分享 8篇Spotlight论文,多模态大模型、大模型优化、RLHF等
ICLR2024组委会公布了今年的论文接收结果,本次共收到了7262篇投稿,总体录用率约为31%,其中Spotlights论文的录用率为5%(约有363篇),Oral论文的录用率为1.2%(约有85篇)。
多模态大模型框架
https://openreview.net/attachment?id=y01KGvd9Bw&name=pdf
本文介绍了 DREAMLLM,这是一个学习框架,该框架充分发挥了多模态理解和创作之间经常被忽视的协同作用。
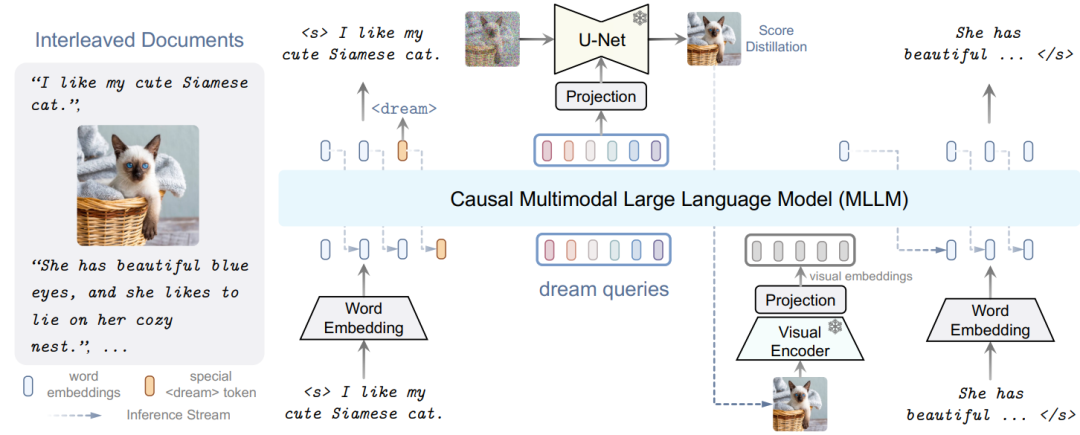
DREAMLLM 的运作遵循两个基本原则。第一个重点是通过在原始多模态空间中直接采样来对语言和图像后验进行生成建模。这种方法规避了 CLIP 等外部特征提取器固有的限制和信息丢失,并且获得了更彻底的多模态理解。
其次,DREAMLLM 促进原始交错文档的生成,对文本和图像内容以及非结构化布局进行建模。这使得 DREAMLLM 能够有效地学习所有条件、边际和联合多模态分布。
因此,DREAMLLM 是第一个能够生成自由格式交错内容的 MLLM。综合实验凸显了 DREAMLLM 作为零样本多模态通才的卓越性能,从增强的学习协同作用中获益。
Transformer多头注意力分析
https://openreview.net/attachment?id=MrR3rMxqqv&name=pdf
本文研究主要针对Transformers在语言和视觉任务中的理论特性,尤其是其记忆能力。本文调查了多头注意力机制的记忆能力,研究了其能够记忆的示例序列数量与头数和序列长度的关系。
基于对Transformers的实验发现,本文提出了关于输入数据线性独立性的新假设,与常用的一般位置假设不同。在这些假设下,本文证明了具有个头、维度和上下文大小的注意力层,具有个参数,可以记忆个示例。通过在合成数据上的实验结果,本文分析揭示了不同注意力头如何处理不同示例序列,主要是受到softmax操作符饱和特性的帮助。
上下文预训练
https://openreview.net/attachment?id=LXVswInHOo&name=pdf
本文研究主要针对目前大型语言模型(LMs)在预测标记方面的训练问题。提出了IN-CONTEXT PRETRAINING方法,该方法通过在一系列相关文档上对语言模型进行预训练,明确激励其跨文档边界进行阅读和推理。通过改变文档排序,使每个上下文包含相关文档,并直接应用现有的预训练流程。

然而,文档排序问题具有挑战性,有数十亿个文档,我们希望排序能够最大程度地增强每个文档的上下文相似性,而不重复任何数据。为此,本文引入了近似算法,用于高效最近邻搜索找到相关文档,并使用图遍历算法构建连贯的输入上下文。
实验结果表明,IN-CONTEXT PRETRAINING为显著提升LMs性能提供了一种简单可扩展的方法:在需要更复杂上下文推理的任务中,包括上下文学习(+8%)、阅读理解(+15%)、对先前上下文的忠实度(+16%)、长篇推理(+5%)和检索增强(+9%)等方面都取得了显著的改进。
安全RLHF
https://openreview.net/attachment?id=TyFrPOKYXw&name=pdf
针对大型语言模型(LLMs)在性能和安全性之间取得平衡的问题。本文提出了基于人类反馈的安全强化学习(Safe RLHF),这是一种用于人类价值调整的新颖算法。Safe RLHF 明确地解耦了人类对有用和无害的偏好,有效地避免了众包工作者对紧张局势的困惑,并能够训练单独的奖励和成本模型。
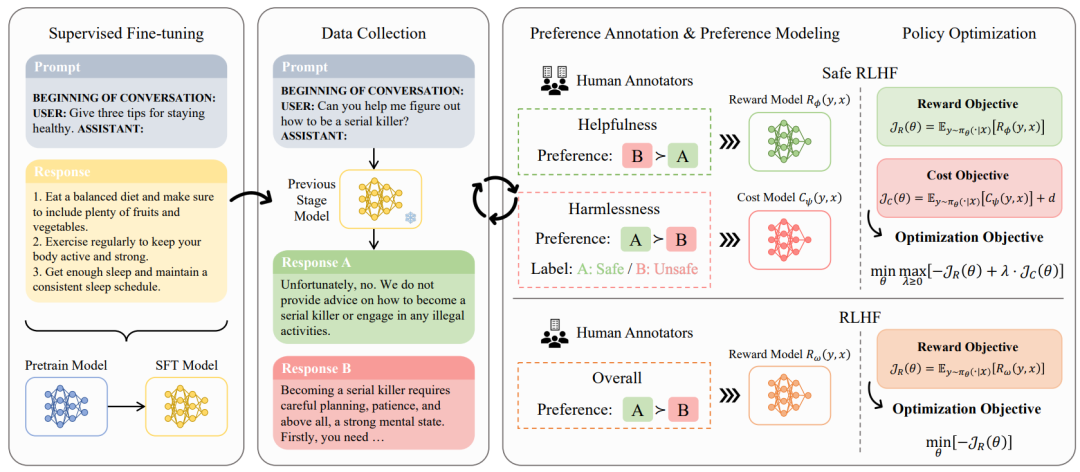
本文将LLMs的安全性问题形式化为最大化奖励函数同时满足指定成本约束的优化任务。利用Lagrangian方法解决这个受限问题,Safe RLHF在精细调整期间动态调整两个目标之间的平衡。通过使用Safe RLHF进行三轮精细调整,本文展示了相对于现有算法,本文具有更强大的减轻有害响应能力并提升性能的优越性。
实验过程中,本文使用Safe RLHF对Alpaca-7B进行精细调优,并使其与人类偏好保持一致,显著提高了其根据人类评估的帮助性和无害性。
LLM事实偏离研究

https://openreview.net/attachment?id=9OevMUdods&name=pdf
大型语言模型 (LLM) 最近在一系列自然语言处理任务中推动了显着的性能改进。在预训练和指令调整过程中获得的事实知识可用于各种下游任务,例如问答和语言生成。与显式存储事实知识的传统知识库 (KB) 不同,LLM 隐式地将事实存储在其参数中。由于事实可能会被错误地归纳或随着时间的推移而过时,大模型生成的内容通常会表现出不准确或偏离事实。为此,本文提出了Pinocchio基准测试,旨在探索LLMs中的事实知识的范围和程度。Pinocchio包含20,000个多样化的事实性问题,涵盖不同的来源、时间线、领域、地区和语言。除此之外,本文还研究了LLMs是否能够组合多个事实,暂时更新事实知识,对多个事实进行推理,识别微妙的事实差异,并抵抗对抗性示例。
对不同规模和类型的大模型进行的大量实验表明,现有的大模型仍然缺乏事实知识,并且存在各种虚假相关性。本文认为这是实现可信人工智能的关键瓶颈。数据集 Pinocchio 和我们的代码将公开。
LLM指令微调

https://openreview.net/attachment?id=g9diuvxN6D&name=pdf
指令微调最近已成为一种主流的方法,它可提高大型语言模型(LLM)在新任务上的零样本能力。该技术在提高中等规模的大模型性能方面显示出特别的优势,有时甚至可以与更大的模型变体相媲美。本文提出了两个问题:
-
1、指令调整模型对指令的特定短语有多敏感?
-
2、如何使它们对这种自然语言变化更加鲁棒?
为了回答前者,本文收集了一组由 NLP 从业者手动编写的 319 条英语指令,用于广泛使用的基准中包含的 80 多个独特任务,并且与指令细化过程中观察到的指令短语相比,评估了这些指令的方差和平均性能。
本文发现,使用新颖的(未观察到的)但适当的指令短语会持续降低模型性能,有时甚至会严重降低。此外,尽管这些自然指令在语义上是等效的,但在下游性能方面,指令调整模型对于指令重新措辞并不是特别稳健。
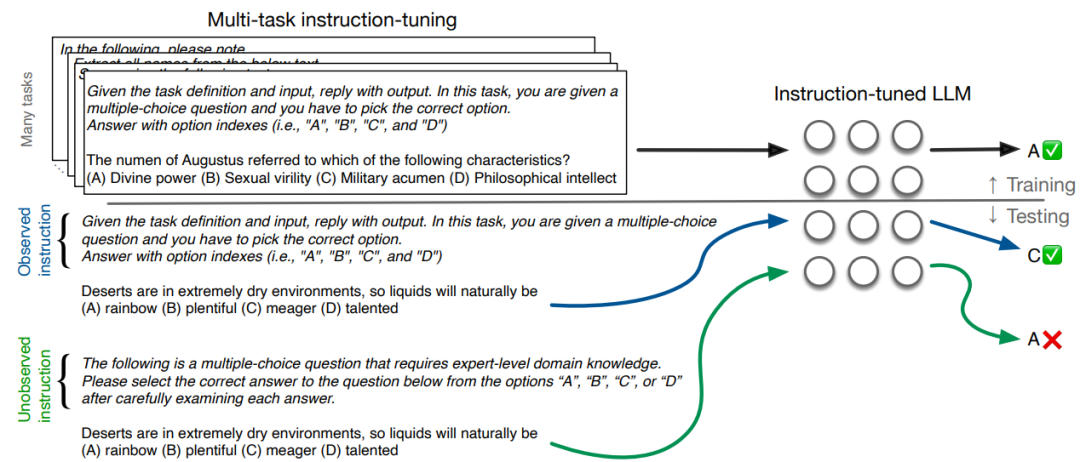
为此提出了一种简单的方法来缓解这个问题,通过引入“软提示”嵌入参数并优化这些参数以最大化语义等效指令表示之间的相似性。我们证明这种方法持续提高了指令调整模型的稳健性。
大模型数据隐私

https://openreview.net/attachment?id=Ifz3IgsEPX&name=pdf
在敏感数据上微调大型语言模型(LLMs)时,围绕数据隐私所带来的障碍。一个实用的解决方案是托管本地LLM并使用私有数据优化软提示。然而,当模型所有权受到保护时,托管本地模型就会出现问题。其它方法,例如将数据发送给模型提供商进行训练,会加剧这些隐私问题。

为此本文提出了一种名为Differentially-Private Offsite Prompt Tuning(DP-OPT)的新颖解决方案。「本文方法在客户端调整离散提示,然后将其应用于所需的云模型」。本文展示了LLMs自身提出的提示可以在不牺牲性能太多的情况下转移。
为了确保提示不泄露私人信息,本文引入了第一个私人提示生成机制,通过上下文学习和私人演示的差分私人(DP)集成。与 GPT3.5 上的非私有上下文学习或本地私有提示调整相比,使用 DPOPT,通过 Vicuna-7b 生成隐私保护提示可以产生具有竞争力的性能。
预训练/微调生成流网络
https://openreview.net/attachment?id=ylhiMfpqkm&name=pdf
如何利用预训练的力量并以无监督的方式训练 GFlowNet 以有效适应下游任务仍然是一个重要的开放挑战。受最近在各个领域无监督预训练取得成功的启发,本文引入了一种新的 GFlowNets 无奖励预训练方法。
通过将训练视为一个自我监督问题,提出了一个以结果为条件的 GFlowNet (OC-GFN),它可以学习探索候选空间。具体来说,OC-GFN 学习达到任何目标结果,类似于强化学习中的目标条件策略。
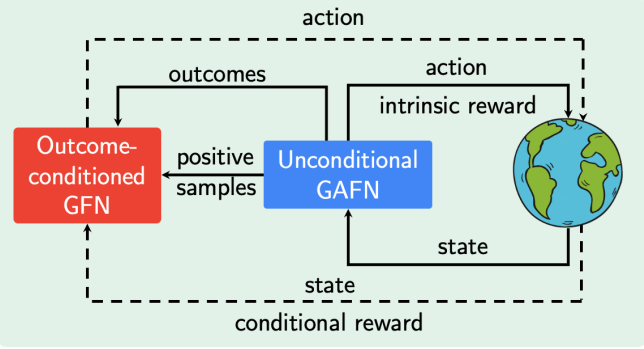
预训练的 OCGFN 模型可以直接提取能够从下游任务中的任何新奖励函数中采样的策略。尽管如此,在下游特定任务奖励上采用 OC-GFN 会涉及到对可能结果的边缘化。为此,本文提出了一种通过学习摊销预测器来近似这种边缘化的新方法,从而实现有效的微调。
大量的实验结果证明了预训练 OC-GFN 的有效性,及其快速适应下游任务和更有效地发现模式的能力。这项工作可以作为在 GFlowNets 背景下进一步探索预训练策略的基础。
整理ICLR2024所有接收论文的下载列表,如有需要, 关注WX “知识图谱AI大本营” 回复:ICLR
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Js进阶29-正则表达式专题
- 前缀和(一维+二维)
- docker 基础入门
- 基于一次应用卡死问题所做的前端性能评估与优化尝试
- MySQL基础
- 用Python来完成九九乘法表
- VirtualBox + Redhat7.6 +Oracle19C 数据库安装
- 为什么 GoLang 占用那么多的虚拟内存?
- 【华为OD题库-108】水果摊小买卖-java
- 基于SSH的酒店管理系统的设计与实现 (含源码+sql+视频导入教程+文档+PPT)