总结不同方案实现-LLM数据库查询-即Text2SQL
文本到SQL模型的设计通常具有挑战性,因为它们需要在不同的数据库上工作,并考虑各种用户文本输入和数据库结构。由于文本到SQL任务的复杂性,对其性能的全面评估需要考虑多种场景。随着大规模语言模型越来越受到关注,它们已成为自然语言处理中的重要组成部分。随着预训练模型规模的增长,它们的使用也在逐渐发生变化。本文主要谈论大语言模型背景下,如何与数据库交互-即利用大模型生成sql,并提升sql的准确性和复杂性。
随着NLP的发展,
1 准备:使用的数据库
本文研究基于ClickHouse,当然可以选其他数据库进行连接。
CH_HOST = 'http://localhost:8123' # default address
def get_clickhouse_data(query, host = CH_HOST, connection_timeout = 1500):
r = requests.post(host, params = {'query': query},
timeout = connection_timeout)
return r.text这段代码主要设置了与数据库连接的函数get_clickhouse_data(query),用于与数据库交互。我们将把这个函数的结果传递给LLM。因此,获取任何输出 DB 返回都是可以的,无论它是否是错误。LLM就能妥善处理。
使用到的表结构如下:我们只需要几个表来表示基本电子商务产品的数据模型。我们将使用用户列表 (?ecommerce.users) 及其会话 (?ecommerce.sessions)。
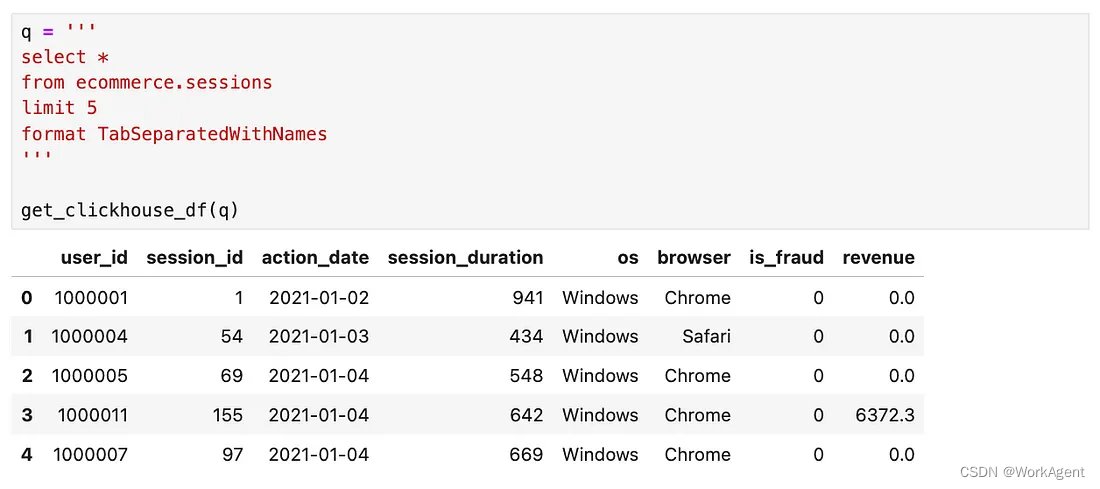
会话 (?ecommerce.sessions)表如下:
用户列表 (?ecommerce.users) 如下
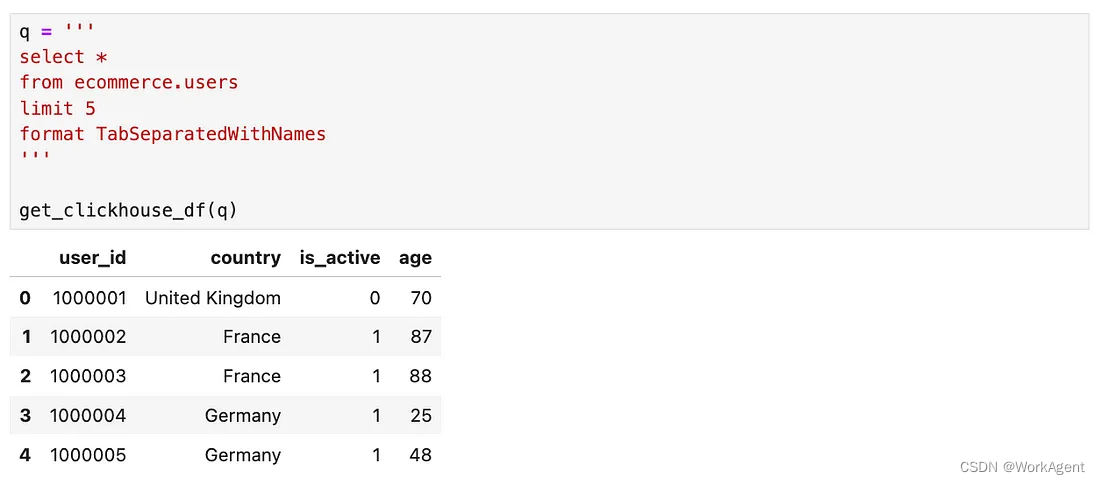
?现在基于已有的两个表,接下来将使用LLM与之交互。
2 现有技术
LLM 代理的核心思想是使用 LLM 作为推理引擎来定义要采取的操作集。在经典方法中,我们对一系列操作进行硬编码,但对于代理,我们为模型提供工具和任务,并让她决定如何实现它们。
事实上,这就是人类智能的运作方式:我们将内心的声音推理与面向任务的行动结合起来。假设您需要做饭。你将使用推理来定义一个计划(“客人将在 30 分钟内到来,我只有时间煮意大利面”),调整它(“本已经成为素食主义者,我应该为他点一些东西”)或决定委托哪些任务相当于外部工具(“意大利面没有了,我需要让我的伙伴去买”)。同时,你将通过行动来使用一些工具(向伙伴寻求帮助或使用搅拌机)或获取一些信息(在互联网上查找你需要煮意大利面多少分钟才??能使其有嚼劲)。因此,对LLM使用类似的方法是合理的,因为它适用于人类(毫无疑问是 AGI)。
自 ReAct 以来,LLM 代理有很多不同的方法。它们的不同之处在于用于设置模型推理的提示、我们如何定义工具、输出格式、处理有关中间步骤的内存等。以下是一些流行的方法:
- OpenAI functions
- AutoGPT
- BabyAGI
- Plan-and-execute agent
在Text2SQL领域,本文将利用上述方法综合测试,对文本生成SQL进行实验和总结。
?
3?第一个版本-构建代理:主要使用函数
LLM代理的核心组成部分是:
- 提示指导模型的推理。
- 模型可以使用的工具。
- 记忆—一种将先前迭代传递给模型的机制。
对于第一个版本的 LLM 代理,我们将使用 OpenAI 函数作为框架来构建代理。?
3.1 定义工具
让我们从定义机器人的工具开始。让我们想想我们的LLM数据分析师可能需要哪些信息才能回答问题:
- 表列表 - 我们可以将其放在系统提示符中,以便模型对我们拥有的数据有一定的了解,并且不需要每次都为其执行工具
- 表的列列表,以便模型可以理解数据模式
- 表中列的顶部值,以便模型可以查找过滤器的值
- SQL查询执行的结果才能得到实际的数据。
?为了在LangChain中定义工具,我们需要使用@tool装饰器来实现函数。我们将使用 Pydantic 指定每个函数的参数模式,以便模型知道要传递给函数的内容。
下面的代码定义了三个工具:execute_sql、get_table_columns和get_table_column_distr。
from langchain.agents import tool
from pydantic import BaseModel, Field
from typing import Optional
class SQLQuery(BaseModel):
query: str = Field(description="SQL query to execute")
@tool(args_schema = SQLQuery)
def execute_sql(query: str) -> str:
"""Returns the result of SQL query execution"""
return get_clickhouse_data(query)
# 主要功能:查询数据库表信息。不同数据库的系统表不一致,需要根据不同数据库进行设置。
class SQLTable(BaseModel):
database: str = Field(description="Database name")
table: str = Field(description="Table name")
@tool(args_schema = SQLTable)
def get_table_columns(database: str, table: str) -> str:
"""Returns list of table column names and types in JSON"""
q = '''
select name, type
from system.columns
where database = '{database}'
and table = '{table}'
format TabSeparatedWithNames
'''.format(database = database, table = table)
return str(get_clickhouse_df(q).to_dict('records'))
# 主要功能:查询表结构:列信息。
class SQLTableColumn(BaseModel):
database: str = Field(description="Database name")
table: str = Field(description="Table name")
column: str = Field(description="Column name")
n: Optional[int] = Field(description="Number of rows, default limit 10")
@tool(args_schema = SQLTableColumn)
def get_table_column_distr(database: str, table: str, column: str, n:int = 10) -> str:
"""Returns top n values for the column in JSON"""
q = '''
select {column}, count(1) as count
from {database}.{table}
group by 1
order by 2 desc
limit {n}
format TabSeparatedWithNames
'''.format(database = database, table = table, column = column, n = n)
return str(list(get_clickhouse_df(q)[column].values))我们将使用 OpenAI 函数并需要转换我们的工具。另外,我将我们的工具包保存在字典中。执行工具来获取观察结果时会很方便。
from langchain.tools.render import format_tool_to_openai_function
# converting tools into OpenAI functions
sql_functions = list(map(format_tool_to_openai_function,
[execute_sql, get_table_columns, get_table_column_distr]))
# saving tools into a dictionary for the future
sql_tools = {
'execute_sql': execute_sql,
'get_table_columns': get_table_columns,
'get_table_column_distr': get_table_column_distr
}?3.2 定义Chain
我们已经为该模型创建了工具。现在,我们需要定义Chain。我们将使用最新的 GPT 4 Turbo,它也经过了微调以与这些功能一起使用。让我们初始化一个聊天模型。
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview')\
.bind(functions = sql_functions)?下一步是定义由系统消息和用户问题组成的提示。我们还需要MessagesPlaceholder为模型将使用的观察列表设置一个位置。
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
system_message = '''
You are working as a product analyst for the e-commerce company.
Your work is very important, since your product team makes decisions based on the data you provide. So, you are extremely accurate with the numbers you provided.
If you're not sure about the details of the request, you don't provide the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
All the data is stored in SQL Database. Here is the list of tables (in the format <database>.<table>) with descriptions:
- ecommerce.users - information about the customers, one row - one customer
- ecommerce.sessions - information about the sessions customers made on our web site, one row - one session
'''
analyst_prompt = ChatPromptTemplate.from_messages(
[
("system", system_message),
("user", "{question}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)?
我们已将数据库中的表列表添加到提示中,以便模型至少对我们的数据库信息有一些了解。
我们已具备所有构建模块,并已准备好建立Chain。输入参数是用户消息和中间步骤(先前的消息、函数调用和观察)。将输入参数传递给提示符,用于format_to_openai_function_messages将它们转换为预期的格式。然后,我们将所有内容传递给 LLM,最后,使用输出解析器OpenAIFunctionsAgentOutputParser。
以下是代码结构:
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
analyst_agent = (
{
"question": lambda x: x["question"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(x["intermediate_steps"]),
}
| analyst_prompt
| llm
| OpenAIFunctionsAgentOutputParser()
)3.3 开始执行
我们已经定义了我们的主要Chain。让我们尝试调用它。
analyst_agent.invoke({"question": "How many active customers from the United Kingdom do we have?",
"intermediate_steps": []})
# AgentActionMessageLog(
# tool='execute_sql',
# tool_input={'query': "SELECT COUNT(DISTINCT user_id) AS active_customers_uk FROM ecommerce.sessions WHERE country = 'United Kingdom' AND active = TRUE"},
# log='\nInvoking: `execute_sql` with `{\'query\': "SELECT COUNT(DISTINCT user_id) AS active_customers_uk FROM ecommerce.sessions WHERE country = \'United Kingdom\' AND active = TRUE"}`\n\n\n',
# message_log=[AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{"query":"SELECT COUNT(DISTINCT user_id) AS active_customers_uk FROM ecommerce.sessions WHERE country = \'United Kingdom\' AND active = TRUE"}', 'name': 'execute_sql'}})]
# )如果我们查看tool_input,我们可以看到模型想要执行以下查询。
SELECT COUNT(DISTINCT user_id) AS active_customers_uk
FROM ecommerce.sessions
WHERE country = 'United Kingdom' AND active = TRUE该查询看起来不错,但使用了错误的列名:active而不是is_active.?看看 LLM 是否能够从这个错误中恢复并返回结果将会很有趣。
- 我们可以手动一步步执行,但是自动化会更方便。
- 如果
AgentActionMessageLog返回对象,我们需要调用一个工具,将观察添加到agent_scratchpad,并再次调用该链。 - 如果我们得到了
AgentFinish对象,我们就可以终止执行,因为我们有了最终的答案。
?我还将在十次迭代后添加一个中断,以避免潜在的无限循环。代码如下:
from langchain_core.agents import AgentFinish
# setting initial parameters
question = "How many active customers from the United Kingdom do we have?"
intermediate_steps = []
num_iters = 0
while True:
# breaking if there were more than 10 iterations
if num_iters >= 10:
break
# invoking the agent chain
output = analyst_agent.invoke(
{
"question": question,
"intermediate_steps": intermediate_steps,
}
)
num_iters += 1
# returning the final result if we got the AgentFinish object
if isinstance(output, AgentFinish):
model_output = output.return_values["output"]
break
# calling tool and adding observation to the scratchpad otherwise
else:
print(f'Executing tool: {output.tool}, arguments: {output.tool_input}')
observation = sql_tools[output.tool](output.tool_input)
print(f'Observation: {observation}')
print()
intermediate_steps.append((output, observation))
print('Model output:', model_output)我在输出中添加了一些工具使用情况的日志记录,以查看执行情况。此外,您始终可以使用 LangChain 调试模式来查看所有调用。
执行的结果是,我们得到了以下输出。
Executing tool: execute_sql, arguments: {'query': "SELECT COUNT(*) AS active_customers_uk FROM ecommerce.users WHERE country = 'United Kingdom' AND active = TRUE"}
Observation: Code: 47. DB::Exception: Missing columns: 'active'
while processing query: 'SELECT count() AS active_customers_uk
FROM ecommerce.users WHERE (country = 'United Kingdom') AND (active = true)',
required columns: 'country' 'active', maybe you meant: 'country'.
(UNKNOWN_IDENTIFIER) (version 23.12.1.414 (official build))
Executing tool: get_table_columns, arguments: {'database': 'ecommerce', 'table': 'users'}
Observation: [{'name': 'user_id', 'type': 'UInt64'}, {'name': 'country', 'type': 'String'},
{'name': 'is_active', 'type': 'UInt8'}, {'name': 'age', 'type': 'UInt64'}]
Executing tool: execute_sql, arguments: {'query': "SELECT COUNT(*) AS active_customers_uk FROM ecommerce.users WHERE country = 'United Kingdom' AND is_active = 1"}
Observation: 111469
Model output: We have 111,469 active customers from the United Kingdom.因此,模型尝试执行 SQL,但收到错误:没有列active。然后,它决定查看表模式,相应地更正查询,并得到结果。
这是一个相当不错的表现。我自己也有同样的行为方式。我通常首先尝试回忆或猜测列名,只有在第一次尝试失败时才检查文档。
4?第二个版本-研究ReAct 代理
我们可以利用模块化框架的优势:我们只需要更改一个参数agent = AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION。
代码如下所示:
system_message = system_message + '''\n您可以访问以下工具:'''
agent_kwargs = {
"prefix" : system_message
}
Analyst_agent_react = initialize_agent(
llm = ChatOpenAI(温度= 0.1 , model = 'gpt-4-1106-preview ' )、
agent = AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION、
tools = [execute_sql、get_table_columns、get_table_column_distr]、
agent_kwargs = agent_kwargs、
verbose = True、
max_iterations = 10、
early_stopping_method = 'generate'
)
Analyst_agent_react.run( "我们有多少来自英国的活跃客户?" )尽管模型遵循不同的路径(从理解表模式开始,然后执行 SQL),但它得到了相同的结果。
?
5 第三个版本:计划与执行代理
此方案灵感来自 BabyAGI 框架和论文“Plan-and-Solve Prompting”,该代理遵循“计划和执行”方法。这种方法的特点是代理首先尝试计划接下来的步骤,然后执行它们。
该方法有两个组成部分:
- Planner——一个常规的大型语言模型,其主要目标——只是为了推理和计划
- 执行者——行动代理,一个LLM,拥有一套可用于行动的工具。
?这种方法的优点是可以进行分离:一个模型专注于计划(推理),而另一个模型专注于执行(行动)。它更加模块化,并且有可能您可以使用针对您的特定任务进行微调的更小、更便宜的模型。然而,这种方法也会生成更多的 LLM 调用,因此如果我们使用 ChatGPT,成本会更高。
代码如下:
Analyst_agent_plan_and_execute = PlanAndExecute(
planner=planner,
executor=executor
)
Analyst_agent_plan_and_execute.run( "我们有多少来自英国的活跃客户?" )from langchain_experimental.plan_and_execute import PlanAndExecute, load_agent_executor, load_chat_planner
model = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview')
planner = load_chat_planner(model)
executor = load_agent_executor(model,
tools = [execute_sql, get_table_columns, get_table_column_distr],
verbose=True)
Analyst_agent_plan_and_execute = PlanAndExecute(
planner=planner,
executor=executor
)
Analyst_agent_plan_and_execute.run( "我们有多少来自英国的活跃客户?" )调用返回错误:RateLimitError: Error code: 429 — {'error': {'message': 'Request too large for gpt-4–1106-preview in organization on tokens_usage_based per min: Limit 150000, Requested 235832.', 'type': 'tokens_usage_based', 'param': None, 'code': 'rate_limit_exceeded'}}。
这是一个很好的例子,说明了代理将问题过于复杂化并涉及太多细节的情况。它查询了表中所有数据进行分析。
6?第四个版本:BabyAGI 代理与工具
这种方法使用检索,因此我们需要建立向量存储和嵌入模型。我使用开源轻量级Chroma进行存储和 OpenAI 嵌入。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embedding = OpenAIEmbeddings()
persist_directory = 'vector_store'
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embedding
)首先,我们将创建一个 TO-DO 链,稍后将其用作执行器的工具。
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
todo_prompt_message = '''
You are a planner who is an expert at coming up with a todo list for
a given objective. Come up with a todo list for this objective: {objective}
'''
todo_prompt = PromptTemplate.from_template(todo_prompt_message)
todo_chain = LLMChain(llm=OpenAI(temperature=0.1,
model = 'gpt-4-1106-preview'), prompt=todo_prompt)然后,我们将创建相应的工具和用于提示的代理,代码如下。
from langchain.agents import AgentExecutor, Tool, ZeroShotAgent
from langchain.prompts import PromptTemplate
tools = [
execute_sql,
get_table_columns,
get_table_column_distr,
Tool(
name="TODO",
func=todo_chain.run,
description="useful for when you need to come up with todo lists. Input: an objective to create a todo list for. Output: a todo list for that objective. Please be very clear what the objective is!",
)
]
prefix = """
You are an AI who performs one task based on the following objective: {objective}. Take into account these previously completed tasks: {context}.
You are asked questions related to analytics for e-commerce product.
Your work is very important, since your product team makes decisions based on the data you provide. So, you are extremely accurate with the numbers you provided.
If you're not sure about the details of the request, you don't provide the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
All the data is stored in SQL Database. Here is the list of tables (in the format <database>.<table>) with descriptions:
- ecommerce.users - information about the customers, one row - one customer
- ecommerce.sessions - information about the sessions customers made on our web site, one row - one session
"""
suffix = """Question: {task}
{agent_scratchpad}"""
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["objective", "task", "context", "agent_scratchpad"],
)
llm = OpenAI(temperature=0.1)
llm_chain = LLMChain(llm=llm, prompt=prompt)
tool_names = [tool.name for tool in tools]
analyst_agent_babyagi = ZeroShotAgent(llm_chain=llm_chain, allowed_tools=tool_names)
analyst_agent_babyagi_executor = AgentExecutor.from_agent_and_tools(
agent=analyst_agent_babyagi, tools=tools, verbose=True
)最后一步是定义 BabyAGI 执行器并运行它。
from langchain_experimental.autonomous_agents import BabyAGI
baby_agi = BabyAGI.from_llm(
llm=llm,
vectorstore=vectordb,
task_execution_chain=analyst_agent_babyagi_executor,
verbose=True,
max_iterations=10
)
baby_agi("Find, how many active customers from the United Kingdom we have.")结果发现:
该模型决定不使用 TO-DO 函数创建待办事项列表,而是跳转到查询 SQL。但是,第一个查询不正确。该模型尝试恢复并调用get_table_columns函数来获取列名称,但未能遵循架构。它们无法遵循结构。
7 第五个版本:带工具的 AutoGPT 代理
同样,我们需要为中间步骤设置向量存储。此处省略代码,同上。
在这种情况下,我们再次无法为模型指定任何提示。让我们尝试在没有任何具体指导的情况下使用它。但让我们添加该get_tables工具,以便模型可以看到所有可用的表。我希望它能帮助模型编写正确的 SQL 查询。
@tool()
def get_tables() -> str:
"""Returns list of tables in the format <database>.<table>"""
return ['ecommerce.users', 'ecommerce.sessions']让我们创建一个 AutoGPT 代理,它就像一个函数调用一样简单。然后,让我们执行它并看看它是如何工作的。
from langchain_experimental.autonomous_agents import AutoGPT
analyst_agent_autogpt = AutoGPT.from_llm_and_tools(
ai_name="Harry",
ai_role="Assistant",
tools= [execute_sql, get_table_columns,
get_table_column_distr, get_tables],
llm=ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
memory=vectordb.as_retriever(),
)
analyst_agent_autogpt.chain.verbose = True
analyst_agent_autogpt.run(["Find how many active customers from the United Kingdom we have."])该模型能够得出正确的答案:“来自英国的活跃客户数量为 111469。”
阅读提示很有趣,因为我们使用了默认提示。您可以通过 访问它analyst_agent_autogpt.chain.prompt。
可以看到这个模型通过向量存储具有长期记忆。并且具有由思想、理由、计划、批评、总结等组成的综合推理。让我们看看模型的推理(只过滤了模型的响应)。所以,它遵循了与之前成功代理相同的方式。
{
"thoughts": {
"text": "To find the number of active customers from the United Kingdom, I need to identify the relevant database and table that contains customer information. Once I have that, I can look for columns that might indicate customer activity and country. The first step is to list all the available tables.",
"reasoning": "Understanding the structure of the database is essential before I can execute a query to find the active customers. Listing tables is a logical first step to identify where customer data might be stored.",
"plan": "- Use the get_tables command to list all available tables.\n- Identify the table that likely contains customer information.\n- Use get_table_columns to understand the structure of the customer table.\n- Execute an SQL query to count active UK customers.",
"criticism": "I need to ensure that I'm efficient with the commands I use, aiming to gather the necessary information in as few steps as possible.",
"speak": "I am now going to list all the available tables to find where customer information is stored."
},
"command": {
"name": "get_tables",
"args": {}
}
}
{
"thoughts": {
"text": "The 'ecommerce.users' table is likely to contain information about the customers. To find the number of active customers from the United Kingdom, I need to understand the structure of this table, specifically looking for columns that might indicate whether a customer is active and their country.",
"reasoning": "Knowing the structure of the 'users' table will help me determine which columns to use in an SQL query to count active UK customers.",
"plan": "- Use the get_table_columns command to get the structure of the 'ecommerce.users' table.\n- Identify columns that indicate customer activity and country.\n- Formulate an SQL query to count active UK customers based on the identified columns.",
"criticism": "I must continue to be efficient with my commands, ensuring that each step brings me closer to the goal without unnecessary actions.",
"speak": "I will now retrieve the structure of the 'ecommerce.users' table to identify the relevant columns for active customers and their country."
},
"command": {
"name": "get_table_columns",
"args": {
"database": "ecommerce",
"table": "users"
}
}
}
{
"thoughts": {
"text": "With the structure of the 'ecommerce.users' table known, I can see that there are columns for 'country' and 'is_active', which are necessary to identify active customers from the United Kingdom.",
"reasoning": "The 'country' column will allow me to filter customers by their country, and the 'is_active' column will allow me to filter customers by their activity status. With this information, I can construct an SQL query to count the number of active customers from the UK.",
"plan": "- Execute an SQL query using the 'execute_sql' command to count the number of active customers from the United Kingdom.\n- The query will count rows where 'country' is 'United Kingdom' and 'is_active' is true (1).",
"criticism": "I need to ensure that the SQL query is correctly formulated to retrieve the exact information needed without any errors.",
"speak": "I am now ready to execute an SQL query to count the number of active customers from the United Kingdom."
},
"command": {
"name": "execute_sql",
"args": {
"query": "SELECT COUNT(*) FROM ecommerce.users WHERE country = 'United Kingdom' AND is_active = 1"
}
}
}
{
"thoughts": {
"text": "I have successfully executed the SQL query and obtained the number of active customers from the United Kingdom, which is 111,469.",
"reasoning": "The goal was to find the number of active customers from the UK, and the SQL query has provided this information.",
"plan": "- Since the goal has been achieved, the next step is to use the 'finish' command to signal that I have completed all my objectives.",
"criticism": "There is no need for further action or commands as the objective has been met.",
"speak": "I have found the number of active customers from the United Kingdom and am ready to finish the task."
},
"command": {
"name": "finish",
"args": {
"response": "The number of active customers from the United Kingdom is 111,469."
}
}
}
总体而言,AutoGPT 看起来是一种可行的方法。不过,仍然认为目前构建代理最可靠的方法是通过 OpenAI 函数。因为AutoGPT过程是不可控的。
8 第六个版本:LangChain 自己的 SQL 代理实现—— SQLDatabaseChain
以下是使用LangChain自己模块的方法:
uri = 'clickhouse+native://localhost/ecommerce'
db = SQLDatabase.from_uri(uri)
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0))
agent_executor = create_sql_agent(
llm=ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
toolkit=toolkit,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS
)
agent_executor.run("How many active customers from the United Kingdom do we have?")很顺利地得到答案:
> Entering new AgentExecutor chain...
Invoking: `sql_db_list_tables` with ``
sessions, users
Invoking: `sql_db_schema` with `users`
CREATE TABLE users (
user_id UInt64,
country String,
is_active UInt8,
age UInt64
) ENGINE = Log
/*
3 rows from users table:
user_id country is_active age
1000001 United Kingdom 0 70
1000002 France 1 87
1000003 France 1 88
*/
Invoking: `sql_db_query` with `SELECT COUNT(*) FROM users WHERE country = 'United Kingdom' AND is_active = 1`
[(111469,)]We have 111,469 active customers from the United Kingdom.
> Finished chain.
'We have 111,469 active customers from the United Kingdom.'其实这里langchain中两种方式,第一种构建chain,执行chain.run(question)。第二种是toolkit = SQLDatabaseToolkit(db=db, llm=llm) 然后构建Agent使用toolkit方法。这里是直接使用的第二种。
langchain文档中关于sql_agent的详细解释:
9 总结
本文探究如何创建不同类型的代理实现text2sql。我们已经实现了一个由 LLM 支持的代理,可以完全从头开始使用 SQL 数据库。然后,我们利用高级 LangChain 工具通过几个函数调用来实现相同的结果。我们可以添加数据库Agent作为 LLM 支持的分析师的工具。这将是我们的一项技能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 苍穹外卖项目笔记(10)— 订单处理、客户催单
- 用贪心算法编程求解任务安排问题
- 工厂方法?按图索骥!
- 如何解决推广难 用户粘性低? 链动+消费增值 你可以借鉴一下
- Pipeline 助您轻松驾驭海量数据!
- springboot集成cas客户端
- 官宣!DevExpress Blazor UI组件,支持全新的.NET 8渲染模式
- C语言字符串函数
- Java Bean Validation规范
- AutoCAD2023+天正建筑T20V9.0+南方CASS11安装教程