sklearn实现岭回归(Ridge Regression)

💥 项目专栏:sklearn实现经典机器学习算法(附代码+原理介绍)
文章目录
前言
🌟 哈喽,亲爱的小伙伴们,你们知道吗?最近我们的粉丝群里有好多小可爱私信问我一些关于决策树、逻辑回归等机器学习的超级有趣的问题呢!🌈 为了让大家更轻松地理解,我决定开一个超可爱的专栏,叫做 用sklearn玩转机器学习,特别适合机器学习的小新手哦!
🍬 在这个专栏里,我们会用sklearn这个超级强大的魔法工具来实现各种闪闪发光的机器学习算法!不用担心难度哦,我会用最简单、最可爱的方式,带领大家一起探索算法的神秘世界!?
🎈 适合哪些小伙伴加入呢?当然是对机器学习感兴趣的小新手们,还有那些刚开始接触sklearn的可爱宝宝们!我们会一起学习如何用sklearn轻松实现那些看起来好厉害的机器学习算法,让新手小白也能快快乐乐地理解它们哦!
🌸 在这个专栏里,大家可以看到用sklearn实现的机器学习算法,我们不仅仅是理论学习哦,每一篇文章都会附带 完整的代码+超级可爱的原理讲解,让大家在轻松愉快的氛围中一起学习成长呢!🌼 快来加入我们的学习大冒险吧!
🚨 我的项目环境:
- 平台:Windows11
- 语言环境:Python 3.10
- 编译器:Jupyter Lab、PyCharm
- scikit-learn:1.2.1
- Pandas:1.3.5
- Numpy:1.19.3
- Scipy:1.7.3
- Matplotlib:3.1.3
💥 项目专栏:sklearn实现经典机器学习算法(附代码+原理介绍)
一、岭回归算法背景
🌟 岭回归(Ridge Regression)入门 🌟
这篇文章将引领我们深入了解岭回归——一个在统计学和机器学习领域中广泛应用的回归分析方法。岭回归特别适用于处理多重共线性数据,即当输入特征高度相关时。通过引入正则化项,岭回归能有效减少过拟合问题,保持模型的稳健性。
📖 起源与背景
- 发展历史:岭回归由统计学家Hoerl和Kennard于1970年代提出,用于解决线性回归中的多重共线性问题。
- 理论基础:岭回归在传统最小二乘法的基础上,增加了L2正则化项,从而改善模型的稳定性和预测能力。
🌐 应用领域
- 经济学:用于宏观经济指标预测和市场趋势分析。
- 工程学:用于系统建模和信号处理。
- 生物信息学:用于基因数据分析和生物标记物的识别。
- 心理学:用于行为数据分析和心理测验评分模型。
? 特点
- 降低过拟合风险:通过L2正则化减少模型复杂度,提高泛化能力。
- 处理多重共线性:在特征高度相关时依然保持良好的预测准确性。
- 灵活性高:正则化程度可通过调整参数灵活控制。
尽管在处理非线性复杂数据时可能存在局限,但岭回归凭借其稳定性和灵活性,在实际应用中仍是一种重要且实用的分析工具。
💡 本篇亮点
在本篇文章中,我们将使用sklearn库实现 Ridge Regression。这篇文章不仅是本专栏的一部分,还是一个详尽的操作指南,旨在帮助初学者快速掌握机器学习算法训练的基础框架,并深入了解其实现细节。
二、算法原理
🌟 岭回归:处理多重共线性的有效方法 🌟
岭回归,也称为Tikhonov正则化,是一种处理线性回归问题的技术,特别适用于解决自变量之间存在多重共线性的情况。当数据集中的自变量高度相关时,传统的最小二乘法估计可能不稳定,岭回归通过引入正则化项来克服这一问题。
🧩 基本原理
-
核心:岭回归的核心在于对估计的系数添加L2正则化项。这种正则化可以缩小系数的估计值,减少模型的复杂度,从而降低过拟合风险。
公式表达如下:
β ^ = arg ? min ? β { ∑ i = 1 n ( y i ? X i β ) 2 + λ ∑ j = 1 p β j 2 } \hat{\beta} = \arg\min_{\beta} \left\{ \sum_{i=1}^{n} (y_i - X_i \beta)^2 + \lambda \sum_{j=1}^{p} \beta_j^2 \right\} β^?=argβmin?{i=1∑n?(yi??Xi?β)2+λj=1∑p?βj2?}
其中, y i y_i yi?是因变量, X i X_i Xi?是自变量, β \beta β是系数, λ \lambda λ是正则化参数,控制着正则化的强度。
📊 参数估计
- 岭估计:通过最小化残差平方和加上L2正则化项来估计参数。
📈 模型评估
- 交叉验证:可以使用交叉验证来选择最佳的正则化参数 λ \lambda λ。
- 偏差-方差权衡:通过调整 λ \lambda λ,岭回归在偏差和方差之间进行权衡。
?? 优化
- 选择合适的 λ \lambda λ:正则化参数 λ \lambda λ的选择对模型性能至关重要。较大的 λ \lambda λ值会增加偏差,而较小的 λ \lambda λ值可能导致过拟合。
🧪 模型假设
- 线性关系:假设因变量与自变量之间存在线性关系。
- 无严格的统计假设:与普通最小二乘法相比,岭回归对数据的统计分布假设不严格,更加灵活。
🌐 应用价值
岭回归因其在处理具有多重共线性特征的数据集方面的有效性而受到青睐。在金融、生物统计学、工程等领域,岭回归提供了一种强有力的工具,用于建立更稳健的预测模型。
三、算法实现
3.1 导包
🎉 欢迎来到岭回归模型的快乐小工具箱! 在这个项目中,我们使用了一系列既实用又有趣的第三方库,它们就像我们的小帮手,使数据分析和模型构建变得既轻松又愉快!🛠? 让我们一起来看看它们都有哪些魔法功效吧!
-
numpy:想象一下,如果有一个能轻松操纵巨大数字矩阵和解决复杂数学问题的魔法工具!Numpy就是这样的一个神奇工具包,它让科学计算变得像搭建乐高积木一样简单有趣!🔢
-
matplotlib.pyplot:这个库就像我们的魔法画布,能让我们用代码就画出美丽的图形!就像用魔法笔一样,它可以将枯燥的数据变成五彩缤纷的图像,让人一看就着迷!🎨
-
seaborn:Seaborn是matplotlib的时髦小伙伴,它提供了更多华丽的图表样式。使用它绘图就像给数据穿上了漂亮的晚礼服,让每个图表都变得格外吸引人!🌟
-
sklearn.datasets.fetch_california_housing:在机器学习的世界里,数据就像是无价之宝。这个工具箱里藏着各种各样的数据集,比如迷人的加利福尼亚房价数据集,是我们探索和学习的宝贵资源!🏠
-
sklearn.model_selection.train_test_split:这个工具就像是将数据分成两支队伍的智能分配器,一个是训练队伍,一个是测试队伍。它帮助我们训练出能够精准预测的模型!👥
-
sklearn.linear_model.Ridge:这里有一个聪明的岭回归模型,它擅长在复杂的数据中找出隐藏的规律,帮助我们解决回归问题。就像是一个解决谜题的侦探!🕵??♂?
-
sklearn.metrics:要如何知道我们的模型表现得好不好呢?这个工具箱里的小助手们会告诉我们!它们能够精确评估模型的表现,就像是给我们的模型打分一样!📝
-
sklearn.model_selection.GridSearchCV:寻找最佳模型参数就像是寻宝游戏,这个工具就像是一张详尽的宝藏地图。它帮我们在众多参数中找到最佳的组合,确保我们的模型达到最佳表现!🗺?
-
sklearn.preprocessing.StandardScaler:这个小工具就像是给数据做整容手术,让数据变得整齐划一,更适合用于机器学习。就像是给数据做了一个美容SPA,让它们更加光鲜亮丽!💆?♀?💆?♂?
使用这些工具,我们可以在数据科学和机器学习的世界中畅游无阻,它们每一个都承担着独特的任务,帮助我们将数据转化为有用的洞见和知识!
import warnings
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
3.2 加载数据集
这段代码是关于加载回归数据集的,具体来说,它执行了以下几个操作:
-
导入数据集:首先,代码中使用了
fetch_california_housing函数。这个函数来自于sklearn.datasets,是 scikit-learn(一个非常流行的Python机器学习库)提供的一种方法,用于获取数据集。 -
加载加利福尼亚房价数据集:
fetch_california_housing()函数调用的结果是加载了一个著名的公共数据集——加利福尼亚房价数据集(California Housing dataset)。这个数据集通常用于回归分析的学习和实践。 -
数据集结构:加载后的数据集被分为两部分:
X和y。X代表数据集中的特征矩阵。在这个矩阵中,每一行代表一个数据点(在这个场景下是加利福尼亚州的一个区域),每一列代表一个特征(例如,人均收入、房屋年龄等)。y代表目标变量或响应变量,即我们试图通过模型预测的值。在加利福尼亚房价数据集中,y通常代表房屋的中位数价格。
这段代码的主要目的是准备数据,以便进行后续的数据分析和建模工作。
# 2. 加载回归数据集
housing = fetch_california_housing()
X, y = housing.data, housing.target
加利福尼亚房价数据集(California Housing dataset)是一个广泛用于回归分析的公开数据集,特别在机器学习和统计领域中应用广泛。这个数据集的特点和内容包括:
-
数据来源:这个数据集最初来源于1990年美国人口普查。
-
目的:主要用于回归分析任务,尤其是预测房价。
-
数据量:它包含了加利福尼亚州各区域(或街区群)的房屋信息,通常有约20640个样本点。
-
特征:数据集包含多个特征(或属性),通常有8个。这些特征包括:
- MedInc:街区居民的收入中位数。
- HouseAge:房屋年龄的中位数。
- AveRooms:平均房间数目。
- AveBedrms:平均卧室数目。
- Population:街区人口。
- AveOccup:平均房屋占用率。
- Latitude:街区的纬度。
- Longitude:街区的经度。
-
目标变量:数据集的目标变量是每个街区房屋的中位数价格。这是一个连续的数值,通常用于回归分析。
-
应用:这个数据集常被用于测试各种回归模型的性能,包括线性回归、岭回归、决策树和神经网络等。
-
挑战:由于其特征的多样性和实际应用背景,这个数据集为预测模型的建立提供了一定的挑战,如如何处理非线性关系、如何解释模型结果等。
总的来说,加利福尼亚房价数据集是理解和实践回归分析的一个经典案例,它提供了丰富的信息来预测房价,并帮助初学者和专业人士理解数据在真实世界中的应用。
3.3 数据预处理
在这段代码中,我们进行了数据预处理的一个关键步骤:特征标准化。标准化是一种使数据符合标准正态分布(即均值为0,方差为1)的技术。这通常是机器学习中的一个重要步骤,因为许多算法的性能在标准化数据上会更好。具体来说,我们使用了 StandardScaler 类从 sklearn.preprocessing 包中。
-
实例化 StandardScaler:首先,我们创建了
StandardScaler类的一个实例,命名为scaler。这个实例将用于后续的标准化过程。 -
拟合并转换数据:通过调用
scaler.fit_transform(X),我们对数据集X进行了拟合和转换。在这一步中,fit方法会计算数据集X的均值和标准差,然后transform方法会使用这些参数将每个特征转换为标准正态分布。换句话说,对于每个特征,算法都会减去其均值并除以其标准差。
这个过程有助于消除不同特征之间的尺度差异,使得模型对于所有特征的敏感度相同。特别是当特征的尺度相差很大时,标准化是非常重要的步骤。
# 3. 数据预处理
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
3.4 划分训练集、测试集
在这段代码中,我们使用了 train_test_split 函数,这是 sklearn.model_selection 模块中的一个功能,用于将数据集划分为训练集和测试集。这是机器学习项目中的一个关键步骤,目的是确保模型可以在未见过的数据上进行测试,从而评估其泛化能力。
具体来说,train_test_split 接受几个参数:X_scaled 和 y 分别是经过预处理(如标准化)的特征数据和对应的标签。参数 test_size=0.3 指定了测试集应占总数据集的30%,这意味着剩余的70%将用作训练集。最后,random_state=42 确保了每次代码运行时划分的方式都相同,这有助于实验的可重复性。通过这种方式,我们可以确保模型在训练时有足够的数据,并且在测试时有代表性的数据来验证模型性能。
# 5. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
3.5 定义岭回归模型
在这部分代码中,我们定义了岭回归模型,它是一种用于回归任务的统计方法。这里使用的是 Ridge 类,它也来自于Python的scikit-learn库。岭回归是线性回归的一个变种,主要用于处理具有多重共线性(自变量之间高度相关)的数据集。
岭回归通过引入所谓的L2正则化项来解决共线性问题。L2正则化项是对模型系数的平方和进行惩罚,其强度由参数 alpha 控制。较大的 alpha 值意味着更强的正则化,有助于减少过拟合,但同时也可能导致欠拟合。因此,选择一个适当的 alpha 值对于模型的性能至关重要。
岭回归特别适合于那些特征数量可能大于样本数量的情况,或者当各个特征之间存在一定程度的相关性时。这种方法通过缩减系数来减少模型的复杂度,从而提高模型的泛化能力。
通过定义这个模型,我们可以在训练数据上训练它,并用它来对测试数据进行预测。在预测房价、股票价格等连续变量时,岭回归模型通常表现良好,因为它能够处理那些可能导致普通线性回归失败的数据集特征。
# 6. 定义岭回归模型和参数网格
model = Ridge()
以下是以表格形式展示的 sklearn 中 Ridge 类的常用参数,包括参数名称、描述以及可选的值或类型:
| 参数 | 描述 | 可选的值/类型 |
|---|---|---|
alpha | 正则化强度,控制L2正则化的程度。较大的值表示更强的正则化。 | 正浮点数 |
solver | 用于计算岭回归系数的算法。不同的算法有不同的性能特点和限制。 | ‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’ |
fit_intercept | 是否计算该模型的截距。如果设置为 False,则不会在计算中使用截距(即,数据被假设已经居中)。 | 布尔值 |
max_iter | 求解器进行迭代的最大次数(仅适用于’sag’和’saga’求解器)。 | 正整数或 None |
tol | 解的精度(求解器停止的标准)。 | 正浮点数 |
random_state | 当solver使用’sag’或’saga’时,用于随机数生成器的种子。 | 整数或 None |
normalize | 在拟合前是否对数据进行归一化处理。在solver设置为’svd’时会忽略。 | 布尔值 |
这些参数提供了对岭回归模型进行微调的灵活性,以优化其在特定数据集上的性能。正确理解和应用这些参数对于提高模型的预测准确性和泛化能力至关重要。例如,通过调整alpha值,可以在偏差与方差之间找到一个平衡点,而选择合适的solver可以根据数据的大小和特性提高计算效率。
3.6 网格搜索
这段代码的目的是通过网格搜索(Grid Search)来寻找岭回归模型的最佳参数。具体来说,代码执行了以下几个关键步骤:
-
定义参数网格:首先,定义了一个名为
param_grid的字典,其中包含了想要优化的参数。在这个例子中,我们只关注alpha参数,它控制着岭回归中的正则化强度。alpha的值被设置为一个列表[0.1, 1, 10, 100],意味着网格搜索将尝试这四个不同的alpha值来找出最优的一个。 -
初始化 GridSearchCV:接下来,使用
GridSearchCV类来设置网格搜索。这个类是 scikit-learn 提供的一个强大工具,用于系统地遍历多种参数组合,通过交叉验证找到最佳的参数设置。这里传入了三个参数:model(即我们的岭回归模型),param_grid(定义的参数网格),和cv=5(指定5折交叉验证)。return_train_score=True表示在搜索过程中返回每个参数组合在训练集上的评分。 -
执行网格搜索:通过调用
grid_search.fit(X_train, y_train),网格搜索在训练数据上执行,尝试所有可能的alpha值组合,以找出最佳参数设置。在这个过程中,它将使用交叉验证来评估每种参数组合的性能。 -
输出最佳参数和模型:搜索完成后,代码使用
grid_search.best_params_打印出最优的参数组合。这告诉我们在给定的候选列表中,哪个alpha值使模型表现最好。同时,grid_search.best_estimator_提供了已经使用最佳参数设置过的模型实例,即best_model。这个模型已经准备好用于预测或进一步分析。
总体来说,这段代码非常有用于参数调优,帮助我们以一种系统和高效的方式找到模型的最优参数配置。
param_grid = {
'alpha': [0.1, 1, 10, 100] # 正则化强度
}
# 使用网格搜索,寻找最佳参数(包含训练得分)
grid_search = GridSearchCV(model, param_grid, cv=5, return_train_score=True)
grid_search.fit(X_train, y_train)
# 7. 网格搜索后的最佳参数和模型
print("最佳参数:", grid_search.best_params_)
best_model = grid_search.best_estimator_
3.7 评估指标
这段代码的目的是评估岭回归模型在训练集和测试集上的性能。具体来说,它执行了以下步骤:
-
预测:首先,使用最佳模型(
best_model,即通过网格搜索找到的参数最优化的岭回归模型)来预测训练集(X_train)和测试集(X_test)的响应变量。这一步通过调用predict方法完成,分别生成train_predictions和test_predictions。 -
计算均方根误差(RMSE):接着,代码使用
mean_squared_error函数来计算模型预测值和实际值之间的均方误差,再通过取平方根得到均方根误差(RMSE)。RMSE 是回归模型常用的性能指标,它提供了误差的平均大小。对于训练集和测试集分别计算,得到train_rmse和test_rmse。 -
计算决定系数(R2 Score):然后,代码计算了决定系数(R2 Score),使用
r2_score函数。决定系数是衡量模型拟合优度的指标,它表示模型对数据变异性的解释程度。值越接近1,表示模型解释的变异性越多,拟合效果越好。同样地,这个指标分别对训练集和测试集计算,得到train_r2和test_r2。 -
打印结果:最后,代码打印了这些评估指标,包括训练集和测试集的 RMSE 和 R2 Score。这提供了一个关于模型性能的直观理解,包括模型在训练集上的拟合能力以及在未见数据(测试集)上的泛化能力。
总体而言,这段代码非常重要,因为它帮助我们理解和评估模型的性能,确保模型既没有过拟合(在训练数据上表现过好)也没有欠拟合(在训练数据上表现不足)。
# 8. 单独打印训练集和测试集的模型评估指标
train_predictions = best_model.predict(X_train)
test_predictions = best_model.predict(X_test)
train_rmse = np.sqrt(mean_squared_error(y_train, train_predictions))
test_rmse = np.sqrt(mean_squared_error(y_test, test_predictions))
train_r2 = r2_score(y_train, train_predictions)
test_r2 = r2_score(y_test, test_predictions)
print(f"训练集 RMSE: {train_rmse:.4f}, R2: {train_r2:.4f}")
print(f"测试集 RMSE: {test_rmse:.4f}, R2: {test_r2:.4f}")
打印结果:
最佳参数: {'alpha': 1}
训练集 RMSE: 0.7234, R2: 0.6093
测试集 RMSE: 0.7284, R2: 0.5958
通过这些评估指标,我们能够全面了解模型在训练数据和未知数据上的表现,判断模型是否出现了过拟合或欠拟合的现象,并对模型的泛化能力做出判断。这对于理解和改进机器学习模型至关重要。
3.8 结果可视化
之后,我们对结果进行了可视化,例如:训练曲线、真实值与预测值关系图、误差分布图。
3.8.1 训练曲线
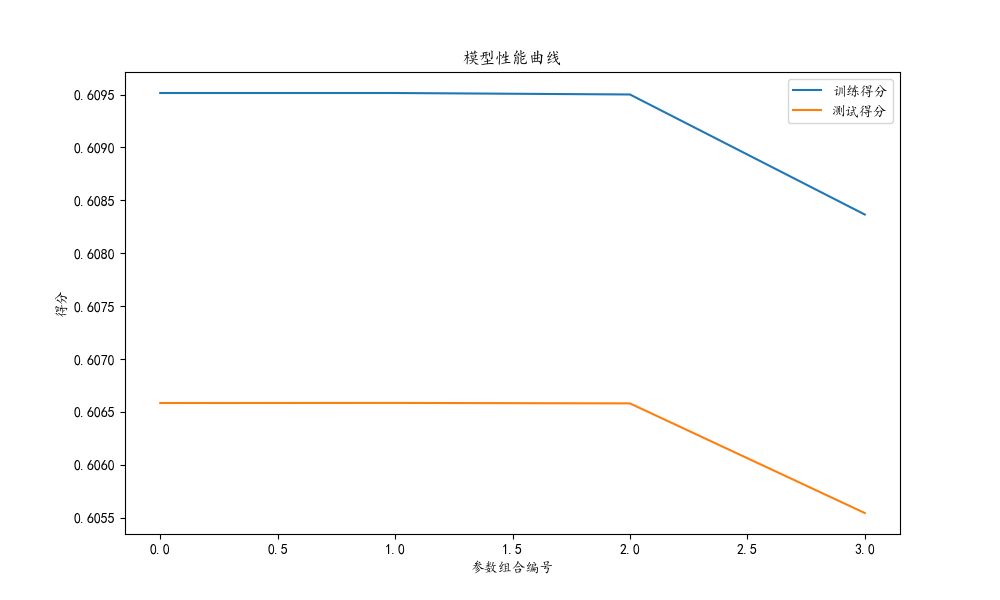
这段代码的主要目的是绘制岭回归模型在网格搜索过程中的训练曲线。它展示了不同参数组合下模型在训练集和交叉验证测试集上的平均得分。具体步骤如下:
-
获取网格搜索结果:
cv_results = grid_search.cv_results_这行代码从网格搜索(GridSearchCV)的结果中提取了各项详细信息。cv_results_是一个包含了每次训练/验证过程详细结果的字典。 -
提取训练和测试得分:接下来,代码从这个字典中提取了
mean_train_score和mean_test_score。这两个值分别表示对于每个参数组合,模型在训练集和交叉验证测试集上的平均得分。这些得分通常用于评估模型的性能。 -
绘制性能曲线:
- 使用
plt.figure设置图表大小。 plt.plot用于绘制曲线,分别为训练得分和测试得分。- 添加了图表标题(
plt.title)、坐标轴标签(plt.xlabel和plt.ylabel)以及图例(plt.legend)。
- 使用
-
展示图表:最后,
plt.show()显示了绘制好的图表。这张图表可以帮助我们直观地理解不同参数组合下模型的表现情况,包括过拟合和欠拟合的趋势。例如,如果训练得分远高于测试得分,可能表明模型过拟合;如果两者都较低,则可能是欠拟合。
总体而言,这段代码非常有用于评估模型在不同参数设置下的性能,以及选择最优的参数组合。通过这种方式,可以更好地理解模型如何在特定的数据集上表现,并据此作出调整。
# 9. 绘制模型的训练曲线
cv_results = grid_search.cv_results_
mean_train_score = cv_results['mean_train_score']
mean_test_score = cv_results['mean_test_score']
plt.figure(figsize=(10, 6))
plt.plot(mean_train_score, label='训练得分')
plt.plot(mean_test_score, label='测试得分')
plt.title('模型性能曲线')
plt.xlabel('参数组合编号')
plt.ylabel('得分')
plt.legend()
plt.show()
3.8.2 真实值与预测值关系图
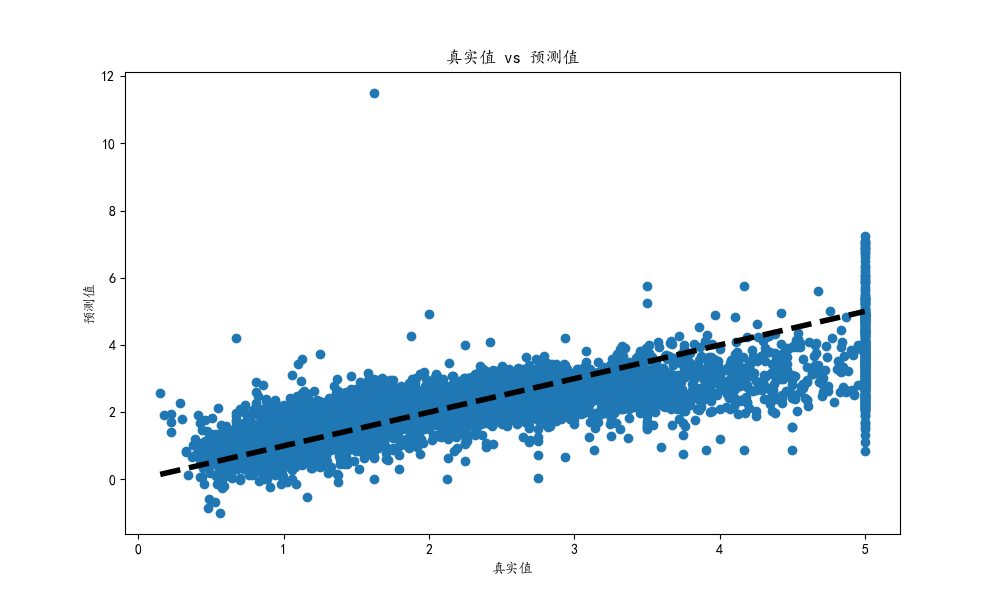
这段代码用于可视化真实值与预测值之间的关系,它是评估回归模型性能的一个直观方式。具体来说,代码执行了以下几个操作:
-
设置图表大小:
plt.figure(figsize=(10, 6))设置了绘图的大小,确保图表足够大,以便清晰地展示数据点。 -
绘制散点图:
plt.scatter(y_test, test_predictions)绘制了一个散点图,其中横坐标是测试集的真实值(y_test),纵坐标是模型对测试集的预测值(test_predictions)。这样的散点图有助于直观地观察预测值与真实值的一致性。 -
添加坐标轴标签和标题:
plt.xlabel('真实值')和plt.ylabel('预测值')分别设置了横轴和纵轴的标签。plt.title('真实值 vs 预测值')添加了图表的标题,表明图表的内容和目的。
-
绘制参考线:
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)绘制了一条黑色虚线,这条线表示完美预测的情况,即预测值完全等于真实值。这条线作为参考,可以帮助我们评估预测值偏离真实值的程度。 -
展示图表:最后,
plt.show()显示了绘制好的图表。
通过这个图表,我们可以快速判断模型的预测性能。理想情况下,散点应该紧密地围绕着参考线分布,这表明预测值与真实值非常接近。如果点离线太远,则表明预测误差较大。这种可视化是理解和解释模型预测性能的重要工具。
# 10. 可视化真实值与预测值的关系
plt.figure(figsize=(10, 6))
plt.scatter(y_test, test_predictions)
plt.xlabel('真实值')
plt.ylabel('预测值')
plt.title('真实值 vs 预测值')
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
plt.show()
3.8.3 误差分布图
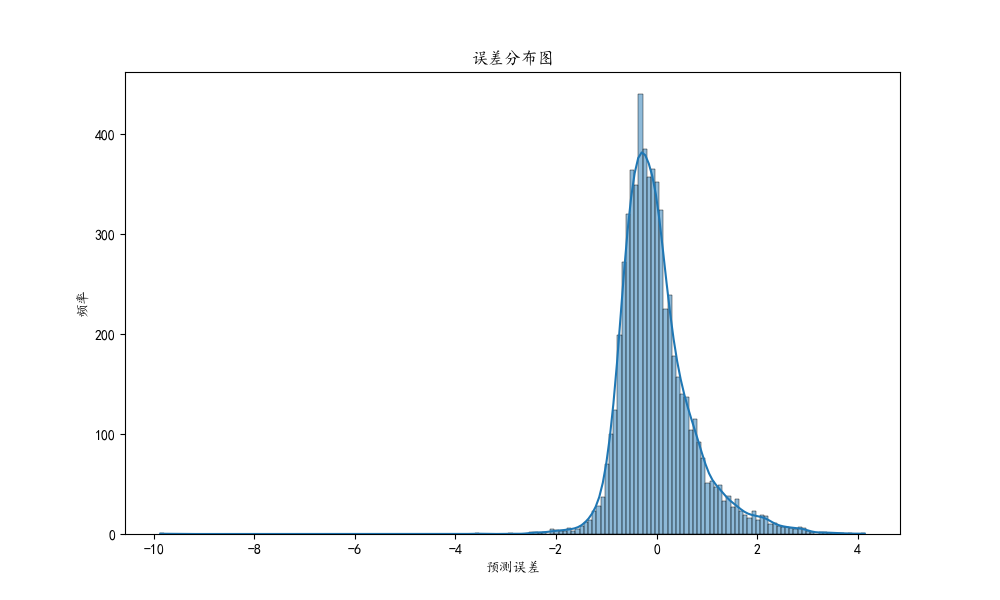
这段代码用于绘制模型预测误差的分布图,帮助我们理解模型在预测时的误差特性。具体步骤如下:
-
计算误差:首先,
errors = y_test - test_predictions这行代码计算了测试集的真实值 (y_test) 和模型预测值 (test_predictions) 之间的差异,即预测误差。这个误差反映了模型预测的准确性。 -
设置图表大小:
plt.figure(figsize=(10, 6))设置了图表的大小,确保图表足够大,以便清晰地展示数据。 -
绘制直方图和核密度估计(KDE):
sns.histplot(errors, kde=True)使用 seaborn 库绘制了误差的直方图,并且加上了核密度估计(KDE)。直方图显示了不同误差值的频率分布,而 KDE 曲线提供了误差分布的平滑估计。 -
添加坐标轴标签和标题:
plt.xlabel('预测误差')和plt.ylabel('频率')分别设置了横轴和纵轴的标签。plt.title('误差分布图')添加了图表的标题,说明了图表的主要内容。
-
展示图表:
plt.show()显示了绘制好的图表。
通过这个误差分布图,我们可以直观地看到模型预测误差的分布情况。在理想的情况下,误差分布应该接近于正态分布,且集中在零附近。这表示模型的预测通常是准确的,且没有系统性偏差。如果误差分布偏离这种形态,比如长尾或偏斜,那么可能表明模型存在某些系统性问题。这种可视化是评估和改进模型预测性能的重要工具。
# 11. 绘制误差分布图
errors = y_test - test_predictions
plt.figure(figsize=(10, 6))
sns.histplot(errors, kde=True)
plt.xlabel('预测误差')
plt.ylabel('频率')
plt.title('误差分布图')
plt.show()
完整源码
import warnings
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams["axes.unicode_minus"] = False
# 1. 导入所需的库
# 已在代码开头导入
# 2. 加载回归数据集
housing = fetch_california_housing()
X, y = housing.data, housing.target
# 3. 数据预处理
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 4. 特征工程
# 在这个例子中,我们直接使用了原始特征,没有进行额外的特征工程
# 5. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 6. 定义岭回归模型和参数网格
model = Ridge()
param_grid = {
'alpha': [0.1, 1, 10, 100] # 正则化强度
}
# 使用网格搜索,寻找最佳参数(包含训练得分)
grid_search = GridSearchCV(model, param_grid, cv=5, return_train_score=True)
grid_search.fit(X_train, y_train)
# 7. 网格搜索后的最佳参数和模型
print("最佳参数:", grid_search.best_params_)
best_model = grid_search.best_estimator_
# 8. 单独打印训练集和测试集的模型评估指标
train_predictions = best_model.predict(X_train)
test_predictions = best_model.predict(X_test)
train_rmse = np.sqrt(mean_squared_error(y_train, train_predictions))
test_rmse = np.sqrt(mean_squared_error(y_test, test_predictions))
train_r2 = r2_score(y_train, train_predictions)
test_r2 = r2_score(y_test, test_predictions)
print(f"训练集 RMSE: {train_rmse:.4f}, R2: {train_r2:.4f}")
print(f"测试集 RMSE: {test_rmse:.4f}, R2: {test_r2:.4f}")
# 9. 绘制模型的训练曲线
cv_results = grid_search.cv_results_
mean_train_score = cv_results['mean_train_score']
mean_test_score = cv_results['mean_test_score']
plt.figure(figsize=(10, 6))
plt.plot(mean_train_score, label='训练得分')
plt.plot(mean_test_score, label='测试得分')
plt.title('模型性能曲线')
plt.xlabel('参数组合编号')
plt.ylabel('得分')
plt.legend()
plt.show()
# 10. 可视化真实值与预测值的关系
plt.figure(figsize=(10, 6))
plt.scatter(y_test, test_predictions)
plt.xlabel('真实值')
plt.ylabel('预测值')
plt.title('真实值 vs 预测值')
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
plt.show()
# 11. 绘制误差分布图
errors = y_test - test_predictions
plt.figure(figsize=(10, 6))
sns.histplot(errors, kde=True)
plt.xlabel('预测误差')
plt.ylabel('频率')
plt.title('误差分布图')
plt.show()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 浏览器进程模型和JS的事件循环
- 深度了解六西格玛培训:用MINITAB软件优化数据处理和项目管理——张驰咨询
- 重定向的原理及代码演示
- Linux网络编程
- 腾讯地图绘画多边形和计算面积
- 【leetcode100-029】【链表/双指针】删除链表的倒数第N个节点
- 【教程】蓝奏云网盘API接口并解除官方限制
- seatunnel部署遇到的一些问题及总结
- 国产系统-银河麒麟桌面版系统进入root用户
- mybatis之TypeHandler,再也不怕数据库与实体类之间的数据转换问题了