机器学习(七)模型选择
1.10模型选择
一个模型可能有很多种情况出现,那么我们如何选择最优的模型呢?
1.10.1那条曲线拟合效果是最好的?

观察上述图示:
利用已知的样本点在图示的坐标轴上画出了绿色的曲线,表示源数据的大致分布状况。假设我们使用后面要学习的线性回归去解决样本点拟合问题, 比如用多项式表示线性回归模型: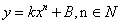 ,当n=0时,y=k,就是图一的平行于x轴的直线,此时该直线不能很好的拟合样本数据;当n=1时,y=kx+B,得到图2的一次直线,我们可以注意到无论怎么调整该直线都不能很好的拟合样本数据;上述n=0或1时是模型的欠拟合情况。当n=3时,
,当n=0时,y=k,就是图一的平行于x轴的直线,此时该直线不能很好的拟合样本数据;当n=1时,y=kx+B,得到图2的一次直线,我们可以注意到无论怎么调整该直线都不能很好的拟合样本数据;上述n=0或1时是模型的欠拟合情况。当n=3时,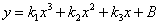 ,得到图3的三次函数拟合曲线,这种情况是能够很好的拟合样本数据;但是,当n=9时,得到图4的拟合曲线。当n取值越高的时候,当前样本的数据能够很好的拟合,但是在新的数据上效果却很差,这时出现了过拟合情况。
,得到图3的三次函数拟合曲线,这种情况是能够很好的拟合样本数据;但是,当n=9时,得到图4的拟合曲线。当n取值越高的时候,当前样本的数据能够很好的拟合,但是在新的数据上效果却很差,这时出现了过拟合情况。
通过上述图大家应该能看到,即便我们确定了使用线性回归模型去处理,我们在选择参数的时候也是有很多种情况。如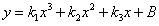 ,可以调整不同的k1、k2和k3的值,同时也对应了不同的拟合直线,我们希望可以从这些参数中找到拟合较好的直线,但不能过分的好,因为我们要考虑当新数据来了模型的分类情况。
,可以调整不同的k1、k2和k3的值,同时也对应了不同的拟合直线,我们希望可以从这些参数中找到拟合较好的直线,但不能过分的好,因为我们要考虑当新数据来了模型的分类情况。
由此我们引入了模型的“泛化”能力的概念。
1.10.2泛化
机器学习的目标是使学得的模型能很好地适用于“新样本”,而不是仅仅在训练样本上工作的很好;即便对聚类这样的无监督学习任务,我们也希望学得的簇划分能适用于没在训练集中出现的样本。学得模型适用于新样本的能力,称为“泛化”(generalization)能力。具有强泛化能力的模型能很好地适用于整个样本空间。(现实任务中的样本空间的规模通常很大,如20 个属性,每个属性有10个可能取值,则样本空间的规模是1020)。
还有一个泛化的概念:
【基础概念】模型具有好的泛化能力指的是:模型不但在训练数据集上表现的效果很好,对于新数据的适应能力也有很好的效果。
当我们讨论一个机器学习模型学习能力和泛化能力的好坏时,我们通常使用过拟合和欠拟合的概念,过拟合和欠拟合也是机器学习算法表现差的两大原因。
【基础概念】过拟合overfitting:模型在训练数据上表现良好,在未知数据或者测试集上表现差。
【基础概念】欠拟合underfitting:在训练数据和未知数据上表现都很差。
1.10.3欠拟合
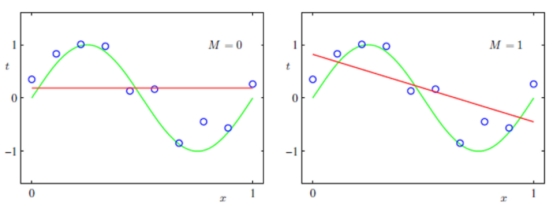
图1和图2都是模型欠拟合的情况:即模型在训练集上表现的效果差,没有充分利用数据,预测准确率很低,拟合结果严重不符合预期。
产生的原因:模型过于简单
出现的场景:欠拟合一般出现在机器学习模型刚刚训练的时候,也就是说一开始我们的模型往往是欠拟合也正是因为如此才有了优化的空间,我们通过不断优化调整算法来使得模型的表达能力更强。
解决办法:(1)添加其他特征项:因为特征项不够而导致欠拟合,可以添加其他特征项来很好的解决。
(2)添加多项式特征,如图(3)我们可以在线性模型中通过添加二次或三次项使得模型的泛化能力更强。
(3)减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,需要减少正则化参数。
1.10.4过拟合
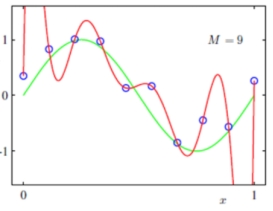
上图是模型过拟合的情况:即模型在训练集上表现的很好,但是在测试集上效果却很差。也就是说,在已知的数据集合中非常好,再添加一些新数据进来效果就会差很多。
产生的原因:可能是模型太过于复杂、数据不纯、训练数据太少等造成。
出现的场景:当模型优化到一定程度,就会出现过拟合的情况。
解决办法:(1)重新清洗数据:导致过拟合一个原因可能是数据不纯导致的,
(2)增大训练的数据量:导致过拟合的另一个原因是训练数据量太小,训练数据占总数据比例太低。
(3)采用正则化方法对参数施加惩罚:导致过拟合的原因可能是模型太过于复杂,我们可以对比较重要的特征增加其权重,而不重要的特征降低其权重的方法。常用的有L1正则和L2正则,我们稍后会提到。
(4)采用dropout方法,即采用随机采样的方法训练模型,常用于神经网络算法中。
注意:模型的过拟合是无法彻底避免的,我们能做的只是缓解,或者说减小其风险,因为机器学习面临的是NP难问题(这列问题不存在有效精确解,必须寻求这类问题的有效近似算法求解),但是有效算法必然是在多项式时间内运行完成的,因此过拟合是不可避免的。在实际的任务中往往通过多种算法的选择,甚至对同一个算法,当使用不同参数配置时,也会产生不同的模型。那么,我们也就面临究竟选择哪一种算法,使用哪一种参数配置?这就是我们在机器学习中的“模型选择(model select)”问题,理想的解决方案当然是对候选模型的泛化误差进行评估,然后选择泛化误差最小的那个模型。我们更详细的模型选择会有专门的专题讲到,如具体的评估方法(交叉验证)、性能度量准则、偏差和方差折中等。
补充:NP难问题
NP是指非确定性多项式(non-deterministic polynomial,缩写NP)。所谓的非确定性是指,可用一定数量的运算去解决多项式时间内可解决的问题。
例如,著名的推销员旅行问题(Travel Saleman Problem or TSP):假设一个推销员需要从香港出发,经过广州,北京,上海,…,等 n 个城市, 最后返回香港。任意两个城市之间都有飞机直达,但票价不等。假设公司只给报销 C 元钱,问是否存在一个行程安排,使得他能遍历所有城市,而且总的路费小于 C?
推销员旅行问题显然是 NP 的。因为如果你任意给出一个行程安排,可以很容易算出旅行总开销。但是,要想知道一条总路费小于 C 的行程是否存在,在最坏情况下,必须检查所有可能的旅行安排! 这将是个天文数字。
迄今为止,这类问题中没有一个找到有效算法。倾向于接受NP完全问题(NP-Complet或NPC)和NP难题(NP-Hard或NPH)不存在有效算法这一猜想,认为这类问题的大型实例不能用精确算法求解,必须寻求这类问题的有效的近似算法。
1.10.5奥卡姆剃刀原则
奥卡姆剃刀原则是模型选择的基本而且重要的原则。
模型是越复杂,出现过拟合的几率就越高,因此,我们更喜欢采用较为简单的模型。这种策略与应用就是一直说的奥卡姆剃刀(Occam’s razor)或节俭原则(principe of parsimony)一致。
奥卡姆剃刀:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取。
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ?留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢不能老盯着手机屏幕,要不时地抬起头,看看老板的位置?
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12468207.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- apache2的虚拟主机的配置
- 2024.1.12每日一题
- 使用CRA(create-react-app)初始化一个完整的项目环境(该初始化项目已上传到本文章的资源)
- 产品分析 | 数据资产目录竞品分析
- 项目代码生成心得
- Unity——VContainer的依赖注入
- JVM性能调优-垃圾收集器G1详解
- 代码生成器技术乱弹五十二,业务优先还是逻辑优先
- 电子学会C/C++编程等级考试2020年12月(一级)真题解析
- 【建议收藏】一文全面解读Linux最常用的解压缩命令(tar、zip、unzip、gzip、guznip、bzip2、bunzip2)