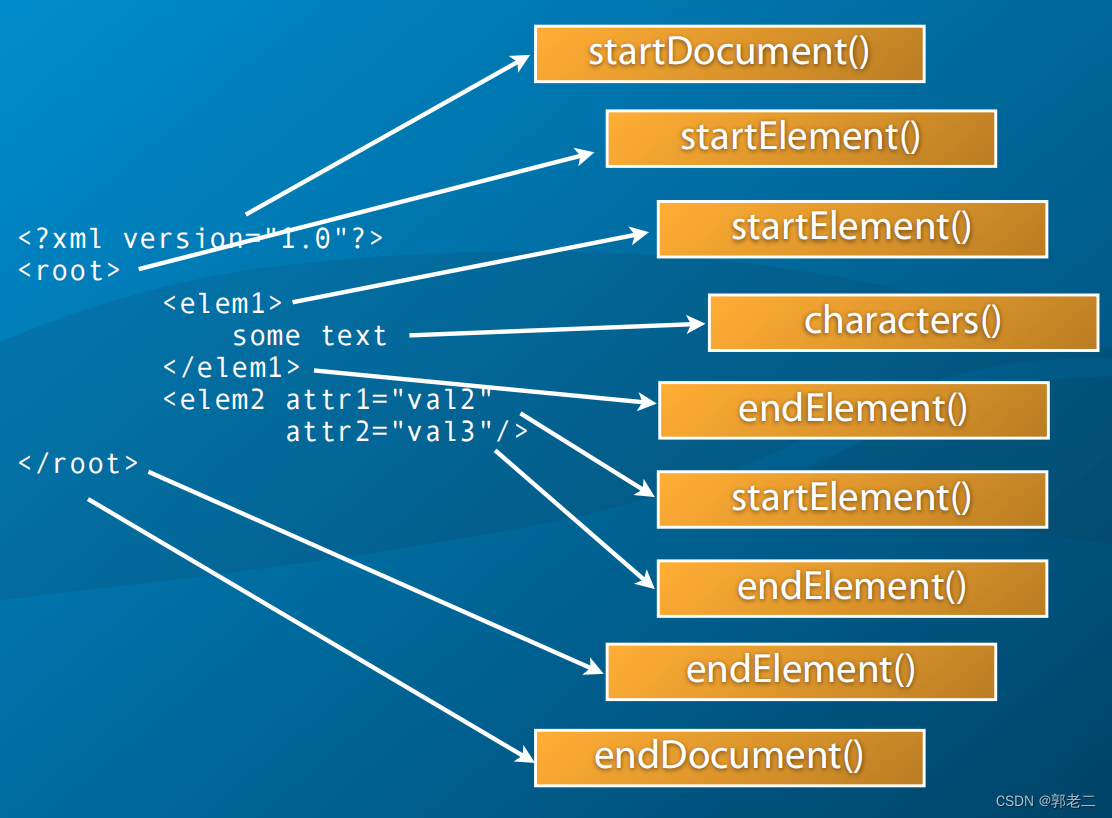
3.2 用法
1)属性
通过索引或名称访问属性值
2)内容事件:ContentHandler
常用接口:startElement()、endElement()、characters(),…
3)DTD处理事件:DeclHandler
一种简单的模式语言处理XML文件中的DTD声明
DTD是什么?Document Type Declaration:文档类型声明
用于XML文件中DTD声明的可选处理程序
example.dtd
<!ELEMENT people_list (person*)>
<!ELEMENT person (name, birthdate?, gender?)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT birthdate (#PCDATA)>
<!ELEMENT gender (#PCDATA)>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE people_list SYSTEM "example.dtd">
<people_list>
<person>
<name>Peter Schojer</name>
<birthdate>15/03/1976</birthdate>
<gender>Male</gender>
</person>
</people_list>
4)处理未被DeclHandler处理的DTD:DTDHandler
处理未被DeclHandler处理的DTD
- 未解析的实体
- 符号
- startDocument和第一个startElement之间的所有报告
常用接口:notationDecl(), unparsedEntityDecl()
5)词法事件:LexicalHandler
SAX的可选扩展处理程序,用于提供关于XML文档的词法信息;
词法信息包括所使用的文档编码格式和嵌入文档中的 XML 注释,以及 DTD 和任何 CDATA 部分的节边界。
常用接口:startDTD(), endDTD(), startCDATA(), endCDATA(), comment()
4、DOM 文档对象模型
4.1 说明
DOM文档对象模型:是由万维网联盟(W3C)指定的一个API。
DOM使用XML文档的树表示;
整个文档必须加载到内存中;
可以直接修改XML文档。
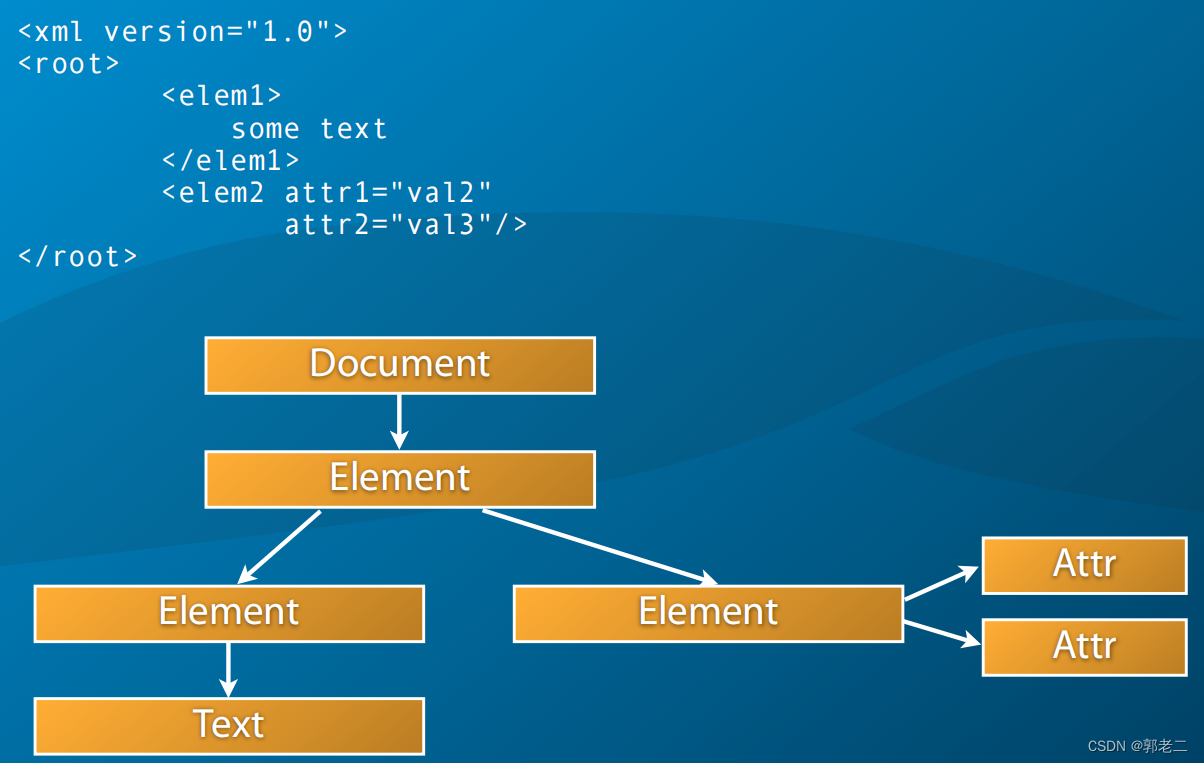
4.2 在DOM中导航
1)节点信息
- parentNode ():父节点
- firstChild():第一个子节点
- lastChild():最后一个子节点
- nextSibling():下一个子节点(同级别的,兄弟姐妹)
- previousSibling():前一个子节点(同级别的,兄弟姐妹)
2)节点迭代用于文档顺序遍历
- nextNode():前一个节点
- previousNode():后一个节点
3)支持节点过滤
4.3 DOM中的内存管理
DOM节点被引用计数。
如果创建一个新节点并将其添加到文档中,则文档将增加其引用计数。所以请使用AutoPtr。
可以通过 NamedNodeMap 和 NodeList 接口获得非树对象的所有权,所以必须释放它们(或使用AutoPtr)。
文档保留了从树中删除的节点的所有权。这些节点在文档的AutoReleasePool中结束。
4.4 创建XML文档
- 从头开始构建DOM文档
- 通过使用XMLWriter类,
XMLWriter支持生成XML数据的SAX接口。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [RoarCTF 2019]Easy Java(java web)
- OpenHarmony——基于HDF驱动框架构建的Display驱动模型
- STM32入门教程-2023版【3-2】详细讲解实现LED流水灯
- 基于SSM的牙科诊所管理系统
- 超级干货!五个步骤教你从0到1搭建FP独立站!
- Docker安装MySql详细步骤
- 由于找不到kernel32.dll无法继续执行此代码的解决方法
- Spring Security 6.x 系列【71】扩展篇之基于角色的访问控制模型(RBAC)
- CF1914C Quests
- isp代理/双isp代理/数据中心代理的区别?如何选择?