9.集合进阶(二)
文章目录
一、Collection的其他相关知识
1.前置知识:可变参数
1.1 可变参数定义
就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:数据类型…参数名称;
1.2 可变参数的特点和好处
- 特点:可以不传数据给它;可以传一个或者同时传多个数据给它;也可以传一个数组给它
- 好处:常常用来灵活的接收数据
1.3 可变参数的注意事项
- 可变参数在方法内部就是一个数组
- 一个形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
package d7_variableparam;
/*
* 需求:利用可变参数求和
*/
public class SumVariable {
public static void main(String[] args) {
System.out.println(Sum(1, 2, 3, 4, 5));
System.out.println(Sum()); //不会报错:因为在可变参数的本质是一个数组,会创建一个数组,不会报 NullPointerException
}
public static int Sum(int...arr){
int sum = 0;
//计算多个数之和
for (int i : arr) {
sum += i;
}
return sum;
}
}
2.Collections
一个用来操作集合的工具类
2.1 Collections提供的常用静态方法
| 方法名称 | 说明 |
|---|---|
| public static boolean addAll(Collection<? super T> c, T… elements) | 给集合批量添加元素 |
| public static void shuffle(List<?> list) | 打乱List集合中的元素顺序 |
| public static void sort(List list) | 对List集合中的元素进行升序排序 |
| public static void sort(List list,Comparator<? super T> c) | 对List集合中元素,按照比较器对象指定的规则进行排序 |
import java.util.ArrayList;
import java.util.Collections;
public class Demo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
Collections.addAll(list, "赵六", "田七");
for (String s : list) {
System.out.println(s);
}
ArrayList<Integer> list1 = new ArrayList<>();
Collections.addAll(list1, 12, 43, 21, 23, 90);
//Collections.sort(list1); //默认升序
Collections.sort(list1, ((o1, o2) -> o2 - o1));// 比较器 降序排列
System.out.println(list1);
}
}
2.2 Collections排序
Collections只能支持对List集合进行排序
2.2.1 方式一:
| 方法名称 | 说明 |
|---|---|
| public static void sort(List list) | 对List集合中元素按照默认规则ASC排序 |
2.2.2 方式二:
| 方法名称 | 说明 |
|---|---|
| public static void sort(List list,Comparator<? super T> c) | 对List集合中元素,按照比较器对象指定的规则进行排序 |
3.综合案例:斗地主
- 需求:
总共有54张牌
点数: “3”,“4”,“5”,“6”,“7”,“8”,“9”,“10”,“J”,“Q”,“K”,“A”,"2“
花色: “?”, “?”, “?”, "?“
大小王: “👲” , "🃏“
斗地主:发出51张牌,剩下3张做为底牌
- 分析实现:
在启动游戏房间的时候,应该提前准备好54张牌
接着,需要完成洗牌、发牌、对牌排序、看牌
3.1 牌–实体类
// 牌--实体类
public class Card {
private String number;//点数
private String color;//花色
private int count; //记录每一张牌
@Override
public String toString() {
return color + number;
}
[get、set、构造器]
}
3.2 创建的房间类(用来洗牌、发牌)
//创建的房间
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Room {
//提供一个集合,用来存储54张牌
private List<Card> cardList = new ArrayList<>();
//提供一个无参构造方法,在构造方法中准备54张牌
public Room() {
int count = 0;
/*
?2 ?2 ?2 ?2 ?3 ?3 。。。。。
*/
String[] numbers = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"};
String[] colors = {"?","?","?","?"};
for (int i = 0; i < numbers.length; i++) {
//numbers[i] 3
for (int j = 0; j < colors.length; j++) {
//colors[j]
cardList.add(new Card(numbers[i],colors[j],++count));
}
}
//准备大小王
cardList.add(new Card("小王","",53));
cardList.add(new Card("大王","",54));
/*for (Card card : cardList) {
System.out.println(card);
}*/
}
//提供一个开始游戏的方法
public void start() {
//1.洗牌
Collections.shuffle(cardList);
/* for (Card card : cardList) {
System.out.println(card);
}*/
//2.发牌
//准备3个集合,每一个集合相当于一个玩家
List<Card> zhouYaJun = new ArrayList<>();
List<Card> ruHua = new ArrayList<>();
List<Card> liuYiFei = new ArrayList<>();
//注意:要留3张牌
for (int i = 0; i < cardList.size() - 3; i++) {
// i % 3 : 只有3种结果,分别是 0 1 2
if(i % 3 == 0) {
zhouYaJun.add(cardList.get(i));
} else if(i % 3 == 1) {
ruHua.add(cardList.get(i));
} else {
liuYiFei.add(cardList.get(i));
}
}
//3.排序
//Collections.sort(zhouYaJun,(o1,o2) -> o1.getCount() - o2.getCount());
Collections.sort(zhouYaJun, Comparator.comparingInt(Card::getCount));
Collections.sort(ruHua,(o1,o2) -> o1.getCount() - o2.getCount());
//将地主给刘亦菲
liuYiFei.add(cardList.get(cardList.size() - 1));
liuYiFei.add(cardList.get(cardList.size() - 2));
liuYiFei.add(cardList.get(cardList.size() - 3));
Collections.sort(liuYiFei,(o1,o2) -> o1.getCount() - o2.getCount());
//4.看牌
System.out.println("周亚军的牌是:");
for (Card card : zhouYaJun) {
System.out.print(card + " ");
}
System.out.println();
System.out.println("如花的牌是:");
for (Card card : ruHua) {
System.out.print(card + " ");
}
System.out.println();
System.out.println("刘亦菲地主的牌是:");
for (Card card : liuYiFei) {
System.out.print(card + " ");
}
System.out.println();
}
}
3.3 主方法–开始游戏
public class Demo {
public static void main(String[] args) {
Room r = new Room();//当我们创建好房间后,排就应该准备
r.start();
}
}
二、Map集合
1.Map集合概述
- 双列集合,格式:{key1 = value1, key2 = value2, …}
- 键值对集合
- 键(key)不能重复,值(value)可以重复,键和值一一对应,每一个键只能找到自己对应的值
- Map是双列集合的祖宗,它的功能是全部双列集合都可以继承过来使用的
1.1 Map集合体系
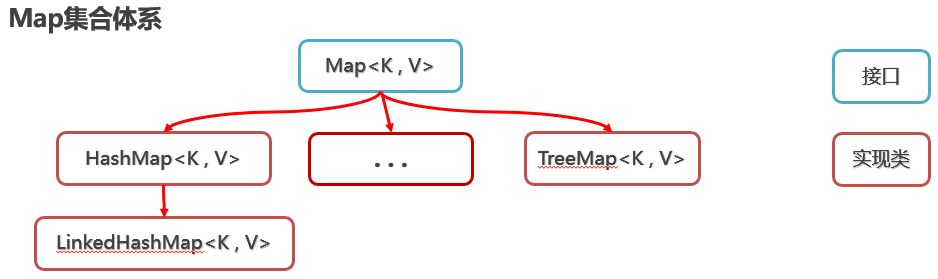
1.2 Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
-
HashMap(由键决定特点): 无序、不重复、无索引; (用的最多)
-
LinkedHashMap (由键决定特点):由键决定的特点:有序(存取有序)、不重复、无索引。
-
TreeMap (由键决定特点):按照大小默认升序排序**、**不重复、无索引
1.3 Map集合使用场景
- 需要存储一一对应的数据时,就可以考虑使用Map集合来做
2.Map常用方法
| 方法名称 | 说明 |
|---|---|
| public V put(K key.V value) | 添加元素 |
| public int size() | 获取集合的大小 |
| public void clear() | 清空集合 |
| public boolean isEmpty() | 判断集合是否为空,为空返回true |
| public V get(object key) | 根据键获取对应值 |
| public V remove(object key) | 根据键删除整个元素 |
| publicboolean containsKey(object key) | 判断是否包含某个键 |
| public boolean containsValue(object value) | 判断是否包含某个值 |
| public Set keySet() | 获取全部键的集合 |
| public Collection values() | 获取Map集合的全部值 |
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapDemo {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
//put 添加元素
map.put("郭靖","黄蓉");
map.put("杨过","小龙女");
map.put("张三丰","郭襄");
map.put("张无忌","赵敏");
//size 获得集合的大小[对]
int size = map.size();
System.out.println("集合的大小是:"+size);
//map.clear(); 清空集合
System.out.println(map.isEmpty());
//根据【键】获得该键对应的 值
String s1 = map.get("杨过");
System.out.println(s1);
//根据 【键】 删除集合中的元素
String s2 = map.remove("张三丰");
System.out.println(s2);
//判断集合中是否包含 指定 【键】
boolean s3 = map.containsKey("张无忌");
System.out.println(s3);
//判断集合中是否包含 指定 【value】
boolean s4 = map.containsValue("小龙女");
System.out.println(s4);
//获得集合的全部【键】
Set<String> s5 = map.keySet();
for (String s : s5) {
System.out.println(s);
}
//获得集合中元素的全部 【value】
Collection<String> values = map.values();
for (String value : values) {
System.out.println(value);
}
System.out.println("========");
//遍历一:遍历键 找值
for (String s : map.keySet()) {
System.out.println(s+"=="+map.get(s));
}
System.out.println("==============");
//遍历二:entrySet()方法(map.entrySet())得到一个Set集合,使用该集合的getKey,getValue得到
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey()+"=="+entry.getValue());
}
System.out.println("=========");
//遍历三:forEach
map.forEach((k,v) -> System.out.println(k+"="+v));
}
}
3.Map遍历方式
3.1 键找值
先获取Map集合全部的键,再通过遍历键找值
| 方法名称 | 说明 |
|---|---|
| public Set kevSet() | 获取所有键的集合 |
| public V get(object key) | 根据键获取其对应的值 |
3.2 键值对
把“键值对”看成一个整体进行遍历
| Map提供的方法 | 说明 |
|---|---|
| Set<Map.Entry<K,V>> entrySet() | 获取所有“键值对”的集合 |
| Map.Entry提供的方法 | 说明 |
| K getKey() | 获取键 |
| V getValue() | 获取值 |
3.3 Lambda表达式
JDK1.8开始之后的新技术
| 方法名称 | 说明 |
|---|---|
| default void forEach(BiConsumer<??super K,?super V> action) | 结合lambda遍历Map集合 |
import java.util.*;
import java.util.function.Consumer;
/**
* @author Mzh15
* @address JavaProject:d7_map
* @data 2023/12/24 11:42
* @description: 要求在程序中记住如下省份和其对应的城市信息,记录成功后,要求可以查询出湖北省的城市信息
* 江苏省 = 南京市,扬州市,苏州市,无锡市,常州市
* 湖北省 = 武汉市,孝感市,十堰市,宜昌市,鄂州市
* 河北省 = 石家庄市,唐山市,邢台市,保定市,张家口市
*/
public class MapCityDemo {
public static void main(String[] args) {
HashMap<String, List<String>> map = new HashMap<>();
//存储城市数据
List<String> cities1 = new ArrayList<>();
//存储江苏省的数据
cities1.add("南京市");
cities1.add("扬州市");
cities1.add("苏州市");
cities1.add("无锡市");
cities1.add("常州市");
map.put("江苏省",cities1);
//存储湖北省的数据
List<String> cities2 = new ArrayList<>();
cities2.add("武汉市");
cities2.add("孝感市");
cities2.add("十堰市");
cities2.add("宜昌市");
cities2.add("鄂州市");
map.put("湖北省",cities2);
//存储河北省的数据
List<String> cities3 = new ArrayList<>();
cities3.add("石家庄市");
cities3.add("唐山市");
cities3.add("邢台市");
cities3.add("保定市");
cities3.add("张家口市");
map.put("河北省",cities3);
//遍历map并输出 【湖北省】的城市数据
//遍历一:增强for循环
Set<Map.Entry<String, List<String>>> entries = map.entrySet();
for (Map.Entry<String, List<String>> province : entries) {
String key = province.getKey();
List<String> cities = province.getValue();
if ("湖北省".equals(key)) {
System.out.println(key);
for (String city : cities) {
System.out.println("\t" + city);
}
}
}
System.out.println("=======");
//遍历二:迭代器
Iterator<Map.Entry<String, List<String>>> it = entries.iterator();
while (it.hasNext()){
Map.Entry<String, List<String>> province = it.next();
String key = province.getKey();
if ("湖北省".equals(key)){
System.out.println(key);
List<String> value = province.getValue();
for (String s : value) {
System.out.println("\t"+s);
}
}
}
//遍历三:forEach循环
//Set<Map.Entry<String, List<String>>> entries = map.entrySet();
entries.forEach(new Consumer<Map.Entry<String, List<String>>>() {
@Override
public void accept(Map.Entry<String, List<String>> stringListEntry) {
if ("湖北省".equals(stringListEntry.getKey())){
System.out.println(stringListEntry.getKey());
stringListEntry.getValue().forEach(s -> System.out.println("\t"+s));
}
}
});
}
}
3.4 案例:统计投票人数
3.4.1 学生类
import java.util.Objects;
public class Student {
private String name;
private int age;
[get,set,构造器]
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public Student() {
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
3.4.2 进行统计的主方法
import java.util.*;
public class StuMapArr {
public static void main(String[] args) {
Random rd = new Random();
//1.定义一个数组,用来存储4个景区
String[] arr = {"A","B","C","D"};
//2.模拟班级80个学生的选择
ArrayList<String> list = new ArrayList<>();
for (int i = 0; i < 80; i++) {
//模拟每一个学生的选择
int index = rd.nextInt(arr.length);
list.add(arr[index]);
}
//System.out.println(list);
HashMap<String, Integer> result = new HashMap<>();
//遍历list集合
for (String s : list) {
//判断map是否包含指定的键
if (result.containsKey(s)){
Integer value = result.get(s);
value += 1;
result.put(s,value);
}else {
result.put(s,1);
}
}
System.out.println(result);
//求哪个景点的人数最多
int count = 0;
String name = "";
Set<Map.Entry<String, Integer>> entries = result.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer value = entry.getValue();
if (count < value){
name = key;
count = value;
}
}
System.out.println("选择最多的景点是:"+name+" 人数是:"+count);
}
}
4.HashMap
4.1 HashMap集合的底层原理
- HashMap跟HashSet的底层原理是一模一样的,都是基于哈希表实现的。
实际上:原来学的Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要键数据,不要值数据而已
4.2 哈希表
- JDK8之前,哈希表 = 数组 + 链表
- JDK8开始,哈希表 = 数据 + 链表 + 红黑树
- 哈希表是一种增删改查数据,性能都较好的数据结构
4.3 HashMap如何实现唯一性
- 依赖 **hashCode **方法和 equals 方法保证键的唯一
- 如果键要存储的是自定义对象,需要重写hashCode和equals方法
4.4 HashMap应用案例:存储自定义对象并遍历
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 需求:创建一个HashMap集合,键是学生对象(Student),值是籍贯(String)。存储三个键值对元素,并遍历
*/
public class HashMapDemo {
public static void main(String[] args) {
HashMap<Student, String> map = new HashMap<Student, String>();
map.put(new Student("张三",18),"陕西西安");
map.put(new Student("李四",28),"陕西渭南");
map.put(new Student("王五",21),"陕西咸阳");
map.put(new Student("赵六",25),"陕西西安");
//遍历 map 集合
Set<Student> stus = map.keySet();
for (Student student : stus) {
String stu = map.get(student);
System.out.println(student.getName()+"同学的年龄是:"+student.getAge()+" 籍贯是:"+stu);
}
Set<Map.Entry<Student, String>> entries = map.entrySet();
for (Map.Entry<Student, String> entry : entries) {
System.out.println(entry.getKey()+"=="+entry.getValue());
}
System.out.println("======");
map.forEach((k,v) -> System.out.println(k+"=="+v));
}
}
5.LinkedHashMap
5.1 LinkedHashMap集合的原理
底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外的多了一个双链表的机制记录元素顺序(保证有序)
实际上:LinkedHashSet集合的底层原理就是LinkedHashMap
5.2 Demo案例
import java.util.LinkedHashMap;
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("张三",18);
map.put("李四",10);
map.put("王五",20);
map.put("赵六",21);
System.out.println(map);
}
}
6.TreeMap
6.1 TreeMap特点
不重复、无索引、可排序(按照键的大小默认升序排序,只能对键排序)
6.2 TreeMap集合底层原理
reeMap跟TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序
6.3 TreeMap指定排序规则方式
- 让类实现Comparable接口,重写比较规则
- TreeMap集合有一个有参数构造器,支持创建Comparator比较器对象,以便用来指定比较规则
import java.util.TreeMap;
/**
* 需求:创建一个TreeMap集合,键是学生对象(Student),值是籍贯(String)。
* 学生属性姓名和年龄,按照年龄进行排序并遍历
*/
public class TreeMapDemo {
public static void main(String[] args) {
//方式二: 在new对象的时候使用 比较器 指定排序规则
TreeMap<Student, String> treeMap = new TreeMap<>(
((o1, o2) -> o1.getAge()-o2.getAge()==0? o1.getName().compareTo(o2.getName()): o1.getAge()-o2.getAge()));
treeMap.put(new Student("张三",23),"陕西西安");
treeMap.put(new Student("李四",23),"陕西西安");
treeMap.put(new Student("王五",21),"陕西西安");
treeMap.put(new Student("王五",21),"陕西西安");
System.out.println(treeMap);
}
}
//方式一:让 Student 类实现 Comparable 接口
public class Student implements Comparable{ ... }
7.补充知识:集合嵌套
指的是集合中的元素又是一个集合
- 案例:要求在程序中记住如下省份和其对应的城市信息,记录成功后,要求可以查询出湖北省的城市信息
import java.util.*;
import java.util.function.Consumer;
/**
* 需求: 要求在程序中记住如下省份和其对应的城市信息,记录成功后,要求可以查询出湖北省的城市信息
* 江苏省 = 南京市,扬州市,苏州市,无锡市,常州市
* 湖北省 = 武汉市,孝感市,十堰市,宜昌市,鄂州市
* 河北省 = 石家庄市,唐山市,邢台市,保定市,张家口市
*/
public class MapCityDemo {
public static void main(String[] args) {
HashMap<String, List<String>> map = new HashMap<>();
//存储城市数据
List<String> cities1 = new ArrayList<>();
//存储江苏省的数据
cities1.add("南京市");
cities1.add("扬州市");
cities1.add("苏州市");
cities1.add("无锡市");
cities1.add("常州市");
map.put("江苏省",cities1);
//存储湖北省的数据
List<String> cities2 = new ArrayList<>();
cities2.add("武汉市");
cities2.add("孝感市");
cities2.add("十堰市");
cities2.add("宜昌市");
cities2.add("鄂州市");
map.put("湖北省",cities2);
//存储河北省的数据
List<String> cities3 = new ArrayList<>();
cities3.add("石家庄市");
cities3.add("唐山市");
cities3.add("邢台市");
cities3.add("保定市");
cities3.add("张家口市");
map.put("河北省",cities3);
//遍历map并输出 【湖北省】的城市数据
//遍历一:增强for循环
Set<Map.Entry<String, List<String>>> entries = map.entrySet();
for (Map.Entry<String, List<String>> province : entries) {
String key = province.getKey();
List<String> cities = province.getValue();
if ("湖北省".equals(key)) {
System.out.println(key);
for (String city : cities) {
System.out.println("\t" + city);
}
}
}
System.out.println("=======");
//遍历二:迭代器
Iterator<Map.Entry<String, List<String>>> it = entries.iterator();
while (it.hasNext()){
Map.Entry<String, List<String>> province = it.next();
String key = province.getKey();
if ("湖北省".equals(key)){
System.out.println(key);
List<String> value = province.getValue();
for (String s : value) {
System.out.println("\t"+s);
}
}
}
//遍历三:forEach循环
//Set<Map.Entry<String, List<String>>> entries = map.entrySet();
entries.forEach(new Consumer<Map.Entry<String, List<String>>>() {
@Override
public void accept(Map.Entry<String, List<String>> stringListEntry) {
if ("湖北省".equals(stringListEntry.getKey())){
System.out.println(stringListEntry.getKey());
stringListEntry.getValue().forEach(s -> System.out.println("\t"+s));
}
}
});
}
}
三、Stream流
1.认识Stream
1.1 Stream概述、优势
也叫Stream流,是Jdk8开始新增的一套APl(java.utilstream.*),可以用于操作集合或者数组的数据
优势:Stream流大量的结合了Lambda的语法风格来编程,提供了一种更加强大,更加简单的方式操
作集合或者数组中的数据,代码更简洁,可读性更好
1.2 Stream流处理数据步骤
- 先得到集合或者数组的Stream流
- 然后调用Stream流的方法对数据进行处理
- 获取处理的结果
1.3 Stream流初体验
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
// 需求:把集合中所有以“张”开头,且是3个字的元素存储到一个新的集合
public class Demo {
public static void main(String[] args) {
//1.获取 stream流
Stream<String> stream = Stream.of("张三", "李思思", "王五", "张三", "赵六", "张无忌", "张翠山");
//把流处理后的数据放到一个数组中去 toArray()
//Object[] array = stream.toArray();
//System.out.println(Arrays.toString(array));
//把流处理后的数据 收集到 一个指定的 List集合中
List<String> list = stream.collect(Collectors.toList());
System.out.println(list);
//Set<String> set = stream.collect(Collectors.toSet());
//System.out.println(set);
}
}
2.Stream的常用方法
2.1 获取Stream流
2.1.1 获取集合的Stream流
| Collection提供的方法 | 说明 |
|---|---|
| default Stream stream() | 获取当前集合对象的stream流 |
2.1.2 获取数组的Stream流
| Arrays类提供的如下方法 | 说明 |
|---|---|
| public static Stream stream(T[]array) | 获取当前数组的stream流 |
| Stream类提供的如下方法 | 说明 |
|---|---|
| public static Stream of(T… values) | 获取当前接收数据的stream流 |
2.2 Stream流常见的中间方法
中间方法指的是调用完成后会返回新的Stream流,可以继续使用(支持链式编程)
| Stream提供的常用中间方法 | 说明 |
|---|---|
| Stream filter(Predicate<? super T> predicate) | 用于对流中的数据进行过滤 |
| Stream sorted() | 对元素进行升序排序 |
| Stream sorted(Comparator<? super I> comparator) | 按照指定规则排序[比较器] |
| Stream limit(long maxSize) | 获取前几个元素 |
| Stream skip(long n) | 跳过前几个元素 |
| Stream distinct() | 去除流中重复的元素 |
| Stream map(Eunction<? super I,? extends R> mapper) | 对元素进行加工,并返回对应的新流 |
| static Stream concat(Stream a,Stream b) | 合并a和b两个流为一个流 |
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
// 筛选出 姓张,且名字长度为3的名字并输出
public class StreamDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list,"张三","张三丰","张无忌","李四");
//list.stream()--获取list对应的流,filter()进行筛选
List<String> newList = list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).collect(Collectors.toList());
System.out.println(newList);
}
}
2.3 Stream常见的终结方法
终结方法指的是调用完成后,不会返回新Stream了,没法继续使用流了
| Stream提供的常用终结方法 | 说明 |
|---|---|
| void forEach(Consumer action) | 对此流运算后的元素执行遍历 |
| long count() | 统计此流运算后的元素个数 |
| Optional max(Comparator<? super I> comparator) | 获取此流运算后的最大值元素 |
| Optional min(Comparator<? super I> comparator) | 获取此流运算后的最小值元素 |
- 收集Stream流:是把Stream流操作后的结果转回到集合或者数组中去返回
- Stream流:方便操作集合/数组的手段 集合/数组:才是开发中的目的。
| Stream提供的常用终结方法 | 说明 |
|---|---|
| R collect(Collector collector) | 把流处理后的结果收集到一个指定的集合中去 |
| Object[] toArrav() | 把流处理后的结果收集到一个数组中去 |
| Collectors工具类提供了具体的收集方式 | 说明 |
|---|---|
| public static Collector tolist() | 把元素收集到List集合中 |
| public static Collector toSet() | 把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper , Function valueMapper) | 把元素收集到Map集合中 |
2.4 Stream案例
需求1:请计算出身高超过168的学生有几人
需求2:请找出身高最高的学生对象,并输出
需求3:请找出身高最矮的学生对象,并输出
需求4:请找出身高超过170的学生对象,并放到一个新集合中去返回
需求5:请找出身高超过170的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class StuDemo {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
Student s1 = new Student("蜘蛛精", 26, 172.5);
Student s2 = new Student("蜘蛛精", 26, 172.5);
Student s3 = new Student("紫霞", 23, 167.6);
Student s4 = new Student("白晶晶", 25, 169.0);
Student s5 = new Student("牛魔王", 35, 183.3);
Student s6 = new Student("牛夫人", 34, 168.5);
Collections.addAll(students, s1, s2, s3, s4, s5, s6);
//需求1:请计算出身高超过168的学生有几人。
long count = students.stream()
.filter(stu -> stu.getHeight() > 168)
.count();
System.out.println(count);
//需求2:请找出身高最高的学生对象,并输出
Student stu = students.stream()
.max(((o1, o2) -> (int) (o1.getHeight() * 10 - o2.getHeight() * 10)))
.get();
System.out.println(stu);
//需求3:请找出身高最矮的学生对象,并输出。
Student stu2 = students.stream()
.min(((o1, o2) -> (int) (o1.getHeight() * 10 - o2.getHeight() * 10)))
.get();
System.out.println(stu2);
//需求4:请找出身高超过170的学生对象,并放到一个新集合中去返回。
List<Student> newList = students.stream()
.filter(s -> s.getHeight() > 170)
.collect(Collectors.toList());
System.out.println(newList);
//需求5:请找出身高超过170的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回。
Map<String, Integer> map = students.stream()
.filter(s -> s.getHeight() > 170) //筛选
.distinct() //去除重复名字的
.collect(Collectors.toMap(t -> t.getName(), t -> t.getAge(), (t1, t2) -> t1));//收集到一个Map集合中
System.out.println(map);
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!