【大厂秘籍】系列-Mysql基础框架
? 学习新知识的时候千万不要一上来就陷入细节,你应该先完成一个整体框架的构建,才可以在高维度视角理解问题。然后再把框架拆解成小的分支,逐个攻破。久而久之,习惯养成,很多问题也就不成问题了。
关注企鹅君公众号,一起高效学习~

一 MySQL 基本架构
我们在使用MySQL中看到的只是输入一条语句,返回一个结果,却不知道这条语句在 MySQL 内部的执行过程。
比如我们在执行下面这个查询语句时:
mysql> select * from T where id=1;
客户端发出一条SQL查询语句的执行过程:
连接器 --> 分析器 --> 优化器 --> 执行器 --> 存储引擎
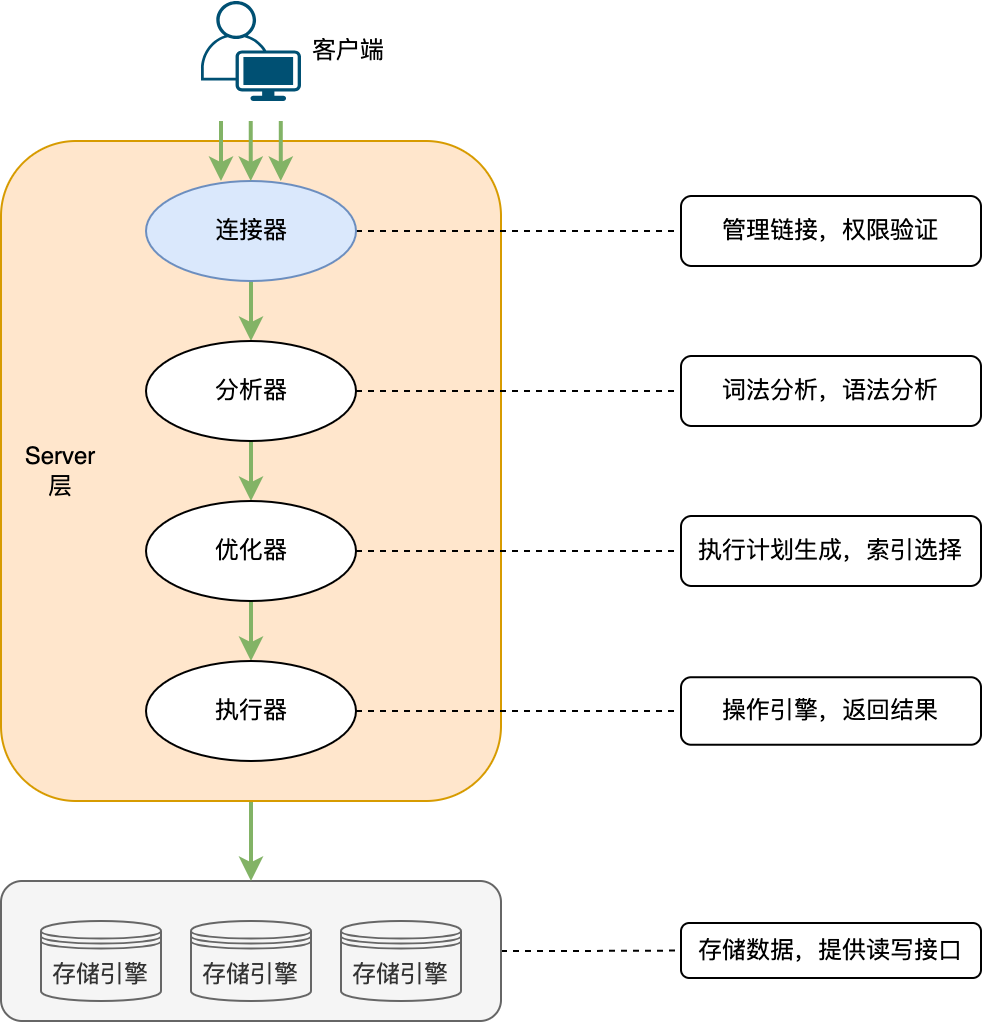
MySQL可以分为 Server 层和存储引擎层两部分:
Server 层
Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层
存储引擎层则负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
从图中不难看出,不同的存储引擎共用一个Server 层,也就是从连接器到执行器的部分。你可以先对每个组件的名字有个印象,接下来我会结合开头提到的那条 SQL 语句,带你走一遍整个执行流程,依次看下每个组件的作用。
连接器
第一步,你会先登陆数据库系统,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。超时自动断开,建立连接过程复杂,建议使用长链接,连接比较占用内存,需要定时断开,5.7之后可以使用mysql_reset_connection。连接命令一般是这么写的:
mysql -u 数据库用户名 -p
输完命令之后,你就需要在交互对话里面输入密码。认证通过后,连接器会到权限表里面查出你拥有的权限。你就可以对数据库进行操作了。
查询缓存 (MySQL 8.0版本后被移除)
其他资料中第二步是去查询缓存, 但是这个功能不实用,MySQL 8.0 版本就直接将查询缓存的整块功能删掉了
图中博主也直接删掉了
查询缓存简单来说就是以key-value对的形式存储之前做过的查询,key是查询语句,value是查询的结果,如果正在执行的查询,存在缓存中,那么直接返回结果。表上的任意更新都会导致表上的所有查询缓存清空。
分析器
成功建立连接后,对于客户端输入的命令,MySQL 需要先知道你要做什么,因此需要对 SQL 语句做解析。
第一步,词法分析,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“id”识别成“列 id”。
第二步,语法分析,主要就是判断你输入的 SQL 是否正确,是否符合 MySQL 的语法。 如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 select 少打了开头的字母“s”。
mysql> elect * from t where id=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where id=1' at line 1
一般语法错误会提示第一个出现错误的位置,所以你要关注的是紧接“use near”的内容。
完成这 2 步之后,MySQL 就准备开始执行了,但是如何执行,怎么执行是最好的结果呢?这个时候就需要优化器上场了。
优化器
优化器的作用就是它认为的最优的执行方案去执行(有时候可能也不是最优,这篇文章涉及对这部分知识的深入讲解),比如多个索引的时候该如何选择索引,多表查询的时候如何选择关联顺序等。
可以说,经过了优化器之后可以说这个语句具体该如何执行就已经定下来。
执行器
当选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果。
二 日志模块
上面说完了查询的流程,与查询流程不一样的是,更新流程还涉及两个重要的日志模块,
redo log(重做日志)和 binlog(归档日志)。
这时候有同学要问,这里为什么要用两个日志模块,用一个日志模块不行吗?
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
这两种日志有以下三点不同。
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
接下来我们看看一条更新语句如何执行的呢?SQL 语句如下:
mysql> update T set c=c+1 where ID=2;
我们来看执行器和 InnoDB 引擎在执行这个简单的 update 语句时的内部流程。
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
为什么日志需要“两阶段提交”。这里不妨用反证法来进行解释。 由于 redo log 和 binlog 是两个独立的逻辑,如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者采用反过来的顺序。我们看看这两种方式会有什么问题。 仍然用前面的 update 语句来做例子。假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash,会出现什么情况呢?
- 先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。 但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。 然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
- 先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
如果采用 redo log 两阶段提交的方式就不一样了,写完 binlog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。
三 总结
- MySQL 主要分为 Server 层和引擎层,Server 层主要包括连接器、查询缓存、分析器、优化器、执行器,同时还有一个日志模块(binlog),这个日志模块所有执行引擎都可以共用,redolog 只有 InnoDB 有。
- 引擎层是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。
- 查询语句的执行流程如下:权限校验(如果命中缓存)—>查询缓存—>分析器—>优化器—>权限校验—>执行器—>引擎
- 更新语句执行流程如下:分析器---->权限校验---->执行器—>引擎—redo log(prepare 状态)—>binlog—>redo log(commit 状态)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- “神秘巨鲸”将数十亿USDT转入交易所!花旗前高管,绕过美证监会发行比特币证券!比特币将迎来拉涨行情?
- 微信小程序性能优化
- UR5机器人的旋转向量转换到四元数,再从四元数转换到旋转向量python代码
- 【12.23】转行小白历险记-算法02
- 2024年【A特种设备相关管理(锅炉压力容器压力管道)】新版试题及A特种设备相关管理(锅炉压力容器压力管道)考试试卷
- 发送HTTP POST请求并处理响应
- 新生代和老年代介绍
- k8s中 pod,service,deployment,ingress的使用场景
- BGP协议概念与配置(HCIP完整版)
- 高中电学实验学习