基于Redis和mysql架构,如果保证数据一致性
一、背景介绍
如图所示,是redis+mysql整体架构设计

该设计会出现一个问题,如下图所示
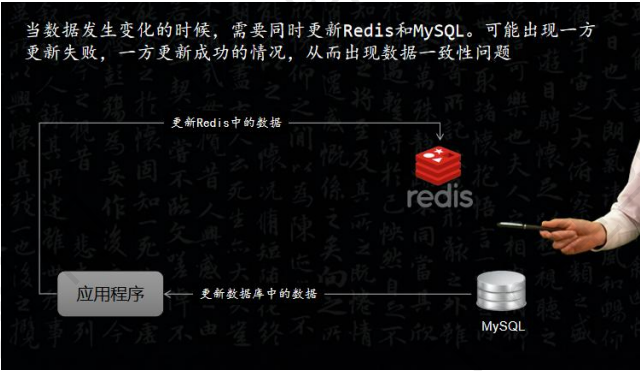
二、解决思路
如果出现数据不一致问题,一般会想到2种思路
1)更新数据库,再更新缓存(如果更新缓存失败,也会导致数据不一致)
2)删除缓存,更新数据库
考虑并发情况,线程A写,线程B读

三、解决方案
使用消息中间件来实现数据一致性(异步更新)或加版本号或时间戳方式

弱一致性方案:先更新数据库,再删除缓存。适用业务场景:社交平台点赞功能
最终一致性方案:先更新数据库,再删除缓存,配合使用消息队列异步重试机制达到数据一致性。使用场景:秒杀项目库存数量
方案一:
整体方案思路:先更新数据库,再删除缓存,配合使用消息队列异步重试机制达到数据一致性
具体思路:
1)先更新数据库,把需要删除的缓存数据放到消息队列中
2)消费端实现删除缓存的操作,如果成功,将该条数据从消息队列中移除,避免重复操作,如果失败,把重试请求写到消息队列中,由专门消费者重试,直到成功,如果达到重试次数还未成功,我们就需要向业务层发送报错信息了。
具体方式:
生产端:
// 更新MySQL
userMapper.update(user);
//发送消息
UserUpdateMQ message=UserUpdateMQ.builder()
.userId(userId);
.build();
log.info("生产端开始发送消息={}",message.toString());
mqMessageSender.syncSend(MessageConstants.USER_UPDATE_TOPIC,message);消费端:(更新redis)
public void handleMessage(UserUpdateMQ message) {
log.info("【消费端异步处理消息】, 请求报文:{}", JSON.toJSONString(message));
long start = System.currentTimeMillis();
try {
Long userId = message.getUserId()
log.info("productId={}",userId);
User user = userMapper.selectById(userId);
redisTemplate.opsForValue().set("user_" + user.getId(), user);
} catch (Exception e) {
log.error("处理【更新redis任务】出现异常, 原因:{}", e.getMessage(), e);
} finally {
long end = System.currentTimeMillis();
log.info("完成【更新redis任务】, 耗时(ms):{}", end - start);
}
}缺点:消息队列可能因为各种原因丢失消息
方案二:使用版本号或时间戳
每次更新数据时,除了更新MySQL和Redis的记录外,还要更新对应的版本号或时间戳。
例如,我们可以在用户表中添加一个版本号字段"version":
// 更新MySQL
userMapper.update(user);
// 更新Redis
redisTemplate.opsForValue().set("user_" + user.getId(), user);
// 更新版本号
redisTemplate.opsForValue().increment("version_user_" + user.getId());在读取数据时,先比较MySQL和Redis中的版本号或时间戳。如果不一致,则重新从MySQL中读取数据,并更新到Redis中。
这种方式可以提高数据一致性的可靠性,但也会增加一定的复杂性和开销。
四、总结
我们在面试的时候,面试官还可能会问各种没有场景化的纯粹的技术问题,比如说: “你这个最终一致性方案”还是会存在数据不一致的问题啊?那怎么解决?
先不用慌,技术是为业务服务的,所以不同的业务场景,对于技术的选择和方案的 设计都是不同的,所以这个时候,可以反问面试官,具体的业务场景是什么?
大家一定要记住,某个技术方案不可能适用于所有的业务场景,只有最合适的方案, 没有最优的方案。
五、深度分析
5.1 如何数据保持一致性?
需要做两件事,1: 更新数据库,2:更新缓存
5.2 思考
1)先操作数据库还是缓存?
2)缓存是更新还是删除?
3)可能产生的问题:
1:操作执行失败,两件事如果有一件执行失败是怎么样?
2:高并发:是否会出现数据不一致的情况?
5.3 先操作数据库
考虑并发操作:线程A写,线程B读
先更新数据,再删除缓存(后面加粗字体回答此处为啥是删缓存,而不是更新缓存)

一个是读操作,一个是写操作的并发,先更新了数据库中的数据,此时缓存依然有效,所以此时读操作查到的是没有更新的旧数据,但是更新操作马上让缓存失效了,后续的查询操作再把数据从数据库中查出来。
考虑并发操作:线程A写,线程B写,线程C读

该情况下由于线程A、B最初都把数据写入了数据库,接着都有delete cache,此时如果有线程C来读数据,你会发现不管线程C的动作做任意顺序穿插在A、B动作之间,最后查询数据最差也就是在线程A、B删除cache之前获取到了旧数据,其余都会获取到新数据,并不会影响后来的请求获取到新数据。
为什么最后是把缓存的数据删掉,而不是把更新的数据写到缓存里。这么做引发的问题是,如果A、B两个线程同时做数据更新,A先更新了数据库,B后更新数据库,则此时数据库里存的是B的数据。而更新缓存的时候,是B先更新了缓存,而A后更新了缓存,则缓存里是A的数据。这样缓存和数据库的数据会发生不一致。
小结:
- 先操作数据库再删除缓存能有让人可接受的结果,所以最推荐这种做法。
- 先操作缓存再更新数据库可能造成数据不一致的场景,不推荐这种做法。
5.4 先操作缓存
1)先更新缓存,再更新数据库(如果缓存执行成功,更新数据库失败,就会出现数据不一致情况)
2)先删除缓存,再更新数据库(高并发,假设操作都成功,线程A写,线程B读)

考虑并发操作:线程A写,线程B写

小结
可看到先操作缓存不论是先删除缓存还是先更新缓存都会发生数据不一致的情况,所以不推荐这两种做法。
5.5 异常情况
如果两步操作有其中一步操作失败了呢?(以先操作数据库再操作缓存举例)
- 第一步失败:这种情况很简单,不会影响第二步操作,也不会影响数据一致性,直接抛异常出去就好了。
- 第二步失败:
5.6 为什么要删除缓存而不是更新缓存?
- 避免数据不一致: 更新缓存可能引发数据不一致,特别是在并发更新数据库和缓存的情况下。因为有过期时间的设置,删除缓存可以确保缓存中不会存在旧的或错误的数据。
- 简化逻辑: 删除缓存可以简化缓存更新的逻辑。更新缓存可能需要检查和比较旧数据和新数据,需要更多的逻辑来处理不同的数据版本。而删除缓存则可以避免这些复杂的比较操作。
- 节省内存:对于大多数的非热点数据,缓存中的数据更新后,不一定会马上被读取。如果没有读取,就浪费了缓存资源。不如等下一次读的时候, 更新缓存。
5.7 对于热点数据或秒杀项目的库存数据,如何操作缓存呢?
整体方案思路:先更新数据库,再删除缓存,配合使用消息队列异步重试机制达到数据一致性
具体思路:
1)先更新数据库,把需要删除的缓存数据放到消息队列中
2)消费端实现删除缓存的操作,如果成功,将该条数据从消息队列中移除,避免重复操作,如果失败,把重试请求写到消息队列中,由专门消费者重试,直到成功,如果达到重试次数还未成功,我们就需要向业务层发送报错信息了。
使用重试机制,
方案:先更新数据库,再删除缓存,引入消息队列,将哪些需要从缓存中删除的数据先放到消息队列中,由消费者来操作数据。
使用异步重试,把重试请求写到消息队列中,由专门的消费者重试,直到成功。
如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
消息队列的特性:
- 消息队列保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)
- 消息队列保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的需求)
至于写队列失败和消息队列的维护成本问题:
- 写队列失败:操作缓存和写消息队列,「同时失败」的概率其实是很小的
- 维护成本:我们项目中一般都会用到消息队列,维护成本并没有新增很多
举个例子,来说明重试机制的过程。

5.8 总结
1)性能和一致性不能同时满足,为了性能考虑,通常会采用「最终一致性」的方案
2)掌握缓存和数据库一致性问题,核心问题有 3 点:缓存利用率、并发、缓存 + 数据库一起成功问题
3)失败场景下要保证一致性,常见手段就是「重试」,同步重试会影响吞吐量,所以通常会采用异步重试的方案
4)订阅变更日志的思想,本质是把权威数据源(例如 MySQL)当做 leader 副本,让其它异质系统(例如 Redis / Elasticsearch)成为它的 follower 副本,通过同步变更日志的方式,保证 leader 和 follower 之间保持一致
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- VMware workstation配置Ubuntu20.04.6虚拟机NAT网络上内外网
- 数据结构-B树删除示例
- 开发板SD卡插入读卡器,插入电脑后无法识别的解决方法(亲自尝试过了)
- 基于Flume+Kafka+Hbase+Flink+FineBI的实时综合案例(一)案例需求
- TwinCAT3 Modbus-TCP Client/Server使用
- 【VTKExamples::PolyData】第十二期 ExtractSelectedIds & ExtractSelection
- 6K star! 100%本地运行LLM的AI助手
- Python实现音乐推荐系统
- 校内点餐系统(JSP+java+springmvc+mysql+MyBatis)
- SpringBoot-Mybatis-分页