SpringCloud-高级篇(十一)
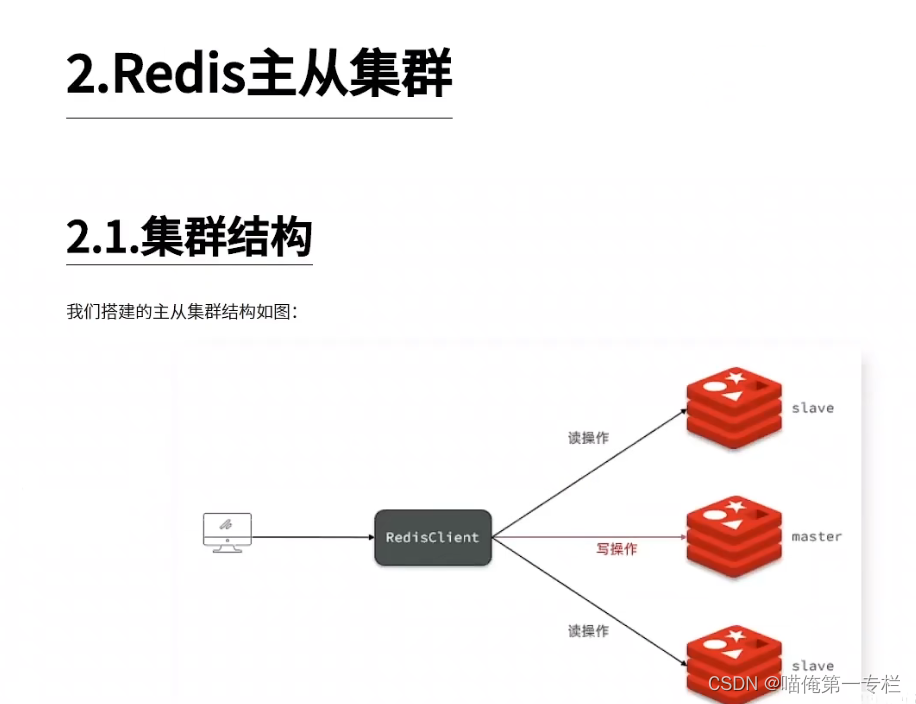
(1)搭建Redis-主从架构
前面我们实现了Redis的持久化,解决了数据安全问题,但是还有需要解决的问题,下面学习Redis的主从集群,解决Redis的并发能力的问题

Redis的集群往往是主从集群,Redsi为什么做成主从的集群,而不做成传统负载均衡的集群呢?因为Redis应用当中往往都是读多写少的场景,查询比较多,增删改比较少,我们更多应对的是读的压力,做读写分离,一主多从,多个从节点共同承担读的请求,并发能力能够做到很大的提升,这就是为啥搭建主从集群
需要保证客户端无论访问那个从节点都要拿到相同的结果

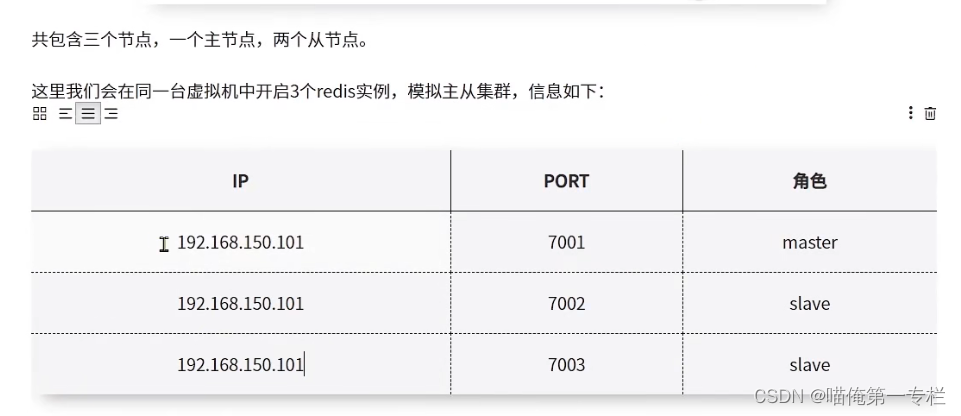

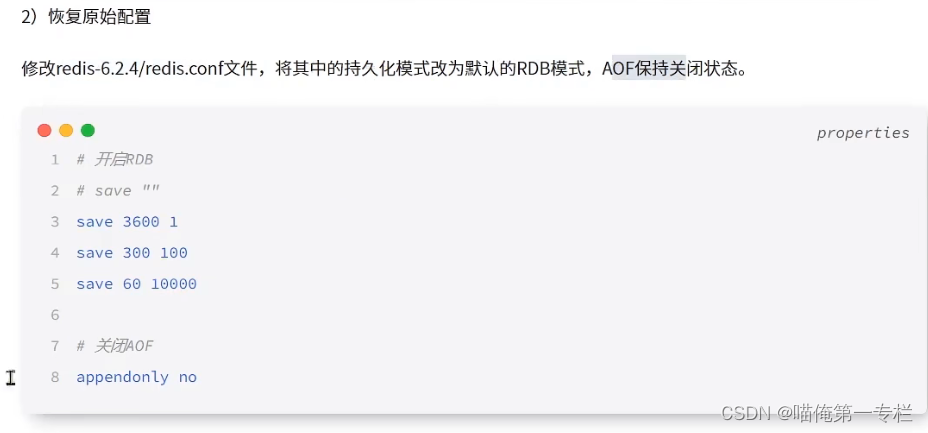
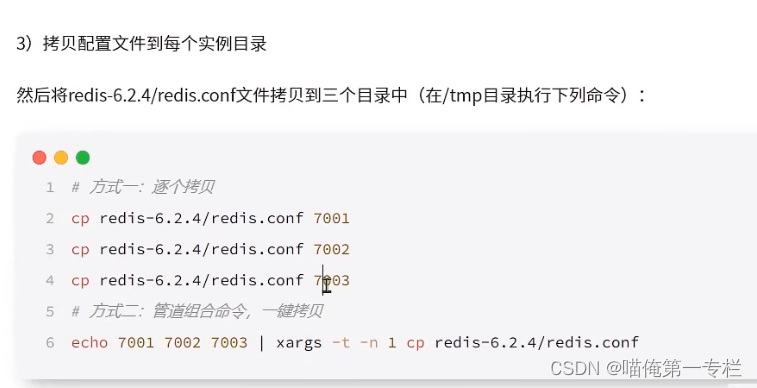

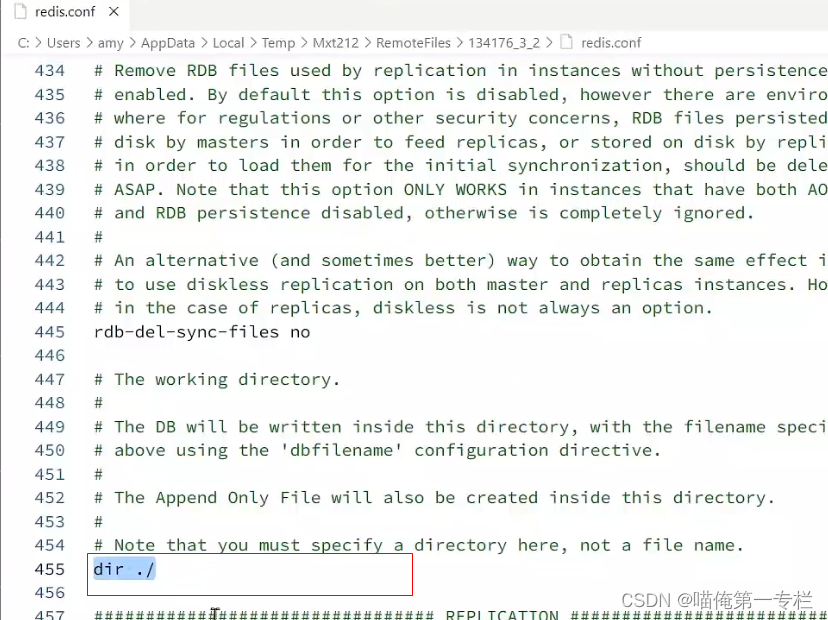
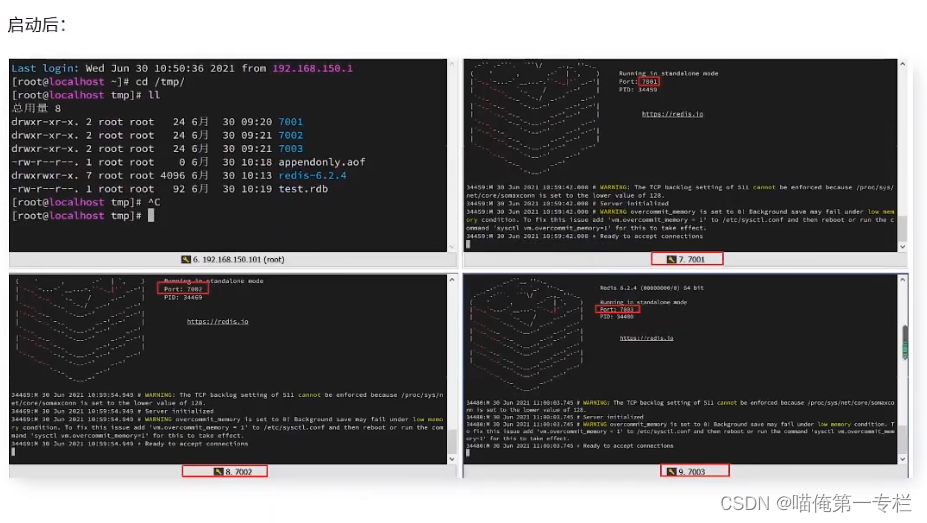
修改每个配置文件
修改数据保存目录:默认是当前目录:
一个一个配置文件改比较麻烦可以使用一个命令:
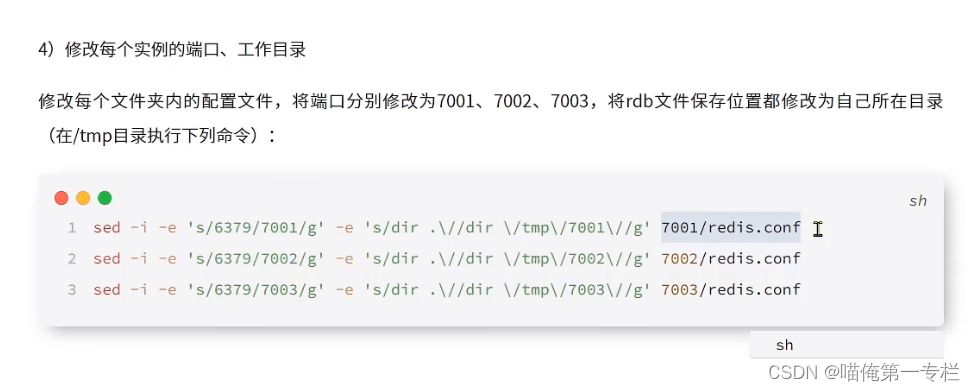
s表示替换:把6379替换成7001 g是全局? 把dir .替换成、tmp\7001
 ?
?
1a:表示在第一行的后面追加一行


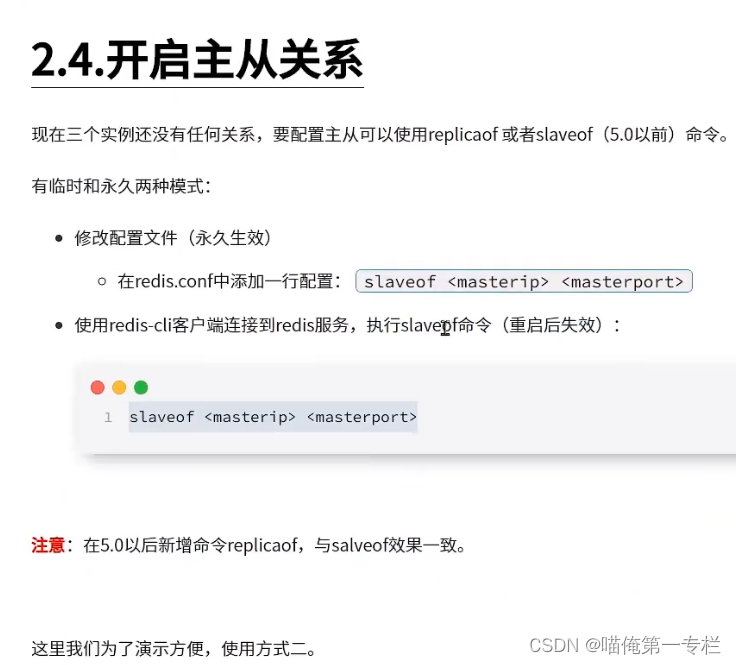

7002设置为7001的从节点:?

此时7001会有日志产生:来自7002的请求数据同步

把7003设置为7001的从节点:replicaod跟slaveof命令效果一致

此时7001会有日志产生:来自7003的请求数据同步

查看7001的状态信息:从属关系
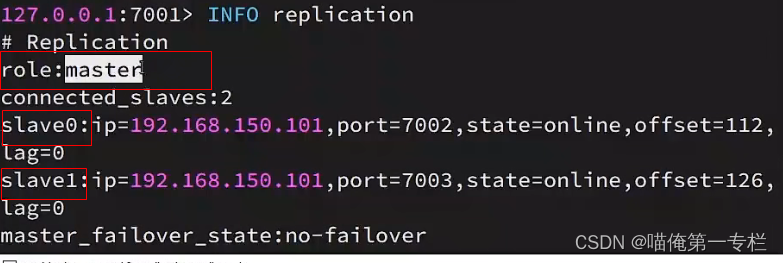
主节点:?
从节点?

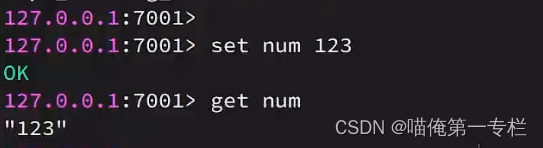
从节点不能够写:?
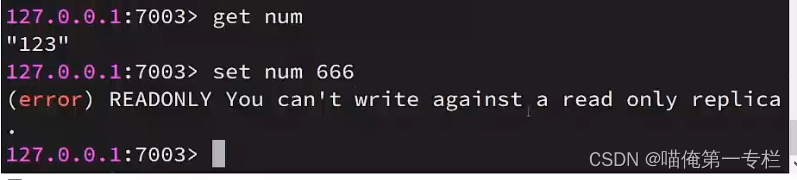
就实现了主节点做些操作,从节点做读操作
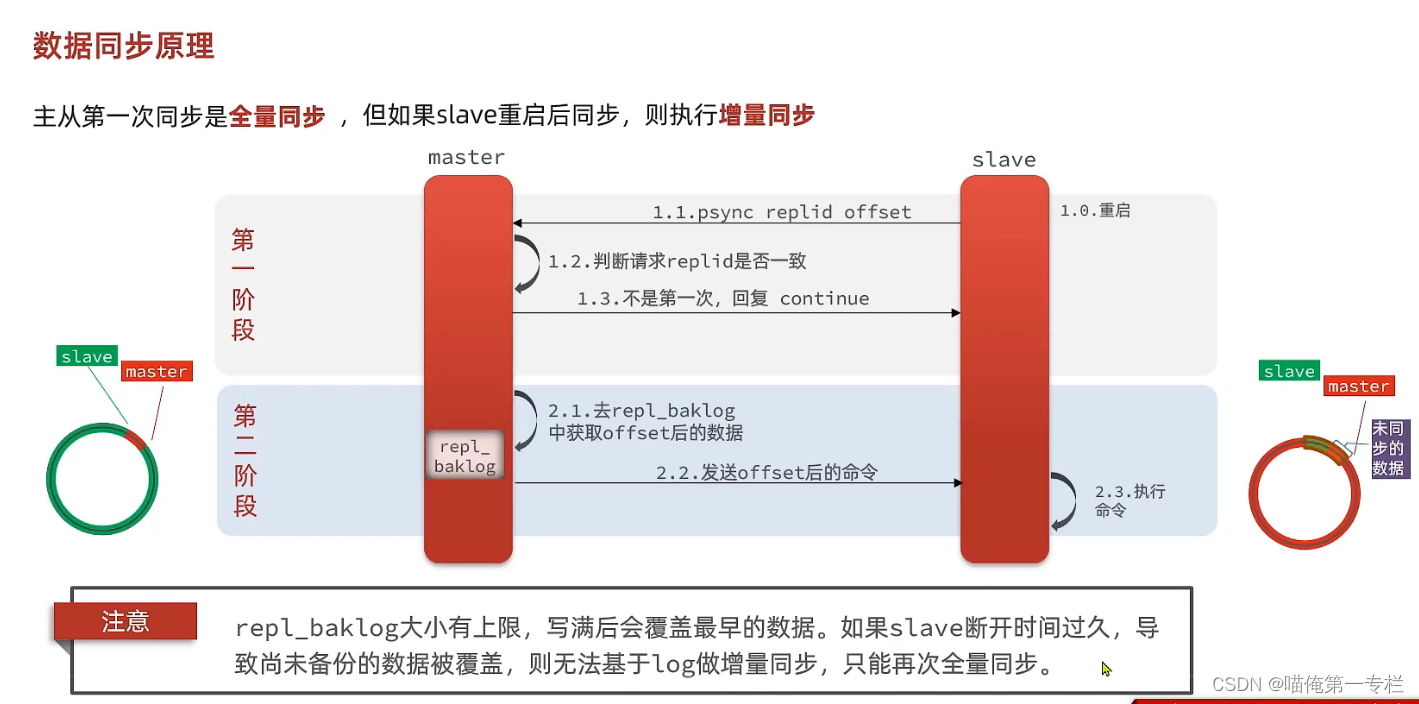
(2)数据同步原理
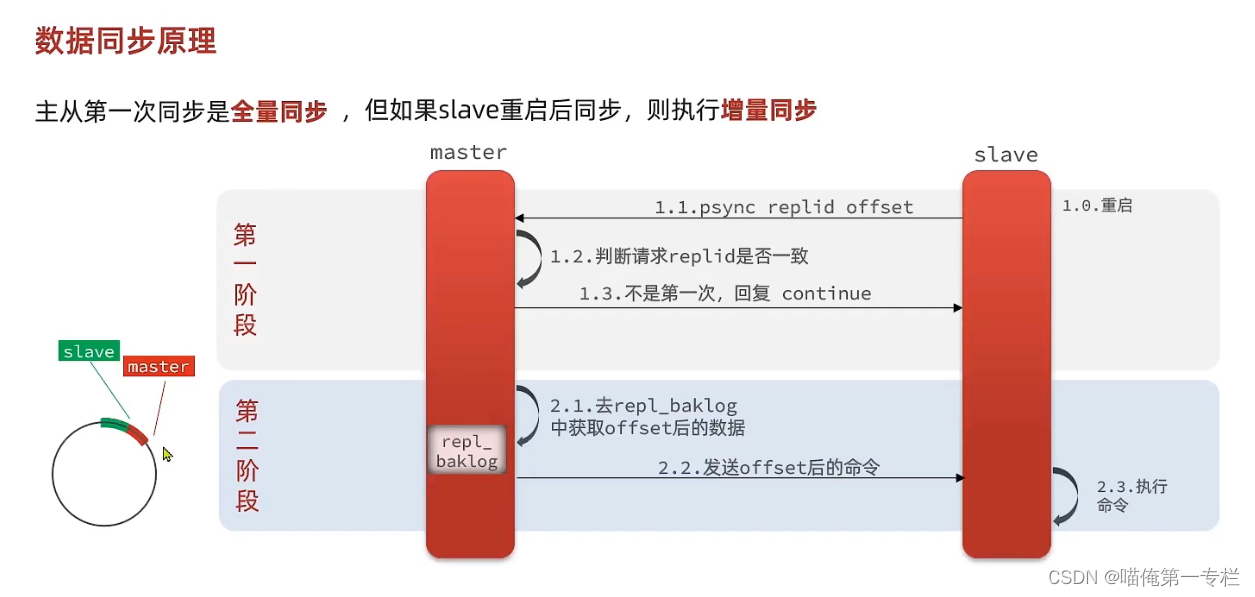
数据同步的底层是如何做到的
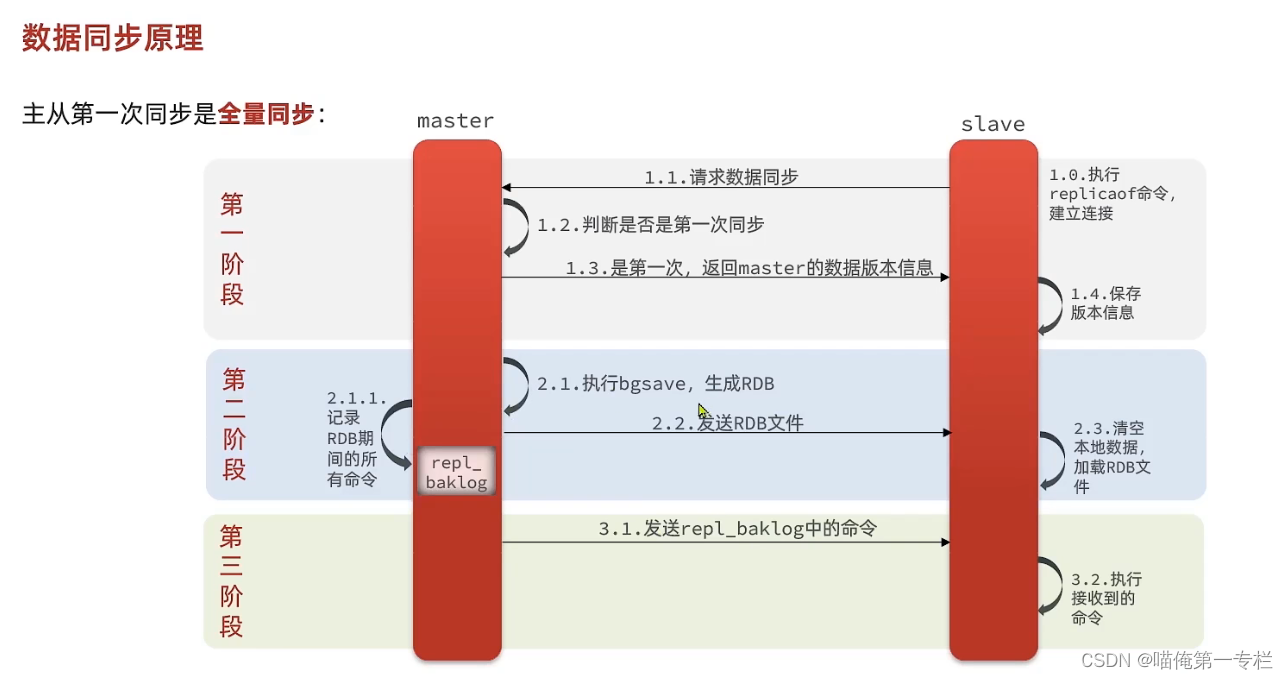
全量同步:有一个RDB的过程,会把内存形成快照,整体发送给slave,是比较消耗性能的,生成RDB的速度比较慢,全量拷贝
Redis全量同步


第二次来,就可以根据offset来判断你的进度了,可以基于它做增量同步
查看我们的日志
7002日志:连接? ? sync同步
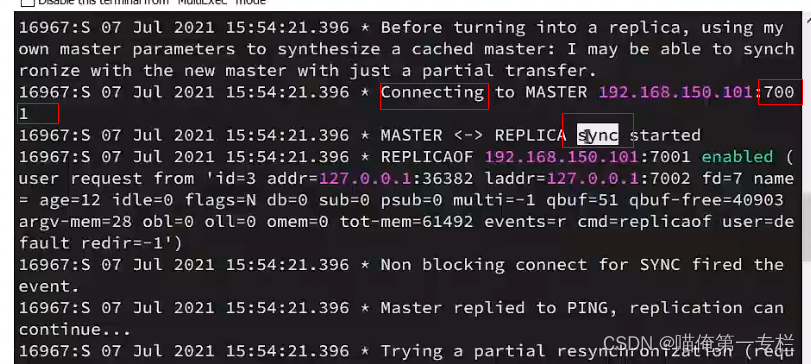
第一次7002请求尝试做局部的同步:增量同步,它会传过去id 和offset:1
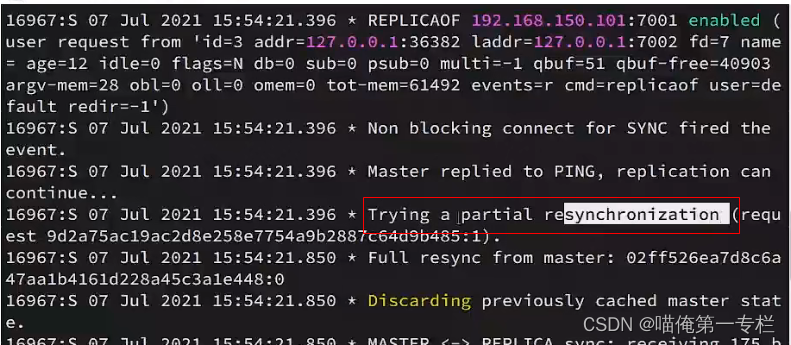
7001主节点:主节点接口到增量同步,判断id不一样,就拒绝增量同步
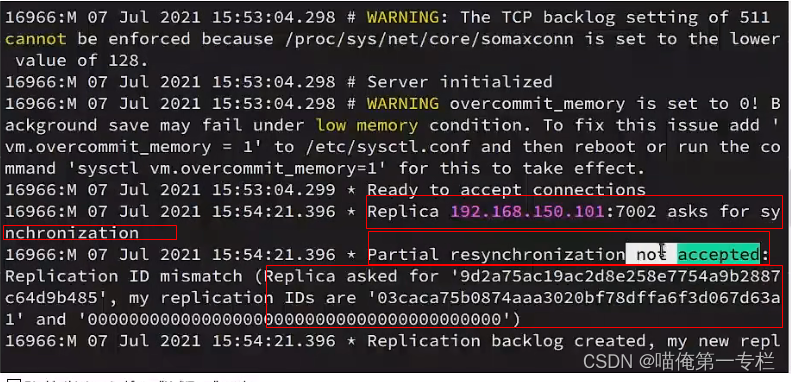
拒绝之后做全量同步:?
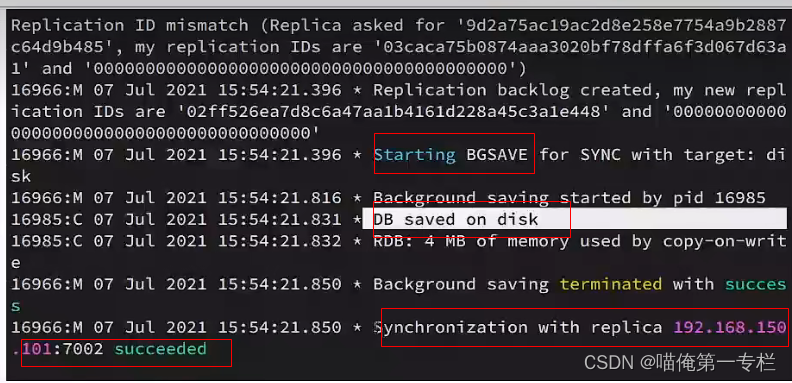
7002只能做全量同步:
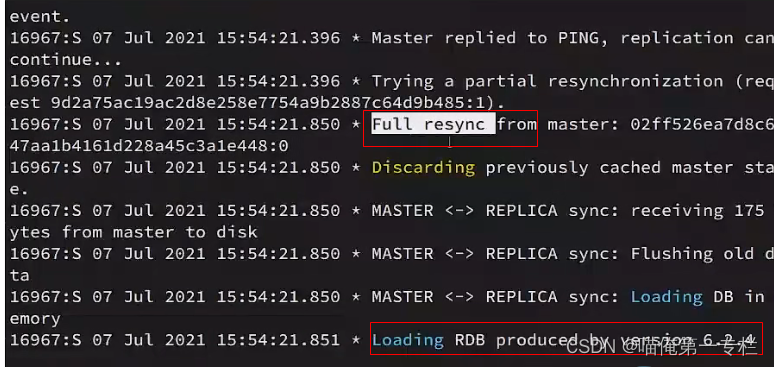

Reids增量同步
在什么情况下无法做增量同步:
offset底层是一个数组,
当slave宕机后,master在一直接收新数据,一直走,当它超多slave的宕机处,走了一环还在走,
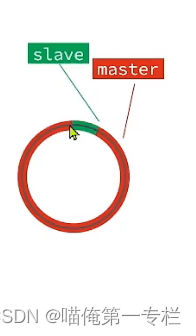
slave欠的太多了一环没有记下,又多了一部分

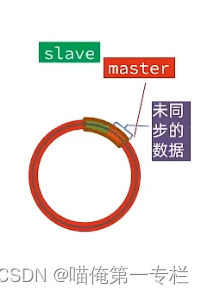
这部分的数据被覆盖了,就消失了只能去master的内存中去找,只能去做全量同步了
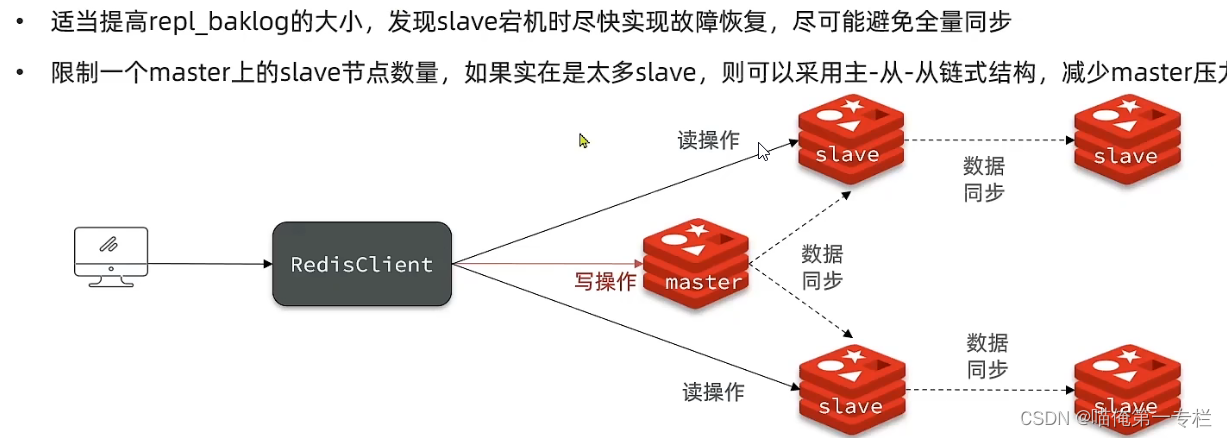
(3)主从同步的优化
从两个方面:
1.尽可能的减少全量同步,全量同步的性能比较差嘛
2.优化全量同步的性能
? ?在配置文件中做无磁盘复制:正常的复制要生成RDB文件,比如说内存有10g,要在磁盘写10g,然后在把磁盘的文件通过网络发送给我们slave,磁盘的读写是比较慢的导致了,同步复制的效率比较低,无磁盘复制就是,当要写RDB文件时,就是io流,不去把它写入磁盘的io流,直接网络中,直接发给slave,减少了磁盘读写
在什么时候可以用呢?当磁盘很慢,网路很快,如果网络带宽不够快,会导致网络阻塞,一定要增加网络带宽
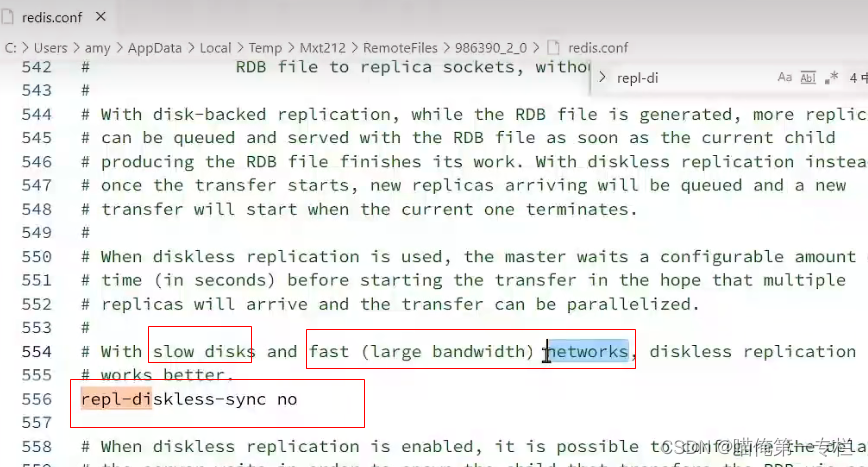
全量同步可以这样优化?

尽可能避免全量同步

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux安装系统遇到的问题
- 【JAVA】volatile 关键字的作用
- 模仿Activiti工作流自动建表机制,实现Springboot项目启动后自动创建多表关联的数据库与表的方案
- 永磁同步电机的磁场定向控制
- 《Training language models to follow instructions》论文解读--训练语言模型遵循人类反馈的指令
- 水平居中、垂直居中、水平垂直居中
- 制作小游戏能不能赚钱?
- 企业需要专业的合同档案管理系统吗
- SpringBoot框架入门
- Infant-freesurfer安装和使用,适用于0-2岁婴幼儿大脑自动分割