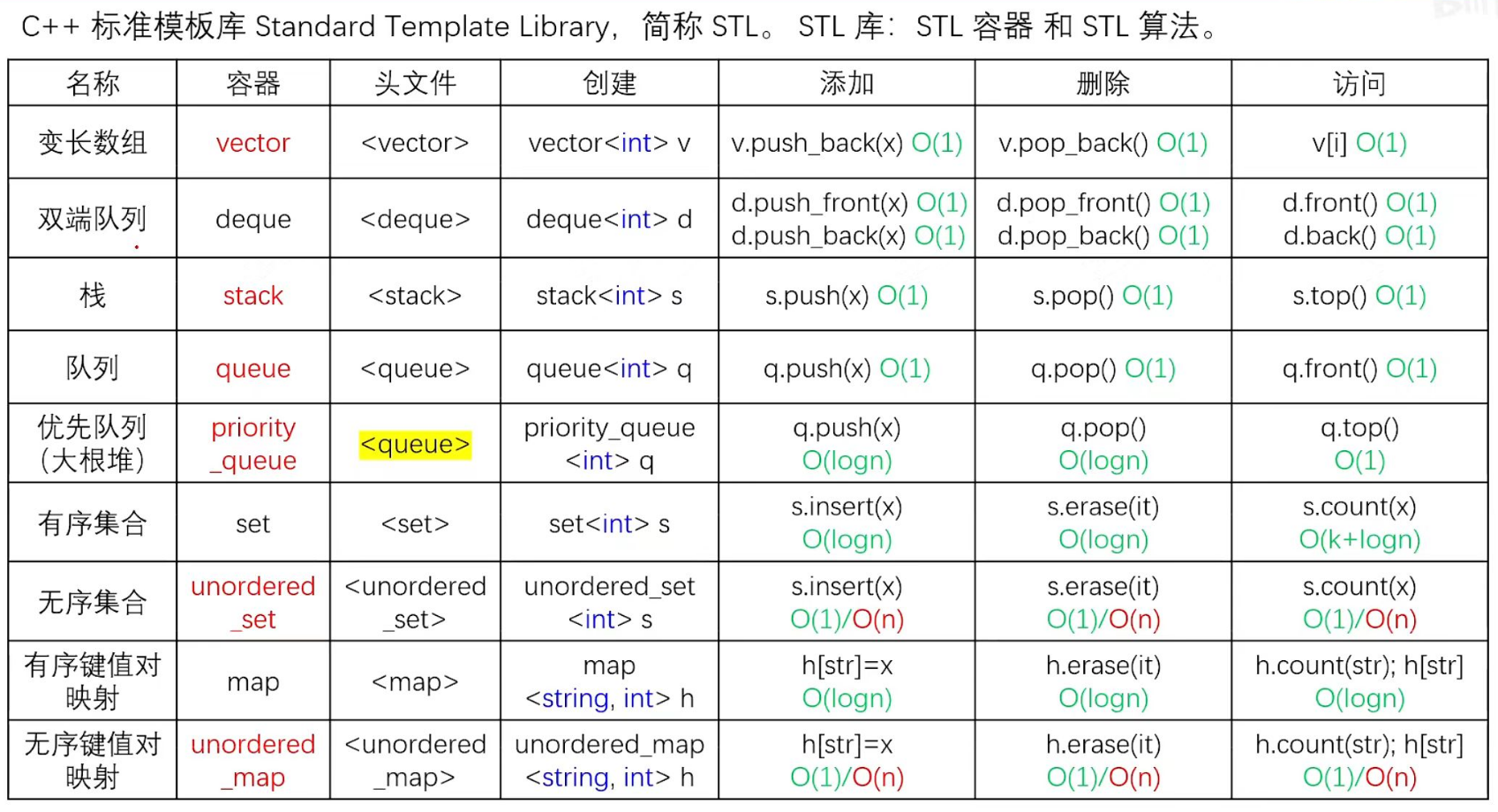
俩万字详解C++STL期末复习知识点(C++STL课本源码私信可得)
邸老师复习建议
复习注意事项
1 不考死记硬背的题,比如名词解释。
2 选择题重点考核宏观性、综合性的问题,比如:把电话通讯录存入容器,该选哪一个容器?
3 选择题重点考核理解性的问题,比如,我们这门课主要学习的内容?
4 选择题重点考核概念性的问题,比如,二个容器内容的比较问题,如果是集合容器,因集合无序的,你的比较算法应反映这一概念。如果是序列容器,因有序,你该用另一种算法。
5 关于程序阅读题,多数使用了模板技术,所以要熟练地掌握它们,包括特化、实例化等技术,也包括traits技术。
6 关于程序阅读题,一个可类比的难度是,如果用模板技术操作一个map, 因模板参数较多,map的元素特殊,所以阅读时是有困难的。
set的比较
心得:
- 邸老师的set比较强调:必须使用find函数,因为关联式容器都是没有顺序的,所以用equal就是纯扯淡
- 对于这个operator+ 返回值一定要小心
#include<iostream>
#include<set>
#include<map>
#include<sstream>
using namespace std;
template<typename T,typename PR1=less<T>,typename PR2=less<T> >
bool operator==(const set<T,PR1>& set1, const set<T,PR2>& set2)
{
if (set1.size() != set2.size())
{
return false;
}
typename set<T,PR1>::iterator it=set1.begin();
while(it!=set1.end())
{
if(set2.find(*it)==set2.end())
{
return false;
}
++it;
}
return true;
}
template<typename K,typename V>//,typename PR1=less<K>,typename PR2=less<K>
bool operator==(map<K,V> map1, map<K,V> map2)
{
if (map1.size() != map2.size())// 比较元素大小
{
return false;
}
//
typename map<K,V>::iterator map1_it=map1.begin();
while(map1_it!=map1.end())
{
typename map<K,V>::iterator map2_it=map2.find((*map1_it).first);
//map2_it就是一个迭代器 指向map2的位置
if(map2_it == map2.end() || (*map2_it).second != (*map1_it).second)
{
return false;
}
++map1_it;
}
return true;//如果一个一个找到了 那么就对了!
}
//输出map
template<typename K,typename V>
ostream& operator<<(ostream& out,map<K,V>m)
{
typename map<K,V>::iterator it=m.begin();
while(it!=m.end())
{
out <<"key:" << (*it).first << " " << "value:" << (*it).second << " ";
++it;
}
return out;
}
template<class K,class V1,class V2>
map<K,string>operator+(const map<K,V1>&m1,const map<K,V2>&m2)
{
stringstream os;
map<K,string>m;
typename map<K,V1>::const_iterator it1=m1.begin();
typename map<K,V2>::const_iterator it2;
while(it1!=m1.end())
{
it2=m2.find((*it1).first);
if(it2!=m2.end())//如果有key的话
{
os << (*it1).second;
os << "-";
os << (*it2).second;
m[(*it1).first]=os.str();
os.str("");//这里必须清空一下 要不然之前的还会存在
//输出流字符串 输入流和输入输出流 必须用clear() 三个流有俩种清空方式
}
++it1;
}
return m;
}
int main()
{
map<string,int>m1;
m1["haha"]=2; m1.insert(make_pair("hehe",1));
//m1先插入haha m2先插入hehe 但是map是无顺序的
map<string,int>m2;m2["hehe"]=1;m2.insert(make_pair("haha",2));
if(m1==m2)
{
cout << "map相等" << endl;
}
else
{
cout << "不相等" << endl;
}
cout << m1 << endl;cout << m2 << endl;
map<int,string>m3;m3[1]="原神";m3[2]="hehe";
map<int,string>m4;m4[1]="启动";m4[2]="haha";
cout << m3+m4 << endl;
map<int,string>m5;m5[1]=1.1;m5[2]=1.2;
map<int,double>m6;m6[1]=1.9;m6[2]=2.3;
cout << m5+m6 << endl;
return 0;
}
版本二:
#include<iostream>
#include<set>
#include<map>
#include<sstream>
//using namespace std;
// 定义操作符重载函数
//set map是无序的 再次强调 所以一定不可以用 equal 只可以用find
//-----------------------------------set的==函数--------------------------------------------------//
template<typename T,typename PR1=std::less<T>,typename PR2=std::less<T>> //三个模板参数
bool operator==(const std::set<T,PR1>& set1, const std::set<T,PR2>& set2)
{
if (set1.size() != set2.size())
{
return false;
}
// 逐个比较set中的元素
typename std::set<T,PR1>::iterator it=set1.begin(); //这个和查找60学生成绩不同 这个必须从最开始就开始找
while(it!=set1.end()) //这里一定注意小心写成 it!=set2.end() 这可就大错特错了
{
if(set2.find(*it)==set2.end())
{
return false;
}
++it;
}
return true;
}
//-----------------------------------map的==函数--------------------------------------------------//
namespace lzy
{
// 比较两个 pair 是否相等
template <typename K1, typename V1, typename K2, typename V2>
bool comparePairs(const std::pair<K1, V1>& pair1, const std::pair<K2, V2>& pair2)
{
return (pair1.first == pair2.first) && (pair1.second == pair2.second);
}
// 重载 map 的等于运算符
template<typename K1, typename V1, typename K2, typename V2>
bool operator==(std::map<K1, V1> map1, std::map<K2, V2> map2)
{
if (map1.size() != map2.size()) // 比较元素大小
{
return false;
}
typename std::map<K1, V1>::iterator it1 = map1.begin(); // 从 map1 的最开始找
typename std::map<K2, V2>::iterator it2;
while (it1 != map1.end())
{
it2 = map2.find((*it1).first); // 先找到 key
// 一旦 key 找不到或者 value 不匹配就说明不相等
if (it2 == map2.end() || !comparePairs(*it1, *it2))
{ // (*it2).second != (*it1).second)
return false;
}
++it1;
}
return true; // 如果一个一个找到了,那么就对了!
}
}
//-----------------------------------map的输出函数--------------------------------------------------//
template<typename K,typename V>
std::ostream& operator<<(std::ostream& out,std::map<K,V>m)
{
typename std::map<K,V>::iterator it=m.begin();
while(it!=m.end())
{
out <<"key:" << (*it).first << " " << "value:" << (*it).second << " ";
++it;
}
return out;
}
//------------------------------map的operator+函数--------------------------------------------------//
template<class K,class V1,class V2>
std::map<K,std::string>operator+(const std::map<K,V1>&m1,const std::map<K,V2>&m2)
{
std::stringstream os;
std::map<K,std::string>m;
typename std::map<K,V1>::const_iterator it1=m1.begin();
typename std::map<K,V2>::const_iterator it2;
while(it1!=m1.end())
{
it2=m2.find((*it1).first);
if(it2!=m2.end())//如果有key的话
{
os << (*it1).second;
os << "-";
os << (*it2).second;
m[(*it1).first]=os.str();
os.str("");//这里必须清空一下 要不然之前的还会存在
//输出流字符串 输入流和输入输出流 必须用clear() 三个流有俩种清空方式
}
++it1;
}
return m;
}
void test_set()
{
std::set<int> s1 = {1, 2, 4, 5};
std::set<int, std::greater<int>> s2 = {1, 2, 4, 5};
if (s1 == s2)
{
std::cout << "set相等" << std::endl;
}
else
{
std::cout << "set不相等" << std::endl;
}
}
void test_map()
{
std::map<std::string, int> m1;
m1["haha"] = 2;
m1.insert(std::make_pair("hehe", 1));
std::map<std::string, int> m2;
m2["hehe"] = 1;
m2.insert(std::make_pair("haha", 2));
if (m1 == m2) //lzy::operator==(m1, m2)
{
std::cout << "map相等" << std::endl;
}
else
{
std::cout << "不相等" << std::endl;
}
std::cout << m1 << std::endl;
std::cout << m2 << std::endl;
std::map<int, std::string> m3;
m3[1] = "原神";
m3[2] = "hehe";
std::map<int, std::string> m4;
m4[1] = "启动";
m4[2] = "haha";
std::cout << m3 + m4 << std::endl;
std::map<int, std::string> m5;std::map<int, double> m6;
m5[1] = "1.1";m5[2] = "1.2";
m6[1] = 1.9; m6[2] = 2.3;
std::cout << m5 + m6 << std::endl;
}
int main()
{
test_map();
return 0;
}
函数对象传递边界值
Teacher_Bai\7.1算法.cpp 白老师的这段代码 强烈建议好好品味
问题总结
为什么map也是集合?都是 邸老师说:元素之间没有关系 就是集合

感觉课本上很多代码都是一个套路:就是先创建一个元素类,接着利用对应的容器将类封装成为容器类型,并使这些元素进行整合操作
元素类里面一般需要写的东西:构造函数+各种各样的重载(小心set,map,priority_queue)+公有接口函数+show函数(如果不写show,那经常会重载<<)
容器组织类一般写的东西:构造函数(一般不写)+Add函数+show函数(往往会调用元素类里面的show函数) 等等 eg:词典问题
或者不写容器组织类,写函数对象类,对里面进行操作(注意参数,如果主函数的容器元素类型是自定义类,那么我们函数对象的参数一定也是自定义类型的) eg:图书类sort库存类问题
但还是不得不提醒一句,思维不可以太过固化,比如deque的评委打分问题,在选手类中,也需要实现对五个成绩的全部插入
而且小心:如果没有重载<< 下面调用类内元素的disp函数的时候,一定不要加cout<< ,应该是==(*it).disp();==
第一章:STL
STL主要包括
容器 算法 迭代器
第二章:trait技术模板特化?

答案:模板特化
2.1目的
traits主要用于解决需要兼容数据类型,而不同类型又有各自特点的问题
2.2定义


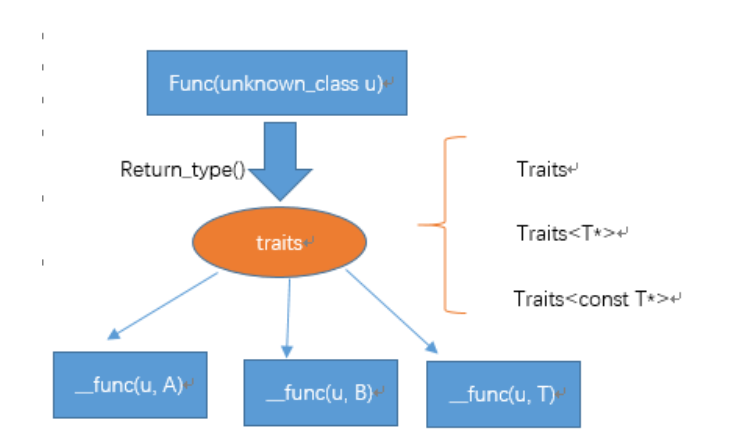
2.3内嵌类型typename
对于用于模板定义的依赖于模板参数的名称,只有在实例化的参数中存在这个类型名,或者这个名称前使用了 typename 关键字来修饰,编译器才会将该名称当成是类型。除了以上这两种情况,绝不会被当成是类型。
对于我们下面的resulttype而言 它如果不写typename的话 就会被编译器当成变量 但是resulttype明明是一个类型 所以得小心
我们常见的 T tmp 本身就是定义变量 是不需要加typename的
尤其是对于迭代器 typename map<K,V1>::iterator it1=m1.begin(); 如果不加typename的话 map<K,V1>::iterator就会被当成变量 这是万万不对的

内嵌例子
template<typename T>
void show(T& s)
{
typename T::iterator i=s.begin();
while(i!=s.end())
{
cout << *i << " ";
++i;
}cout << endl;
}
这个的意思是指明T的类型 告诉编译器T是一个类型 因为编译器从来没见过T 否则默认情况下 就会把T当成是一个变量
2.4trait技术核心要点
trait重点在于特化
屏蔽差异 提供统一界面 用到了模板特化 但不是模板特化
不要因为环境的不同 给用户造成了使用界面的不统一 就是trait的目的
技术出现的原因就是因为我们发现单纯实现模板类和统一接口编制类无法解决问题了,我们需要使用模板特化和typedef技术,给用户提供统一接口 课本上的套路为:俩个基本元素类+定义基本模板类+模板特化参数类typedef+统一接口类
#include<iostream>
using namespace std;
class Stu
{
public:
Stu(int n = 0)
:n(n)
{
}
float get_score()
{
return n * score;
}
private:
int n;
float score = 4.0f;
};
class Tea
{
public:
Tea(int n = 0)
:n(n)
{
}
int get_score()
{
return grade*n;
}
private:
float grade = 3;
int n;//课程数量
};
//通过一个类的接口函数来实现
template<class T>
class traits
{
};
template<>
class traits<Stu>
{
public:
typedef float result_type;
//typedef float input_type;
};
template<>
class traits<Tea>
{
public:
typedef int result_type;
//typedef int input_type;
};
template<class T>+
class give_grade
{
public:
typename traits<T>::result_type get_scores(T obj)
{
return obj.get_score();
}
};
int main()
{
Stu s1(3);
give_grade<Stu>s;
cout << s.get_scores(s1) << endl;
Tea t1(3);
give_grade<Tea>t;
cout << t.get_scores(t1) << endl;
return 0;
}
这段代码展示了模板类(give_grade)和特化类(traits)的使用。在这个例子中,give_grade类模板允许使用不同的类(如Stu和Tea)来计算分数,而traits特化类用于确定不同类的返回类型。
Stu和Tea类分别代表学生和老师,它们都有一个函数来获取分数。give_grade类模板中的get_scores函数接受一个对象,并通过调用对象的get_score函数来获取分数。traits特化类为每个类定义了结果类型,这样在give_grade类模板中就可以使用typename traits::result_type来确定返回类型。
这里体现了trait技术的地方在于traits特化类的使用。通过特化traits类来为不同的类定义不同的类型,使得在模板类中能够根据具体的类来确定返回类型,从而增加了代码的灵活性和可复用性。
代码易错
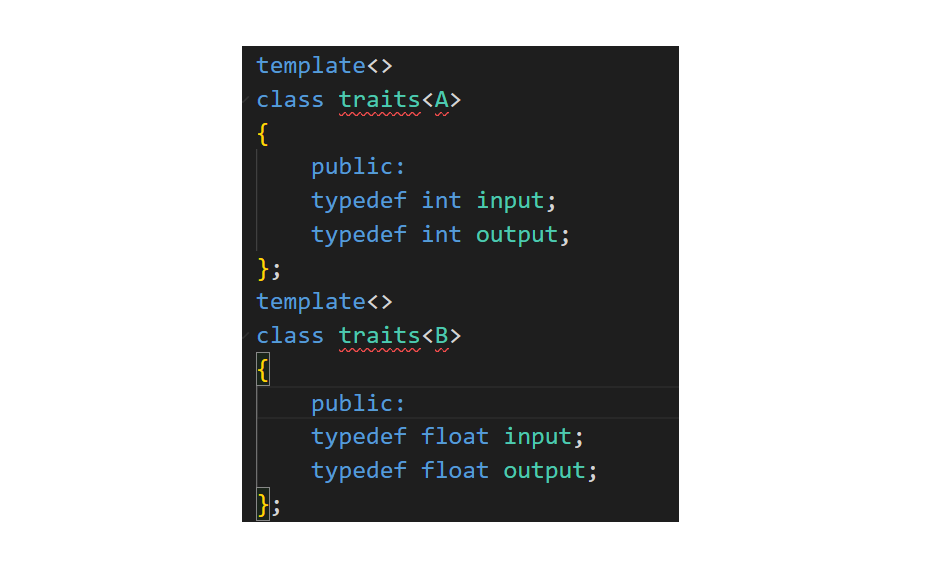
这俩个地方因为放的都是类型,所以就会疏忽,类内应该加上public(同样的道理发生在统一接口模板类上)

如果这个地方不写模板的话,下面的模板特化都是扯淡,模板特化的前提必须得是我们的类是模板类!
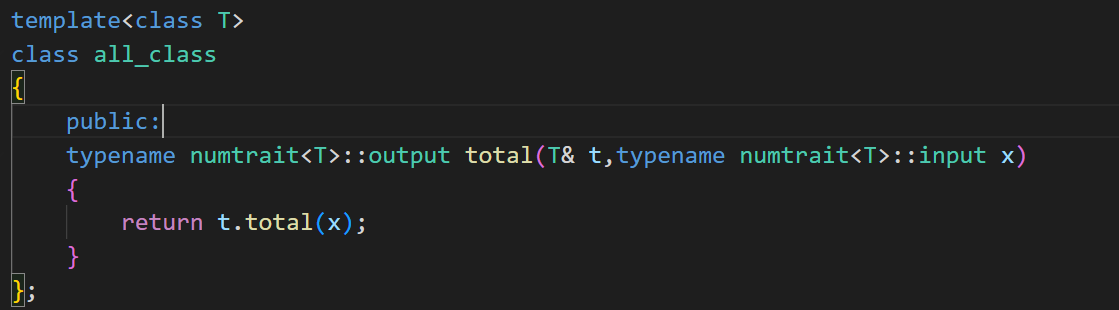
我们的统一模板调用类的一个参数,一定得是对象,只有这样才可以调用上面基类中的函数
第三章:迭代器
3.1迭代器类型介绍
- 输入迭代器(Input Iterator):只读,支持单遍扫描,不支持随机访问。
- 输出迭代器(Output Iterator):只写,支持单遍扫描,不支持随机访问。
- 前向迭代器(Forward Iterator):支持读写,支持多遍扫描,可用于单向链表等结构。
- 双向迭代器(Bidirectional Iterator):支持读写,支持多遍扫描,可用于双向链表等结构。
- 随机访问迭代器(Random Access Iterator):支持读写,支持多遍扫描,支持随机访问,可用于数组等结构。
3.2俩个常用的迭代器函数
advance(it,4)
对于我们的双向迭代器容器而言,必须使用这个函数来进行迭代器位置的跳转,如果初始值迭代器是begin的话,那么到达的位置是4+1=5,第5个位置 本质是it++ 执行四次
distance(v.begin(),it)
3.3反向输出迭代器的初始化方法
LISTINT::reverse_iterator rit=a.rbegin();
不只是单纯的将begin换成rbegin 还必须将iterator变成reverse_iterator
3.4rbegin rend
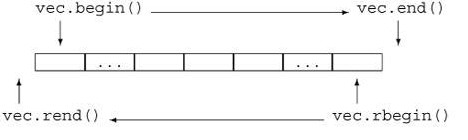
第四章:输入输出流
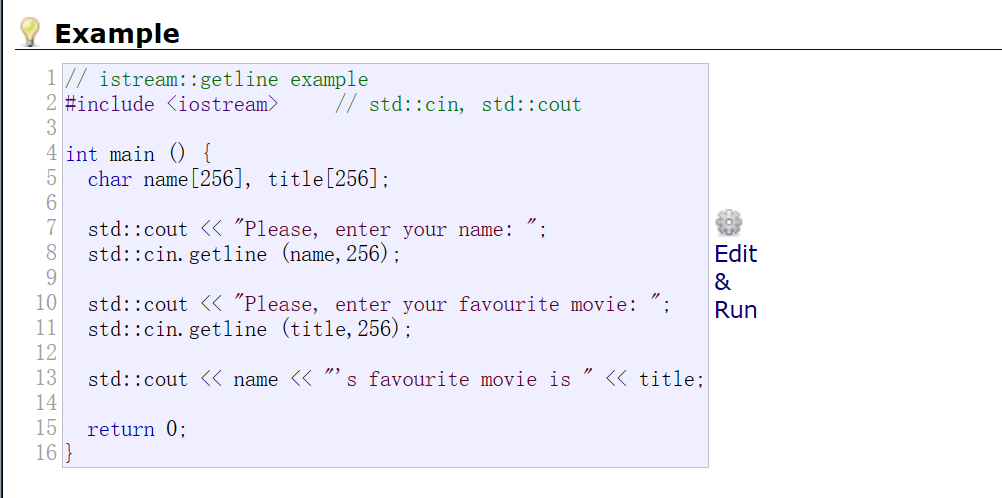
4.1get与getline的相爱相杀

#include <iostream>
int main (){
char arr[10];
std::cin.get(arr, 9, ';');
std::cout << "输入的字符串是: " << arr << std::endl;
char ch = getchar();
std::cout << "get input buffer: " << ch << std::endl;
char line[10];
std::cin.getline(line, 9, ';');
std::cout << "输入的字符串是: " << line << std::endl;
ch = getchar();
std::cout << "getline input buffer: " << ch << std::endl;
return 0;
}
这段代码可以看到get与getline最大的区别:前者把定界符留在缓冲区,然后给数组后面加斜杠0;一个把定界符转换成斜杠0
#include<bits/stdc++.h>
using namespace std;
int main (){
char arr[10];
std::cin.get(arr, 9, ';');
std::cout << "输入的字符串是: " << arr << std::endl;
//char ch = getchar();
//std::cout << "get input buffer: " << ch << std::endl;
char line[10];
std::cin.get(line, 9, ';');
std::cout << "输入的字符串是: " << line << std::endl;
char ch = getchar();
std::cout << "getline input buffer: " << ch << std::endl;
return 0;
}
这段代码就可以更加直观的看到,get把定界符留在缓冲区的弊端
cin.getline(buffer,100)与字符串getline差异

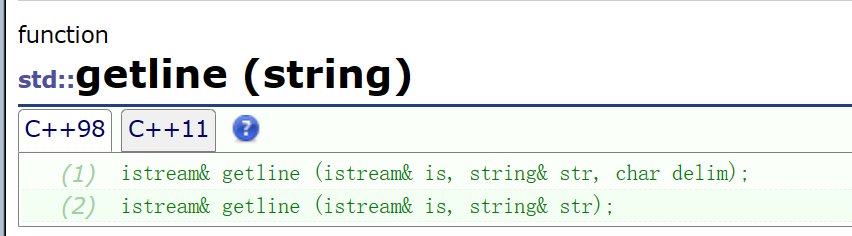
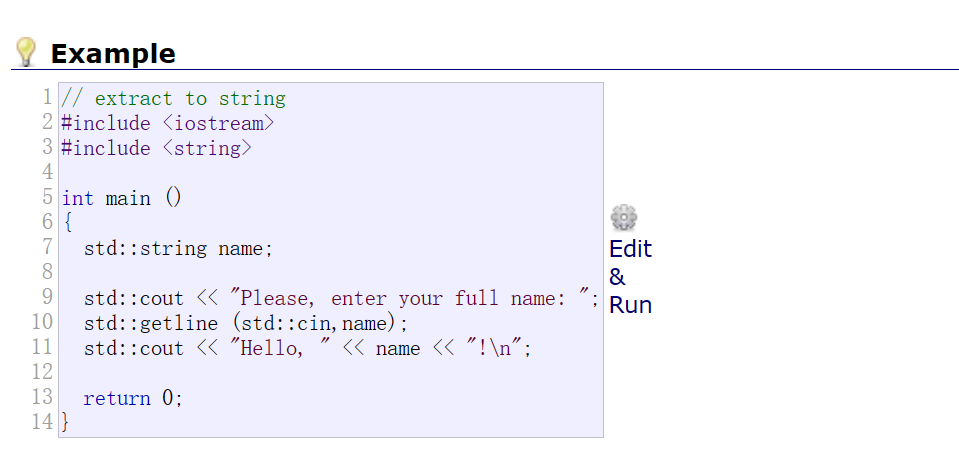
字符串的getline是:
getline(cin,buffer)即可
但是cin.getline(buffer,100);
起码得加上大小,否则一定会出错
这里还有一个特别注意的点:
ifstream in(“D:\vs code_code\my.txt”);
string name;
string text;
int a,b,c,d;
while(getline(cin,text))
{
? istringstream in(text);//字符串封装成字符串输入输出流对象
? in >> name >> a >> b >> c ;
? d=a+b+c;
? cout << name << " " << a << " " << b << " " << c << " " << d << endl;
}可以看出来哪里出问题了吗??
当我们使用getline的时候,得看清楚我们的输出输出流对象getline(in,text),比如这里getline的第一个参数是我们命名的文件名字in,但是我错误的写成了cin,这样就达不到我想要的效果了!
4.2rdstate
使用下面函数来检测相应输入输出状态:
- bool good(): 若返回值 true, 一切正常,没有错误发生。
- bool bad(): 发生了(或许是物理上的)致命性错误,流将不能继续使用。
- bool fail(): 若返回值 true,表明I/O 操作失败,主要原因是非法数据(例如读取数字时遇到字母)。但流可以继续使用。
- bool eof(): 若返回值 true, 表明已到达流的末尾。
要想重置以上成员函数所检查的状态标志,你可以使用成员函数clear(),没有参数。
4.3注意
一定要养成书写文件输入输出流代码的时候,关闭文件的习惯,这很重要!
第五章:字符串
5.1replace
replace(pos,len,str) 这个len 不是限制替换串的,而是限制被替换的串
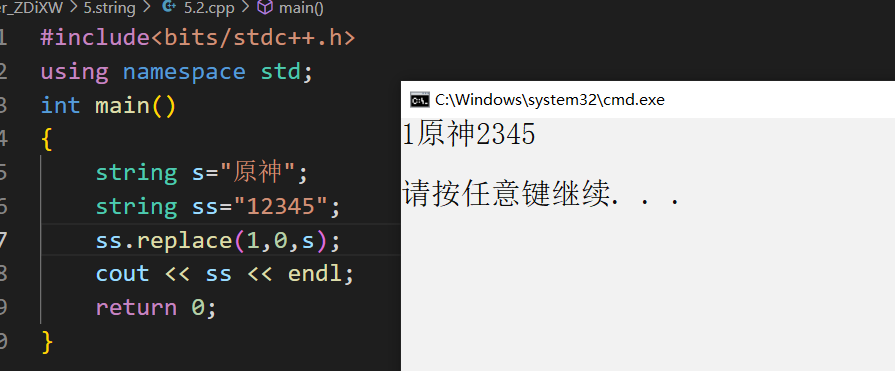
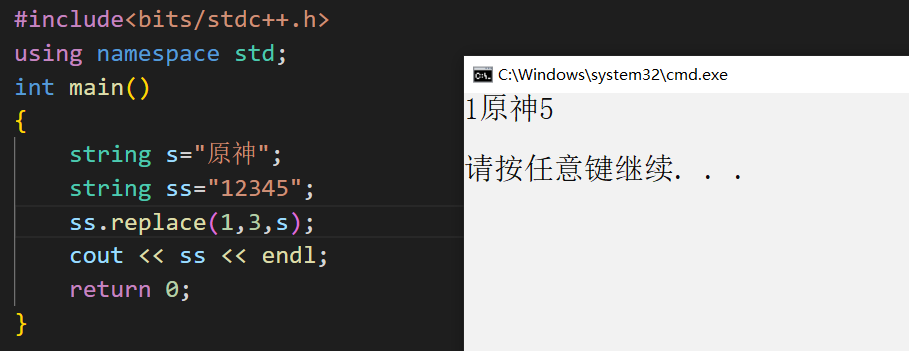
换句话讲,replace的第二个参数,代表删除几个字符;对于上面这种情况,没有删除字符,使得replace的效果与insert相同
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s="原神";
string ss="12345";
//ss.replace(1,0,s);
ss.insert(1,s);
cout << ss << endl;
return 0;
}
5.2字符串的各种find(用的时候记得字符串.)

void string_find_test()
{
//查询
string s="how are you";
string a="aaaaaaaab";
int n=s.find("are"); //返回值是下标,没查到返回-1 没有返回true或false
n=s.find("o",5); //从第五个元素开始往后找o这个元素 返回9
cout<<n<<endl;
n=s.find_first_of("abc"); //abc 找的是第一个遇到a、b、c其中任意一个字母的下标
cout<<n<<endl;
n=s.find_last_of("abc"); ///abc 找的是最后一个遇到a、b、c其中任意一个字母的下标
cout<<n<<endl;
n=s.find_first_not_of("abc"); //返回的下标是0 -->h-->第一个既不是a,也不是b,也不是c的字母
cout<<n<<endl;
n=s.find_last_not_of("abc"); //返回的下标是10 -->u-->最后一个既不是a,也不是b,也不是c的字母
cout<<n<<endl;
n=a.rfind("a"); //aaaaaaaa 从后往前找第一个a 就是下标为7的地方 如果是find的话,这里就是0
cout << n << endl;
n=a.find("a");
cout << n << endl; //rfind("a",a.size()-1); find("a",0);
}
n=s.find(“o”,5); //从第五个元素开始往后找o这个元素 这个参数还是比较少见的
5.3erase

- erase用迭代器删除:如果只有一个参数的话,那么无论是什么,都是只删除那一个元素
- erase用下标删除:如果只有一个参数的话,只保留下标,后面的全部删除(第二个参数默认传递npos)
5.4字符串类型转换的套路
先将类型各异的,不管是整形还是字符型,统统读入字符串输入输出流对象,接着定义最终需要被转换成的对象变量,用字符串输入输出流对象流向定义变量即可
- ss << 类型1
- ss >> 类型2
5.5高频考点之字符串拆分
T result;//接收变量任意类型接收
string text="1 2 3 4 5 2 2 1";
istringstream in(text);//只可以用拷贝构造
while(!in.eof())
{
in >> result;
//自由发挥
}
我们往往会现拥有一串string str=“1 2 3 7 8 9”;这样的字符串,但是我们想要其中的数据,我们并不关心空格符,这个时候,字符串拆分的重要性不言而喻
字符串拆分的本质,就是先创建出我们的类似于文件的对象in(俩种类型的构造方式不同),就拿空格字符串来举例:当我们的文件中已经写入好str的时候,我们想要得到每一个数字,写一个循环while(!in.eof()),代表当我们没有读取完的时候,将 in >> temp;这个时候最精彩的来了,>> 读数据的时候,默认把空格作为分隔符,导致遇到空格就停(拆),这个时候我们的temp就会获得字符串的一个字符,我们就可以对temp进行我们需要的操作了(eg:插入容器或者输出)

(1)当我们使用istringstream的时候(只可以拷贝构造,不可以流入流出)
由于我们的istringstream是字符串读,也就是说,这个类型只可以赋值给变量,而不支持写入
所以我们类型转换的时候,istringstream就像一个只读文件,in >> num的时候,遇到空格就不给num传值了,我们正好可以趁这个空隙,对num进行操作
(比如push_back)
(2)当我们使用stringstream的时候(支持拷贝构造,也支持流入流出)

(3)这里循环体也有俩种写法
while(in >> num)
{
?
}
while(!in.eof())
{
? in >> num;
}
(4)三个例子(前俩个思路基本一致,注意类型与格式)
void test_split_kongge()
{
int result;
string text="1 2 3 4 5 2 2 1";
map<int,int>m;
istringstream in(text);//只可以用拷贝构造
while(!in.eof())
{
in >> result;
//自由发挥
m[result]++;
}
cout << m[2] << endl;
}
void test_split_kongge()
{
string result;
string text="1 2 3 4 5 2 2 1";
map<string,int>m;
istringstream in(text);//只可以用拷贝构造
while(!in.eof())
{
in >> result;
//自由发挥
m[result]++;
}
cout << m["2"] << endl;
}
void test_split_douhao()
{
string result;
string text="How,Are,You";
vector<string>v;
istringstream in(text);//只可以进行拷贝构造
while(!in.eof())
{
getline(in,result,',');//读一行 自定义分隔符
v.push_back(result);
}
for(auto it:v)
{
cout << it << " " << endl;
}
}
第六章:函数对象?
第六章
为什么要用仿函数
函数适配器的优点
系统仿函数常见的有哪些要会写 sort(v.begin(),v.end(),greater());
自定义仿函数也要会写 sort(v.begin(),v.end(),comp());
一句话:函数对象:重载了()的类创建出来的对象通通称为函数对象 也被叫做仿函数
6.1函数对象的特点

6.2函数对象的分类

6.3一元函数


6.4二元函数

这个代码知识点实在是太庞大了
//#include <functional>
#include <algorithm>
#include <iostream>
#include<vector>
#include<iterator>
#include <string>
using namespace std;
/*
问题区域:
2.为什么二元函数要写成继承这个样子 有什么好处 答:为了保证一致性
4.为什么重载小于号就可以用
答案:
sort(v.begin(),v.end(),less<Student>());//原型是这样的
我本来是纠结,这个写法不是函数对象吗 查了less的文档之后 less居然是一个类,里面重载了operator()
template <class T> struct less : binary_function <T,T,bool>
{
bool operator() (const T& x, const T& y) const
{return x<y;}
};
所以我们的sort(v.begin(),v.end());虽然没有写第三个参数,但缺省值是less便会自己调用我们上面写的代码,由于我们重载了小于号 所以就可以达到我们的目的
7.模板特化的意义
模板特化说通俗一点 就是底层的东西我们改不了 所以我们模仿底层写了一个和底层一摸一样的再加上自己功能的类 不严谨的说,实则我们问题4的代码,就是调用了没有写here这段代码的less,道理是一样的
8.就是因为这里模板特化了解的太过深入,导致我以为模板特化就是trait技术 实则并不然 这里用模板特化也只是为了另一种展现形式而已 而且模板特化不可以调用
*/
/*
知识区域:
1.模板特化的时候 const不要丢失 只要用到less 那么我们重载的小于号必须上const
2.修改binary_sort类的定义,使用std::less作为基类而不是binary_function。这样可以避免名称冲突问题
*/
template<class T>
void show(T v)
{
typename T::iterator it=v.begin();
while(it!=v.end())
{
cout << *it << " ";
++it;
}cout << endl;
}
class Student
{
private:
string name;int grade;
public:
Student(string name, int grade)
:name(name)
,grade(grade)
{}
bool operator<(const Student& s) const
{
cout << "hehe" << endl;
return grade < s.grade;
}
friend ostream& operator <<(ostream& os, const Student& s);
};
ostream& operator <<(ostream& os, const Student& s)
{
os << s.name << " " << s.grade;
return os;
}//定义成全局 为什么是俩个参数?为什么不写成成员函数??
//1.成员函数:那么就是 对象+操作符:Student s1;s1<<cout;这样的可读性实在是太差了
//2.全局函数:可以写俩个参数,这样就可以避免语义
//3.上面的类对象写成public:完全就是因为运算符重载写成了全局函数,只有这样才可以用
//用sort的less库输出
void disp_sort(vector<Student> v)
{
cout << "用less自己重载小于号输出" << endl;
sort(v.begin(),v.end());//这个是不用函数对象的操作 为什么这么写可以呢 是因为less调用了我们写的小于
//所以说,这个缺省的代码的本质是sort(v.begin(),v.end(),less<Student>()) 就是这样的
show(v);
}
//用继承二元函数对象+copy的知识输出
template<class _inPara1, class _inPara2>
class binary_sort : public binary_function<_inPara1, _inPara2, bool>
{
public:
bool operator()(_inPara1 inl, _inPara2 in2) // Student& Student&
{
cout << "我在这里哦" << endl;//说明没有用类内的小于号
//荒谬 他妈的居然用到了我擦
return inl < in2;
}
};
void disp_function_obj(vector<Student> v)
{
//这个template后的类还不可以放在函数里面 嘿嘿 有学到了 所以我把它写在外面咧!
cout << "用函数对象的知识输出:" << endl;
//排序
sort(v.begin(),v.end(),binary_sort<const Student&,const Student&>());
copy(v.begin(),v.end(),ostream_iterator<Student>(cout,"\n"));
/*拷贝函数:把first和last拷贝到result(目标容器的起点)中在这个例子中就是:
vector的begin和end拷贝到 输出流的迭代器
输出迭代器:有俩个参数,第一个代表什么流 第二个代表分隔符
cout参数指的是标准输出流,不是文件流,也不是字符串流 " ":表示连续俩个输出的时候用空格来分隔 里面也可以换别的参数
细节:但是为什么cout就可以解决问题呢? 是因为上面重载了 << 所以我们copy这里才可以正确执行
而且别忘了和白老师讨论过的 const引用给普通引用赋值报错的问题 这会导致权限放大 也就是说
ostream& operator <<(ostream& os, const Student& s)
解决方案:1.要么const & 2.要么这俩个都不写
*/
}
// //利用模板特化输出
// template< >
// bool less<const Student&>::operator()(const Student& v1,const Student& v2) const
// {
// cout << "here" << endl;
// return v1<v2;
// }
template <class T>
struct Less : binary_function <T,T,bool>
{
bool operator() (const T& x, const T& y) const {return x < y ;}
};
template<>
struct Less<const Student&>
{
bool operator()(const Student& v1,const Student& v2) const
{
cout << "here" << endl;
return v1<v2;
}
};
void disp_moban_tehua(vector<Student>v)
{
sort(v.begin(),v.end(),Less<const Student&>());
for(auto it : v)
{
cout << it << endl;
}
}
// #include<iostream>
// #include<vector>
// using namespace std;
// class less
// {
// public:
// bool operator()(const int& a,const int& b) const
// {
// cout << "hehe" << endl;
// return (a<b);
// }
// };
// int main()
// {
// vector<int>v={1,5,8,9,4};
// //sort(v.begin(),v.end());
// return 0;
// }
void copy_test()
{
//我写成模板特化的话,我觉得就没必要用类里面的小于号了
//写成模板特化 那么主函数得这么写:sort(v.begin(),v.end(),less<Student>());
//库函数扩展的时候,只需要扩展对应的操作符 less对应的操作符就是小于 所以就没用自己写的模板特化
//template<>使用特化 一致性就可以提高效率 这样用户就可以用less实现各种各样的功能 比如我想改成大于等等
}
int main()
{
Student s1("zhangsan",60);
Student s2("lisi",80);
Student s3("wangwu",70);
Student s4("zhaoliu", 90);
vector<Student> v;
v.push_back(s1);
v.push_back(s2);
v.push_back(s3);
v.push_back(s4);
//disp_sort(v);
disp_function_obj(v);
//disp_trait(v);
return 0;
}
当我们使用二元函数less 和 greater的时候 重载对应的运算符就应该加上const
但是需要强调的是:operator< 后面加const 是因为调用了less二元函数 二元函数内部都是const对象
greater less
这俩个函数是二元的,需要注意的知识点有
- 当我们需要用这俩个求 >60的学生人数的时候,必须用绑定函数适配器才可以
- 当我们使用这俩个系统仿函数的时候,类内重载的时候,后面必须加上const: bool operator<(stu s) const
- set、map、priority_queue只要这三个容器一些出来,就代表着使用系统仿函数less,类内该重载的时候一定得重载
6.5系统函数对象(前 操作 后)
对于非常规数据类型必须重载类中对应的operator运算符
当我们使用系统函数对象,需要类内进行运算符重载的时候,系统仿函数是const,所以成员函数必须写成const成员函数
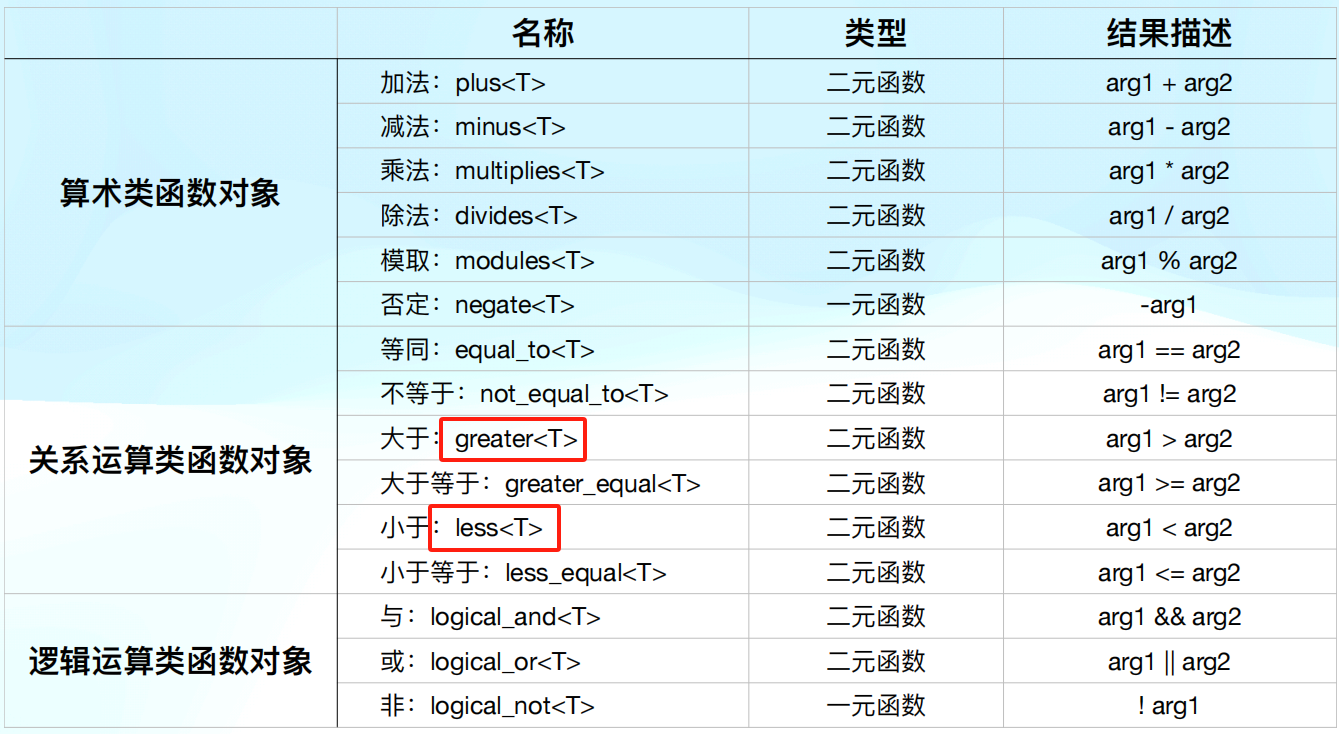
二元仿函数都是拥有三个参数的,俩个输入,一个输出,但是三个参数都是一个类型,所以显式实例化传递一个值
template <class T> struct plus : binary_function <T,T,T> {
T operator() (const T& x, const T& y) const {return x+y;}
};
plus<int> pobj;
cout<<pobj(5,6)<<endl; //此处的小括号是重载的小括号,此处的pobj(5,6)是函数对象,不是函数名称
cout<<plus<int>() (5,6)<<endl; //无名对象的方式
(5,6)这个括号里面的内容表示的都是一样的 表明运用到了重载
6.6函数适配器
定义:仿函数适配器可以在不改变原有仿函数代码的情况下,为其添加新的行为或修改其行为。它通过包装(wrapping)原有的仿函数,并提供新的接口来实现这一目的。
问题引入:我们想找到数组元素中,元素大于10的元素数量
初步想法:cout << count_if(a,a+sizeof(a)/sizeof(int),greater());
改变想法:cout << count_if(a,a+sizeof(a)/sizeof(int),bind2nd(greater(),10); 绑定第二个参数
1.绑定bind1st bind2nd(二元变一元)
//bind1st(函数):绑定第一个参数
//bind2nd(函数):绑定第二个参数
class comp1:public binary_function<int,int,bool>
{
//仿函数适配器 需要继承父类 模仿greater less
public:
bool operator()(int x,int y) const
{
return x>=y;
}
};
//一元仿函数
class comp2:public unary_function<int,bool>
{
public:
bool operator()(int x) const
{
return x>=7;
}
};
void test1()
{
int a[]={1,2,3,4,5,6,7};
vector<int> v(a,a+7);
int num;
num=count_if(v.begin(),v.end(),bind2nd(greater<int>(),6));//绑定第二个参数 绑定参数y为6 找大于6的数
cout << num << endl;
num=count_if(v.begin(),v.end(),bind1st(less<int>(),6));//绑定第一个参数 6<y 和上面的效果是一样的!
cout << num << endl;
//自定义的二元函数
num=count_if(v.begin(),v.end(),bind1st(comp1(),7));// 7 >= y 则为小于等于7的值
cout << num << endl;
//自定义的一元函数
num=count_if(v.begin(),v.end(),comp2());
cout << num << endl;
}
2.取反not1 not2(1、2代表的是几元取反)
count_if(v.begin() ,v.end() ,not1(bind1st(greater<int>(),7))); //找>=7有几个
sort(v.begin(),v.end(),not2(less<int>()));//>=
3.成员函数mem_fun(多态必须封装指针) 和 mem_fun_ref
第一个是封装指针的 第二个直接封装对象
void test()
{
stu s1("zhang",20),s2("lisi",30);
vector<stu> v;
v.push_back(s1);v.push_back(s2);
//mem_fun_ref
for_each(v.begin(),v.end(),mem_fun_ref(&stu::show));//这个成员函数必须加上类名限定域
//v[i].show--->成员函数
//mem_fun
vector<stu*>p;//注意这里面是指针
p.push_back(&s1);p.push_back(&s2);
for_each(p.begin(),p.end(),mem_fun(&stu::show));
}
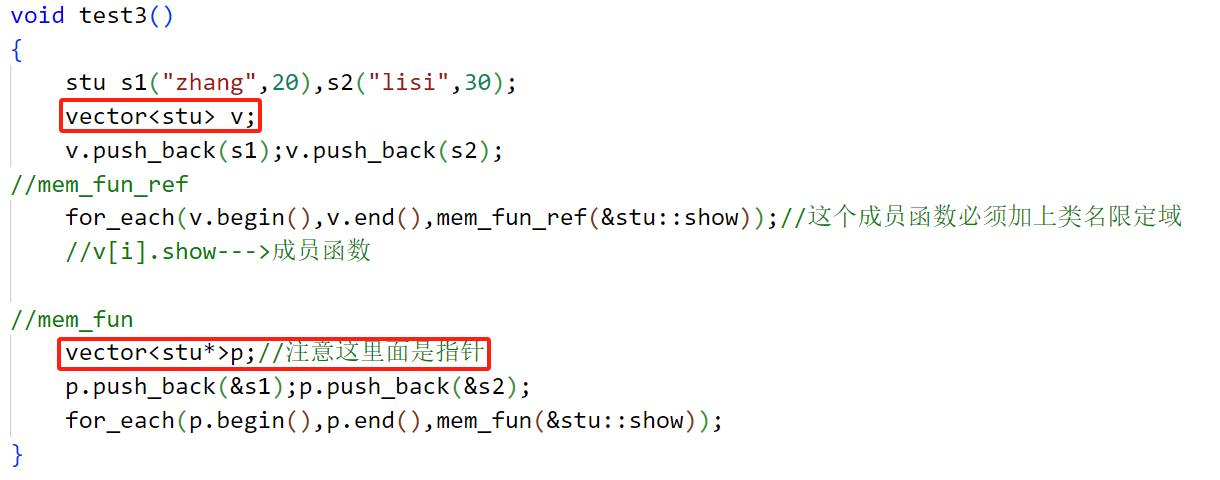
细节:
1.我们的mem_fun后面得加上地址符号&
2.我们的mem_fun本质上就是函数 mem_fun(&stu::show),这里show就不要再加括号了,这里的意思是函数名当作函数指针来做另一个函数的参数

一定要小心这里没有括号,否则是无法通过编译的!!!
利用多态+mem_fun
#include<iostream>
#include<vector>
#include<algorithm>
#include<functional>//函数对象必须要有这个
using namespace std;
/*
知识区域:因为我们需要实现多态,需要的就是继承+虚函数+指针,那么我们的vector就保存Book*类型的数据
这样我们插入后,利用for_each( , , &Shape::area) 就可以满足要求
*/
//求不同图形的面积 -- 多态的形式来实现(继承虚函数+指针)
class Shape
{
public:
virtual void area() //就是为了给子类继承用的 我们不知道子类具体是什么 搭建一个框架就好了
{
cout << "hehe" << endl;
}
};
class Rect:public Shape
{
int with;
int high;
public:
Rect(int w,int h)
{
with=w;high=h;
}
void area()
{
cout << with*high << endl;//面积就是宽乘以高
}
};
class Circle:public Shape
{
private:
int r;
public:
Circle(int sr)
{
r=sr;
}
void area()
{
cout << r*3.14*3.14 << endl;
}
};
/*问题引入:每次定义一个图形 都得定义一个对象 太麻烦了 这个时候我们搞一个容器*/
int main()
{
Rect rt(5,6);
Circle cl(2);
vector<Shape*>v;
v.push_back(&rt);
v.push_back(&cl);//代替下面那一坨
// Shape *s;
// v[0]=&rt;//子类的地址赋给父类指针 就是多态
// v[0]->area();
// v[1]=&cl;
// v[1]->area();
for_each(v.begin(),v.end(),mem_fun(&Shape::area));
//area是成员函数 所以我们用成员函数适配器 如果容器里面的类型是指针 那么就用指针 反之 则用mem_fun_ref
return 0;
}
4.普通函数ptr_fun
我们的函数本身是可以做算法的第三个参数的,但是如果我们写的普通函数被绑定了,那么就得用到ptr_fun
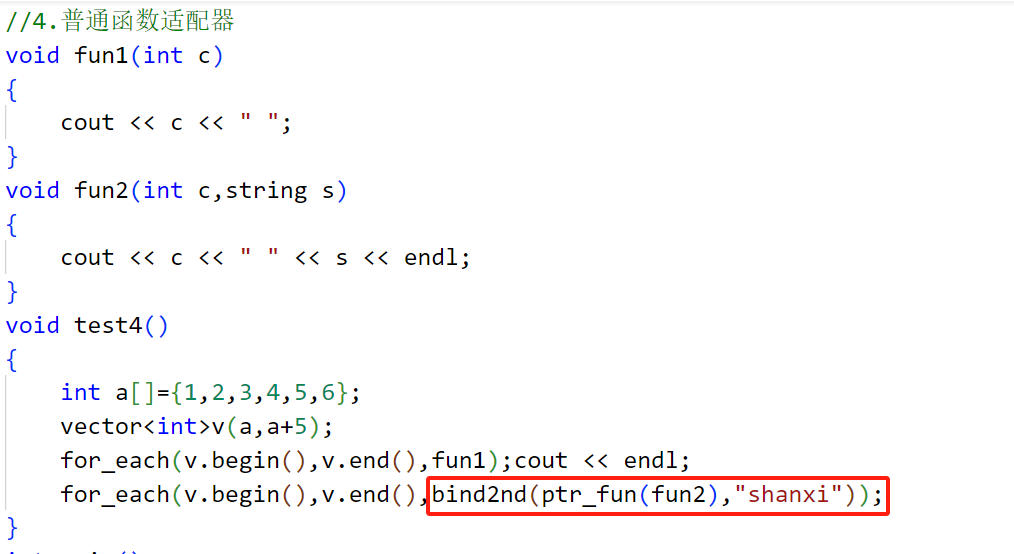
6.7总结:各个操作分别需要重载什么,已经包含几个参数,以及返回值
sort(< 俩种情况 bool)
情况一:如果是写函数对象的话,必须是俩个参数
bool operator()(Book& a,Book& b)
{
return a.getname() < b.getname();
}
情况二:如果是写类内的话,一个参数即可
bool operator<(const Student& s) const
{
? return grade < s.grade;
}
find_if(不需要 一个参数 bool)
find(unique也是一样的)需要重载 == 号,但是一定要小心:重载 == 号的时候 一定得小心观察清楚哪个是需要判断的关键
find_if不需要重载==号 函数对象是单参数
bool operator()(person p)
{
? return p.get() > low && p.get() < up;
}
根据需求是什么意思? 比如我这里用到了大于和小于 那么我就必须在我的Person类中重载我的这俩个运算符,因为它得符合我们自己构造的函数对象的需求
count_if(不需要 一个参数 bool)
原型:
count_if (T1 first, T1 last, T2 pred)
{
? typename iterator_traits::difference_type ret = 0;
? while (first!=last)
? {
? if (pred(*first))
? {
? ++ret;//这个是什么意思
? }
? ++first;
? }
? return ret;
count必须重载 == 双等号
bool operator()(tea t)
{
? //return t.getage() < 25;
? return t.getage() < up && t.getage() > down ;
}
for_each(不需要 一个参数 void)
less(1.重载小于号 2.重载后面加const)
为什么一用less的时候,重载小于号的参数类型都是自定义类型呢?
答:
template<typename _Tp>
struct less : public binary_function<_Tp, _Tp, bool>
{
bool
operator()(const _Tp& __x, const _Tp& __y) const
{ return __x < __y; }
};
可以看到less内部调用了函数对象,也就是说,当我们使用自定义函数适配器的时候,实则还是在使用函数对象来进行操作,那么函数对象需要什么参数,应该不用我多说了吧~(看邸老师帮我解决大问题)
bool operator < (stu s) const
//邸老师:对象是可以进行隐式类型转换的 但是函数不可以(只可以人为后面加const)
//我们把函数后面加上const理解成const成员函数 而不要单纯的理解为封装函数的第一个参数 是整个函数都变成了const函数
//const对象(在less中把它变成了const)不可以访问普通函数 常对象只能访问常函数
//而在我们的less底层中 我们的Stu s隐式类型转换变成了const对象 为了避免权限放大 我们的函数必须是const函数
{
if (sum < s.sum) return true;
if (sum == s.sum && chinese < s.chinese) return true;
return false;
}
find count unique
这三个针对?定义类需要重载 == 符号
bool operator==(int NO)
{
? return this->NO==NO;
}
??一个突然感悟到的小套路
我们写find函数的时候,往往需要重载==,判断数值是否相等;
重载< 和 > 的时候,一定是为了排序,那么排序针对的就是对象,就是自定义类型
所以类内重载==的时候,一般参数都是数值;但是重载 < 与 > 的时候,往往参数都是自定义类型
??类重载运算符与函数对象关于数字的问题
当我们写类重载的时候,函数体内一定不要出现数字,比如查询成绩等于80的同学,我们需要书写==的时候
bool operator==(int x)
{
? return 类内成绩元素==x;
}
不要写成 return x == 80 或者是 类内成绩元素 == 80 这样都是不妥的
(左边的也可以达到效果,但是不合适)
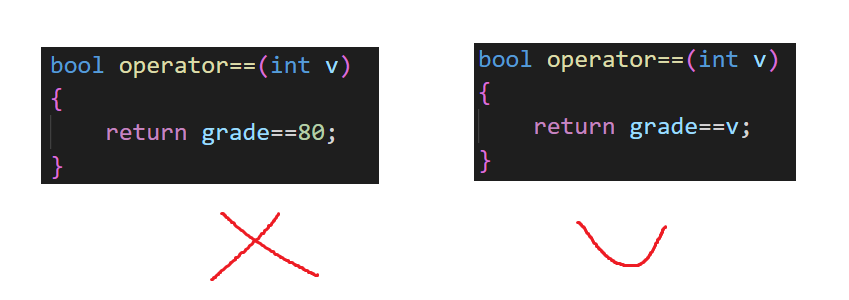
当我们写函数对象的时候,函数体内是可以出现数字的,因为我们函数对象传参有时候参数为类类型,那么我们需要的正是一个比较规则,来告诉算法如何比较的,所以无论是左边还是右边的写法,都是可以的,具体看题目要求如何,但右边当然略胜一筹

重载操作符时,一定是有自定义类型参与,包括==操作符。你的概括需要改正。函数运算符的总结是正确的,就是为了提高其的灵活性。
我懂邸老师的意思:邸老师的意思就是,我们需要写==的时候,一定是因为有自定义类型的出现与存在我们才需要写,这个点也是必须要狠狠get到!!
6.8白老师强调的俩个排序三个输出
//可能让你这个自定义的仿函数 也可能让你写系统仿函数里面的构造
#include<bits/stdc++.h>
using namespace std;
//案例 :排序 :sno大到小
class stu
{
int sno;
string name;
public:
stu(int s,string n)
{
sno=s;
name=n;
}
bool operator>(stu s)const//复用less greater必须加
{
return sno > s.sno;
}
int get()
{
return sno;
}
void disp()
{
cout << sno << " " << name << " ";
}
friend ostream& operator<<(ostream& out,stu s);
};
ostream& operator<<(ostream& out,stu s)
{
out << s.sno << " " << s.name << " ";
return out;
}
//自定义仿函数
class comp
{
public:
bool operator()(stu s1,stu s2)
{
return s1.get() > s2.get();
}
};
class output
{
public:
void operator()(stu s)
{
s.disp();
}
};
//**********************************************************************************************************************
//!!!!!!!!!!!!以下两种排序方法考试都会考到(都要掌握) 调用系统的 和自动的都有可能会考到
int main()
{
stu s1(1002,"zhang");
stu s2(1001,"lisi");
stu s3(1008,"wang");
vector<stu>v;
v.push_back(s1);
v.push_back(s2);
v.push_back(s3);
//排序1--系统仿函数
sort(v.begin(),v.end(),greater<stu>());//stu1>stu2
//greater是个类,greater<stu>是类型, greater<stu>()是个对象
//排序2--自定义仿函数
sort(v.begin(),v.end(),comp());
//遍历输出1--迭代器
vector<stu>::iterator it=v.begin();
for(;it!=v.end();++it)
{
cout << *it ;
}cout << endl;
//遍历输出2--for_each
for_each(v.begin(),v.end(),output());
cout<<endl;
//遍历输出3--copy+ostream_iterator
copy(v.begin(),v.end(),ostream_iterator<stu>(cout));
return 0;
}
??邸老师帮我解决大问题之operator()参数的问题
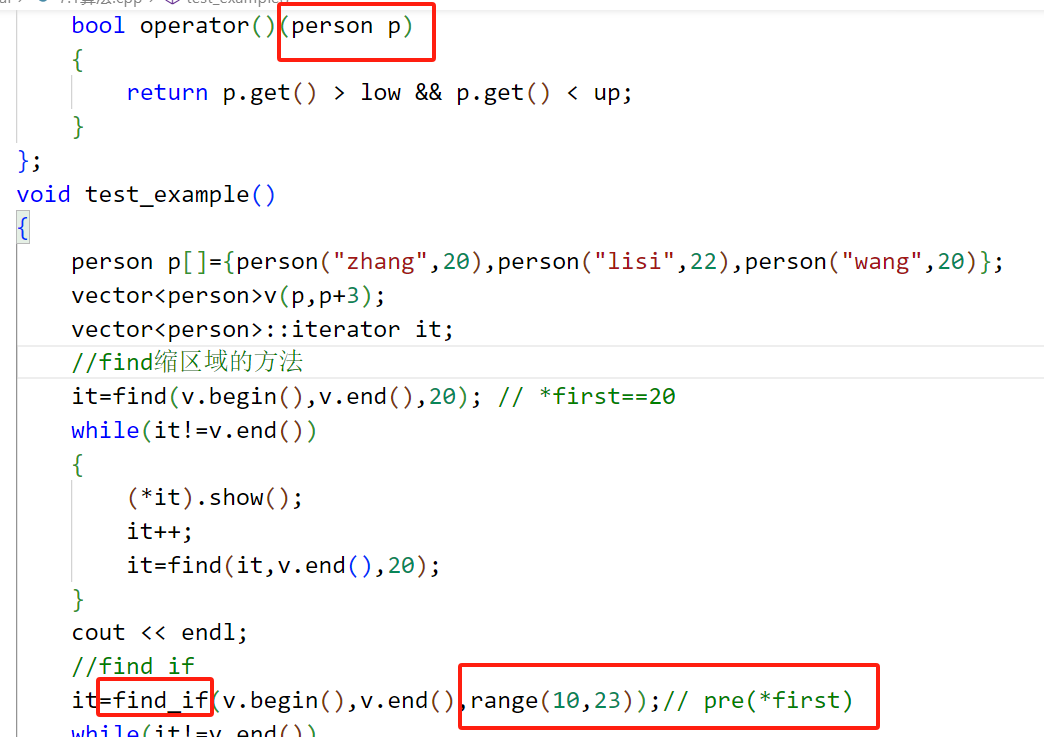
比如这里,我们想使用函数对象来完成操作,但是对我而言,函数对象的operator()传参一直是我的一个心病
邸老师:函数对象里面的参数实则用的就是容器里的元素,所以容器里面是什么类型,参数就是什么类型!!!
关于operator()(int a)书写容易错的地方
当我们的函数对象需要用到for_each算法中的时候,千万不可以写返回类型,必须写成void!这个白老师也强调过
但是也只限于for_each是void类型 sort 的返回值是bool count_if的函数对象返回值也是bool (当然话不能说的这么绝对,具体问题还是得具体分析,但是可以保证的是for_each调用的函数对象返回值一定是void)
第七章:容器
7.1容器概述
- 序列容器:
- vector:支持随机访问迭代器(Random Access Iterator)。
- deque:支持随机访问迭代器(Random Access Iterator)。
- list:支持双向迭代器(Bidirectional Iterator)。
- forward_list:支持前向迭代器(Forward Iterator)。
- 关联容器:
- set:支持双向迭代器(Bidirectional Iterator)。
- multiset:支持双向迭代器(Bidirectional Iterator)。
- map:支持双向迭代器(Bidirectional Iterator)。
- multimap:支持双向迭代器(Bidirectional Iterator)。
- 容器适配器:
- stack:不提供迭代器。
- queue:不提供迭代器。
- priority_queue:不提供迭代器。
- 无序关联容器:
- unordered_set:不提供迭代器。
- unordered_multiset:不提供迭代器。
- unordered_map:不提供迭代器。
- unordered_multimap:不提供迭代器。
各个容器可能的用途
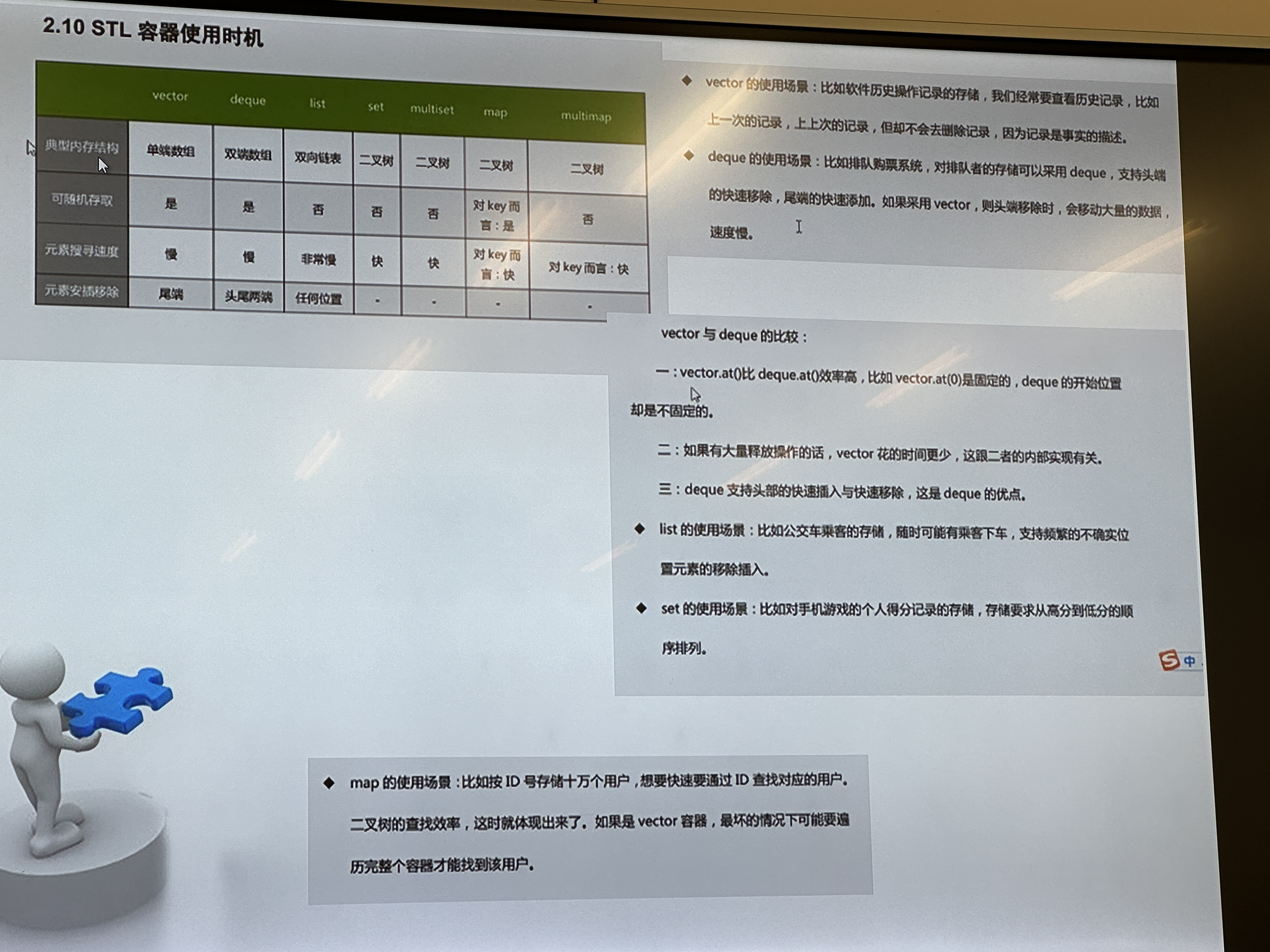
vector:软件历史操作的存储,比如查看历史记录等(这个过程中,删除记录的情况很少,刚好符合)
deque:对排队系统头部尾部的快速添加可以用deque,购票系统
list:公交车乘客的存储,随时都有可能乘客下车,用于频繁的不确定位置的插入删除
set:对于手机游戏的个人得分记录的存储,存储要求按照低序或者高序排序
map:每个用户都有自己的身份证号,想要快速通过身份证号码来查找这个人是谁,就得用map

优先级队列的使用场景:
(甚至也有堆排序)
操作系统的cache


bitset在课本中的例子是用于考勤系统!
公共容器的错误
输出迭代器的begin元素
set s(a,a+6);
cout << *(s.begin());
关于insert
vector deque list 的insert都是后面跟上位置,再加上val 换句话讲 序列性容器的insert最少是俩个参数
对于stack来说
对于queue来说
但对于set来说,虽然insert也有俩个参数的,但是并没有意义,最终还是会排序,所以直接插入一个参数val是最常用的
对于map来说,插入都是用make_pair来进行插入,返回值是pair<iterator,bool>
关于+/-/++/–迭代器
set没有+/-迭代器
list没有+/-迭代器
map没有+/-迭代器
vector是随机迭代器,list、map、multimap、set、multiset都是双向迭代器
7.2vector
vector的构造函数是花样最多的
insert插入接口较多

迭代器失效
插入时迭代器失效:vector插入的时候,如果满了,那么异地扩容就会迭代器失效
删除时迭代器失效:vector删除一个元素,其余元素会前移,这就导致迭代器位置如果不更新,就不会指向原来我们想指向的元素
7.3deque
deque可以使用push_front 插入元素 也可以使用 pop_front 来直接删除容器头结点 这一点是vector不具备的

但是deque也没有capacity 无法查看空间配置的容量大小

核心问题在于:vector扩容会引起原先的空间被删除,从而造成的迭代器失效问题;但是deque一旦写好,内存元素的地址不会改变
7.4list
相对于 vector 的连续线性空间,list 是一个双向链表,它有一个重要性质:插入操作和删除操作都不会造成原有的 list 代器失效每插入或删除一个元素就配置或释放一个元素空间。也就是说,对于任何位置的元素插入或删除,list 永远是常数时间
双向链表、链式存储、双向迭代器(只支持++/–,不支持+/-)
但是vector是没有push_front pop_front的!
list的接口相对于别的容器还是相当多的~


sort(里面可以存放排序规则)
v.sort(); 不可以调用库里面的sort函数
v.sort(comp_sort);排序规则必须是双参数的
==想要强调的是:==set 和 map内部也实现了sort函数 但是用法和算法库中的基本吻合 这里和list这里是截然不同的
我又回来了:放屁 set map并没有实现sort函数 他们俩实现的是find函数 红黑树搜索快 并不是排序快!
unique(删除k相邻元素有重复值的,所以必须得先排序才可以使用)
v2.unique(); //相邻且重复,所以要删掉重复值(前提是要相邻,故使用前要先排序)
merge(是移动,不是复制)
vb.merge(va); 必须是俩个有序的 merge之后 vb存放有序排序的俩个链表 va变成了空
splice(将整个链表/单个元素/一段范围 进行剪切+粘贴)
易错:参数里的链表名字是谁,谁被剪切走
list<int>ll={1,2,3,4,5};
list<int>kk={6,7,8,9,10};
//ll.splice(ll.begin(), kk); //挪走整个链表 6 7 8 9 10 1 2 3 4 5
//ll.splice(ll.begin(), ll ,kk.begin());//只是挪走一个元素 6 1 2 3 4 5
ll.splice(ll.begin(), ll, kk.begin(), kk.end()); //ll被剪切 粘贴给kk 6 7 8 9 10 1 2 3 4 5
show(ll);
splice
1.会在 position 后把 vb 所有的元素到剪接到 va 对象
2.只会把it的值剪接到 va 中
3.把 vb.begin() 到 vb.end() 剪接到 va 中
splice的函数原型:(整个链表/单个元素/一段范围)
1.entire list : void splice (iterator position, list& x);
2.single element : void splice (iterator position, list& x, iterator i); 这里书上写的是错的
3.element range : void splice (iterator position, list& x, iterator first, iterator last);
remove(删除所有是这个元素的值 不只删除一个)
remove根据元素值删元素,erase根据位置删除元素
list容器中的remove 成员函数,原型是void remove (const value_type& val);
他的作用是删除list中值与val相同的节点,释放该节点的资源。
而list容器中的erase成员函数,原型是iterator erase (iterator position);
作用是删除position位置的节点。这也是与remove不同的地方。
remove_if
v2.remove_if(comp); //将 v2 中满足某种条件的(预测类,先用普通函数代替),即为真,那就把它删掉!
remove_if每次只需要一个元素就行操作(判定),就像比较函数每次需要两个元素一样!
reverse(反转链表)
v.reverse();
易错:erase 删除的时候老是习惯性的给参数写成元素,应该是迭代器
7.5stack/queue

二者以及下面的优先级队列都是容器适配器
容器适配器:是对容器的再封装,不需要自己重新定义类,起到一个中介作用(队列不用vector,因为没有pop_front)


特别强调:==当我们书写关于stack和queue和priority_queue的模板输出函数的时候,函数参数一定不可以加引用。==因为这三个容器适配器输出的时候都会进行pop删除操作,加入引用的话会修改容器本身的值,使其输出完后变为空
//stack的模板输出
template<class T,class Container>
void show(stack<T,Container>obj) //模板输出不可以加引用!stack<T,Container>&obj是不对的
{
while(!obj.empty())
{
cout << ob.top() << " ";
obj.pop();
}
}
7.6priority_queue(和set map一样 有隐含货)
带优先权的队列 优先权高的元素优先出队
默认用的是less 也就是建立的是大根堆
与普通队列相比,都对对头进行删除操作,对队尾进行插入操作(没有front)
这也是一个适配器,默认的序列是vector!
本质是堆,也就是二叉树
默认构造:priority_queue<int, vector, less> p;
注意:当我们写了priority_queuepr(s,s+4);的时候,本质上其实写的是
priority_queue<,vector,less >pr(s,s+4);
所以就像set map一样,我们拥有隐含的less,所以一定得重载小于号,而且还得加上const

三个容器适配器的异同
相同点:都是容器适配器;他们三个返回元素 都是返回元素的引用;写输出函数的时候,参数都不可以加引用;

不同点:三个函数的模板输出函数不同,俩个deque,一个vector;queue不可以用vector做适配器;优先级队列/stack用top取元素,queue队列用front取元素;
7.7bitset
定义:二进制位的容器,并提供了位的相关操作函数


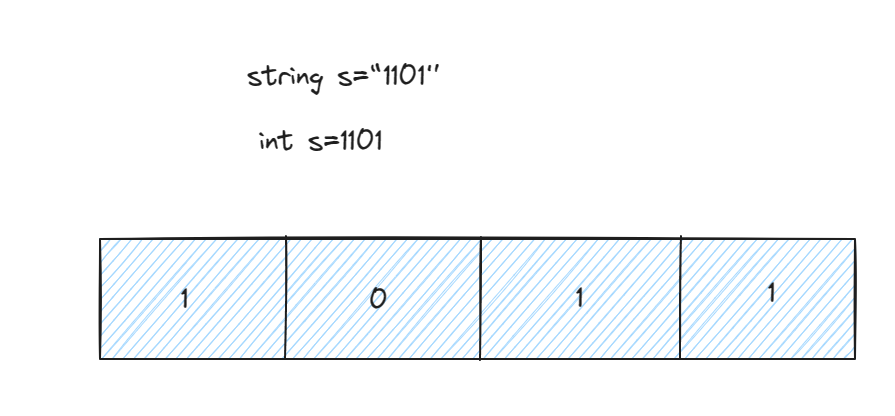
数字和字符串对于bitset有什么区别
- 如果发生了截断,那么数字是从右往左,比如1101存放在容量大小为2的容器,那么就是01(从右边找俩个)(注:不是10,是01)
- 如果发生了截断,字符串是从左往右,比如"1101"存放容量大小为2的容器,那么就是11(从左边找俩个)
- 如果没发生截断,那么就是一视同仁的
- 邸老师精辟总结:这是惯例,整数的最低位在右侧,字符串的最低位在左侧。它们都按位赋给bitset。而其并无左右之分,只有地址之分。

void test1()
{
// 10010 -- 18
bitset<10>a(18);
cout << a.to_string() << endl;
bitset<10>b("10010");
cout << b.to_string();
}
void test2()
{
bitset<5>a(18);
cout << a.to_string() << endl;
bitset<5>b("10010");
cout << b.to_string();
}
void test3()
{
bitset<3>a(18);
cout << a.to_string() << endl;
bitset<3>b("10010");
cout << b.to_string();
}
注:即使截断发生了,我们的bitset[0]、bitset[1],依旧是从右往左访问,这一点是不会变的,只是构造的时候有差异
白老师解答:对于容器外面的数据都是一视同仁的,只是放入容器的时候是反着来的,这个一定要记清楚了!
这里可以理解成这样存,可以理解成bitset<4>a(s); a[1]是从右往左第二个数 这样的俩种理解方式都可以的
bitset容器和[]的相爱相杀
- [] 不管是赋值 还是输出 只要使用方括号运算符 都是从右往左
- set将位进行赋值的时候,也是从右往左
- flip也是如此
7.8set(本身自带排序,不允许重复值)
定义:set和multiset都是集合类,区别在于前者不可以有重复元素,但是后者允许拥有重复元素
必须记住的小细节:
set是关联式容器 之前一直在纠结key和value的事情 但是关联的本意是关联排序方式 我们的set、map的关联方式正是less!
sets;
Stu被保护起来了,使得里面的私有变量都变成了const类型的
stu类里面的对象将全部变成const类型的,这导致的结构就是,类内成员函数后面必须加const 与之类似的还有less(),这也会导致tea变成const类型的,尤其是重载小于号的时候,必须加上const
但是需要强调的是:operator< 后面加const 是因为调用了less二元函数 二元函数内部都是const对象
对于set和map(还有priority_queue)来说,他们俩个只要一用,就有隐含的less,所以我们写代码的时候,一定要注意如果里面封装的是自定义类型,必须重载<,而且还得加上const,因为自定义类型变成了const,他们之间的比较也是const的
关于lower_bound
set的本质是树,但为了观察方便,这里处理成数组
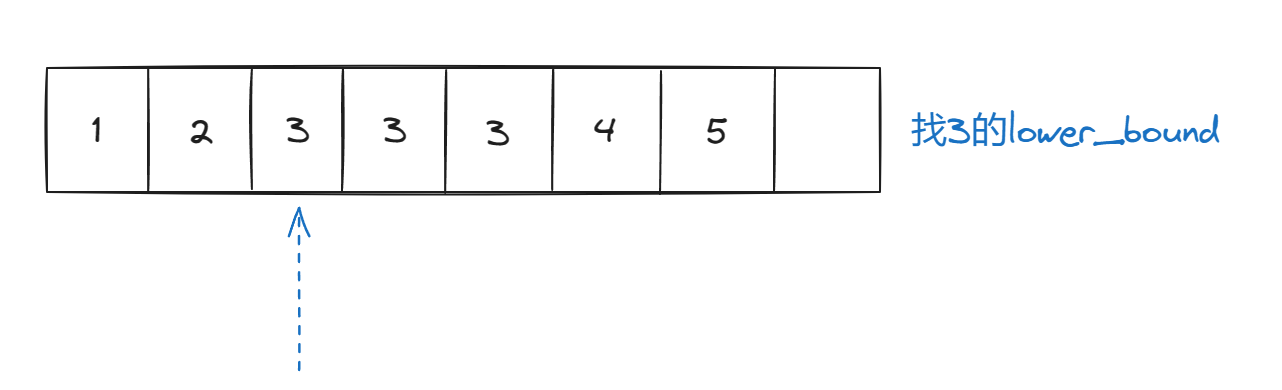
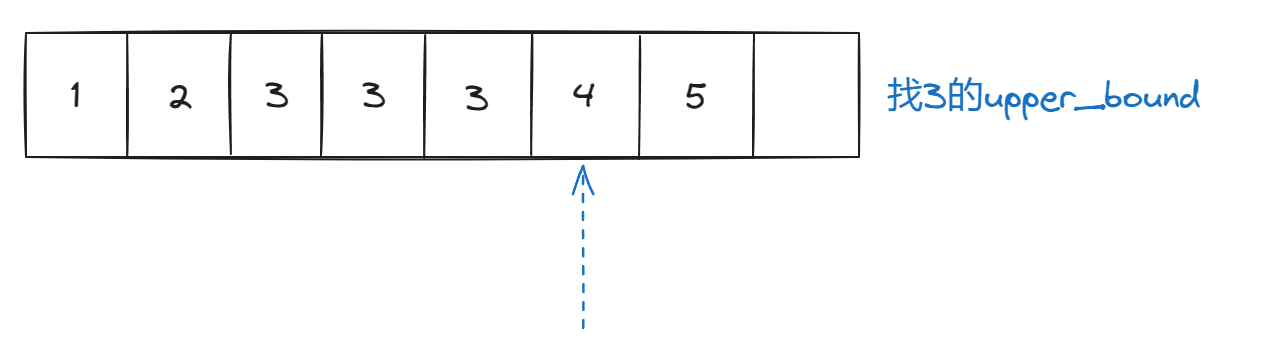
我老是忘了写 谁调用的 sets; s.lower_bound(3); 这样才可以
代码验证:
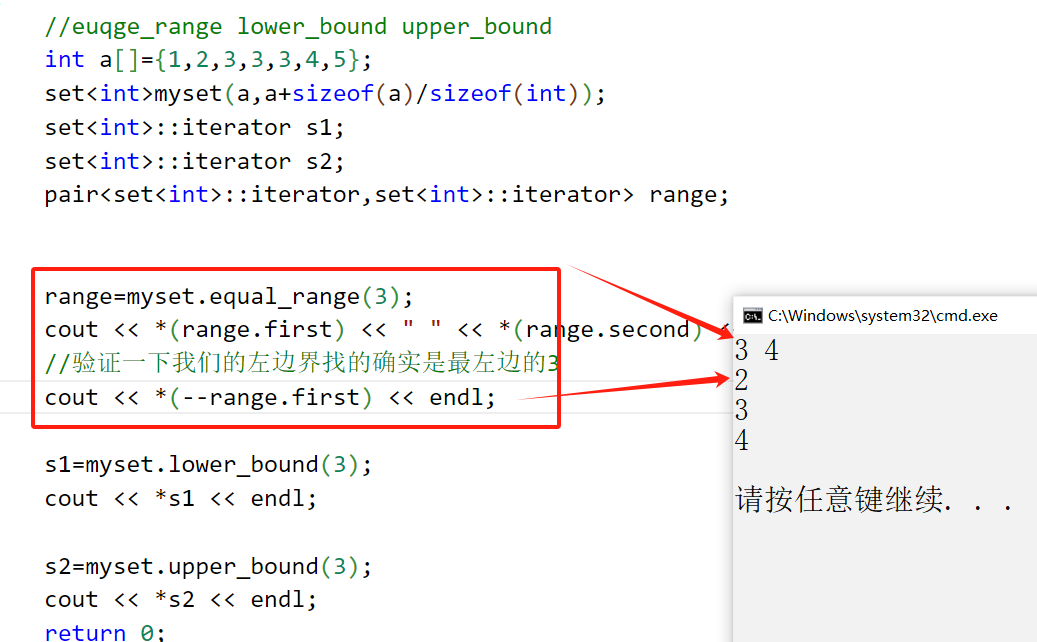
#include<iostream>
#include<set>
using namespace std;
/*
邸老师说:
1.lower_bound是去找边界,左边界;upper_bound的本质是去找右边界
2.利用equal_range就可以代替这俩个功能,直接找到这个元素的左边界和右开边界
*/
int main()
{
//euqge_range lower_bound upper_bound
int a[]={1,2,3,3,3,4,5};
set<int>myset(a,a+sizeof(a)/sizeof(int));
set<int>::iterator s1;
set<int>::iterator s2;
pair<set<int>::iterator,set<int>::iterator> range;
range=myset.equal_range(3);
cout << *(range.first) << " " << *(range.second) << endl;
//验证一下我们的左边界找的确实是最左边的3
cout << *(--range.first) << endl;
s1=myset.lower_bound(3);
cout << *s1 << endl;
s2=myset.upper_bound(3);
cout << *s2 << endl;
return 0;
}
set的insert(set没有push_back)

尤其是第一个插入方法,是set一绝,所以必须搞得清清楚楚

对于vector list 他们的erase都是这样的:
erase(iterator it);
erase(iterator first,iterator last);
也就是说如果想要具体删除某个元素的话,必须借助find函数
但是对于set 除了上面俩个erase的写法 还有第三个写法:
erase(const key& key) 删除元素值等于key的元素 set的key和value相同,其实也就是参数里放什么数字,删谁
也就是说,set的插入往往不借助迭代器,而是直接操作key的大小(也就是value的大小)
小插曲(这不纯纯坑人鸭 这个都根本用不了随机迭代器 怎么用sort? 是我太肤浅了!!!!!!还得是我邸哥)

心得:
- void disp() const 是因为set将thing元素封装了 所以必须加上const
- bool operator<(thing t) const //这个是针对less的 并不是针对元素 set写出来默认就是用的less!!
#include<list>
#include<string>
#include<iostream>
#include<algorithm>
#include<set>
using namespace std;
class thing
{
public:
thing(string xh="", string nm="", int op=0, int tot=0)
: xinhao(xh), name(nm), one_price(op), total(tot)
{
}
void disp() const
{
cout << "型号:" << xinhao << "名字:" << name << "单价:" << one_price << "总价:" << total << endl;
}
// .less中的函数参数都是const类型的,所以重载小于的时候一定得加上const
// operator()(const _Tp& __x, const _Tp& __y) const
// { return __x < __y; }
bool operator<(thing t) const //这个是针对less的
{
if(total==t.total)
{
return one_price > t.one_price; //调用的和传进来的 如果是降序 那么就要相反
}
else
{
return total > t.total;//因为是降序 所以相反的
}
}
private:
string xinhao;
string name;
int one_price;
int total;
};
class thing_mange
{
public:
void add(const thing& t)
{
s.insert(t);
}
void show()
{
//s.sort();
set<thing>::iterator it=s.begin();
for(;it!=s.end();++it)
{
(*it).disp();
cout << endl;
}
}
private:
set<thing>s;
};
int main()
{
thing t1("001","鼠标",5,200);
thing t2("002","电脑",50,200);
thing t3("003","键盘",10,300);
thing_mange m;
m.add(t1);
m.add(t2);
m.add(t3);
m.show();
return 0;
}
/// 不要忘了 set本身就可以排序!!
multiset(没有push_back)
里面可以存放多个key 可以有重复值
7.9map
定义:在前述的各个容器中,仅保存一样东西,但是映射中是不一样的!返回值是一对值<key,value>
map中,key和value是一对一的关系;multimap中,key与value是一对多的关系
map的构造
map模板化的时候必须有俩个类型,一个类型必定出错,而且第三个模板写greater的时候,greater里面的模板必须和第一个参数,也就是和key保持一致
map里面再也不可以放int类型的了 只可以放pair类型
小心[]的坑(底层看map set笔记)
cout << m[1] << endl;//非常逆天 我没有找到 反而被插入了 这个是非人为想法 但是被方括号悄悄插入了
map的输出
我们输出的时候,返回值是迭代器pair*类型的,所以我们得将迭代器先用 operator * 取出元素,再用.取出key和value
换句话理解:我们输出值的时候,对于迭代器都得先 *it ,所以这个规则在map也适用,接着我们再用.first .second就好了
map<T1,T2>::iterator it=m.begin();
while(it!=m.end())
{
? cout << (* it).first << " " << (* it).second << endl;
? it++;
}cout << endl;
对于比较复杂的情况:
pair<multimap <int,string>::iterator,multimap <int,string>::iterator > p;
p=m.equal_range(1); //返回值仍是pair,同时带回两个值
//p不是指针--->p.first;p.first是迭代器--->p是个pair,pair的pair--->(p.first)->first
//cout<<(p.first)->first<<" "<<(p.first)->second<<endl; //上界
cout << (*(p.first)).first << " " << (*(p.second)).second << endl;
cout<<(p.second)->first<<" "<<(p.second)->second<<endl; //下界
我们也要做到可以辨别的能力
map的常用案例分析
1.统计次数问题
//一个经典的期末考试题目
#include<iostream>
#include<map>
#include<string>
#include<sstream>
using namespace std;
int main()
{
string s="1 2 3 4 5 6 7 8 9 1 2 1 2 3 4 5 6 4 2 3 4";
//注意,这里一定是得有空格的,为了和之后的string stream对应
map<int,int>m;
stringstream is(s);//把字符串构造了is字符串流类对象
while(is.eof()!=true) //如果到了文件尾部 则自动返回true 如果没到 则返回false
{
int num;
//num << is;这样当然是不可以的因为num是int类型的 这样反着写是肯定不可以的!!int类型当流的左值 荒谬
// 写 = 出 >> ; 读 = 入 <<
is >> num ;//is的值流向num 此时num有1 因为后面有空格 无法接收更多的值
m[num]++;//小心 不是m[num++];!!!!!!!
//经典的统计数字的方法 如果没有就插入 如果有就将第二个值++ 而且还可以返回第二个值的大小
//V& operator(const key& k)
}
cout << m[2] << endl;
//(*((this->insert(make_pair(k,mapped_type()))).first)).second 返回的是数字2的统计次数
return 0;
}
#include<iostream>
#include<set>
#include<map>
using namespace std;
void test_map_total2()
{//统计水果出现的次数
string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果","苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
map<string, int> countMap;
//我们的期末考试是用了文件流的eof来做循环
for(size_t i=0; i < sizeof(arr)/sizeof(string); ++i)
{
countMap[arr[i]]++;//如果找不到就插入,找到就给第二个值++
}
//输出结果
map<string, int>::iterator it=countMap.begin();
while(it!=countMap.end())
{
cout << (*it).first << " " << (*it).second << endl;
it++;
}
}
int main()
{
test_map_total2();
}
2.公司雇员职业名字问题
注意:pair赋值的时候,千万不可以利用=赋值,只可以用括号拷贝
pair<string,Person>p1(“销售部”,Person(“张三”,22));👍
pair<string,Person>p1=(“销售部”,Person(“张三”,22));??
#include<iostream>
#include<map>
using namespace std;
//案例:员工信息:部门和个人信息 部门->key、个人信息->value 查找不同部门的员工信息
class Person
{
public:
Person(string n,int a)
{
name=n;
age=a;
}
void disp()
{
cout << name << " " << age << endl;
}
private:
string name;
int age;
};
class Mange//第一个作为部门-key ,第二个是每个部门的人员信息-value
{
public:
Mange(pair<string,Person>* first,pair<string,Person>* last)
:m(first,last)
{/*这个构造方法有点牛逼*/}
//方法一:利用conut和find得知人数和遍历次数
void select(string bumen)
{
int num=m.count(bumen);//拿到部门人数
multimap<string,Person>::iterator i=m.find(bumen);//找到部门的第一个人
for(int j=0;j<num;++j)
{
cout << (*i).first << " " ;
(*i).second.disp();//这个对象的变量是私有的,得调用公共函数,这是我之前没有见到过的
++i;
}
}
//方法二:利用equal_range
void chazhao(string bumen)
{
pair<multimap<string,Person>::iterator,multimap<string,Person>::iterator > p;
p=m.equal_range(bumen);// [ )
multimap<string,Person>::iterator i=p.first;
multimap<string,Person>::iterator end=p.second;
for(;i!=end;++i)
{
cout << (*i).first << " ";
(*i).second.disp();
}
}
private:
multimap<string,Person>m;
};
int main()
{
pair<string,Person>p1("销售部",Person("张三",22));
pair<string,Person>p2("财务部",Person("李四",23));
pair<string,Person>p3("销售部",Person("王五",22));
pair<string,Person>p4("销售部",Person("赵六",22));
pair<string,Person>p5("财务部",Person("钱七",23));
pair<string,Person> p[]={p1,p2,p3,p4,p5};
Mange m(p,p+5);
m.select("销售部");cout << endl;
m.chazhao("销售部");
return 0;
}
3.字典问题
#include<iostream>
#include<algorithm>
#include<iterator>
#include<functional>
#include<list>
#include<vector>
#include<sstream>
#include<map>
using namespace std;
/*构造的时候是 一个主单词+剩下的是同义词*/
class Cword//同义词基础类
{
private:
string mainword;
vector<string>vecword;
public:
//构造
Cword(string strLine)
{
istringstream in(strLine);
in >> mainword;
string mid="";
while(!in.eof()) //while(in >> mid)
{
in >> mid;
vecword.push_back(mid);
}
}
//获取主单词
string get_main_word()
{
return mainword;
}
void show()
{
cout << endl;
cout << "单词是:" << "\t" << mainword << endl;
cout << "同义词是:" << "\t";
for(size_t i=0;i<vecword.size();++i)
{
cout << vecword[i] << "\t";
}cout << endl;
}
};
class CWordMange
{
private:
multimap<string,Cword>mymap; //一个key有多个value
public:
bool add(string s)
{
Cword word(s); //创建一个拥有mainword 和 后面同义词的对象
pair<string,Cword>p(word.get_main_word(),word);//这里的pair必须写成这个样子 第二个参数是Cword
mymap.insert(p);
return true;
}
void Show(string s)
{
multimap<string,Cword>::iterator itfind=mymap.find(s);//如果有同义词的话
if(itfind!=mymap.end())
{
Cword obj=(*itfind).second;
obj.show();
}
else
{
cout << s << "没用同义词" << endl;
}
}
};
int main()
{
string s[4]={string("one single unique"),string("correct true right"),string("near close"),string("strong powerful")};
CWordMange m;
for(int i=0;i<4;++i)
{
m.add(s[i]);
}
m.Show("strong");
m.Show("correct");
return 0;
}
map的插入
map的插入一定得有pair,否则无法解决问题!
第八章:算法
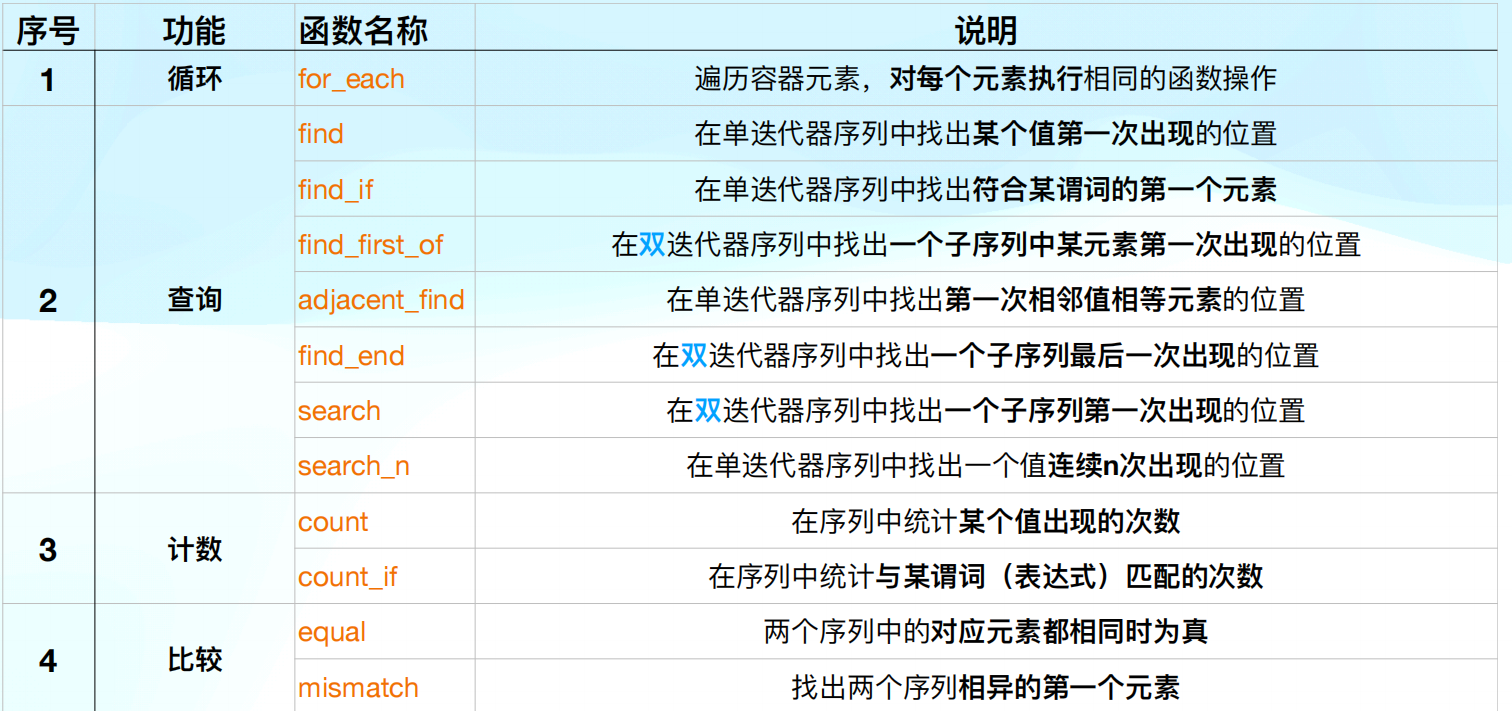

循环
for_each(知识点多)

template<class InputIterator, class Function>
Function for_each(InputIterator first, InputIterator last, Function fn) //参数:迭代器+迭代器+函数名字或者函数对象
{
while (first!=last)
{
fn (*first);
++first;
}
return fn; // or, since C++11: return move(fn);
}
for_each的三种写法:
1.第三个参数传递函数名
2.第三个参数传递函数对象(非匿名)
3.第三个参数传递匿名函数对象(必须加括号,这个括号里面赋值是给构造函数赋值)
匿名对象:类+括号
for_each的返回值类型,必须是仿函数类类型,而不是我们自定义stu类类型,这个一定要小心一点
那么第三个参数支持函数对象有没有好处呢?
第三个参数使用函数对象的优势:我们对于一些接收值而言,不需要进行全局变量的赋值,函数对象的类内私有变量即可,到时候需要使用这些变量的时候,我们用对象接收for_each的返回值,便可对其内部变量及函数进行访问
匿名对象
正常对象 A a(3) 但是不允许 A a() 这样不合语义
匿名对象 “A a()” – > A () 或者 A a(3) --> A(3)
解释Test(10)(2):
这个表达式 Test(10)(2) 中,第一个括号 Test(10) 是用来创建一个临时的 Test 类对象,并调用它的构造函数将参数 10 传递进去;而第二个括号 (2) 则是调用了该对象的函数调用符 operator()(int),并将参数 2 传递给它。
所以可以说,第一个括号和构造函数相关,用于创建对象;第二个括号和重载运算符相关,用于调用对象的函数调用符。这种连续使用括号进行对象的创建和函数调用的方式,可以方便地在一行代码中完成对象的创建和函数调用操作。
但是我们在算法中第三个参数如果使用函数对象,调用了该对象的函数调用符 operator()(int)的这个括号并不需要我们来写出,for_each函数体内部变会fn (*first),自己加上括号
- 如果第三个参数是匿名对象,必须加上括号,但是这个括号是和构造函数挂钩的,而且可以传无参
- 如果第三个参数是非匿名对象,那么一定不要加括号,加上括号就会报错,因为如果是非匿名对象的话,构造过程在for_each函数之外就已经完成了,那么此时就已经是一个构造好了的对象,如果再加上一个括号的话,就会变成fn ()(*first),这会与函数体内部实现造成冲突
class Test
{
public:
Test(int mk=0)
{
k=mk;
}
// () 小括号重载
void operator()(int a)
{
cout << a+k << " ";
}
private:
int k;
};
void test2()
{
Test ts(1);
ts(2);//调用 ts.operator(1)(2) 而不是构造函数赋值
cout << endl;
list<int> l={1,2,3,4,5};
for_each(l.begin(),l.end(),ts); //ts(*first) 写的时候 想想for_each内部是怎么实现的 就知道第三个参数应该怎么传递了
//cout << s << endl;
cout << endl;
//匿名对象引入
Test()(2);
cout << endl;
Test(10)(2);
//这个表达式 Test(10)(2) 中,第一个括号 Test(10) 是用来创建一个临时的 Test 类对象,并调用它的构造函数将参数 10 传递进去;而第二个括号 (2) 则是调用了该对象的函数调用符 operator()(int),并将参数 2 传递给它。
//所以可以说,第一个括号和构造函数相关,用于创建对象;第二个括号和重载运算符相关,用于调用对象的函数调用符。
cout << endl;
//传参传递匿名对象 ts(2)--->Test()(2) ts-->Test()
for_each(l.begin(),l.end(),Test());//Test()(*first)
cout << endl;//构造函数的括号 写的时候是一个 展开函数是俩个
//含参构造
for_each(l.begin(),l.end(),Test(10)); // Test(10)(*first) == ts(*first)
cout << endl;
}
查询
find
唯一难点就是连续查询,套路如下:
先输出结果–>再加加–>再用it=find(it,v.end(),20);
vector<Book>::iterator it=find(v.begin(),v.end(),20);
while(it!=v.end())
{
cout << *it;
it++;
it=find(it,v.end(),20);
}cout << endl;
#include<iostream>
#include<algorithm>
#include<iterator>
#include<string>
#include<vector>
using namespace std;
class Student
{
public:
Student(int NO,string strName)
{
this->NO=NO;
this->strName=strName;
}
bool operator==(int NO) const
{
return this->NO==NO;
}
friend ostream& operator<<(ostream& out,Student &s);
int get_NO() const
{
return NO;
}
string get_strNO() const
{
return strName;
}
public:
int NO=0;//学号
string strName="";//姓名
};
ostream& operator<<(ostream& out,Student &s)
{
out << s.NO << " " << s.strName << endl;
return out;
}
int main()
{
vector<Student>v; // 这个方式对我来说 写的很少 很重要
Student s1(101,"张三");
Student s2(102,"a");
Student s3(103,"b");
Student s4(104,"c");
Student s5(102,"王五");
v.push_back(s1);
v.push_back(s2);
v.push_back(s3);
v.push_back(s4);
v.push_back(s5);
vector<Student>::iterator it=find(v.begin(),v.end(),102);
while(it!=v.end())
{
cout << *it << endl;
it++;
it=find(it,v.end(),102);
}
return 0;
}

find_if

差点翻车:
之前我一直以为,写了find_if这个函数之后,就不需要写循环了,但是静下心来想想还是得写 课本P167
class person
{
string name;
int age;
public:
person(string n,int a)
{
name=n;
age=a;
}
void show()
{
cout << name << " " << age << endl;
}
int get()
{
return age;
}
};
class range
{
int up;
int low;
public:
range(int l,int u)
{
up=u;
low=l;
}
bool operator()(person p)
{
return p.get() > low && p.get() < up;
}
};
void test_example()
{
person p[]={person("zhang",20),person("lisi",22),person("wang",20)};
vector<person>v(p,p+3);
vector<person>::iterator it;
//find_if
it=find_if(v.begin(),v.end(),range(10,23));// pre(*first)
while(it!=v.end())
{
(*it).show();
it++;
it=find_if(it,v.end(),range(10,23));
}
}
差点就闹笑话了!
for_each不写是因为人家本来就是循环 count_if不写是因为人家只输出一个结果
search find_end equal 感觉都是蕴含
计数
比较
copy
注意:当我们用的是普通数组的时候,前俩个参数是 a,a+sizeof(a)/sizeof(int)
copy(v.begin(),v.end(),ostream_iterator(cout));
当我们自定义输出运算符的时候,如果第二个参数类型加上了引用,必须加const

原因如下:
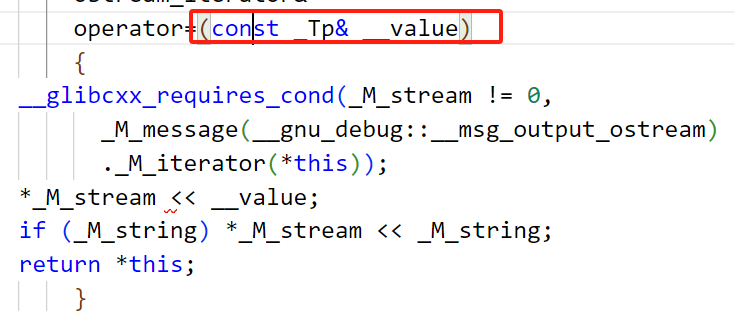
这个是ostream_iterator的源码,ostream_iterator里面的源码,这就表明,我们的普通引用不可以给const引用赋值
改正方法:

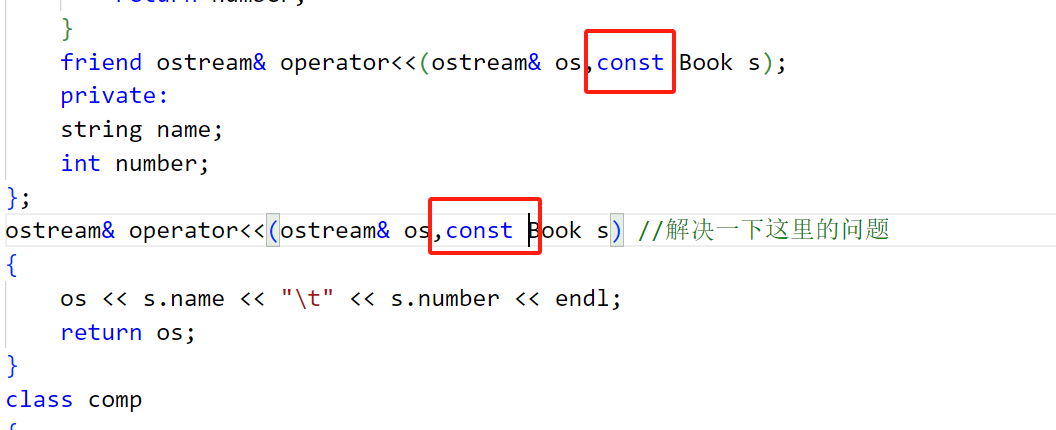
或者就是const+&都写上,但是白老师一般写的参数就是Book s,我选择:跟上 白老师的节奏!!!
sort
不要忘了如果我们写sort函数的时候,如果需要比较大小,那么一定要重载 <
而且我们的函数参数一定是类类型的,这个一定得记住,目前只有sort是这么写的重载
类内重载
[白老师deque代码例子](D:\vs code_code\Teacher_Bai\4.4deque_example.cpp)
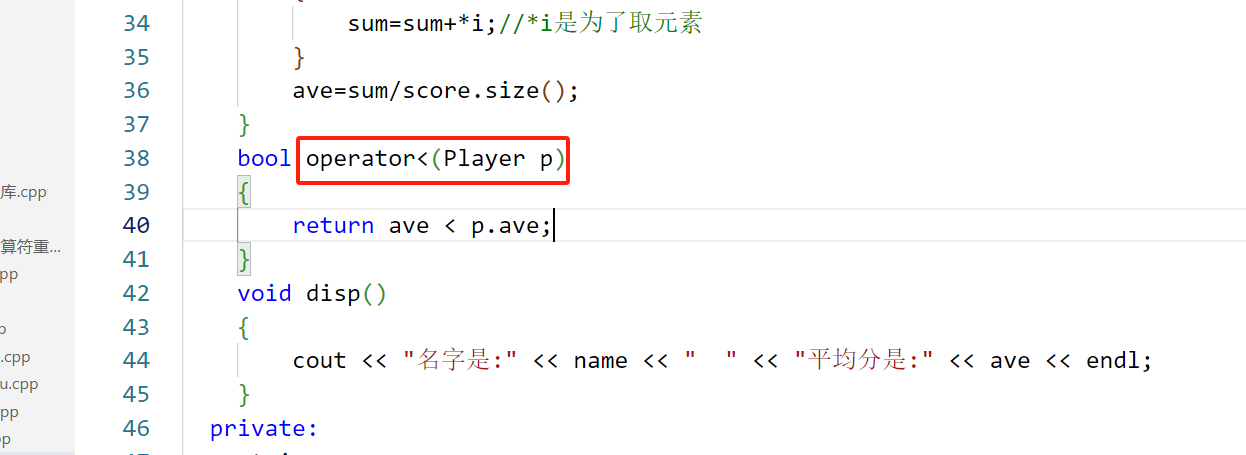
利用函数对象重载
// 创建图书类Book,其中包含属性:
// 书名name(字符串类型) , 库存量number(整型); (3分)
// b. 使用容器vector存储4个图书对象,完成对容器数据的输入(具体数值自己确定)(3分)
// c. 使用find算法和运算符重载技术,查找库存量等于20的图书信息,并输出结果(8分)
// d. 定义比较仿函数comp,并使用sort按库存量从小到大排序,并输出排序结果(8分)
#include<iostream>
#include<vector>
#include<algorithm>
#include<iterator>
using namespace std;
class Book
{
public:
Book(string name="",int number=0)
{
this->name=name;
this->number=number;
}
bool operator==(int n)
{
return n==number;
}
int getname()
{
return number;
}
friend ostream& operator<<(ostream& os,const Book& s);
private:
string name;
int number;
};
ostream& operator<<(ostream& os,const Book& s)
{
os << s.name << "\t" << s.number << endl;
return os;
}
class comp
{
public:
bool operator()(Book& a,Book& b)
{
return a.getname() < b.getname();
}
};
int main()
{
vector<Book>v;
Book s1("计算机网络",17);
Book s2("原神",20);
Book s3("本草纲目",25);
Book s4("操作系统",15);
v.push_back(s1);
v.push_back(s2);
v.push_back(s3);
v.push_back(s4);
vector<Book>::iterator it=find(v.begin(),v.end(),20);
while(it!=v.end())
{
cout << *it;
it++;
it=find(it,v.end(),20);
}cout << endl;
sort(v.begin(),v.end(),comp());
// auto i=v.begin();
// while(i!=v.end())
// {
// cout << *i ;
// ++i;
// }cout << endl;
copy(v.begin(),v.end(),ostream_iterator<Book>(cout));
return 0;
}

这个是利用函数对象的知识去书写的,所以我们下面sort第三个参数也要小心不要写错了
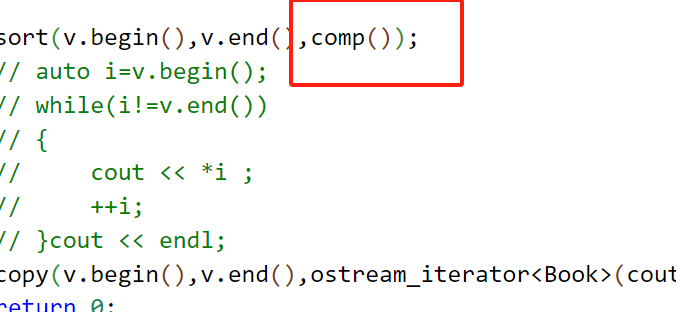
关于函数对象的参数到底怎么写,请回忆邸老师和我讲述的相关细节!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!