逻辑斯蒂回归-建模概率计算(鸢尾花)
发布时间:2023年12月22日
导入的数据说明
因为气候不同,造就性不同,统计鸢尾花的关键特征数据:花萼长度、花萼宽度、花瓣长度,花瓣宽度
植物学家划分:
setosa(中文名:山鸢尾)
versicolor(中文名:杂色鸢尾)
virginica(中文名:弗吉尼亚鸢尾)
鸢尾花数据集中每个样本包含有四个特种(花萼长度、花萼宽度、花瓣长度,花瓣宽度),用于对鸢尾花的分类
导入包
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 1、数据加载
iris = datasets.load_iris()
X = iris['data']
y = iris['target']
cond = y != 2 # 筛选出0和1
X = X[cond]
y = y[cond]
# 数据拆分
X_train,X_test,y_train,y_test = train_test_split(X,y)
display(y)
模型的创建和模型预测
model = LogisticRegression()
model.fit(X_train,y_train)
y_pred = model.predict(X_test) # 预测分类结果
print('算法预测结果是:',y_pred)
print('真实的类别是:',y_test)
print(model.score(X_test,y_test))

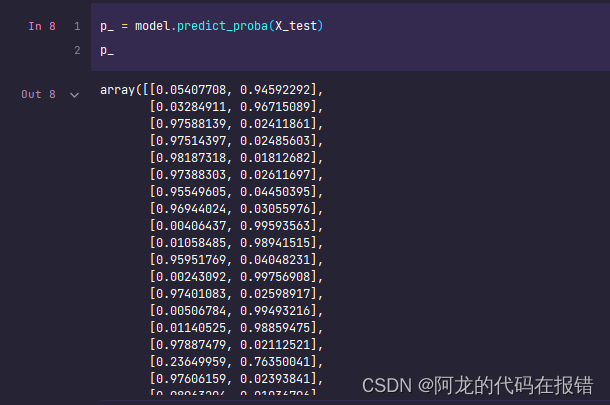
p_ = model.predict_proba(X_test)
p_
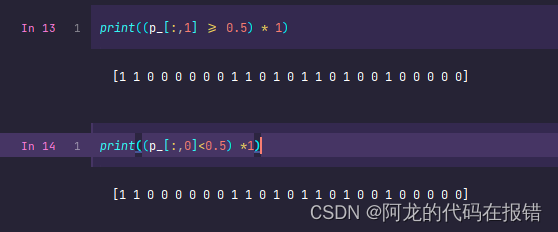
(p_[:,1] >= 0.5) * 1
(p_[:,1] < 0.5) * 1
3.2 根据公式手动计算
z = ? θ T x z = -\theta^Tx z=?θTx
# 线性回归方程
b = model.intercept_
w = model.coef_
print(b, w)
# 逻辑回归函数 ,z表示线性回归方程
def sigmoid(z):
return 1 / (1 + np.exp(-z))
如果直接使用w则会出现形状不匹配的报错的情况出现,这个时候需要进行转至
# 转至前:
print(w.shape)
# 转至后
print(w.T.shape)

线性方程 乘法
z = (X_test.dot(w.T) + b)
proba_ = sigmoid(z)
proba_ = np.c_[proba_,1-proba_]
proba_
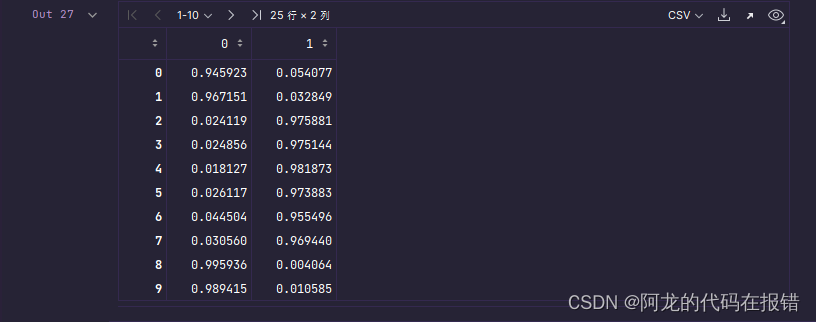
和上面的预测数据进行对比结果一致
愿君前程似锦,未来可期去💯,感谢您的阅读,如果对您有用希望您留下宝贵的点赞和收藏
本文章为本人学习笔记,如有请侵权联系,本人会立即删除侵权文章。可以一起学习共同进步谢谢,如有请侵权联系,本人会立即删除侵权文章。
文章来源:https://blog.csdn.net/yujinlong2002/article/details/135147516
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java研学-spring框架(一)
- 微信小程序 - 导航 、wxs及生命周期函数
- [ECE] 2.1 - 2.6 Number Systems, Operations
- 抖音直播间websocket礼物和弹幕消息推送可能出现重复的情况,解决办法
- 系统学习Python——装饰器:函数装饰器-[装饰器状态保持方案:外层作用域和全局变量]
- Mr_HJ / form-generator项目文档学习与记录(续1)
- LeetCode-反转链表问题
- python类继承之__init__函数覆盖问题
- 《WebKit 技术内幕》之五(4): HTML解释器和DOM 模型
- ECharts基本使用(入门)