代码链:使用语言模型增强代码模拟器进行推理
英文原文地址:?Chain of Code












以下内容是对Chain of Code网址内容的翻译
Abstract
代码提供了一般的语法结构,用于构建复杂的程序并在与代码解释器配对时执行精确的计算。我们假设语言模型(LM)可以利用编写代码的方式改进思维链推理,不仅适用于逻辑和算术任务,还适用于语义任务(尤其是那些混合了逻辑和语义的任务)。
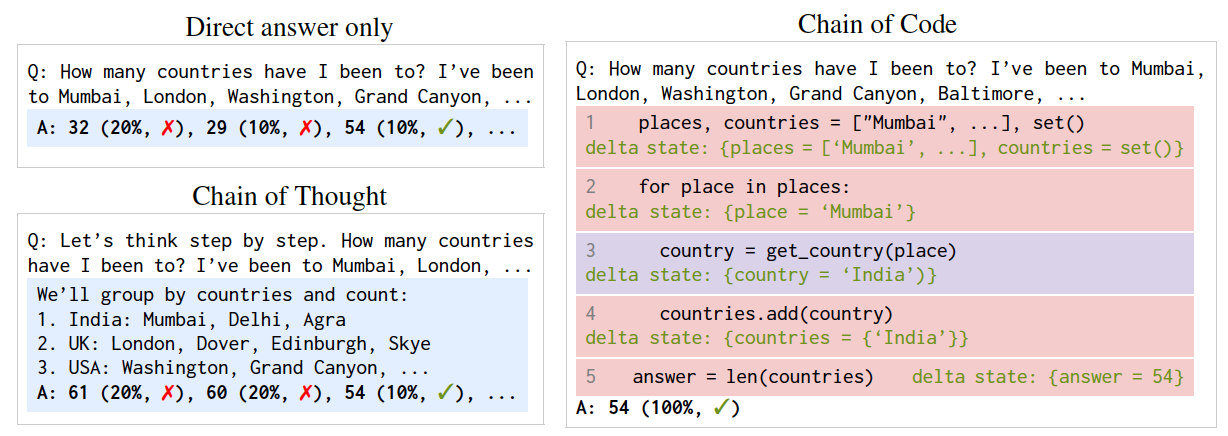
例如,考虑提示一个LM编写代码来计算它在一篇文章中检测到讽刺的次数:LM可能难以编写一个可由解释器执行的"detect_sarcasm(string)"实现(处理边缘情况可能是不可逾越的)。然而,如果LM不仅编写代码,而且还有选择性地"模拟"解释器,通过生成"detect_sarcasm(string)"和其他无法执行的代码行的预期输出,LM仍然可以产生一个有效的解决方案。
在这项工作中,我们提出了Code链(CoC),这是一个简单但出奇有效的扩展,可以改进LM的代码推理能力。其核心思想是鼓励LM将程序中的语义子任务格式化为灵活的伪代码,解释器可以明确捕捉到未定义行为,并将其交给LM进行模拟(作为"LMulator")。实验证明,CoC在各种基准测试中优于思维链和其他基准线;在BIG-Bench Hard上,Code链的准确率达到了84%,比思维链提高了12%。CoC适用于大型和小型模型,并通过"以代码思考"扩大了LM能够正确回答的推理问题的范围。
介绍
我们提出了代码链(CoC),这是一种简单但令人惊讶的有效扩展,可以改进语言模型(LM)代码驱动的推理。它扩大了 LM 可以通过“代码思考”正确回答的推理问题的范围。
关键思想是鼓励 LM 将程序中的语义子任务格式化为灵活的伪代码,解释器可以显式捕获未定义的行为并转交给 LM 进行模拟(作为“LMulator”)。

方法
与以前的推理方法相比,代码链首先 (d) 生成代码或伪代码来解决问题,然后 (e) 如果可能的话,使用代码解释器执行代码,否则使用 LMulator(语言模型模拟代码)执行代码。蓝色突出显示表示 LM 生成。红色突出显示表示 LM 生成的代码正在由解释器执行。紫色突出显示表示 LMulator 通过绿色程序状态模拟代码。

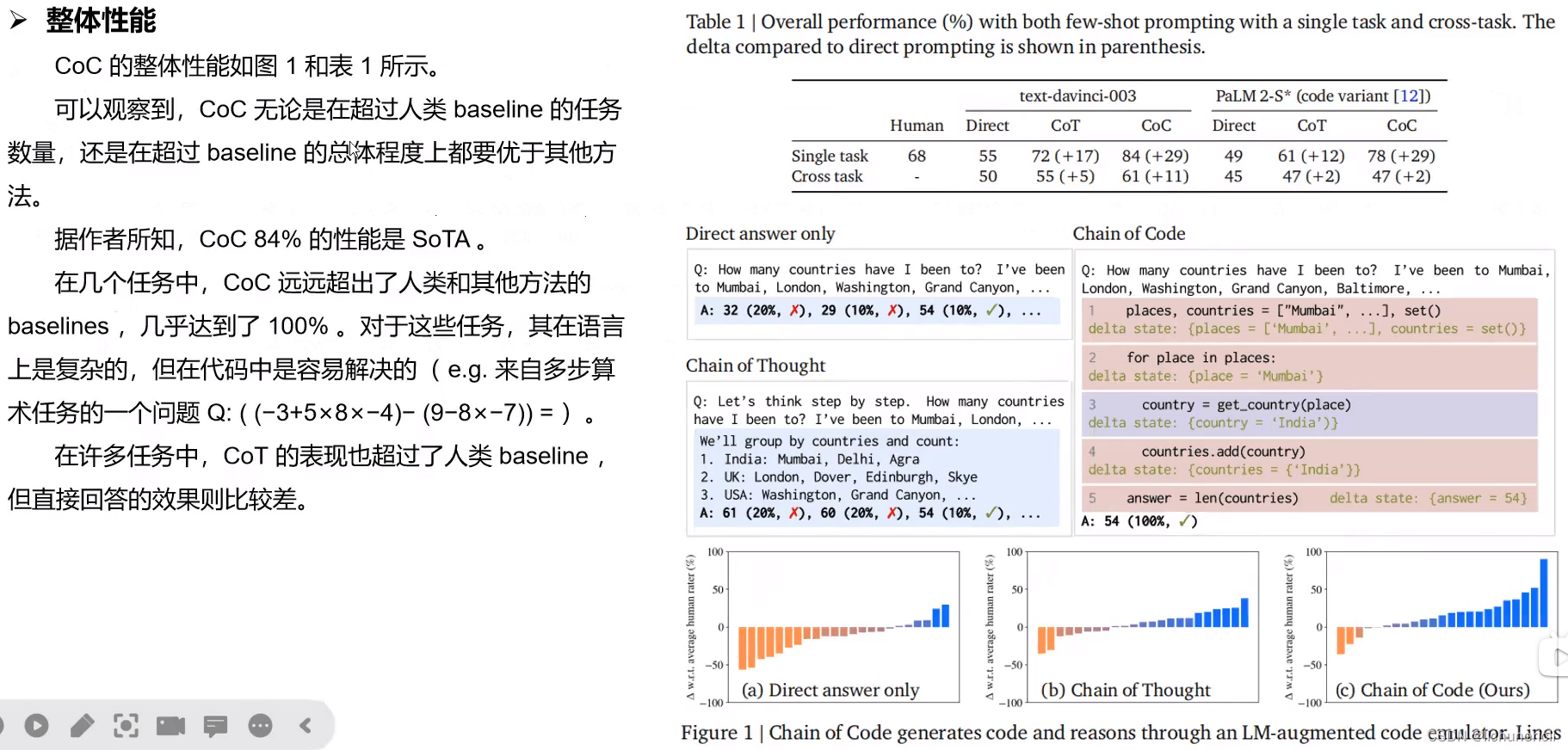
语言推理结果
在 BIG-Bench Hard (BBH) 上,Chain of Code 达到了 84%,比 Chain of Thought 提高了 12%,达到了新的最先进水平。此外,它在 23 项任务中的 18 项中优于人类评分者的平均水平。

对于 BBH 的 NLP 子集,Chain of Code 的表现与 Chain of Thought 相当,对于 BBH 的算法子集,甚至超过了最好的人类评分者。

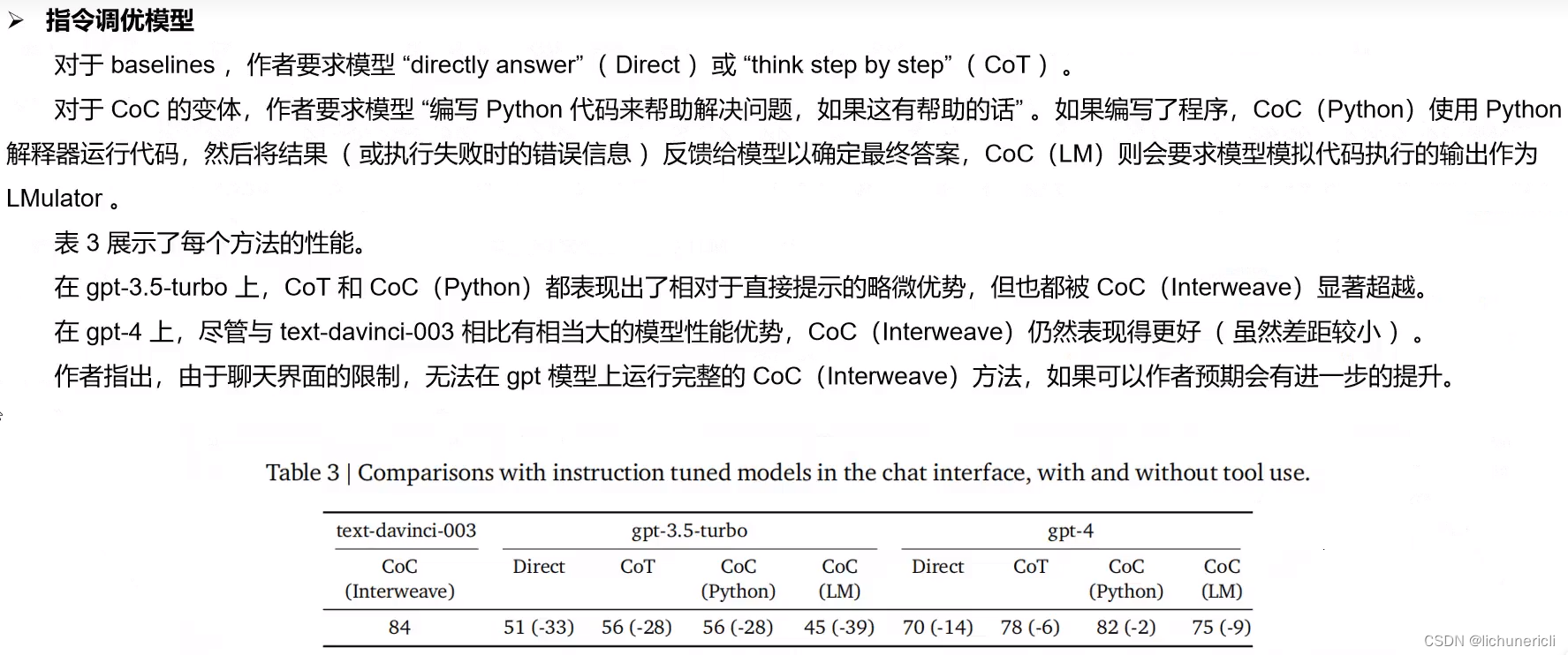
基于 text-davinci-003 的代码链(Interweave)甚至优于更大的指令调整模型 gpt-4,该模型被指示编写代码来解决推理问题(如果这样做有帮助的话)。

机器人应用
代码链非常适合解决机器人任务,因为它们需要语义和算法推理。它们还涉及通过代码(例如,控制或感知API)与其他API 进行交互以及通过自然语言与用户进行交互。红色突出显示表示 LM 生成的代码正在由解释器执行。紫色突出显示表示 LMulator 正在模拟代码。



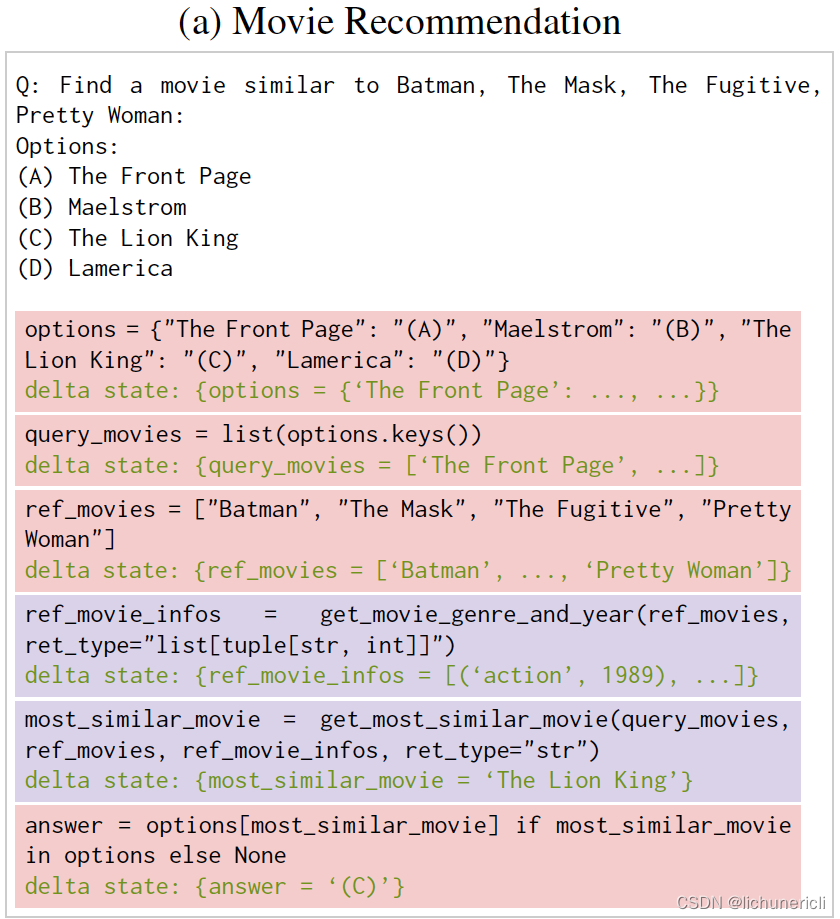
语言推理的模型输出示例
一些最具挑战性的 BBH 任务的示例模型输出,这些任务需要语义和算法推理。红色突出显示表示 LM 生成的代码正在由解释器执行。紫色突出显示表示 LMulator 通过绿色程序状态模拟代码。



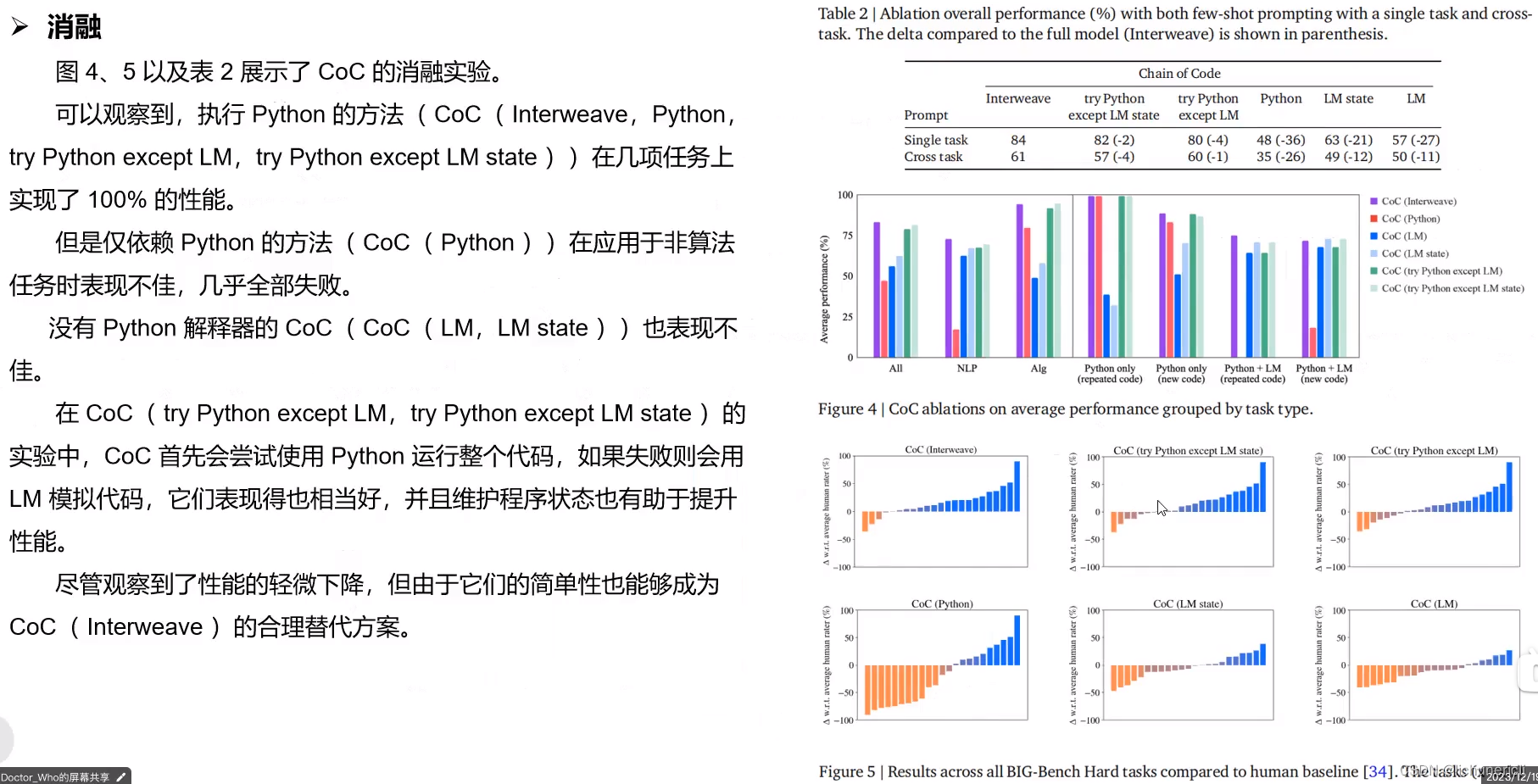
Ablation Studies消融研究
通过仔细的消融研究,我们确认代码链的所有设计选择对于其良好的性能至关重要。

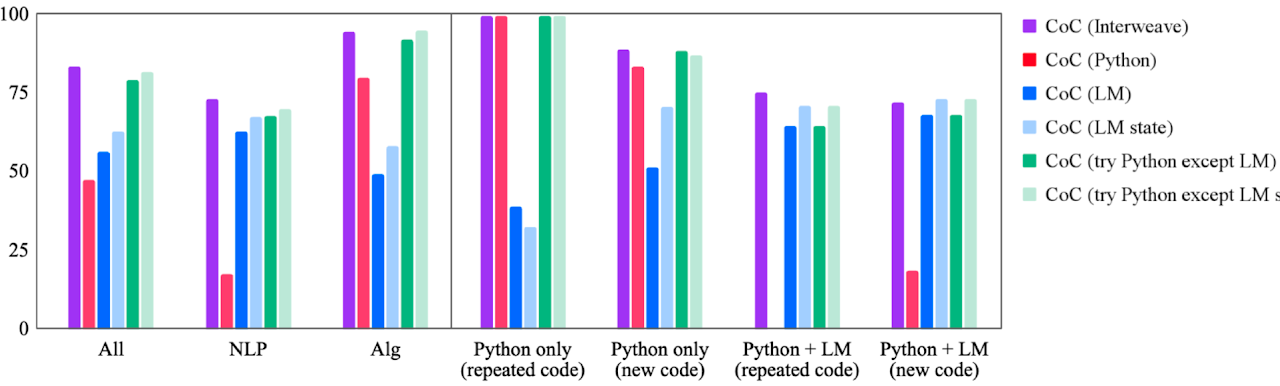
Scaling缩放
与仅针对大型模型出现的思想链不同,代码链对于大型和小型模型都可以很好地扩展。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据分析师面试必备,数据分析面试题集锦(七)
- 设计模式-结构型模式
- 【MySQL】SQL优化五个极简法则
- halcon答题卡识别
- 人工智能SCI二区期刊Applied Intelligence高被引录用论文合集,含2024最新
- Leetcode算法系列| 11. 盛最多水的容器
- 低代码是美味膳食还是垃圾食品?
- 前端构建工具对比 webpack、vite、esbuild等
- 计算机网络在中国的发展
- 2023年全国职业院校技能大赛软件测试赛题—单元测试卷⑥