“智汇语言·驭领未来”——系列特辑:LLM大模型信息获取与企业应用变革
“智汇语言·驭领未来”——系列特辑:LLM大模型信息获取与企业应用变革
原创?认真的飞速小软?飞速创软?2024-01-16 09:30?发表于新加坡


本期引言
LLM(Large Language Model)大型语言模型以其自然语言理解和生成能力,正以前所未有的力量革新我们获取信息、进行沟通交流以及创新知识的方式。敬请期待我们的系列文章,一同揭示LLM大模型如何在信息时代背景下定义知识传播的版图,并深入剖析其功能及其在各领域的实际应用!
一![]()
行业背景
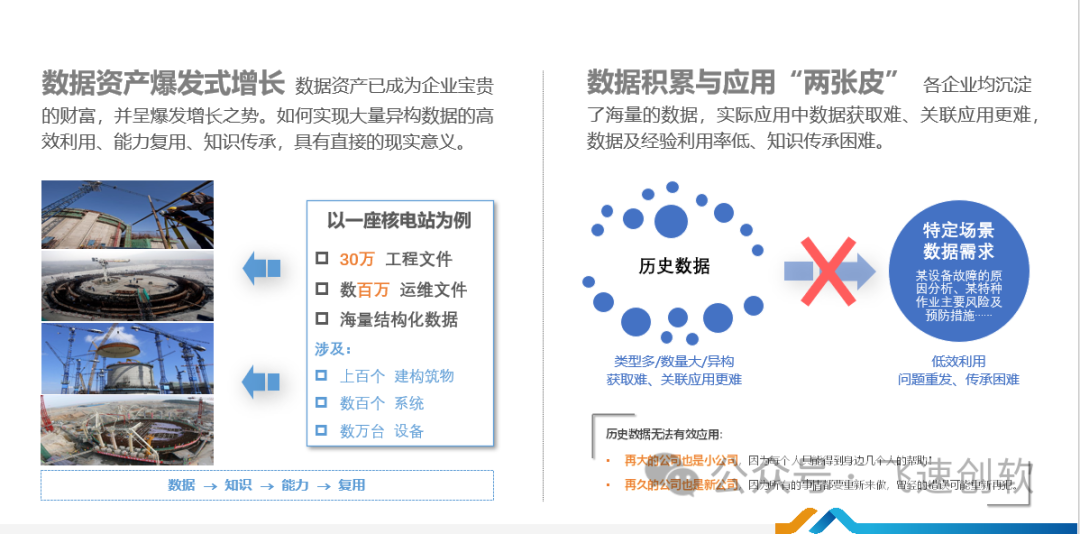
随着数字化进程深入和数字技术不断发展,越来越多类型的资产能够被数字化表达,同时,数字化资产这一概念的外延及其所涵盖的内容边界也在不断拓宽。数据作为构筑整个数字资产体系的根本要素,其存在与否直接决定了数字资产的价值。在当前阶段,中小企业每日产生的原始数据量通常介于数百GB至数TB之间,而大型企业日数据生成规模更是可从数TB级别升至数PB之多。
尽管各类型企业在日常运营中都在不断积累海量的数据资源,然而如何将这些庞大的数据成功转化为富含商业洞察、具有知识产权属性的信息资产,则是当前普遍面临的严峻挑战。只有真正实现对数据的有效捕获、分析和应用,才能充分挖掘并释放出数据背后潜藏的巨大价值潜力。
二![]()
应用制约与行业痛点
-
应用制约
以大语言模型(LLM)为技术基础的ChatGPT问世后,其在各行业领域的应用前景广受关注。但ChatGPT也面临一定挑战,如数据保密性不强、难实现私有化部署、使用成本高、专业问题回答能力有限。这就意味着,基于通用大模型开发的ChatGPT,无法充分满足企业在特定专业领域提出高深度问题的需求。许多公司希望通过自身数据训练,打造能够解决业务核心问题的定制化AI助手。这对低代码开发平台提出了更高要求,需要支持业务定制模型的训练与应用。
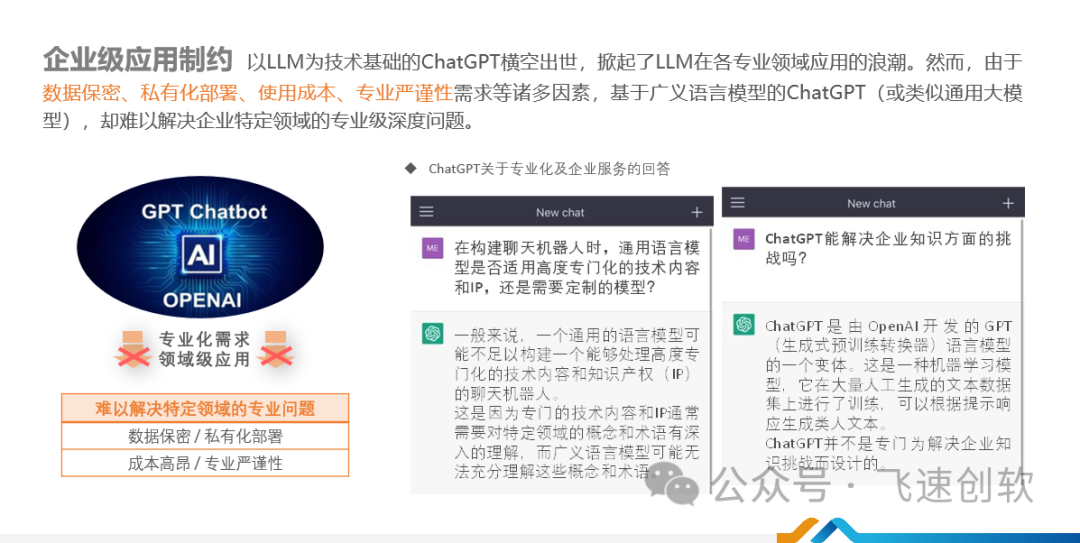
-
行业痛点
小软认为,当前绝大多数企业对历史沉淀数据利用率低主要原因是历史数据类型多、数量大和异架构。这导致了企业很难精准获知和建立各项数据之间的关联。针对这个痛点问题,为帮助企业提高数据利用能力,飞速创软新推出了集低代码开发与人工智能技术为一体的智能化低代码平台。
平台利用飞速AI大模型对原始数据进行清洗并将不同数据类型进行标准化处理,提高数据的准确性和可用性。同时通过机器学习自动发现数据关联点从而帮助企业洞察新的优势机会。最后飞速AI大模型通过NLP自然语言处理,降低终端的使用门槛,通过对话的形式将数据通过图表、表格等形式进行可视化展现,帮助企业更直观快速理解数据价值。
三![]()
飞速产品介绍与关键技术
-
产品介绍
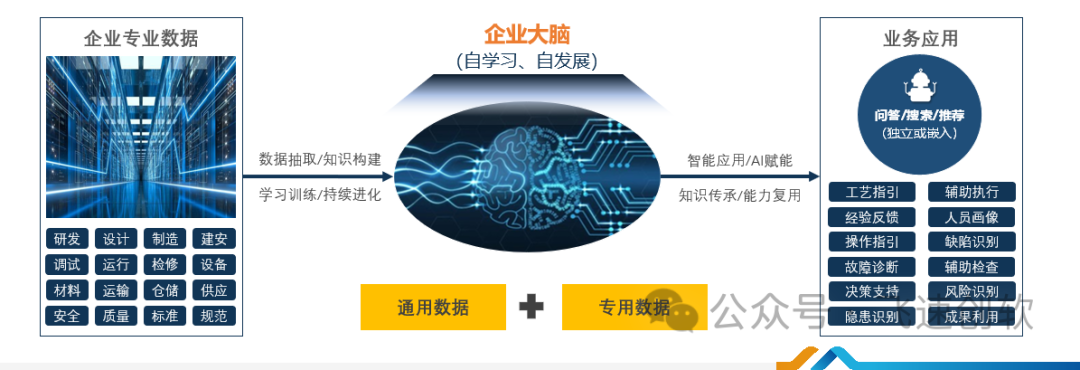
飞速AI大模型成功嵌入至飞速低代码平台中,并实现了以下关键大模型功能:
? ?1.知识获取
-
智能问答:员工可以通过智能问答获取所需的知识和信息,包括政策法规、设计规范、操作说明、维修要求等。
-
语义搜索:员工可以通过语义搜索快速找到相关的资料,例如设备维修流程、安全操作规范等。
? ?2.工作效率提升
-
智能推荐:LLM可以根据员工的当前工作情况,智能推荐相关的知识库内容,帮助员工提高工作效率。
-
文本生成:LLM可以基于自然语言对话,生成需求内容,例如工作日志、周报、检测报告等,帮助员工节省时间。
? ?3.内容管理
-
内容审查:LLM可以基于规则和语义,进行文本内容审核,帮助企业维护正面和谐秩序。
? ?4.业务流程优化
-
智能AI助手嵌入业务流程:LLM可以嵌入业务流程,自动进行风险提示、作业指导和决策支持,帮助企业提高运营效率。
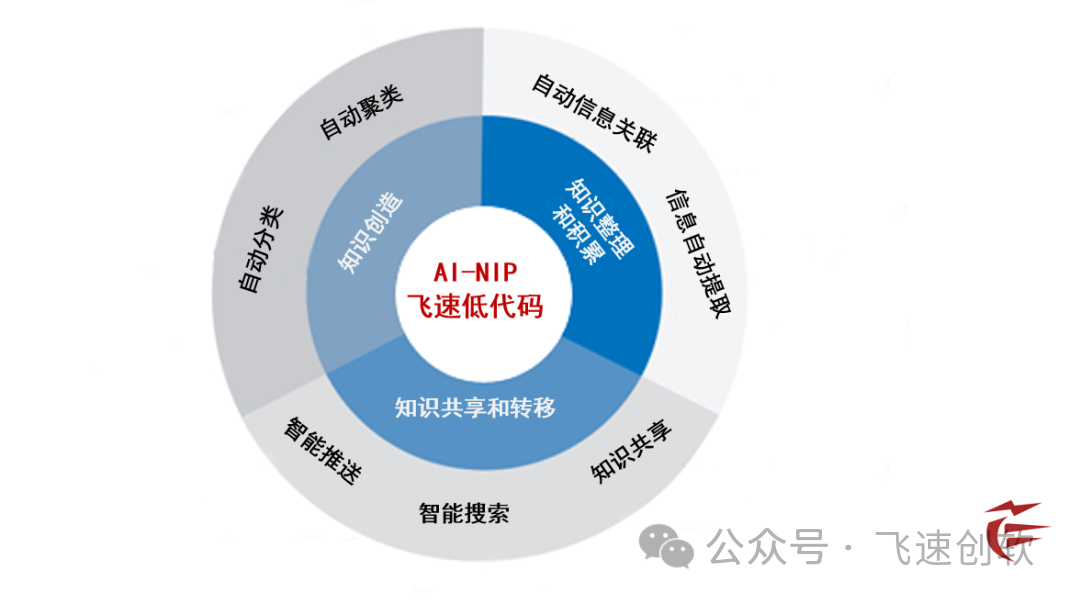
同时为满足企业对数据的安全性考量,飞速低代码+AI大模型产品支持私有化本地部署、源码开放,搭建私有平台、唤醒沉睡数据、打造专业大脑。并支持定制化解决方案,助力企业数据保密和应用自主可控。最终实现企业数据知识化、知识智能化并提升数字竞争力。
-
关键技术
考虑中小企业计算资源限制,飞速采用大模型蒸馏技术对AI大模型进行轻量化优化。在保持精准度的基础上,降低模型复杂度,实现快速低成本部署。
同时支持开发能源等特定行业的知识图谱构建,支持知识抽取、融合、推理和应用。让AI学习图谱结构后,有助提升大模型数据严谨性。飞速还可以将AI技术嵌入企业IT系统,赋能业务流程。例如:
1.自动检测工作风险,给出实时提示;
2.判断工作步骤是否需要操作指导,并提供指引;
3.在应急事件中,AI可以快速响应,给出辅助决策支持。
以上,飞速创软致力于通过结合低代码开发与AI大模型技术,研发解决行业实际问题的定制化技术方案。同时我们注重方案的实用性和应用可行性,通过低代码能力降低技术门槛,助力企业快速开发应用;另一方面,采用大模型蒸馏等技术,使AI模型在资源限制环境下也能高效运行。助力企业数字智能化转型。
END![]()
飞速创软各行业的合作伙伴


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MC-4/11/03/400步进电机驱动器的主要驱动方式有哪些?
- 每日一练【最大连续1的个数】
- Postgres 中文周报:Postgres Weekly 537 期
- 「HDLBits题解」Arithmetic Circuits
- 前端学习路线图和一些经验
- 代码随想录算法训练营第8天 | 344.反转字符串、 541. 反转字符串II、 替换数字(卡码网)、151.翻转字符串里的单词、右旋字符串(卡码网)
- 搜维尔科技:深入研究工作场所人体工程学中的动作捕捉
- MongoDB—SQL到MongoDB映射图表
- 交换两个变量(不创建临时变量)
- ROS学习笔记10——自定义源文件调用