架构10- 理解架构的模式4-数据管理模式
一、分片模式:将数据存储区分为多个水平分区或分片,以便更好地管理和处理大量数据。
当业务量达到单个业务表通过缓存和队列削峰等措施后的平均TPS超过1万时,我们不得不考虑数据库分片。
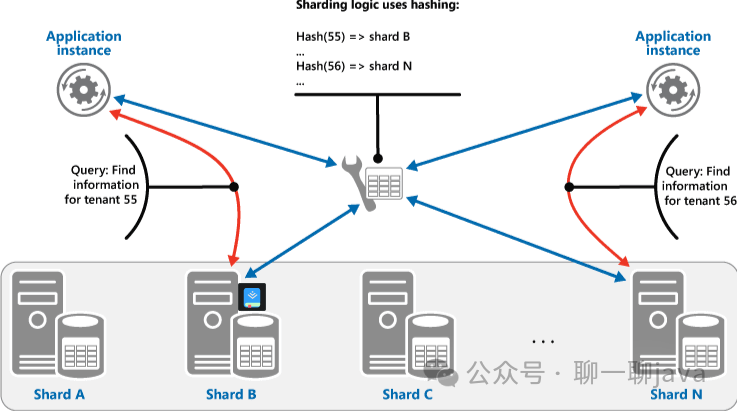
在进行分片之前,我们需要根据数据分布、压力情况和业务逻辑来确定分片的方式,可以是按条件、范围或哈希等策略(三张图展示了三种策略)。此外,还需要对业务代码进行改造,以消除所有不支持的SQL语句。还要确定采用硬编码方式、框架方式或中间件方式进行数据路由。
? ? 在进行分片后,我们需要运维工具来对这些分片数据进行统一的索引加工等操作。最好有一个数据仓库,可以汇总所有数据,方便进行adhoc查询。同时,最好有辅助工具可以帮助我们确定数据会分布在哪个分片中。
二、静态内容托管模式:将静态内容放置在云存储服务中,并直接向客户端传送这些内容,以提高访问效率。
CDN的使用通常有两种方式:主动推送数据到CDN存储和在CDN配置回源站拉取。对于文件类资源,一般使用主动推送数据;而对于静态资源类,一般使用回源方式。
在使用CDN时,需要考虑以下问题:
1. CDN如何认定同一个文件:CDN通常使用文件的URL地址作为唯一标识来认定同一个文件。
2. 缓存刷新工具:CDN提供了缓存刷新工具,可以手动触发刷新边缘节点的缓存,以保证最新的内容能够及时被边缘节点获取。
3. 源站文件一致性:为避免问题,源站需要保持相同文件的一致性,最好是通过版本变化来改变文件名,而不是不断替换同一个文件。这样可以避免边缘节点缓存了不同版本的文件,导致各种奇怪的问题。
4. 排查问题困难性:由于使用CDN后,不同地区的用户访问的是CDN节点上的数据,一旦出现问题,排查和定位可能会比较困难。因此,建议引入前端的错误处理框架,记录前端脚本错误时的调用栈,以便更方便地定位问题。
换句话说:CDN通过URL地址来认定同一个文件,同时提供了缓存刷新工具来刷新边缘节点的缓存。为确保一致性,源站需要保持相同文件的一致性,并尽量避免直接替换同一个文件。当使用CDN后,由于用户访问的是CDN节点上的数据,问题排查可能会比较困难,因此建议引入前端错误处理框架来记录脚本错误以便快速定位问题。
三、索引表模式:为经常被查询的数据存储区中的字段创建索引,以加快数据检索速度。
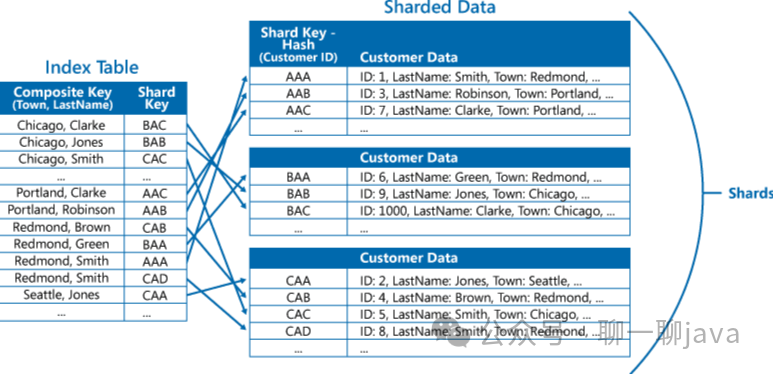
考虑到以下原因,我们会考虑使用索引表:尽管我们的关系型数据库通常支持非聚集索引(除了主键之外的索引),但在某些情况下,直接在大表上创建多个索引可能不利于性能。当我们对数据进行分片后,只能通过分片键来查询数据,无法使用其他维度进行查询。为了以空间换时间,我们可以单独保存某个维度的复合查询结果作为主键方式的索引数据。然而,需要注意的是,索引只有在数据区分度较高的情况下才能发挥其价值。如果有超过90%的数据具有相同的值,那么使用索引进行查询的性能可能会略低于全表扫描。
换句话说:出于性能考虑,我们会考虑使用索引表。尽管关系型数据库支持非聚集索引,但在某些情况下,对大表创建多个索引可能影响性能。在进行数据分片后,我们不能使用分片键以外的维度进行查询。为了加快查询速度,我们可以将某个维度的复合查询结果作为主键单独保存一份数据。然而,需要注意的是,只有当数据的区分度较高时,索引才能发挥作用。如果有超过90%的数据具有相同的值,那么使用索引进行查询的性能可能稍差于全表扫描。
关注公众号:领取架构师面试资料

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 剑指offer——二维数组中的查找
- Paper Survey——NeRF SLAM
- PyTorch 中的距离函数深度解析:掌握向量间的距离和相似度计算
- 面向对象进阶
- 【Python_PySide2学习笔记(二十三)】基于qdarkstyle实现PyQt界面美化
- springboot实现发送邮件开箱即用
- 买显卡别再只看N、A两家了,这些高性价比I卡也很香
- python安装及pycharm环境搭建汉化(保姆级教程)
- 如何计算JMeter性能和稳定性测试中的TPS?
- Shell 正则表达式及综合案例及文本处理工具