【大数据分析与挖掘技术】Mahout聚类算法
目录
????????中国有句古语叫“物以类聚,人以群分”,也就是说,人们倾向于与志趣相投的人生活在一起。在实际生活中,人类的很多行为模式都是将相似的物品联系在一起,如味觉,当人尝到蜂蜜和白糖时,会不自觉将其归为一类;但尝到蜂蜜和辣椒时,则会将其归为不同的类。在不断品尝食物的过程中,人们会根据食物的味道将它们分为酸甜苦辣等等不同的味道;更复杂的,根据食材、烹饪方式、调味料等数据,将菜肴分为不同菜系等。实际上,这就是一个聚类过程,本章将介绍聚类的基本概念,以及在Mahout中如何使用聚类算法对数据进行分析。
一、聚类的基本概念
????????数据聚类,也称为聚类分析、分割分析或无监督分类,是一种创建数据对象集合的方法,这种数据集合也称为簇。聚类的目标是力求达到同一个簇中对象的相似程度尽可能的高,在不同簇中对象相似性差异尽可能大。聚类分析与数据分类是两个不同的方法,在数据分类中,数据对象被分配到预定义的类中,但在聚类的过程中,类本身是没有预先创建的,也不知道有多少个类,类的概念是在聚类过程中逐渐形成,并加以度量的,在聚类结束前每个数据点都不一定被稳定分配到某个类中。用术语来解释,聚类分析的过程是属于无监督的学习方法,而分类过程属于监督学习的方法。
????????数据挖掘的目的是要从大量数据中发现有用信息,因为数据量大,这些数据看起来可能是毫无关联的,但是在聚类分析的帮助下,就可以发现数据对象之间的隐藏联系。同时,聚类分析也是模式识别过程中的一个基本问题。聚类算法一般分为四个设计阶段:数据表示、建模、数据聚类和有效性评估。数据表示阶段已经预先确定了数据中可以发现什么样的簇,在此阶段需要对数据进行规范化,除去噪声点与冗余数据;在建模阶段,产生对数据相似性与相异性度量方法,数据聚类的主要目标就是将相似的数据成员聚成一簇,将相异性较大的成员分配到不同的簇中,一般而言,聚类过程需要迭代多次才能得到收敛结果并将各个数据对象划分到各个簇中去;在最后的有效性评估中,是将聚类结果进行量化度量。因为聚类是无监督的过程,必须要指定一些有效性标准,并且在某些聚类算法中,初始聚类数目没有给出,也需要用到有效性指标来找出合适的聚类数。
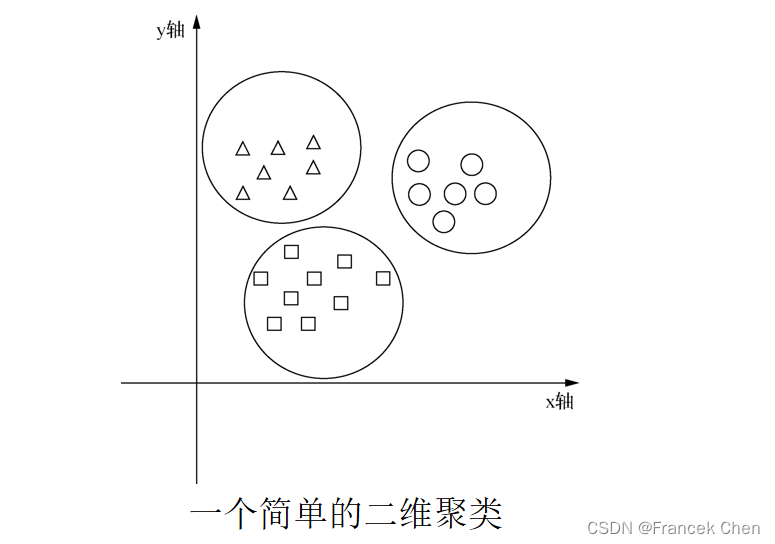
? ? ? ? 如图所示为一个简单的二维平面上的聚类示例,在这个例子中,将XY平面上的点根据距离远近划分为了三个簇,簇的中心点的坐标就是簇中所有样本的坐标的平均值,半径就是簇中最远点距离中心点的距离。这是一个二维平面上的聚类问题,可以用圆的中心点和半径解释,在实际应用中,数据维度往往会很大,可以将其看成一个多维的超球体,那么问题就抽象成了多维数据的距离度量问题了,常见的度量方式有欧氏距离、曼哈顿距离、余弦距离、皮尔森相似度和Jaccard相似度等。
二、常见的Mahout数据结构
????????在Mahout中,许多数据结构是通用的,如向量(Vector)在聚类算法和分类算法中都会用到。本节将对两个常见的数据结构进行介绍,一个是向量(Vector),用于结构化表示数据;另一个是文本文档,这是一个比较常见的数据类型,相对于数值型数据来说,文本文档类型的数据需要进行一些预处理来规范化表示,这就涉及文本文档的向量化算法,后文也将对此进行介绍。
(一)向量(Vector)
????????向量是一个很适合用于表示多维数据的方法,对于聚类的对象而言,将其抽象为向量可以大大简化数据存储和运算的消耗,例如,对苹果进行聚类,每个苹果有三个特征(形状、大小和颜色),可以将苹果对象进行向量化,形成一个三维的向量。Mahout针对不同场景给出了三个适用的向量实现,分别是DenseVector、RandomAccessSparseVector和SequentialAccessSparseVector。
1、DenseVector从字面上理解是密集向量,在使用时我们可以将它视为一个double型数组,在创建向量时,所有的元素就已经被赋值了,无论其是否为0,所以称之为密集向量(DenseVector)。
2、RandomAccesSparseVector,随机访问稀疏向量,为能够随机访问,构造了一组double型和整形的散列函数。与密集向量不同的是,当元素为0时,创建向量并不会为其分配空间,因此被称为稀疏向量。
3、SequentialAccessSparseVector,顺序访问稀疏向量,从字面上看和上面的随机访问稀疏向量
很相似,只不过它针对顺序访问做出了优化,更加适合处理需要顺序访问的数据。
? ? ? ? 显然,在处理不同的数据时,应选择最合适的向量表示。例如,Kmeans聚类算法就更加适合顺序访问稀疏向量,因为它需要重复多次顺序遍历数据集;相反,如果需要对向量做快速大量的随机访问,SequentialAccessSparseVector就远不如其他二者的效率了。
(二)文本文档
????????文本文档是一个特殊的数据类别,它的向量化与一般的数据不同,最常用的文本文档向量化方法是向量空间模型(Vector Space Model, VSM)。
????????假设一篇文章中出现了N个词,那么令向佩维度为N,其中每一维的大小取决于所对应单词在文章中出现的次数或者权重,也就是说,如单词‘我’对应文档向量的第110维,那么'我’出现的次数,就将存储于第110个维度,我们将这种存储方式定义为词频(Term Frequency,TF)权,单词出现的次数越多,该维度数值就越大,在计算向量距离的时候所占权重也就越大。
????????但是,TF权重方式有一个很严重的缺陷,在一篇文章中,最常出现的词往往不是最重要的,而是一些连接词、代称词等,就一篇文章的主题来说,这些词是没有意义的,反映文章主题的词往往不会出现得太频繁,但也不会只出现一两次,因此,在基于词频权重的方式上,应该引入一个其共他的变量来控制权重。词频-逆文档频率(Term Frequency-Inverse Document Frequancy,TF-IDF)是一个广泛应用的改进词频加权方式,它在原有的TF权重上加入了词的文档频率参数,当一个单词在所有文档中使用的越频繁,那么它在权重上被抵消的越多。TF-IDF计算方式如下:设单词wi在一个文档中的词频为fi,文档频率为DF,那么它的逆文档频率为IDF=1/DF,通常还会乘以一个归一化常数N,使得IDF=N/DF,这个N值等于文档个数。那么,我们定义单词wi的权重Wi=fi×IDF。从这个公式可以看出,当一个单词在文档集合中出现的越频繁,那么,IDF值越小,权重相应也会变小,而对于单个文档而言,单词出现的越频繁,fi会增大,权重相应会变大。在实际应用中,人们发现IDF值会掩盖五i对权重W的影响,所以常常将IDF 取对数,那么公式变为Wi=fixlog(N/DF),这就是经典TF-IDF权重。对于那些连接词或者是代称词来说,其权重很小,而反映文章主题的词的fi较大,IDF也比较大,因此会得到一个较大的权重,从而让这些词的权重反映了它的重要性。
????????在Mahout 中,关于文本文档向量化的工具主要有两个,一个是SequenceFilesFromDirectory类,该类可以将目录结构下的文本文档转换成SequenceFile格式;另一个是SparseVectorsFromSequenceFile类,该类基于n-gram(词组)的TF或者TF-IDF加权将SequenceFile格式的文本文档转换为向量。
三、聚类算法种类
????????聚类的概念已经被提出了很多年,按照传统的划分方式,聚类算法大致可以分为以下几种:划分聚类、层次聚类、基于模型的聚类算法、基于密度的聚类算法和基于网格的聚类算法等,而且聚类算法还在不断的发展更新中。比较典型的具体算法有K-means算法及其变种等等,这些算法从被提出到现在仍被广泛使用,许多新的算法都是基于这几种经典算法改进过来。Mahout中也实现了这些算法,本节将对这几种比较常用的算法及其在Mahout中的实现进行简单介绍。
(一)K-means?
????????K-means算法是最广泛使用的一种基于划分的聚类算法,它的主要思想是将对象划分为固定数目的簇,力求同簇元素尽可能相似,异簇元素尽可能相异,因此K-means算法较之于混合正态分布的最大期望算法十分相似,二者均尝试找到自然聚簇的中心。K-means算法的主要思想非常简单,首先选择k个对象最为初始聚类中心,大部分情况下这一步骤是随机的(或者通过一定的算法得到初始聚类中心,如最大最小距离算法等),然后对所有的数据对象进行分配,分配到最近的聚类中心上,分配完毕后再重新计算各个簇的中心,然后再进行分配,一般循环到各个簇成员不再发生变动或者准则函数收敛为止。这个算法是期望最大化(Expectation Maximization,EM)算法的一个经典例子,其算法描述如下:
输人:k,data[n];
(1)选择k个初始中心点,例如, c[0]=data[0],… c[k-1]=data [k-1];
(2)对于data[0]… .data[n],分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3)对于所有标记为i点,重新计算c[i]={所有标记为i的data[j]之和}/标记为i的个数;
(4)重复(2)(3),直到所有c[i]值的变化小于给定阈值。
????????K-means算法中步及到两个先决条件,一个是聚类个数k的选择,另一个是初始聚类中心的选择。发认情况下Mahout中的K-means实现使用RandomSeedGenerator类生成包含k个向量的SeguenceFile。随机中心的生成速度非常快,但是缺点也十分明显,它无法保证为k个簇估计一个比校好的中心,随机性较大,如果选择了不好的初始聚类数目和中心点,就会极大地影响K-means 的聚类收敛速度,甚至影响聚类效果。
????????在Mahout中,实现K-means算法过程的类主要是KMeansDriver,可以通过调用KMeansDriver.run()方法对数据进行聚类,具体的使用方法将在后面的实例中给出。
(二)模糊K-means?
????????模糊K-means算法是K-means聚类模糊形式。与K-means算法排他性聚类不同,模糊K-means试从数据集中生成有重叠的簇。在研究领域,也被称作模糊C-means算法(FCM算法),可以把模糊K-means看作是K-means算法的扩展。
????????K-means致力于寻找硬簇(一个数据集点只属于某一个簇),而在一个模糊聚类算法中,任何点都属于不止一个簇,而且该点到这些簇之间都有一定大小的隶属度,这种隶属度与该点到这个簇中心距离成比例。
????????模糊K-means有一个参数m, 叫做模糊因子,与K-means不同的是,模糊因子的引入不是把向量分配到最近的中心,而是计算每个点到每个簇的关联度。
(三)Canopy聚类算法
????????在实际应用中,很多时候并不知道聚类的最佳数目应该是多少,这往往需要靠人的经验判断,具有明显的不确定性。为了降低或者消除这种不确定性,可以采用一种被称为近似聚类算法的技术。这种聚类算法一般速度很快,但是聚类的精确性不高,结果并没有多少分析价值,但是可以提供一个簇数量的大概估计以及近似的中心点位置估计。
????????Canopy聚类算法是一种近似聚类算法,其时间复杂度很低,只需要进行一次遍历就可以得到结果,所以它有聚类结果不精确的缺点。我们可以利用Canopy聚类的结果确定聚类数目以及初始聚类中心,为K-means算法铺平道路。
????????Canopy算法使用了快速近似距离度量和两个距离阈值T1和T2来处理,T1>T2。基本的算法是,从一个点集合开始并且随机删除一个,创建一个包含这个点的Canopy,并在剩余的点集合上迭代。对于每个点,如果它的距离第一个点的距离小于T1,然后这个点就加入这个聚集中。除此之外,如果这个距离<T2,则将这个点从这个集合中删除。一直循环到初始集合为空,显然,这不是一个硬聚类,每个点可能不仅存在于一个Canopy中。Canopy聚类不要求指定簇中心的个数,中心个数的确定仅仅依赖于距离测度T1和T2的选择。使用生成的canopy,可以将点赋给最近的Canopy中心,理论上就是对这个点进行聚类,称之为Canopy聚类。与K-means类似,Mahout中对Canopy聚类的实现由类CanopyDriver完成,可以通过调用CanopyDriver.run()方法进行聚类,得到初步的聚类中心和个数。
(四)基于模型的聚类算法
????????K-means算法存在的一个局限性就是无法处理非对称正态分布数据,例如,当数据点呈现椭圆形、三角形分布时,K-means算法往往会出现聚簇过大或者过小的情况,无法将真实的数据分布进行呈现。同时,聚类数目的确定也是K-means 的短板,即便是采用canopy算法进行生成,也需要在后续步:中进行距离调优才能对k值进行估计。这类问题在许多基于模型的聚类算法中是可以解决的,其中典型的一种是狄利克雷聚类(Dirichlet Clustering)。狄利克雷在数学上指代一种概率分布,狄利克雷聚类就是利用这种分布搭建的一种聚类方法,其原理十分简单。假设数据点集中在一个类似圆形的区域内呈现均匀分布,我们有一个模型用于描述该分布,从而就可以通过读取数据并计算与模型的吻合程度来判断数据是否符合这种模型。
????????在Mahout中,单机狄利克雷聚类使DirichletClusterer类实现,其实现方式和KMeansDriver.run()方法不一样,下面使用一个简单的例子来说明如何通过使用DirichletClusterer类来进行聚类,代码如下所示:
List<VectorWritable>sampleData = new ArrayList<VectorWritable>();
generateSamples (sampleData,400,1,1,3);?
generateSamples (sampleData,300,1,0,0.5);
generatesamples (sampleData,300,0,2,0.1);?
DirichletClusterer dc = new DirichletClusterer(sampleData,new GaussianclusterDistribution(new VectorWritable(new DenseVector(2))),1.0,10,2,2);
List<Cluster []>result = dc.cluster();????????上述代码中,调用了三次generateS amples方法用于生成一些样本点,在狄利克雷聚类对象的构造方法DirichletClusterer()中使用了以下几个参数:第一个参数是以List<VectorWritable>表示的vector数据;第二个参数是传入一个数据拟合模型,使用了正态高斯分布(Gaussian Cluster Distribution)进行拟合;第三个参数值alpha=1.0,是一个平滑因子,值越大,模型的收敛速度就越慢,但是如果值太小会导致模型收敛过快而欠拟合;第四个参数指明初始模型数目是10个;最后两个参数用来降低聚类中内存使用率,在这里不进行深入探究。
????????创建好DirichletClusterer对象后,就可以调用cluster()方法进行聚类,返回值将会是一个List<Cluster[]>类型的结果集。
四、聚类应用实例
????????前面介绍了一些常用的聚类算法,接下来我们分别使用K-means算法和模糊K-means算法对一个实际生活中的数据集进行聚类分析。
(一)使用K-means聚类算法对新闻进行聚类
????????Reuters-21578是一个关于新闻的数据集,在机器学习领域中是最常用的文本分类的数据集之一,可以在http://www.daviddlewis.com/resources/testcollections/reuters21578/中找到。该数据集存放在22 个文件之中,包含22578篇文档,文件格式为SGML格式,类似于XML。可以为SGML创建一个解析器,将文档ID和文档文本写入SequenceFile中后,再使用SpareseVectorsFromSequenceFiles将它们转换为向量。
1、向量化数据
????????Mahout安装文件中包含了处理这个数据集的一个解析器,存放在Mahout安装目录下D的example/directory中,只需要运行这个目录中的org.apache.lucene.benchmark.utils.ExtractReuters即可。详细步骤如下:
????????首先,将下载好的Reuters数据集解压到examples/下的reuters/目录中,在examples目录下执行如下代码。
mvn-e -qexec:java?
-Dexec.mainClass="org.apache.lucene.benchmark.utils.ExtractReuters"?
-Dexec.args="reuters/reuters-extracted/"????????上述代码将Reuters的文章转换为SequenceFile格式,然后,需要运行SpareseVectorsFromSequence Files类,借助Mahout的启动器脚本可以很简单的完成:
bin/Mahout seq2sparse -i reuters-segfiles/ -o reuters-vectors -ow????????其中,-ow参数用于表示是否覆盖输出文件夹,因为数据集过于庞大,一旦出现意外删除的情况,往往需要数小时才能重新完成输出。 seq2sparse命令从SequenceFile中读取Reuters的数据,并将基于词典的向量化程序所生成的向量写入输出目录中,该命令所用的默认选项如表所示。
| 选项 | 类型 | 标志 | 描述 | 默认值 |
|---|---|---|---|---|
| 覆盖 | Bool | -ow | 如果该标志被设置,则输出目录被覆盖;否则,当输出目录不存在时创建该目录,当当输出目录存在时,该作业失败并报错,默认为不设置。 | N/A |
| Lucene分析器名 | String | -a | 所用分析器类名 | org.apache.lucene.analysis. standard.StandardAnalyzer |
| 块大小 | int | -chunk | 以MB为单位的块大小。对于大的文档集合,向量化时无法将全部的词典装入内存,只只有将词典分为特定大小的块,用多个步骤来执行向量化过程。 | 100 |
| 权重 | String | -wt | 所用的加权机制:tf为基于词频的加权,tfidf为基于TF-IDF的加权 | tfidf |
| 最小支持度 | Int | -s | 在整个集合中可放入词典文件的最小频率,低于该频率的词被忽略 | 2 |
| 最小文档频率 | Int | -x | 可放入词典文件的词所在文档的最大个数,这种机制用于去掉高频词,所在文档比例大于该值的词都会被忽略 | 99 |
| n-gram大小 | Int | -ng | 文档集合中选出的n-gram的最大长度 | 1 |
| 最小对数似然比 | LLR,float | -ml | 这个标志仅当n-gram大于1时生效;当LLR小于1.0时n-gram通常无意义 | 1.0 |
| 归一化 | Float | -n | ?归一化值用于Lp空间,默认的策略时对权重不做归一化。 | 0 |
| reducer个数 | Int | -nr | 并行执行的reduce任务的个数。当基于目录的向量化程序运行在Hadoop集群上时,这个标志会生效。将它设置为集群的最大节点数时会获得最高性能。如果把这个值设置得比集群节点个数更大,会导致性能略微下降。 | 1 |
| 生成顺序访问的稀疏向量 | Bool | -seq | 如果这个标志被设置,那么,输出向量就会被创建为SequentialAccessSparseVector。在默认情况下,基于目录的向量化程序创建的是RandomAccessSparseVector。前者在某些算法(如K-means和SVD)上可获得更高性能,原因在于向量操作的连续访问特征。在默认情况下,这个标志不被设置。 | N/A |
2、聚类
????????为了取得新闻中的有效字符,首先需要对数据进行预处理,过滤掉新闻中的非字母字符,可以创建一个自定义分析器用于这项工作,代码如下:
public class MyAnalyzer extends Analyzer {
private final Pattern alphabets = Pattern.compile("[a-z]+");
@Override
public TokenStream tokenStream (String fieldName, Reader reader) {
//使用Lucene过滤器
TokenStream result = new StandardTokenizer(Version.LUCENE_URRENT, reader);
result = new StandardFilter(result);
result = new LowerCaseFilter(result);
result = new StopFilter (true, result, StandardAnalyzer.STOP_WORDS_SET);
TermAttribute termAtt = (TermAttribute) result.addAttribute(TermAttribute.class);
StringBuilder buf = new StringBuilder();
try {
while(result.incrementToken()){
//过滤短词条
if (termAtt.termLength()<3) continue;
String word = new String (termAtt.termBuffer(),0,termAtt.termLength());
Matcher m = alphabets.matcher(word);
//过滤非字母词条
if(m.matches()){
buf.append(word).append(" ");
}
}
} catch(IOException e){
e.printStackTrace();
}
return new WhiteSpaceTokenizer(new StringReader(buf.toString ()));
}
}????????上述代码创建了一个简单的分析器,它可以将非字母字符从数据中删除,接下来便可以开始使用Mahout提供的KMeansDriver进行聚类分析代码如下所示:
public class NewsKMeansClustering {
public static void main(String args[])throws Exceptionb{
int minSupport = 2;
int minDf = 5;
int maxDFPercent = 95;
int maxNGramSize = 2;
int minLLRValue = 50;
int reduceTasks = 1;
int chunkSize = 200;
int norm = 2;
boolean sequentialAccessOutput = true;
String inputDir = "inputDir";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String outputDir = "newsClusters";
HadoopUtil.delete(new Path (outputDir));
Path tokenizedPath = new Path(outputDir, DocumentProcessor.TOKENIZED_DocUMENT_OUTPUT_FOLDER);
//自定义lucene Analyzer
MyAnalyzer analyzer = new MyAnalyzer();
//文本词条化
DocumentProcessor.tokenizeDocunents(new Path(inputDir),analyzer.getClass().asSubclass(Analyzer.class),tokenizedPath,conf);
DictionaryVectorizer.createTermErequencyVectors(tokenizedPath,new Path(outputDir),conf,minSupport,maxNGramSize,minLLRValue,2,true,reduceTasks,chunkSize,sequentialAccessOutput,false);
//计算TF-IDF 向量
TFIDFConverter.processTfIdf(newPath(outputDir,DictionaryVectorizer.DocUMENT_VECTOR_OUTPUT_FOLDER),newPath(outputDir),conf,chunkSize, minDf,maxDFPercent,norm,true,sequentialAccessOutput,false,reduceTasks);
Path vectorsFolder = new Path(outputDir,"tfidf-vectors");
Path canopyCentroids = new Path(outputDir,"canopy-centroids");
Path clusterOutput = new Path(outputDir,"clusters");
//执行Canopy算法生成初始聚类中心
CanopyDriver.run(vectorsFolder,canopyCentroids,new EuclideanDistanceMeasure(),250,120,false,false);
//运行K-means算法
KMeansDriver.run(conf,vectorsFolder,new Path(canopyCentroids,"clusters-0"),clusterOutput,new TanimotoDistanceMeasure(),0.01,20,true,false);
SequenceFile.Reader reader = new SequenceFile.Reader(fs,new Path(clusterOutput + Cluster.CLUSTERED_POINTS_DIR +"/part-00000"),conf);
IntWritable key = new IntWritable();
WeightedVectorWritable value = new WeightedVectorWritable();
//读取vector做聚类映射
while(reader.next(key,value)){
System.out.println(key.toString()+"belongs to cluster"+value.toString());
}
reader.close ();
}
}????????这个NewsKMeasClustering类逻辑简单,首先从输入目录中读取文档,使用自定义分析器和向量化工具创建仅包含字母的一元和二元组向量,再使用生成的Vector作为聚类算法的输入,运行Canopy算法生成初始聚类中心供K-means驱动器使用。在聚类结束后,读取结果,并将其打印出来。
(二)使用模糊K-means聚类算法对新闻进行聚类
????????如果允许簇之间有部分重叠,那么,相关文章的功能显然会更丰富。重叠的分值有助于用户获得相关文章和簇的关联性,进而对它们进行排序。下面,对K-means算法的代码稍加修改,就可以很方便地实现模糊K-means算法,代码如下所示。
public class NewsFuzzyKMeansClustering {
public static void main(String args[]) throws Exception {
//省略与K-means算法相同部分代码
//定义文件路径
String vectorsFolder = outputDir+"/tfidf-vectors";
String canopyCentroids = outputDir+"/canopy-centroids";
String clusterOutput = outputDir+"/cluster/s";
//使用Canopy聚类预处理
CanopyDriver.run(conf,new Path(veatorsFolder),new Path(canopyCentroids),new ManhattanDistanceMeasure(),3000.0,2000.0,false,false);
//运行模糊K-means聚类
FuzzyKMmeansDriver.run(conf,new Path(vectorsFo1der),new Path(canopyCentroids,"clusters-0"),new Path (clusterOutput),new TanimotoDistanceMeasure(),0.01,20,2.0f,true,true,0.0,false);
SequenceFile.Reader reader = new SequenceFile.Reader(fs,new Path(clusterOutput+Cluster.CLUSTERED_POINT_DIR+"/part-m-00000"),conf);
IntWritable key = new IntWritable();
WeightedVectorWritable value = new WeightedVectorWritable();
//打印簇和概率
while(reader.next(key,value)){
System.out.println("Cluster:"+ key.toString()+" "+value.getVector().asFormatString());
}
reader.close();
}
}????????通过模糊K-means算法可以知道一个点在多大程度上与一个簇相关,有了这个信息就能找到最相关的簇,并且根据相关程度确定相关文章的带权分值。相对于传统的K-means算法,这种方式可以避免过于严格的限制,为处于簇边缘的文档识别出更好的相关文章。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言中的printf函数详解
- Distilling the Knowledge in a Neural Network 中文版 (含: bibtex格式的引用)
- 如何在linux下制作静态库和动态库
- 第二百一十四回
- 【实例讲解】通过镜像还原后SSH、JupyterLab无法连接?
- RHCE9学习指南 第21章 用bash写脚本
- HTML的简单介绍
- Maven类包冲突终极三大解决技巧 mvn dependency:tree
- 9. 总结
- 代码提交分支规范