【PaperReading】4. TAP
| Category | Content |
|---|---|
| 论文题目 | Tokenize Anything via Prompting |
| 作者 | Ting Pan, Lulu Tang, Xinlong Wang, Shiguang Shan (Beijing Academy of Artificial Intelligence) |
| 发表年份 | 2023 |
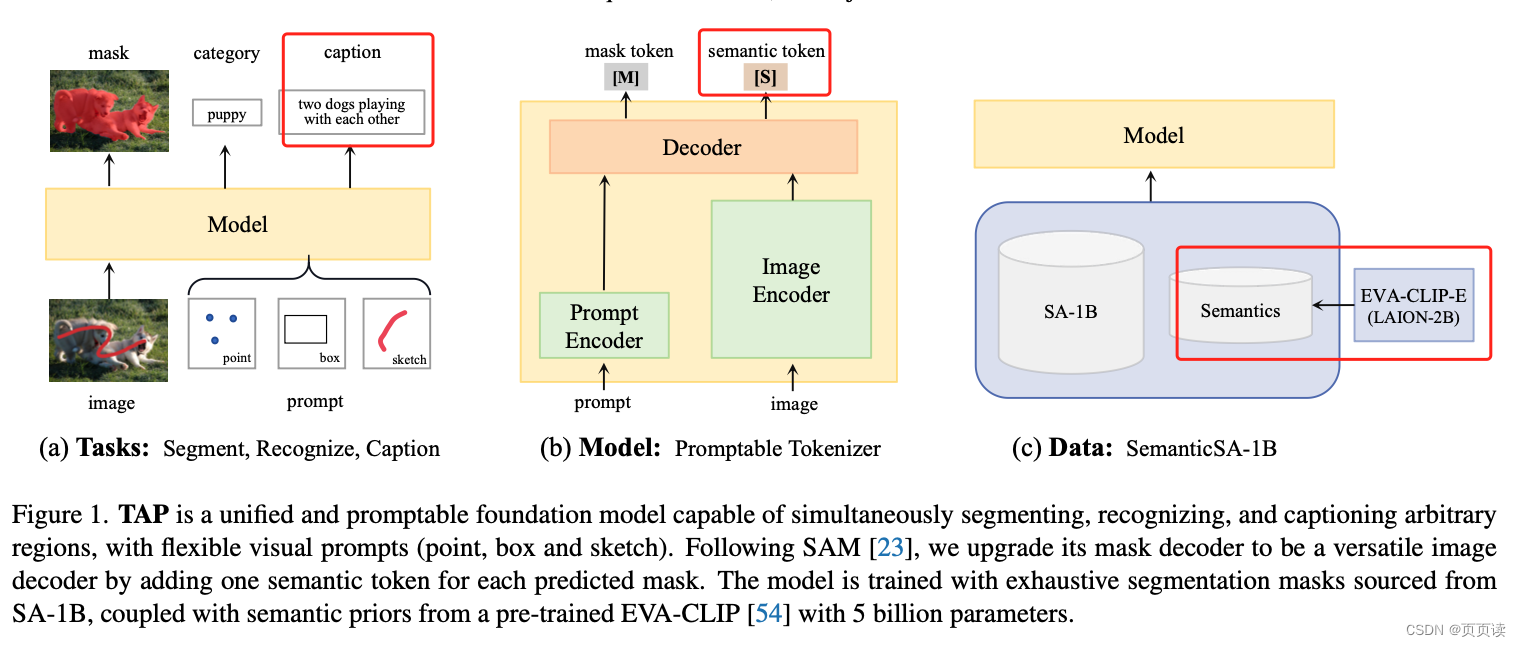
| 摘要 | 提出了一个统一的可提示模型,能够同时对任何事物进行分割、识别和描述。与SAM不同,我们的目标是通过视觉提示在野外构建一个多功能的区域表示。为此,我们使用大量分割掩码(如SA-1B掩码)和来自预训练CLIP模型的语义先验(拥有50亿参数)训练了一个通用模型。 具体而言,通过为每个掩码token添加一个语义token来构建一个可提示的图像解码器。语义token负责在预定义的概念空间中学习语义先验。通过对掩码token上的分割和语义token上的概念预测进行联合优化,模型表现出强大的区域识别和定位能力。例如,一个额外的3800万参数的因果文本解码器从零开始训练,在Visual Genome区域描述任务中创下了150.7的CIDEr分数新纪录。我们认为这个模型可以成为一个多功能的区域级图像tokenizer,能够为广泛的感知任务编码通用的区域上下文。代码和模型可在以下地址获取:https://github.com/baaivision/tokenize-anything。 |
| 引言 | 视觉感知的一个关键目标是有效地定位和识别任意感兴趣区域。它需要一个能够理解区域上下文并同时执行分割、识别和描述等感知任务的单一视觉模型。然而,现有模型通常只专注于定位类不敏感的掩码(例如SAM)或仅提取视觉语义(例如CLIP及其区域级变体)。特别是SAM开发了一个可以通过提示分割任何事物的分割基础模型,使得像素级定位任务具有强大的泛化能力。另一方面,CLIP通过在网规模的图像-文本对上进行对比学习,训练了一个识别基础模型,展示了在识别任务中强大的零样本能力。因此,从CLIP模型中学习语义先验是实现全面视觉感知的有希望的途径。 |
| 主要内容 | 论文详细介绍了如何构建一个能够高效实现分割、识别和描述任何事物的可提示模型。这是通过在可提示分割器内预测CLIP先验以及扩展模型范围来包含描述生成能力来实现的。文章主要关注在一个可提示分割模型SAM中对视觉和语言进行对齐,从而增强模型的区域级语义感知能力。与依赖于精心收集或近似的区域-文本数据的先前方法不同,作者的方法使用来自SA-1B的详尽分割数据和CLIP对掩码和语言进行对齐。模型在人工策划的概念空间中使用现成的CLIP嵌入,并在SAM的框架内进行预训练。 |
| 实验 | 在“实验”部分,作者详细介绍了他们如何在不同的数据集和任务上测试TAP模型。他们使用了SemanticSA-1B数据集进行零样本分割和区域级描述任务的实验。这些实验旨在评估模型在处理各种视觉和语言任务时的效果,包括图像分割、对象识别和图像描述。作者还对模型在各种复杂场景下的性能进行了评估,这包括不同类型的图像和多样化的描述任务。实验结果表明,TAP模型在所有测试任务上均表现出色,尤其是在零样本学习和区域级描述生成方面,显示了其卓越的适应性和灵活性。这些实验结果强调了模型的有效性和广泛的应用潜力。 |
| 结论 | 视觉提示可以促进超越简单分割的更广泛任务范围。通过在图像级CLIP中引入区域语义意识,SAM得到了增强,而不会损害掩码AP。此外,诸如词汇概念空间这样的正交空间对于有效学习CLIP先验至关重要。最后,他们强调,带有视觉提示的TAP模型充当了一个多功能的、位置感知的图像tokenizer,其中token化的区域特征可以直接用于提示因果语言建模。 |
| 阅读心得 |
就是在SAM架构上加上了text_token使得原来基于mask训练的SAM,现在也要基于text的描述进行训练。
这个想法我们以前也提到过(下图中"Mask Decoder Lightly Adapt"部分): 但是苦于训练不动,放弃了。 |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Pytorch学习torch.clamp ()用法浅析
- UVa12419 Heap Manager
- 10年磨一剑,我是如何弃“医”从事“农民工”,给读研的学弟学妹一点建议
- 【网络安全】全网最全的渗透测试介绍(超详细)
- Character Customizer
- SCAU 高级语言程序设计 实验四 选择结构
- 鸿蒙原生应用再添新丁!搜狐集团、航旅纵横入局鸿蒙
- uni-app的学习【第一节】
- 字符串算法总结|双指针的总结
- Java实战:统计文本中数字总和