(7)Linux GDB以及gcc和g++
💭 前言
本章我们将带着大家高雅的学一学令众多习惯图形化页面的朋友难受的 gdb 调试,这部分知识可以选择性学习学习,以后倘若遇到一些问题时能在 Linux 内简单调试,还是很香的。然后在讲讲?gcc 和 g++,系统讲解程序运行时的各个过程。
GDB 调试?
调试前的准备
我们先来创建一个用来演示 GCD 调试功能的目录:?
既然要调试,我们就必须要有个代码,我们这里写一个数字累加的代码:
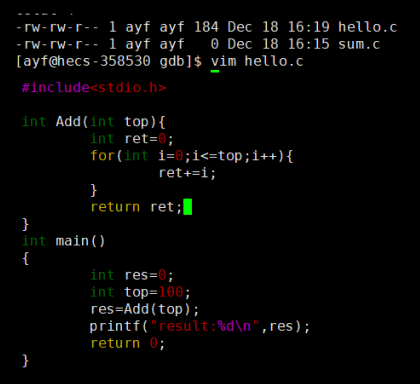
运行结果:?
?
结果是5050,没有问题。如果我们代码出现了一些问题需要我们调试,我们就可以使用 gdb。
如果此时你出现了报错,说什么不支持 for 循环里面定义变量,你可以输入:
$ gcc hello.c -o hello -std=c99?Linux 默认集成环境
在你当前的代码目录下直接执行 gcb + 形成的可执行程序:
$ gdb [可执行程序]![]()
我们需要安装一下:
yum install gdb //切换到root
回到刚才的位置,再输入:gdb hello
?此时就进入了 gdb 的调试命令行中:

(如果想退出,直接按 quit 就可以退出了)
gcb 读取我们的 hello 程序时出现了 "没有调试符号被发现" 的警告。
这是什么意思呢?
我们的 gdb 中有一条命令叫做 list(简写成 l),但是我们输入后出现以下提示:
?
因为 —— 默认形成的可执行程序无法调试!!!
相信大家都知道,C语言的发布方式有两种,一种是 debug 一种是 release。
我们在 VS 里面可以直接调的原因是,VS2019 的默认集成环境是 debug。
而在我们的 Linux 中的默认集成环境是 release,换言之,
在我们 Linux 中如果你想发布一个程序,可以直接发布,无需加任何选项。
但是如果你想调试,以 debug 形式发布,那么你就需要在编译时在后面添加一个 -g 选项:
$ gcc hello.c -o hello.g -g
总结:Linux 默认形成的可执行程序是动态链接且是 release 方式发布。
- 如果想静态链接,加 -static
- 如果想动态链接,加 -g
readelf 读取 ELF 文件信息?
?release 和 debug 的区别:你的可执行程序里本来就有调试信息,?只是 debug 中才有。
首先,这两个版本也都是可以运行的:?
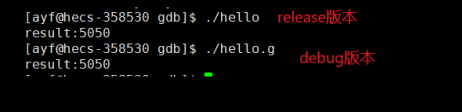
并且我要告诉你的是:debug 版本比 release 版本多几千个字节,这是什么?
毫无疑问,这些就是一个可执行程序的调试信息,它在 debug 版本中有所显现。
?如果你想看调试信息,你可以输入:
$ readelf -S [可执行程序] # 以段的形式读取可执行程序,用于显示读取ELF文件中信息?
我们再来读一读 debug 版的:

因为 debug 版本是能给你的可执行程序添加调试信息的,所以体积自然比 release 版本要大些。
所以我们调试的得是 debug 版本的可执行程序,预备工作全部做好,下面我们来正式学习 gdb。
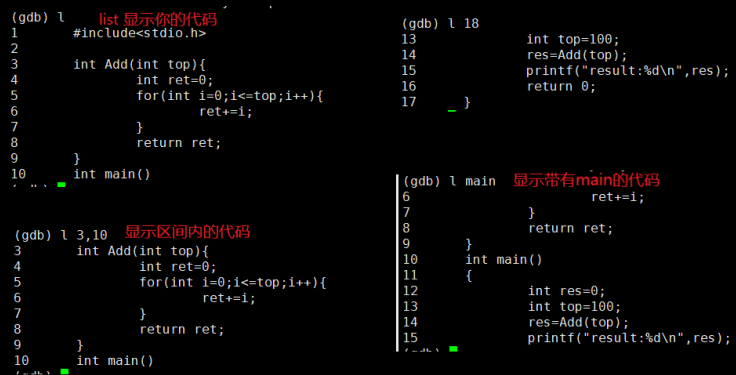
显示代码?gcb(list)?
?现在我们是 debug 版本了,我们也顺理成章地能够使用前面我们说的 list 了。
(gdb) list [n] # 显示代码,可带行号
(gdb) list [function] # 显示带某函数的代码块
(gdb) list [begin, end] # 显示区间内的代码
...我们输入:gdb hello.g ,然后演示
一般在 VS 下调试的时候,除了让你看到代码,还会让你看到进行到了哪里,这里也是一样的。
你按下回车后,gdb 会自动记录你的上一条指令,直接按回车就是上一条命令:
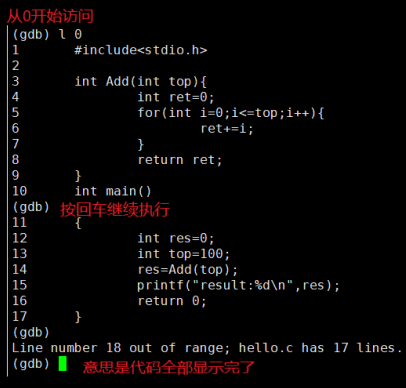
(这么做就能把代码从第一行开始,将所有代码块逐个显示出来了)?
断点?
假设我们想在下面代码的第15行处打个断点:
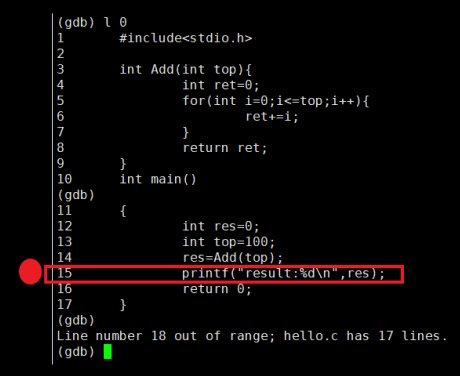
这要是放在 VS 下我们直接滑鼠选中对应行然后无脑按 F11 就行了。?
而在 gdb 下打断点的方式是用 breakpoint:
(gdb) breakpoint [n] # 在第n行处打一个断点? ? ? ? ? ? ? ? ? ? ? ? ? ?
操作演示:我们在代码第15行打个断点看看:

提示在第15行有个断点
此时如果你想查看断点,可以使用 info 查看你打的断点:
(gdb) info b # 查看断点
如果想要删除断点,在 VS 下我们直接再点以下小红点就搞定了
?但是在 gdb 中,我们需要知道要删除的断点的编号:
(gdb) d [Num] # 删除Num号断点?
?调试
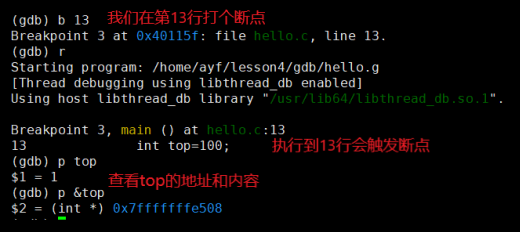
准备开始调试,记得把刚才删除的断点再打回去,调试的指令如下:
(gdb) run # 开始调试?操作演示:输入完 r 按回车开始调试:


这里我们输入y,让他运行:

结果为:5050.
如果你想查看变量的内容,我们可以使用 print 命令:
(gdb) print [val]💭 操作演示:查看变量内容
操作演示:逐语句
如果想逐语句执行(逐语句即一步一步往后走),逐语句指令如下:
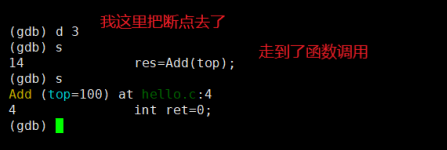
我们 s 两次后,此时走到了函数的调用处。此时如果你不想进入该函数,就不要再按 s 逐语句了。
此时我们应该逐过程执行,我们可以使用 next 命令:
(gdb) next # 逐过程💭 操作演示:逐过程
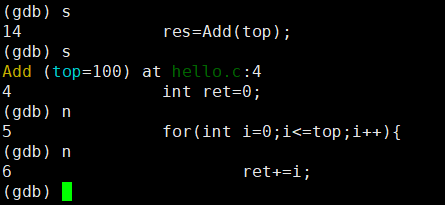
监视?
我们在 VS 中调试代码的时候,有时候要细细观察某个变量时,我们会打开监视窗口:
在 gdb 下我们就可以使用 display 常显示来监视:?
$ display [val] # 监视一个变量,每次停下来都显示它的值
$ display [v1, v2, v3...] # 同时添加多个变量,用括号隔开?操作演示:常显示 i?变量
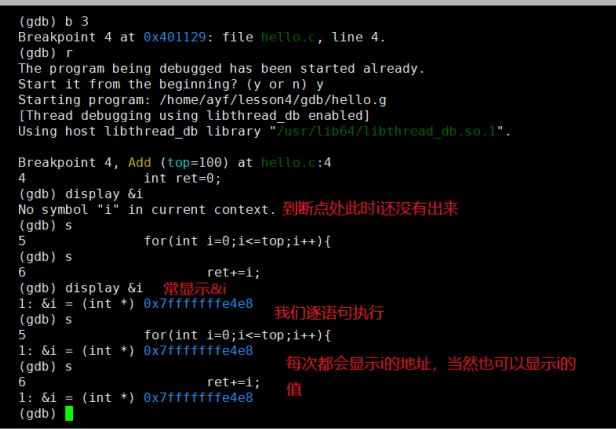
直接输入 display 可以查看监视列表:?
$ display # 查看当前监视列表?
如果想把某个变量从监视窗口移除,我们可以使用 undisplay:
$ undisplay [n] # 删除n号变量?
跳转(until & c & finish)?
我们调试的时候在文本特别大的时候我们有时候会跳转,VS 里我们可以直接拖动箭头跳转。
gdb 调试下我们可以使用 until 指令跳转到指定行:
$ until [n] # 跳转到指定行操作演示:跳转到14行

如果想从一个断点跳转至另一个断点,我们可以使用 c:
$ c # 直接跳转到另一个断点有时候难免手贱不小心进了不想进入了函数,就比如不小心逐语句进了 printf 函数。
这个在 VS 下逐语句是不会进去的,但是在 Linux 下会进入,此时如果你反悔了象出来,
就可以输入 finish,它可以做到直接执行完成一个函数就停下来。
$ finish # 执行到当前函数返回,然后停下来等待命令?对于 gdb 的总结
掌握上面单独介绍的 b、d、l、s、n、display、until、r、c、finish 其实就差不多了。
还有一些 gdb 的指令我们上面没有介绍,这里做一个整合:
list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
list/l 函数名:列出某个函数的源代码。
r 或 run:运行程序。
n 或 next:单条执行。
s或step:进入函数调用。
break(b) 行号:在某一行设置断点。
break 函数名:在某个函数开头设置断点。
info break :查看断点信息。
finish:执行到当前函数返回,然后挺下来等待命令。
print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数。
p 变量:打印变量值。
set var:修改变量的值。
continue(或c):从当前位置开始连续而非单步执行程序。
run(或r):从开始连续而非单步执行程序。
delete breakpoints:删除所有断点。
delete breakpoints n:删除序号为n的断点。
disable breakpoints:禁用断点。
enable breakpoints:启用断点。
info(或i) breakpoints:参看当前设置了哪些断点。
display 变量名:跟踪查看一个变量,每次停下来都显示它的值。
undisplay:取消对先前设置的那些变量的跟踪。
until X行号:跳至X行。
breaktrace(或bt):查看各级函数调用及参数。
info(i) locals:查看当前栈帧局部变量的值。
quit:退出gdb。
gcc 和 g++?
首先我们要明确一点:在之前的Linux学习中谈到:Linux中不分文件后缀,所以文本文件可以设置后缀为txt来提醒读者这是一个文本文件,也可以什么都不写。
但是Linux系统不分文件后缀。不代表Linux下的各种程序不分!
gcc:C语言编译器,只能编译C语言g++:C++编译器,C/C++都可以编译
$ gcc [文件名] # 编译C
$ g++ [文件名] # 编译C++?此外,如果你输入"g++ test.cpp" 时显示并没有这样的指令,可以安装一下:
sudo yum install -y gcc-c++我们知道,gcc 是不能用来编译 C++ 代码的,它只能用来编译 C 语言的代码:
$ gcc test.cpp ?
$ gcc test.c ??但是, g++ 是可以用来编译 C 语言的,这个相信大家是可以理解的,因为 C++ 是 C 的超集:
$ g++ test.c ?
$ g++ test.cpp ?程序的翻译过程
程序(文本)要转换成机器语言(二进制),翻译有以下四个步骤:
- ① 预处理? ?
- ② 编译? ?
- ③ 汇编? ?
- ④ 链接
预处理阶段
预处理阶段要做的工作有:
- 头文件展开
- 去掉注释
- 条件编译
- 宏替换
Linux 的 gcc 是如何进行上面的过程的呢?我们先看预处理的过程。
💬?我们来修改一下 test.c 源文件,让它有头文件、宏、注释和条件编译:

此时我们直接用 gcc 编译一下代码,"gcc + 要编译的文件"?默认生成的可执行程序叫 a.out。
顺便一提,如果你不想让生成的可执行程序为叫?a.out,你想指定名称,可以加上 -o 选项:
?
?默认情况下他会生成一个你指定名字的可执行文件:mytest
gcc -E test.c -o test.i
# -E: 从现在开始给我进行程序的翻译,当预处理完成就停下来
# -o test.i:将最后的结果写到 test.i 中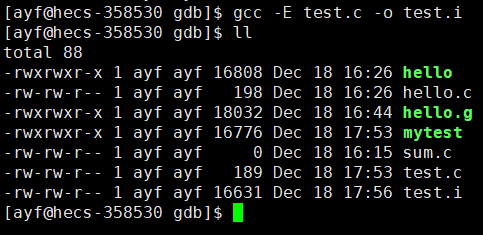
下面操作我会把hello,sum移走(它占地方了,为了简洁-------就是不爱了)
生成test.i。然后我们 gcc 打开 test.c(vim test.c),冒号进入底行模式后输入 vs test.i,就可以分屏观察:?
我们写代码写的 .h 文件 .c 文件,当你编译的时候实际上是把你的 .h 代码全部拷贝到 .c 中的。
为了防止重复包含头文件,我们在《树锯结构》专栏还提到了用 #pragma once 防止重复包含。
观察 test.o 前面部分后我们发现 Linux 中 C语言标准头文件在 /usr/include 下,我们这就去看看:
$ ls /usr/include
一般都会安装在 usr/include 目录下,当然!不排除以后会出现安装在其他目录下的可能性。
现在你只需要记住:以前我们编写C语言代码时 #include<stdio.h> 时,其实并不是说 #include 就一定能成功,前提是你平台必须得装了你引入的头文件,不然也没东西在你的源文件中展开。
?注意:编译器内部都必须通过一定的方式,知道你所包含的头文件所在的路径。?
现在在回头想一想,为什么一个新的语法老的编译器不支持的问题。其根本原因是因为老的编译器配套的头文件和库,压根就没有这一套东西。我们在装 VS 编译器的时所谓的环境安装勾选 C/C++ 后,实际上就是在给你装 C语言 C++ 的头文件和库。?
观察:我们再来比对一下它们的代码部分有什么差别:
打开test.i之后,往下翻呀翻呀翻------找到了

此时,就完成了预处理的工作。
我们刚才的条件编译只保留了 release,现在我们如果 #define 出一个 DEBUG,
再重新编译打开比对,保留的就不是 "hello,release!" 而是 "hello, debug!"?了,这里就不演示了。
? 思考:程序进行完预处理操作后,还是C语言吗?
💡 答案:仍然是C语言!你看这些代码你还认不认识,它当然还是C语言了。
?换言之,这个预处理工作仅仅是为了让程序翻译的更顺畅,帮助我们做了一些文本替换处理操作而已。比如宏替换(当然,例子里面我不小心忘记了在代码中用到宏,所以自然前后也没有替换)、去掉给人读的注释(机器才懒得读你写的注释呢,跟它也没有半毛钱关系)、根据条件编译的结果把不要的选项去掉……最后它还是C语言,只不过时一份干净的C语言。你可以理解为 "文章的润色" 。
命令格式:
gcc [选项] 要编译的文件 [选项] [目标文件]预处理(进行宏替换):
- ??? 预处理功能主要包括宏定义、文件包含、条件编译、去注释等。
- ??? 预处理指令以 # 号开头的代码行。
- ??? 实例:gcc -E hello.c -o hello.i
- ??? 选项:"-E"? 该选项的作用是让 gcc 在预处理结束过后停止编译过程。
- ??? 选项:“-o"? 是指目标文件, "i" 文件为已经过预处理的C初始程序。
?编译过程
编译的核心工作就是将C语言翻译成汇编语言!
如果看不懂也没有关系,你只要知道 —— 这一步会让你的C语言代码大变样!
$ gcc -S test.i -o test.s
# -S: 从现在开始进行程序的编译,当我们编译完成之后,就停下来!这次我们从 test.i 开始走,当然也可以是 test.c,那会重新走一遍预处理的过程然后再编译。
(汇编语言的后缀一般都叫 .s,所以我们这里取名为 .s,我们前面章节也说过 Linux 的类型和文件后缀没有关系,这里你用 .lbwnb 都没有人拦你,只是叫 .s 更符合常理)
输入完上面命令后就形成了 test.s 的文件:
多了一个test.s,我们vim打开:
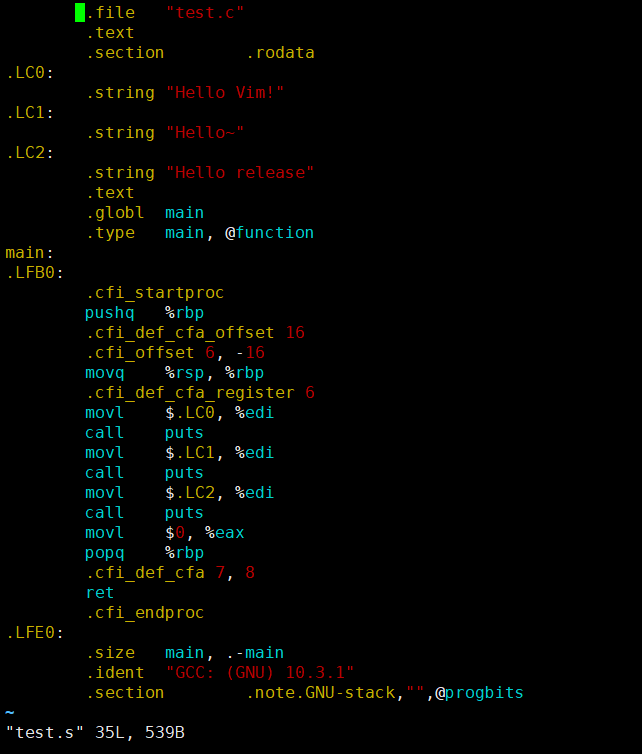
这是 x86 环境下的汇编指令,其中有一些汇编的助记符,即使看不明白也没有关系。
但是你可以发现代码的数量 从刚才 test.i 的八百多行,变成了现在短短的 45 行!
汇编过程(简单了解)?
汇编阶段的主要工作是:
- 将汇编代码变成可重定位二进制文件
$ gcc -c test.s -o test.o
# -c:从现在开始进行程序的编译,当我们汇编结束之后,就停下来!?
乂,我们多了一个test.o文件。
gcc 打开后会是很大的一坨乱码。
我们可以用一些二进制查看工具去查看,刚才的汇编语言确实有人可以看懂,但这里我直接说没有人能直接看懂应该不过分吧:
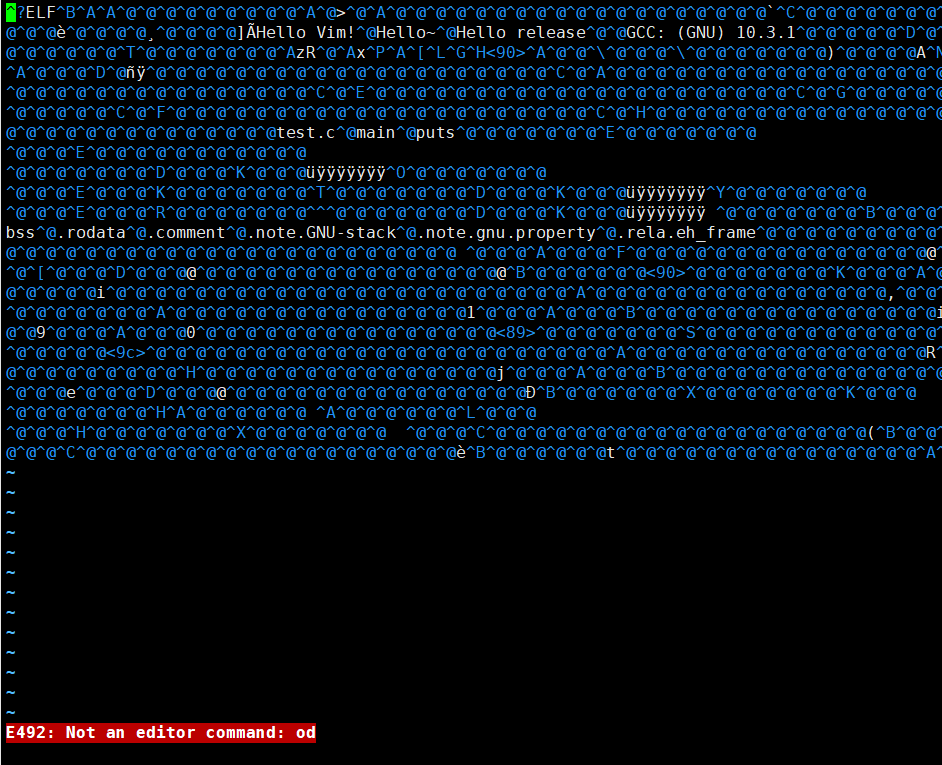
可以使用指令od查看二进制文件:

虽然现在代码已经是二进制的了,但是仍然是不能运行的:
其原因也很简单,因为这里面有些符号目前还没有和系统关联起来。
链接过程?
链接阶段比较复杂,它大致的流程是这样的:
.o文件 + 系统库 = 可执行程序
所有的包含头文件的操作,本质是因为想使用头文件所声明的方法!
$gcc test.o -o mytest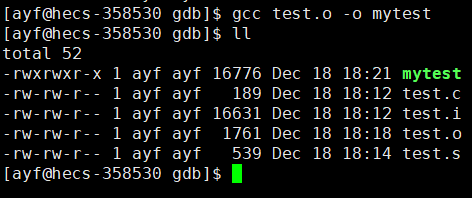
而这最后一步,隐含的就是链接我们自己的程序和库,形成可执行程序!
当然了,直接到程序的翻译过程:
$ gcc test.c -o mytest.c一步就可以到位了,我们之前是为了研究一步步的过程,所以又是 -E 又是 -S 又是 -c 的。
总结
我们先来回故前三个翻译过程,按顺序分别为预处理、编译和汇编。?
$ gcc -E test.c -o test.i # 预处理
$ gcc -S test.i -o test.s # 编译
$ gcc -e test.s -o test.o # 汇编?这里有个记忆方法:预处理 (E) → 编译 (S)→ 汇编 (c) ,三个过程就是?。
如果你记不得,可以看看你键盘的左上角就行了(当然前提你要记住程序翻译过程的顺序)。
另外它们形成的临时文件为 test.i、test.s、test.o,也同样有个记忆的方法:?
函数库(Function library)?
我们在写C语言代码时使用的printf函数并没有自己实现,然而在stdio.h头文件中也只有printf函数的说明,那么此函数的实现是在哪里实现的呢?
引出今天的新内容
查看一个可执行程序依赖的第三方库
头文件与库文件(Header file and Library file)
头文件:给我们提供了可以使用的方法,所有的开发环境,具有语法提示,本质是通过头文件帮我们搜索的。
库文件:给我们提供了可以使用的方法的实现,以供链接,形成我们自己的可执行程序。
动态库与静态库(Dynamic library and static library)?
我们必须承认一个事实,计算机存在两类库:一类库叫动态库,一类库叫静态库。
静态库:Linux (.so),Windows (.dll)? ? —— 动态链接
静态库:Linux (.a),Windows (,lib)? ? ? —— 静态链接
静态链接:将库中的相关代码,直接拷贝到自己的可执行程序中。
动态链接:
- 优点:大家共享一个库,可以节省资源。
- 缺点:一旦库丢失,会导致几乎所有的程序失效!
通俗的来讲,动态库类似于网吧的电脑。而静态库类似于自己家里的电脑?
它们的区别是:
- 动态库是共享库,通过函数地址来关联程序
- 静态库是私有库,可以独立运行
那 gcc 中如何体现呢?
形成的可执行程序体积一定是不一样的,静态链接体积大,动态链接体积小。
那么我们在 Linux 中用 gcc 编译程序
默认情况下形成的的可执行程序就是动态链接的:?
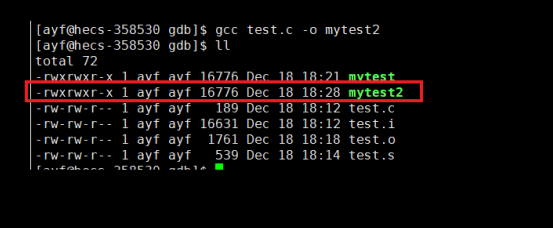
如果你想进行静态链接,你需要在编译代码时在后面加上 -static 选项:
$ gcc test.c -o mytest2 -static # 静态链接?静态库的安装
此时如果出现了像下面这样找不到的情况:

那么你就需要安装一下静态库,记得切换到 root 下去安装。
🔧 安装?C 的静态库:
# sudo yum install -y glibc-static?
安装 C++ 静态库:
# sudo yum install -y libstdc++-static?动态链接和静态链接推荐使用哪个?
默认是动态链接,我们也更推荐动态链接,
因为生成体积小,无论是编译时间还是占资源的成本,一般都比静态链接要好。
但这并不是绝对的!如果你要发布一款软件是动态链接的,程序短小精悍但库相对显得累赘,
如果此时你发布这款软件就不想带库了,你把它静态链接就是完全合适的。
总结以及拓展
总的来说gcc,g++这两个编译器并不难
掌握它们就需要学会使用一些特殊的指令
这里列出一些gcc常用的指令
大家可以下来自己尝试:

感谢~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AWS-SAA-C03认证——之基础知识扫盲
- python学习笔记7
- 什么台灯最好学生晚上用?学生晚上用的护眼台灯推荐
- StartAI文生图攻略(元旦篇)
- 100T数据存进服务器分几步?
- SpringAMQP的使用方式
- MySQL 8.0 InnoDB Tablespaces之General Tablespaces(通用表空间/一般表空间)
- 计算机组成原理——以存储器为中心的计算机硬件框架
- EasyExcel+多线程实现大数据量
- No CPU/ABI system image available for this target