Scaling Up Memory Disaggregated Applications with Smart——论文泛读
问题
近期在RDMA网络方面的发展导致了内存分解的趋势。然而,每个计算节点的性能仍然受到网络的限制,特别是当它需要执行大量并发的细粒度远程访问时。根据我们的评估,现有的IOPS受限解聚应用在32个核心以上的规模上性能并不良好,因此无法充分利用当今的多核机器。
挑战
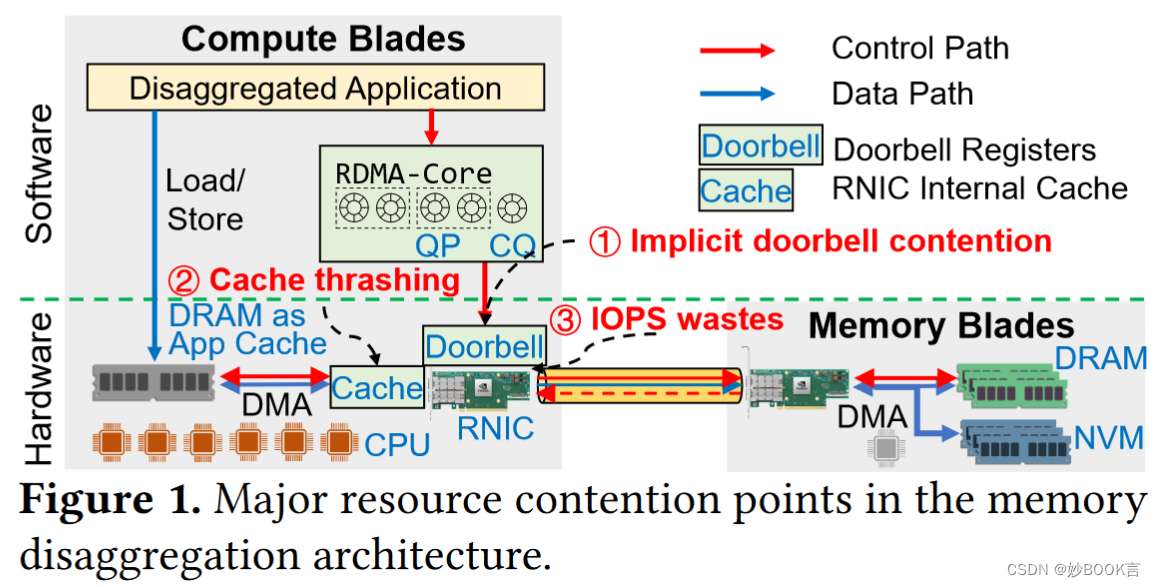
经过对RNIC内部架构的深入分析,我们发现今天的内存分解应用吞吐量受到三个主要的瓶颈的限制:(1) 门铃寄存器的隐式争用;(2) 由于过多未完成的工作请求引起的缓存崩溃; (3) 由于CAS重试失败导致的IOPS浪费。
现有方法局限性
现有的研究 [5, 16, 27, 41] 观察到RDMA操作的吞吐量,特别是依赖可靠连接(RC)的单边操作,随着并行性的增加(即并行执行RDMA操作的线程数量)而无法很好地扩展。研究人员推测这种可扩展性问题可能是由于RNIC内的缓存争用引起的。最近的RNIC设备通过芯片上的SRAM缓存提高了元数据对象访问的性能。由于RNIC必须通过PCIe DMA从DRAM中获取数据,这需要几微秒的时间 [41],所以缓存未命中会导致巨大的性能惩罚。为了缓解这个问题,提出了一种常用的优化方法,称为连接复用 [16, 52, 53],以减少队列对(QP)的总数,因为QP需要建立RC连接,因此需要被缓存以获得良好的性能。与为每个线程分配一个单独的QP不同,使用连接复用,多个线程共享一个QP,以减少资源争用的代价来换取并行性。然而,现有的研究 [16, 27] 已经表明,共享QP导致性能不佳,因为对QP的访问通过锁进行串行化。
本文方法
我们提出了Smart,一个RDMA编程框架,通过提供类似单边RDMA动词的接口来隐藏上述细节。
-
通过通用的线程感知RDMA资源(例如门铃寄存器)分配机制,来解决门铃寄存器的隐式争用。
-
提出了一种基于信用的节流策略,其中深度阈值是根据当前工作负载自动确定的,解决由于过多未完成的工作请求引起的缓存崩溃。
-
提出了一种自适应退避技术,抑制不成功的CAS(compare-and-swap)操作的并发性,解决CAS重试失败导致的IOPS浪费。
我们用44行和16行代码用Smart重构了按部分分解的哈希表(RACE)和持久事务处理系统(FORD)的状态,分别将它们的吞吐量提高了132.4倍和5.2倍。我们还用Smart重构了Sherman(一个最近分解的B+树),并进行了额外的推测性查找优化(更改了48行代码),将其内存访问模式从带宽限制更改为IOPS限制,并将速度提高了2.0倍。
开源代码:https://github.com/hhyx/smart
实验环境
集群中使用了八台机器,每台机器都有两个Intel Xeon Gold 6240R CPU(共96核)、384 GB DRAM(32 GB×12)、1.5 TB Intel Optane DC持久内存(128 GB×12,5)和一个200 Gbps Mellanox ConnectX-6 InfiniBand RNIC。每个RNIC都连接到一个200 Gbps Mellanox InfiniBand交换机,RNIC在我们的测试平台上的硬件限制为110.0 MOP/s。这些机器与Ubuntu 20.04 LTS(Linux内核5.4.0)和 Mellanox OpenFabrics Enterprise Distribution for Linux(MLNX_OFED)v5.3-1.0.0.1 一起安装。
实验对比:吞吐量、延迟、可扩展性、消融实验、减少资源争用方面的有效性
总结
对RNIC内部架构进行深入分析,发现内存分解应用吞吐量受到三个主要的瓶颈的限制:(1) 门铃寄存器的隐式争用;(2) 由于过多未完成的工作请求引起的缓存崩溃; (3) 由于CAS重试失败导致的IOPS浪费。针对3个问题作者分别提出解决方案:通过通用的线程感知RDMA资源(例如门铃寄存器)分配机制,来解决门铃寄存器的隐式争用;提出了一种基于信用的节流策略,其中深度阈值是根据当前工作负载自动确定的,解决由于过多未完成的工作请求引起的缓存崩溃;提出了一种自适应退避技术,抑制不成功的CAS(compare-and-swap)操作的并发性,解决CAS重试失败导致的IOPS浪费。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- “揭秘性能测试工具:优化软件性能的关键秘籍“
- 道可云元宇宙每日资讯|普陀区元宇宙产业联盟成立
- 每日算法打卡:01背包问题 day 13
- 2 python基础系列二-函数
- 使用ArcMap进行实测数据处理
- 分布式之任务调度学习一
- 电压检测芯片适用于哪些应用领域?
- git安装教程 Windows 附安装包链接
- 嵌入式(一)嵌入式系统介绍 | 嵌入式微处理器,嵌入式系统开发流程,嵌入式系统应用
- 用Python编写一个功能强大的爬虫,功能至少要有图片爬取等