(超详细)5-YOLOV5改进-添加A2Attention注意力机制
发布时间:2024年01月12日
1、在yolov5/models下面新建一个A2Attention.py文件,在里面放入下面的代码
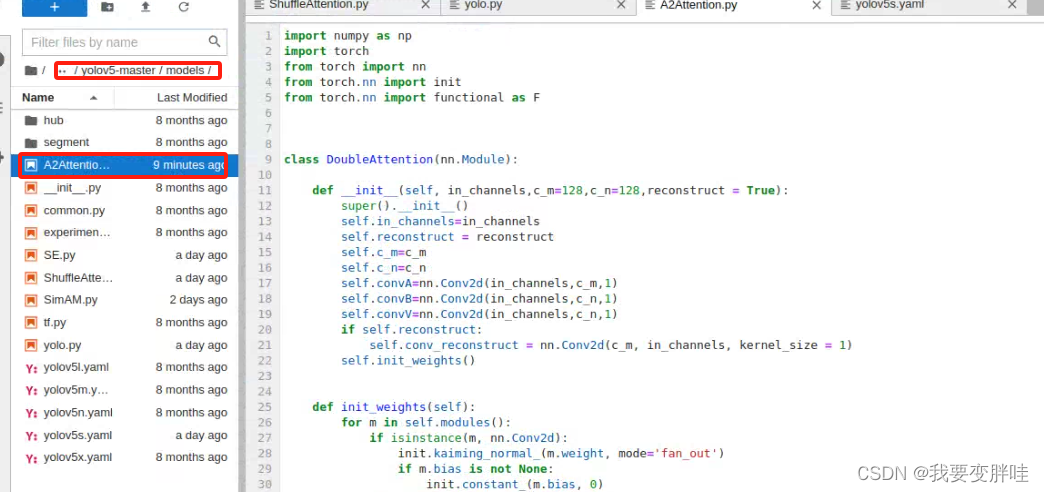
代码如下:
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels,c_m=128,c_n=128,reconstruct = True):
super().__init__()
self.in_channels=in_channels
self.reconstruct = reconstruct
self.c_m=c_m
self.c_n=c_n
self.convA=nn.Conv2d(in_channels,c_m,1)
self.convB=nn.Conv2d(in_channels,c_n,1)
self.convV=nn.Conv2d(in_channels,c_n,1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
assert c==self.in_channels
A=self.convA(x) #b,c_m,h,w
B=self.convB(x) #b,c_n,h,w
V=self.convV(x) #b,c_n,h,w
tmpA=A.view(b,self.c_m,-1)
attention_maps=F.softmax(B.view(b,self.c_n,-1))
attention_vectors=F.softmax(V.view(b,self.c_n,-1))
# step 1: feature gating
global_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*w
tmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,w
if self.reconstruct:
tmpZ=self.conv_reconstruct(tmpZ)
return tmpZ
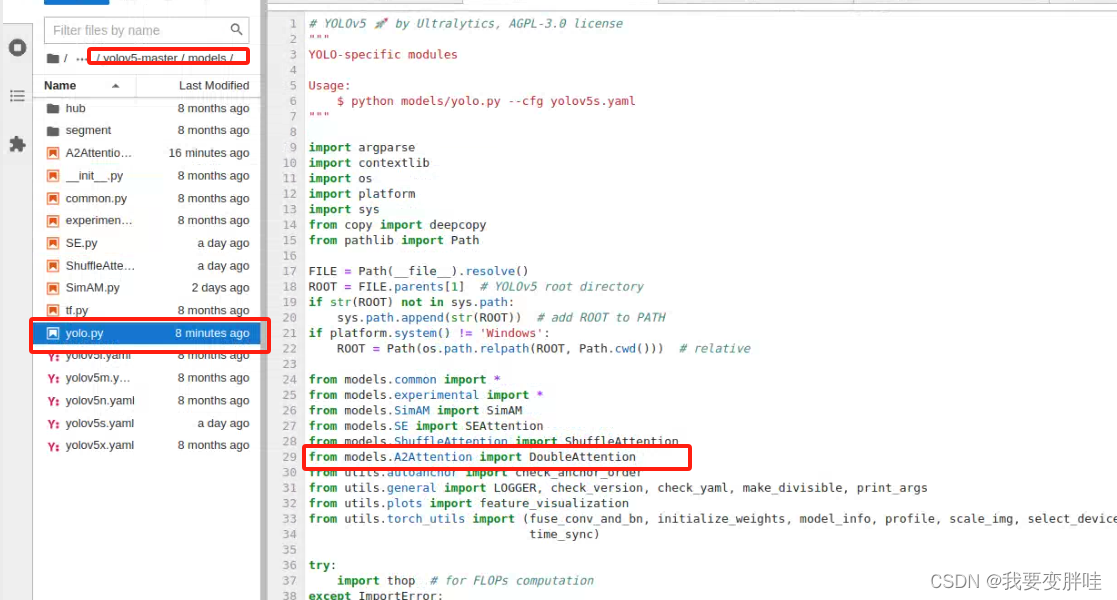
2、找到yolo.py文件,进行更改内容
在29行加一个from models.A2Attention. import DoubleAttention, 保存即可
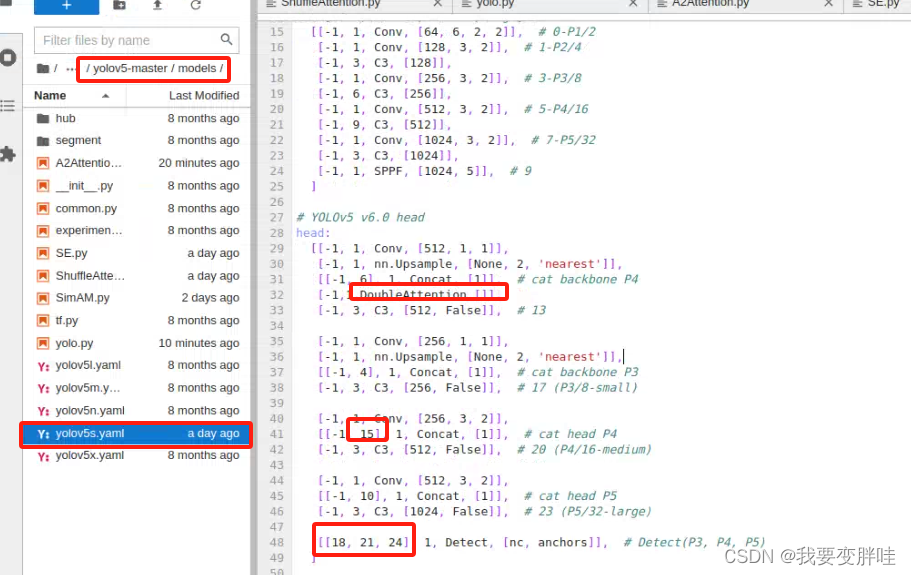
3、找到自己想要更改的yaml文件,我选择的yolov5s.yaml文件(你可以根据自己需求进行选择),将刚刚写好的模块DoubleAttention加入到yolov5s.yaml里面,并更改一些内容。更改如下
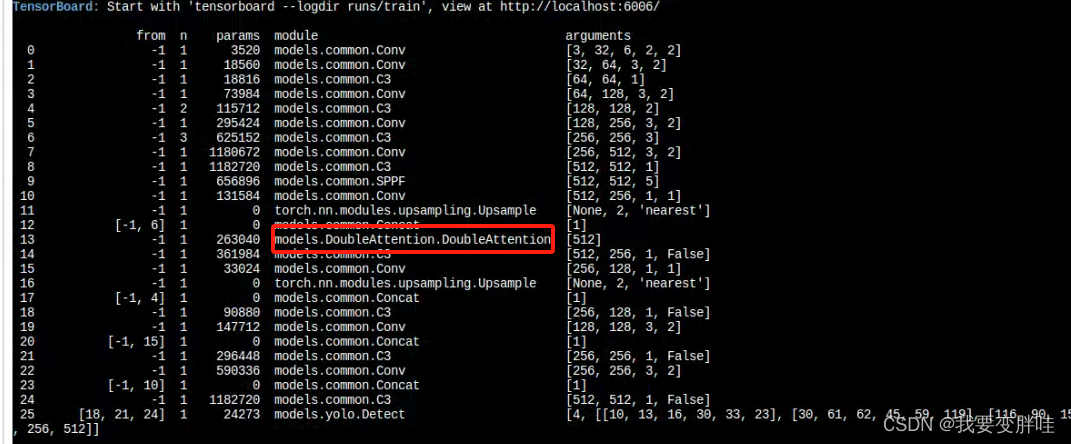
4、在yolo.py里面加入两行代码(335-337)
保存即可!

运行一下
文章来源:https://blog.csdn.net/qq_44421796/article/details/135561444
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 爬虫之牛刀小试(三):爬取中国天气网全国天气
- 七、Redis 缓存 —— 超详细操作演示!
- 《Aspect-Sentiment-Multiple-Opinion Triplet Extraction》论文阅读
- win10安装linux子系统失败问题、成功后迁移子系统、卸载子系统、修改子系统默认登录用户
- 基于java的土地档案管理系统设计与实现
- JavaScript中作用域的理解
- Python 环境部署
- Linux Mii management/mdio子系统分析之二 mdio总线-设备-驱动模型分析
- Ribbon负载均衡
- c 小熊猫 c++ IDE编译ffmpeg 设置